Временами работа с контейнерами может казаться волшебством. В хорошем смысле для тех, кто понимает как устроено внутри, и в ужасающем - для тех, кто этого не понимает. К счастью, мы уже довольно давно изучаем технологию контейнеризации, и нам даже удалось выяснить, что контейнеры - это просто изолированные и ограниченные процессы Linux, что образы на самом деле не нужны для запуска контейнеров, и что, наоборот, для создания образа нам, возможно, потребуется запускать контейнеры.
Теперь пришло время заняться проблемой сети в контейнерах. Или, точнее, проблемой контейнерной сети с одним хостом. В этой статье мы собираемся ответить на следующие вопросы:
Как виртуализировать сетевые ресурсы, чтобы контейнеры думали, что у них есть отдельные сетевые среды?
Как превратить контейнеры в дружелюбных соседей и научить общаться друг с другом?
Как выйти во внешний мир (например, в Интернет) изнутри контейнера?
Как связаться с контейнерами, работающими на хосте Linux, из внешнего мира?
Как реализовать публикацию портов, подобную Docker?
Отвечая на эти вопросы, мы создадим контейнерную сеть с одним хостом с нуля, используя стандартные инструменты Linux. В результате станет очевидным, что магия контейнерных сетей возникает из сочетания гораздо более базовых возможностей Linux.:
Сетевые пространства имен (netns)
Виртуальные устройства Ethernet (veth)
Виртуальные сетевые коммутаторы (bridge)
Маршрутизация IP и преобразование сетевых адресов (NAT).
Давайте начнем! 🚀
Предварительные требования
Предполагается базовое знание сценариев bash и командной строки Linux, но навыков программирования не требуется. Примеры в этом руководстве были протестированы на Ubuntu 22.04, и они, вероятно, будут работать и на других современных дистрибутивах Linux. Рекомендуется использовать изолированную и одноразовую среду "песочницы".
⚠️ ОСТОРОЖНО: выполнение приведенных ниже команд непосредственно в операционной системе вашего компьютера может привести к проблемам.
Основные компоненты сетевой среды (устройства, таблицы маршрутизации, правила брандмауэра)
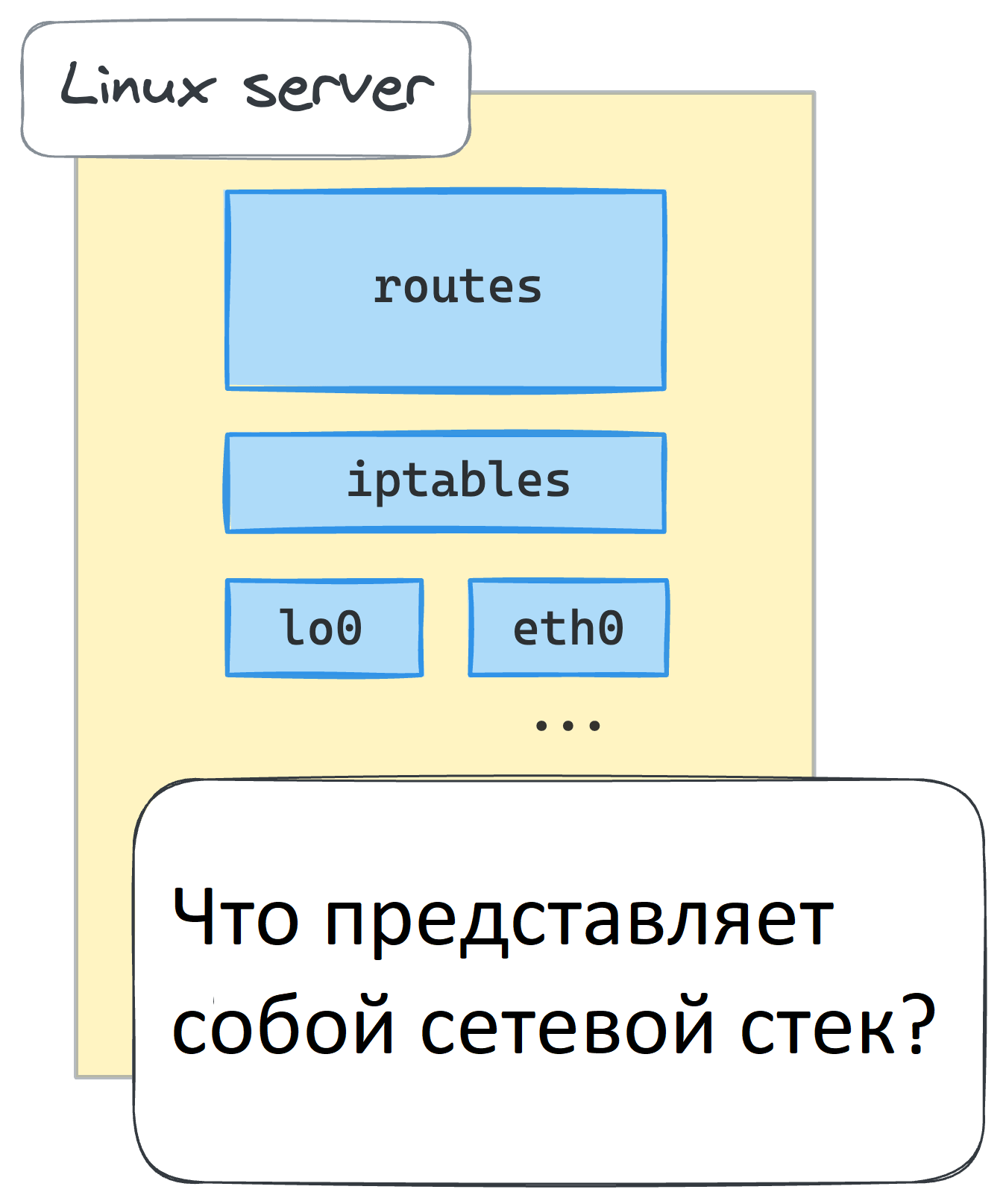
Что представляет собой сетевое окружение Linux, также известное как сетевой контекст? Ну, очевидно, набор сетевых устройств. Что еще? Вероятно, какие-то правила маршрутизации. И, конечно, не стоит забывать - перехваты netfilter, в том числе те, которые определены правилами iptables. Есть и другие компоненты, но приведенного выше должно быть достаточно для наших целей в этом руководстве.
Мы можем быстро создать (не полный) скрипт для проверки сетевой среды:
Файл inspect-net-context.sh
#!/usr/bin/env bash echo "# Network devices" ip link list echo -e "\n# Route table" ip route list echo -e "\n# iptables rules" iptables --list-rules
Однако перед ее запуском давайте добавим новую цепочку iptables, чтобы сделать набор правил более узнаваемым:
💡 Предполагается, что все команды в этом руководстве должны выполняться как
rootили с префиксомsudo.
iptables --new-chain MY_CUSTOM_CHAIN
После этого выполнение скрипта inspect на моей машине выдает следующий результат: Если мы запустим скрипт на обычной машине Linux, мы получим результат, аналогичный следующему:
~/inspect-net-context.sh
# Network devices 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 ... 4: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 92:b2:3d:42:ed:22 brd ff:ff:ff:ff:ff:ff # Route table default via 172.16.0.1 dev eth0 172.16.0.0/16 dev eth0 proto kernel scope link src 172.16.0.2 # iptables rules -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT -N MY_CUSTOM_CHAIN
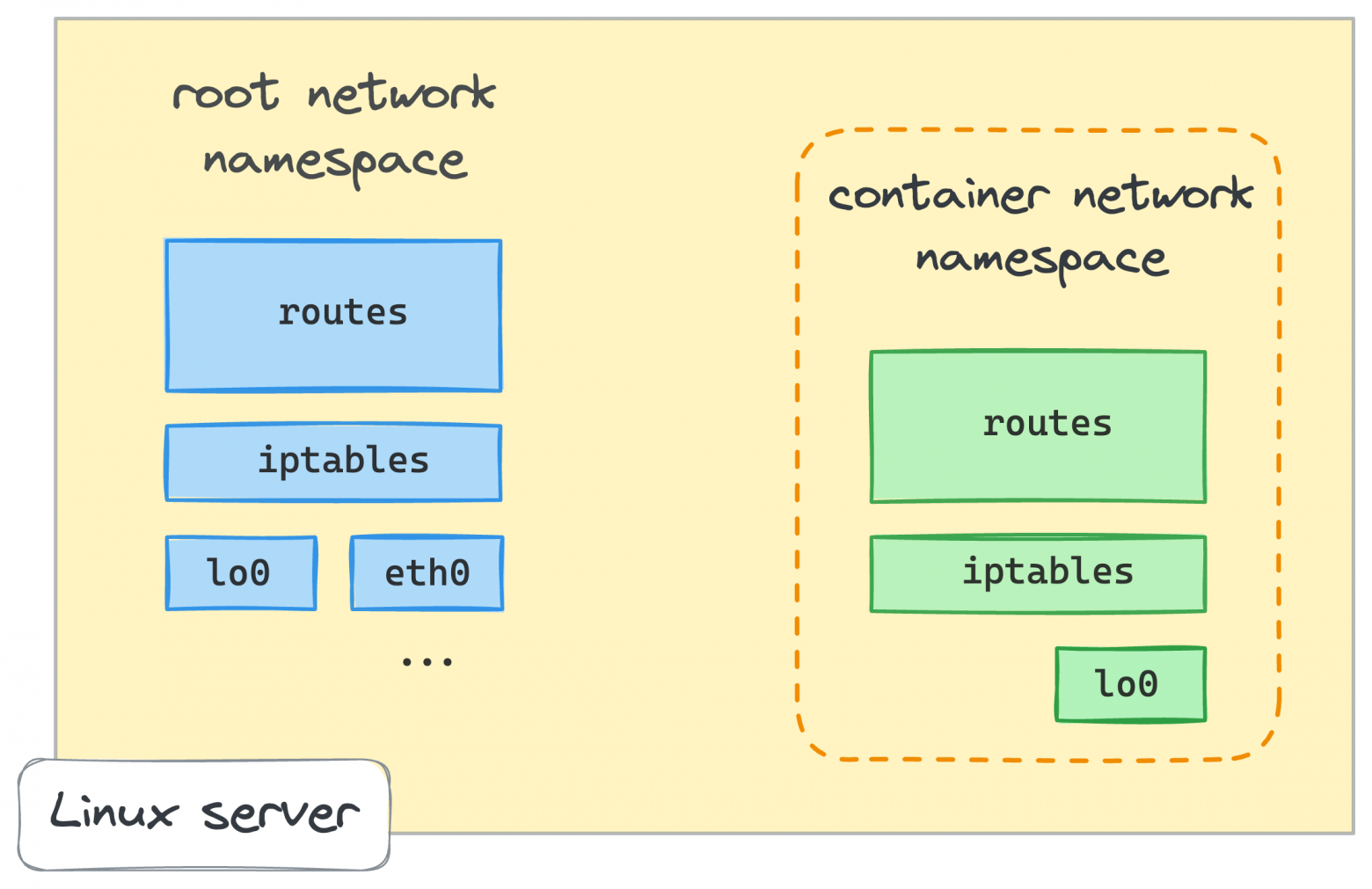
Зачем нам нужно проверять сетевое окружение? Потому что мы собираемся начать создавать контейнеры в ближайшее время, и мы хотим убедиться, что каждый из них получит свой собственный сетевой контекст, полностью изолированный от среды хоста и других контейнеров. Для этого нам нужно привыкнуть к перечислению сетевых устройств, маршрутизации и правил iptables.
👨🎓 Для простоты, вместо создания полноценных контейнеров, использующих все возможные пространства имен Linux, в этом руководстве мы ограничим область виртуализации только сетевым контекстом. Таким образом, пространство имен контейнера и сети, приведенное ниже, будут использоваться взаимозаменяемо.
Создание первого контейнера с использованием сетевого пространства имен (netns)
Вы, вероятно, уже слышали, что одно из пространств имен Linux, используемых для создания контейнеров, называется netns или сетевое пространство имен. От man ip-netns, "пространство имен network логически является еще одной копией сетевого стека со своими собственными маршрутами, правилами брандмауэра и сетевыми устройствами".
Один из способов создать сетевое пространство имен в Linux - использовать ip netns add команду (где ip утилита берется из де-факто стандартной коллекции iproute2):
ip netns add netns0
Чтобы проверить, добавлено ли в систему новое пространство имен, выполните следующую команду:
ip netns list
netns0
Как начать использовать только что созданное пространство имен? Есть еще одна удобная утилита Linux под названием nsenter. Она входит в одно или несколько указанных пространств имен, а затем выполняет в нем заданную программу. Например, вот как мы можем запустить новый сеанс командной строки внутри netns0 пространства имен:
nsenter --net=/run/netns/netns0 bash
Недавно созданный bash процесс теперь находится в netns0 пространстве имен. Если мы запустим наш скрипт inspect в этой новой оболочке, мы получим следующий результат:
~/inspect-net-context.sh
# Network devices 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 # Route table # Iptables rules -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT
Приведенный выше вывод ясно показывает, что bash процесс, который выполняется в netns0 пространстве имен, имеет совершенно другую сетевую среду - здесь вообще нет правил маршрутизации, нет MY_CUSTOM_CHAIN цепочки iptables и только одно сетевое устройство, loopback. Пока все хорошо!
Подключение контейнеров к хостингу с помощью виртуальных устройств Ethernet (veth)
Новая изолированная сетевая среда была бы не так полезна, если бы мы не могли взаимодействовать с ней. К счастью, Linux предоставляет специальное средство для подключения сетевых пространств имен - виртуальное устройство Ethernet или veth. От man veth, "устройства veth - это виртуальные устройства Ethernet. Они могут действовать как туннели между сетевыми пространствами имен для создания моста к физическому сетевому устройству в другом пространстве имен, но также могут использоваться как автономные сетевые устройства ".
Виртуальные устройства Ethernet всегда работают парами. Не беспокойтесь, если это звучит немного запутанно, это станет ясно, когда мы посмотрим на пример использования.
⚠️
nsenterКоманда, которую мы использовали выше, запустила вложенный сеанс командной оболочки вnetns0пространстве имен network. Не забудьте сделатьexitили открыть новую вкладку терминала , прежде чем переходить к следующим шагам.
Из пространства имен корневой сети давайте создадим пару виртуальных устройств Ethernet:
ip link add veth0 type veth peer name ceth0
С помощью этой единственной команды мы только что создали пару взаимосвязанных виртуальных устройств Ethernet. Имена veth0 и ceth0 были выбраны произвольно:
ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 ... 4: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 92:b2:3d:42:ed:22 brd ff:ff:ff:ff:ff:ff 5: ceth0@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether b2:d3:e4:24:c3:f1 brd ff:ff:ff:ff:ff:ff 6: veth0@ceth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 4e:ac:e0:3c:d8:6e brd ff:ff:ff:ff:ff:ff
Как veth0, так и ceth0 после создания находятся в сетевом контексте хоста, то есть в пространстве имен корневой сети. Чтобы соединить корневое пространство имен с netns0 пространством имен, которое мы создали ранее, нам нужно сохранить одно из устройств в корневом пространстве имен и переместить другое в netns0:
ip link set ceth0 netns netns0
Давайте убедимся, что одно из устройств исчезло из корневого сетевого контекста:
ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 ... 4: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 92:b2:3d:42:ed:22 brd ff:ff:ff:ff:ff:ff 6: veth0@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 4e:ac:e0:3c:d8:6e brd ff:ff:ff:ff:ff:ff link-netns netns0
Как только мы включим устройства veth и назначим соответствующие IP-адреса, любой пакет, приходящий на одно из устройств, немедленно появится на его одноранговом устройстве, эффективно соединяя два сетевых пространства имен.
Давайте начнем с корневого пространства имен:
ip link set veth0 up ip addr add 172.18.0.11/16 dev veth0
... и продолжить в netns0 пространстве имен:
nsenter --net=/run/netns/netns0 bash
В новом сеансе оболочки, который выполняется в netns0 пространстве имен:
ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 5: ceth0@if6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether da:08:47:8b:8f:c7 brd ff:ff:ff:ff:ff:ff link-netnsid 0
Похоже, что устройство обратной связи не работает в новых пространствах имен, поэтому нам нужно сначала включить его:
ip link set lo up
Теперь вернемся к ceth0 устройству:
ip link set ceth0 up ip addr add 172.18.0.10/16 dev ceth0

И мы готовы к первой проверке подключения! 🎉 Давайте попробуем пропинговать veth0 устройство из netns0 пространства имен:
ping -c 2 172.18.0.11
PING 172.18.0.11 (172.18.0.11) 56(84) bytes of data. 64 bytes from 172.18.0.11: icmp_seq=1 ttl=64 time=0.093 ms 64 bytes from 172.18.0.11: icmp_seq=2 ttl=64 time=0.075 ms --- 172.18.0.11 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1028ms rtt min/avg/max/mdev = 0.075/0.084/0.093/0.009 ms
Теперь завершите работу netns0, выполнив команду exit (или откройте новую вкладку терминала) и попробуйте пропинговать ceth0 устройство из корневого пространства имен:
ping -c 2 172.18.0.10
PING 172.18.0.10 (172.18.0.10) 56(84) bytes of data. 64 bytes from 172.18.0.10: icmp_seq=1 ttl=64 time=0.012 ms 64 bytes from 172.18.0.10: icmp_seq=2 ttl=64 time=0.078 ms --- 172.18.0.10 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1024ms rtt min/avg/max/mdev = 0.012/0.045/0.078/0.033 ms
Успех! Мы только что получили потоки пакетов между корневым пространством имен и netns0 пространством имен.
Но что, если мы попытаемся связаться с любым другим адресом из netns0 пространства имен? Добьемся ли мы успеха? Давайте выясним!
ip addr show dev eth0
4: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether ee:36:69:36:fe:bd brd ff:ff:ff:ff:ff:ff inet 172.16.0.2/16 brd 172.16.255.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::b0b9:11ff:fe79:613f/64 scope link valid_lft forever preferred_lft forever
Обратите внимание на этот 172.16.0.2 адрес - это IP-адрес другого сетевого интерфейса на хост-компьютере, и мы собираемся использовать его для проверки подключения из netns0 пространства имен:
nsenter --net=/run/netns/netns0 bash
Доступ к сетевому интерфейсу хоста из netns0 пространства имен:
ping 172.16.0.2
ping: connect: Network is unreachable
Что, если мы попробуем что-нибудь из Интернета?
ping 8.8.8.8
ping: connect: Network is unreachable
Однако сбой легко объяснить. В netns0 таблице маршрутизации для таких пакетов просто нет записи. Единственная запись там показывает, как добраться до 172.18.0.0/16 сети:
ip route list
172.18.0.0/16 dev ceth0 proto kernel scope link src 172.18.0.10
Как она туда попала? В Linux есть множество способов заполнения таблицы маршрутизации. Один из них - извлекать маршруты из подключенных напрямую сетевых интерфейсов. Вы помните, что таблица маршрутизации в netns0 была пустой сразу после создания пространства имен? Но затем мы переместили ceth0 устройство в netns0 и присвоили ему IP-адрес 172.18.0.10/16. Поскольку мы использовали не простой IP-адрес, а комбинацию адреса и маски сети, сетевому стеку удалось извлечь из него информацию о маршруте. Из-за этой производной записи каждый пакет из netns0 пространства имен, предназначенный для 172.18.0.0/16 сети, будет отправлен через ceth0 устройство. Но любые другие пакеты будут отброшены.
Аналогично, в корневое пространство имен был добавлен новый маршрут (возможно, вам захочется сначала ввести exit для выхода netns0):
ip route list
... omitted lines ... 172.18.0.0/16 dev veth0 proto kernel scope link src 172.18.0.11
На этом этапе мы готовы ответить на наш самый первый вопрос. Теперь мы знаем, как виртуализировать и соединять сетевые среды Linux.
Создаем второй контейнер, повторяя те же шаги
Идея контейнеризации возникла потому, что людям нужен был лучший способ совместного использования компьютерных ресурсов. Вместо использования одного сервера только для одного приложения контейнеры позволяют запускать множество (изолированных друг от друга) процессов на одном сервере. Таким образом, вы максимально используете возможности сервера.
Давайте посмотрим, что произойдет, если мы разместим несколько контейнеров на одном хосте, используя veth трюк, описанный выше.
Из корневого пространства имен добавляем еще один "контейнер":
ip netns add netns1 ip link add veth1 type veth peer name ceth1 ip link set veth1 up ip addr add 172.18.0.21/16 dev veth1 ip link set ceth1 netns netns1
... и продолжение из "контейнера":
nsenter --net=/run/netns/netns1 bash
ip link set lo up ip link set ceth1 up ip addr add 172.18.0.20/16 dev ceth1
Хорошо, теперь начинается наша любимая часть - проверка подключения (из netns1 пространства имен):
ping -c 2 172.18.0.21
PING 172.18.0.21 (172.18.0.21) 56(84) bytes of data. --- 172.18.0.21 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 1023ms
Хм... Мы сделали все так же, как и раньше, но подключение нарушено. Из netns1 мы не можем получить доступ к корневому пространству имен.
ip route list
172.18.0.0/16 dev ceth1 proto kernel scope link src 172.18.0.20
Есть даже маршрут! Так почему же он не работает?
Что, если мы попытаемся пропинговать ceth1 устройство из корневого пространства имен?
exit
...а потом:
ping -c 2 172.18.0.20
PING 172.18.0.20 (172.18.0.20) 56(84) bytes of data. From 172.18.0.11 icmp_seq=1 Destination Host Unreachable From 172.18.0.11 icmp_seq=2 Destination Host Unreachable --- 172.18.0.20 ping statistics --- 2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 1014ms pipe 2
В то же время из нашего первого контейнера (netns0) мы МОЖЕМ добраться до конца хоста нового контейнера (veth1):
nsenter --net=/run/netns/netns0 bash
ping -c 2 172.18.0.21
PING 172.18.0.21 (172.18.0.21) 56(84) bytes of data. 64 bytes from 172.18.0.21: icmp_seq=1 ttl=64 time=0.037 ms 64 bytes from 172.18.0.21: icmp_seq=2 ttl=64 time=0.046 ms --- 172.18.0.21 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 33ms rtt min/avg/max/mdev = 0.037/0.041/0.046/0.007 ms
Но мы все еще не можем достичь netns1:
ping -c 2 172.18.0.20
PING 172.18.0.20 (172.18.0.20) 56(84) bytes of data. From 172.18.0.10 icmp_seq=1 Destination Host Unreachable From 172.18.0.10 icmp_seq=2 Destination Host Unreachable --- 172.18.0.20 ping statistics --- 2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 63ms pipe 2
Упс! Что-то не так... netns1 застрял в подвешенном состоянии. По какой-то причине он не может связаться с root, и из корневого пространства имен мы также не можем связаться с ним. Однако, поскольку оба контейнера находятся в одной IP-сети 172.18.0.0/16, теперь мы можем общаться с хостом veth1 из netns0 контейнера. Интересно...
Что ж, мне потребовалось некоторое время, чтобы разобраться в этом, но, очевидно, мы столкнулись с конфликтом маршрутов. Давайте проверим таблицу маршрутизации в корневом пространстве имен:
ip route list
... omitted lines ... 172.18.0.0/16 dev veth0 proto kernel scope link src 172.18.0.11 172.18.0.0/16 dev veth1 proto kernel scope link src 172.18.0.21
Несмотря на то, что после добавления второй veth пары таблица маршрутизации root получила новый 172.18.0.0/16 dev veth1 proto kernel scope link src 172.18.0.21 маршрут, уже существовал маршрут для точно такой же 172.18.0.0/16 сети. Когда второй контейнер пытается выполнить пинг veth1 устройства, выбирается первый маршрут, и это прерывает подключение. Если бы мы удалили первый маршрут (ip route delete 172.18.0.0/16 dev veth0 proto kernel scope link src 172.18.0.11) и перепроверили подключение, ситуация была бы обратной - netns0 были бы в подвешенном состоянии и netns1 могли бы пинговать veth0 устройство хоста.

Что ж, я полагаю, что если бы мы выбрали другую IP-сеть для netns1, все бы заработало. Однако несколько контейнеров, размещенных в одной IP-сети, являются законным вариантом использования. Таким образом, нам нужно как-то скорректировать veth подход...
Объединение контейнеров с помощью виртуального сетевого коммутатора (bridge)
К счастью, в Linux есть решение вышеупомянутой проблемы, и это еще одно средство виртуализации сети под названием bridge.
bridgeУстройство Linux ведет себя как сетевой коммутатор. Он пересылает пакеты между интерфейсами, которые к нему подключены. И поскольку это коммутатор, а не маршрутизатор, его не волнуют IP-адреса подключенных устройств, потому что он работает на уровне L2 (т. Е. Ethernet).

Давайте попробуем поиграть с нашей новой игрушкой. Но сначала нам нужно очистить существующую настройку, потому что некоторые конфигурационные изменения, которые мы внесли до сих пор, на самом деле больше не нужны. Удаления сетевых пространств имен должно быть достаточно:
ip netns delete netns0 ip netns delete netns1
Однако, если у вас все еще остались какие-то недоделки, вы можете удалить их вручную:
ip link delete veth0 ip link delete ceth0 ip link delete veth1 ip link delete ceth1
Чтобы подготовить почву для нового эксперимента, давайте быстро воссоздадим два контейнера.
Первый контейнер
Из корневого пространства имен:
ip netns add netns0 ip link add veth0 type veth peer name ceth0 ip link set veth0 up ip link set ceth0 netns netns0
Продолжаем с netns0пространства имен:
nsenter --net=/run/netns/netns0 bash
ip link set lo up ip link set ceth0 up ip addr add 172.18.0.10/16 dev ceth0
exit
Второй контейнер
Из корневого пространства имен:
ip netns add netns1 ip link add veth1 type veth peer name ceth1 ip link set veth1 up ip link set ceth1 netns netns1
Продолжаем с netns1пространства имен:
nsenter --net=/run/netns/netns1 bash
ip link set lo up ip link set ceth1 up ip addr add 172.18.0.20/16 dev ceth1
exit
👨🎓 Обратите внимание, что мы больше не назначаем никаких IP-адресов концам хоста контейнеров (
veth0иveth1).
Убедитесь, что на хосте нет новых маршрутов:
ip route list
default via 172.16.0.1 dev eth0 172.16.0.0/16 dev eth0 proto kernel scope link src 172.16.0.2
Теперь мы готовы создать мостовое устройство:
ip link add br0 type bridge ip link set br0 up
Когда мост создан, нам нужно подключить к нему контейнеры, прикрепив концы хоста (veth0 и veth1) их veth пар:
ip link set veth0 master br0 ip link set veth1 master br0

Пришло время еще раз проверить подключение!
От первого контейнера ко второму:
nsenter --net=/run/netns/netns0 ping -c 2 172.18.0.20
PING 172.18.0.20 (172.18.0.20) 56(84) bytes of data. 64 bytes from 172.18.0.20: icmp_seq=1 ttl=64 time=0.295 ms 64 bytes from 172.18.0.20: icmp_seq=2 ttl=64 time=0.053 ms --- 172.18.0.20 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.053/0.174/0.295/0.121 ms
От второго контейнера к первому:
nsenter --net=/run/netns/netns1 ping -c 2 172.18.0.10
PING 172.18.0.10 (172.18.0.10) 56(84) bytes of data. 64 bytes from 172.18.0.10: icmp_seq=1 ttl=64 time=0.052 ms 64 bytes from 172.18.0.10: icmp_seq=2 ttl=64 time=0.103 ms --- 172.18.0.10 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1019ms rtt min/avg/max/mdev = 0.052/0.077/0.103/0.025 ms
Прекрасно! Все работает отлично. Благодаря этому новому подходу мы не настраивали veth0 и veth1 вообще. Единственные два IP-адреса, которые мы явно назначили, были на концах ceth0 и ceth1. Но поскольку они оба находятся в одном сегменте Ethernet (помните, мы подключили их к виртуальному коммутатору), есть подключение на уровне L2. Вот как мы можем это проверить.:
nsenter --net=/run/netns/netns0 ip neigh
172.18.0.20 dev ceth0 lladdr 3e:f2:8f:03:c8:1c REACHABLE
nsenter --net=/run/netns/netns1 ip neigh
172.18.0.10 dev ceth1 lladdr 4e:ff:98:90:d5:ea REACHABLE
Поздравляем! 🎉 Мы только что узнали, как превратить контейнеры в дружелюбных соседей и научить их общаться друг с другом.
Выход на внешний мир (маршрутизация IP и маскировка)
Наши контейнеры могут взаимодействовать друг с другом, но могут ли они взаимодействовать с хостом, то есть корневым пространством имен?
nsenter --net=/run/netns/netns0 ping -c 2 172.16.0.2 # host's eth0 address
ping: connect: Network is unreachable
Это отчасти очевидно, для этого просто нет маршрута в netns0:
nsenter --net=/run/netns/netns0 ip route list
172.18.0.0/16 dev ceth0 proto kernel scope link src 172.18.0.10
Корневое пространство имен также не может взаимодействовать с контейнерами:
ping -c 2 172.18.0.10
PING 172.18.0.10 (172.18.0.10) 56(84) bytes of data. --- 172.18.0.10 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 1007ms
ping -c 2 172.18.0.20
PING 172.18.0.20 (172.18.0.20) 56(84) bytes of data. --- 172.18.0.20 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 1016ms
Чтобы установить связь между корневым пространством имен и пространством имен контейнера, нам нужно назначить IP-адрес сетевому интерфейсу bridge:
ip addr add 172.18.0.1/16 dev br0
Как только мы назначили IP-адрес интерфейсу bridge, мы получили маршрут в таблице маршрутизации хоста:
ip route list
... omitted lines ... 172.18.0.0/16 dev br0 proto kernel scope link src 172.18.0.1
Теперь корневое пространство имен должно иметь возможность пинговать контейнеры.
Корневое пространство имен для первого контейнера:
ping -c 2 172.18.0.10
PING 172.18.0.10 (172.18.0.10) 56(84) bytes of data. 64 bytes from 172.18.0.10: icmp_seq=1 ttl=64 time=0.141 ms 64 bytes from 172.18.0.10: icmp_seq=2 ttl=64 time=0.081 ms --- 172.18.0.10 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1020ms rtt min/avg/max/mdev = 0.081/0.111/0.141/0.030 ms
Корневое пространство имен для второго контейнера:
ping -c 2 172.18.0.20
PING 172.18.0.20 (172.18.0.20) 56(84) bytes of data. 64 bytes from 172.18.0.20: icmp_seq=1 ttl=64 time=0.048 ms 64 bytes from 172.18.0.20: icmp_seq=2 ttl=64 time=0.083 ms --- 172.18.0.20 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1030ms rtt min/avg/max/mdev = 0.048/0.065/0.083/0.017 ms
Контейнер, вероятно, также получил возможность пинговать интерфейс моста, но они по-прежнему не могут связаться с хостом eth0. Для этого нам нужно добавить маршрут по умолчанию в таблицы маршрутизации контейнеров:
nsenter --net=/run/netns/netns0 \ ip route add default via 172.18.0.1 # i.e. via the bridge interface
nsenter --net=/run/netns/netns1 \ ip route add default via 172.18.0.1 # i.e. via the bridge interface
Подтверждение подключения контейнеров к хостингу:
nsenter --net=/run/netns/netns0 ping -c 2 172.16.0.2
PING 172.16.0.2 (172.16.0.2) 56(84) bytes of data. 64 bytes from 172.16.0.2: icmp_seq=1 ttl=64 time=0.035 ms 64 bytes from 172.16.0.2: icmp_seq=2 ttl=64 time=0.036 ms --- 172.16.0.2 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1009ms rtt min/avg/max/mdev = 0.035/0.035/0.036/0.000 ms
Идеально! Мы можем переходить от контейнеров к хосту и обратно.

Теперь давайте попробуем подключить контейнеры к внешнему миру. По умолчанию пересылка пакетов (то есть функциональность маршрутизатора) в Linux отключена. Нам нужно включить ее (из корневого пространства имен):
echo 1 > /proc/sys/net/ipv4/ip_forward
Это изменение фактически превратило хост-машину в маршрутизатор, а интерфейс bridge стал шлюзом по умолчанию для контейнеров. Проверка подключения контейнеров к Интернету.:
nsenter --net=/run/netns/netns0 ping -c 2 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. --- 8.8.8.8 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 1018ms
Загадочно! По-прежнему безуспешно.
Что мы упустили? Если бы контейнер отправлял пакеты во внешний мир, сервер назначения не смог бы отправлять пакеты обратно в контейнер, потому что IP-адрес контейнера является частным. Т.е. правила маршрутизации для этого конкретного IP-адреса известны только локальной сети. И многие контейнеры в мире используют точно такой же частный IP-адрес 172.18.0.10. Решение этой проблемы называется преобразование сетевых адресов (NAT). Перед отправкой во внешнюю сеть IP-адреса пакетов, отправленных контейнерами, будут заменены на IP-адреса внешнего интерфейса хоста. Хост также будет отслеживать все существующие сопоставления и по прибытии восстановит IP-адреса перед отправкой пакетов обратно в контейнеры. Настройка вручную кажется сложной, но у меня для вас хорошие новости! Благодаря волшебству iptables нам нужна всего одна команда, чтобы это произошло:
iptables -t nat -A POSTROUTING -s 172.18.0.0/16 ! -o br0 -j MASQUERADE
Команда довольно проста, если вы знаете, как iptables работать - мы добавили новое правило в nat таблицу POSTROUTING цепочки с просьбой маскировать все пакеты, отправленные в 172.18.0.0/16 сеть, за исключением тех, которые отправляются в bridge интерфейс.
Еще раз проверяем подключение:
nsenter --net=/run/netns/netns0 ping -c 2 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=115 time=9.29 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=115 time=7.72 ms --- 8.8.8.8 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1002ms rtt min/avg/max/mdev = 7.718/8.505/9.293/0.787 ms
⚠️ Помните, что мы следуем стратегии "по умолчанию - разрешить", которая может быть довольно опасной в реальных условиях. Политика iptables хоста по умолчанию -
ACCEPTдля каждой цепочки:
iptables -S
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPTВ качестве хорошей практики Docker, например, ограничивает все по умолчанию, а затем включает маршрутизацию только для известных путей.
В качестве хорошей практики Docker, например, ограничивает все по умолчанию, а затем включает маршрутизацию только для известных путей.
Нажмите здесь, чтобы ознакомиться с правилами Docker iptables 🧐
Ниже приведены выгруженные правила, сгенерированные демоном Docker на компьютере с Ubuntu 22.04 с одним контейнером, доступным через порт 5005. Вы можете использовать docker run -p 5005:80 -d nginx нашу онлайн-площадку Docker playground для воспроизведения результатов:
iptables -t filter --list-rules
-P INPUT ACCEPT -P FORWARD DROP -P OUTPUT ACCEPT -N DOCKER -N DOCKER-ISOLATION-STAGE-1 -N DOCKER-ISOLATION-STAGE-2 -N DOCKER-USER -A FORWARD -j DOCKER-USER -A FORWARD -j DOCKER-ISOLATION-STAGE-1 -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT -A FORWARD -o docker0 -j DOCKER -A FORWARD -i docker0 ! -o docker0 -j ACCEPT -A FORWARD -i docker0 -o docker0 -j ACCEPT -A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 80 -j ACCEPT -A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2 -A DOCKER-ISOLATION-STAGE-1 -j RETURN -A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP -A DOCKER-ISOLATION-STAGE-2 -j RETURN -A DOCKER-USER -j RETURN
iptables -t nat --list-rules
-P PREROUTING ACCEPT -P INPUT ACCEPT -P OUTPUT ACCEPT -P POSTROUTING ACCEPT -N DOCKER -A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER -A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE -A POSTROUTING -s 172.17.0.2/32 -d 172.17.0.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE -A DOCKER -i docker0 -j RETURN -A DOCKER ! -i docker0 -p tcp -m tcp --dport 5005 -j DNAT --to-destination 172.17.0.2:80
iptables -t mangle --list-rules
-P PREROUTING ACCEPT -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT -P POSTROUTING ACCEPT
iptables -t raw --list-rules
-P PREROUTING ACCEPT -P OUTPUT ACCEPT
Хорошо, давайте посмотрим, сможете ли вы применить свои новые знания в следующей задаче!
Предоставление внешнему миру доступа к контейнерам (публикация портов)
Хорошо известна практика публикации портов контейнера для некоторых (или всех) интерфейсов хоста. Но что на самом деле делает публикация портов?
Представьте, что у нас есть сервер, работающий внутри контейнера:
nsenter --net=/run/netns/netns0 \ python3 -m http.server --bind 172.18.0.10 5000
Если мы попытаемся отправить HTTP-запрос этому серверному процессу с хоста, все будет работать - ну, есть связь между корневым пространством имен и всеми интерфейсами контейнера, почему бы и нет?
Попробуйте сами (из корневого пространства имен в отдельной вкладке терминала):
curl 172.18.0.10:5000
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> ... omitted lines ...
Однако, если бы мы хотели получить доступ к этому серверу из внешнего мира, какой IP-адрес мы бы использовали? Единственный IP-адрес, который мы могли бы знать, - это адрес внешнего интерфейса хостаeth0:
curl 172.16.0.2:5000
curl: (7) Failed to connect to 172.16.0.2 port 5000 after 0 ms: Connection refused
Таким образом, нам нужно найти способ пересылать любые пакеты, поступающие на порт 5000 в eth0 интерфейсе хоста, в 172.18.0.10:5000 пункт назначения. Или, другими словами, нам нужно опубликовать порт контейнера 5000 в eth0 интерфейсе хоста. Еще раз, iptables приходят на помощь!
Публикацию портов для внешнего трафика можно выполнить с помощью следующей команды (из корневого пространства имен):
iptables -t nat -A PREROUTING \ -d 172.16.0.2 -p tcp -m tcp --dport 5000 \ -j DNAT --to-destination 172.18.0.10:5000
Публикация для локального трафика выглядит немного иначе (поскольку она не проходит цепочку предварительной маршрутизации):
iptables -t nat -A OUTPUT \ -d 172.16.0.2 -p tcp -m tcp --dport 5000 \ -j DNAT --to-destination 172.18.0.10:5000
Кроме того, нам необходимо включить iptables, перехватывающие трафик по мостовым сетям:
modprobe br_netfilter
Время тестирования!
curl 172.16.0.2:5000
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> ... omitted lines ...
Идеально! Вы хорошо подготовлены к следующему испытанию!
Понимание типов сетей Docker
Хорошо, что мы можем сделать со всеми этими бесполезными знаниями?
Например, мы могли бы попытаться понять некоторые из сетевых режимов Docker!
Давайте начнем с --network host режима. Используя Docker playground, попробуйте сравнить результаты следующих команд:
ip link list # from the Docker host
...против
docker run -it --rm --network host alpine ip link list
Сюрприз, сюрприз, они совершенно одинаковые! Т.е. в режиме host Docker просто не использует изоляцию сетевого пространства имен, а контейнеры работают в корневом пространстве имен сети и совместно используют сетевой контекст с хост-машиной.
Следующий режим для проверки - --network none. Выходные данные docker run -it --rm --network none alpine ip link команды покажут только один сетевой интерфейс с обратной связью. Это соответствует наблюдениям, которые мы сделали сразу после создания нового сетевого пространства имен в начале нашего путешествия.
И последнее, но не менее важное: --network bridge (режим по умолчанию). Что ж, это именно то, что мы пытались воспроизвести во всем этом руководстве!
Кроме того, многие дистрибутивы Kubernetes также используют bridge сеть для соединения модулей, работающих на одном узле. Итак, понимание того, как это работает, является хорошей отправной точкой для погружения в высокоуровневые CNI Kubernetes, такие как Flannel или Calico.
Заключение
Сегодня мы узнали, как виртуализировать сетевые среды, подключить несколько контейнеров Linux с помощью veth пар и устройств Linux bridge, и даже попытались настроить IP-маршрутизацию и NAT, чтобы обеспечить связь между контейнерами и внешним миром. Самое главное, мы попытались соединить точки между используемыми методами и сетевыми режимами Docker, надеюсь, немного прояснив их. Эти знания помогут вам стать опытным пользователем Docker, а также заложат хорошую основу для понимания высокоуровневых сетевых концепций, используемых в Kubernetes. Удачи вам!
Материалы, использованные при написании этой статьи
⭐ Linux Bridge - часть 1 от Хэчао Ли (и более техническая часть 2)
Отслеживание пути сетевого трафика в Kubernetes - как Kubernetes строит свою сеть поверх контейнеров.
