Мотивация написания статьи
Когда люди задумываются о профессии data scientist-а, они в первую очередь вспоминают нейронные сети, которые создают красивые картинки или ведут с человеком псевдоосмысленные диалоги. Существует огромное количество материалов посвященных такого рода моделям, и они безусловно крайне интересны любому человеку, увлеченному анализом данных. Тем не менее, фактически только небольшая часть data scientist-ов занимается подобными моделями, поскольку внедрение их не может в большинстве случаев принести существенной прибыли, а data scientist это достаточно высокооплачиваемая профессия. При этом существенная часть специалистов работает в банковской сфере, основными моделями которой (порядка 80-90% от общего числа моделей) являются модели PD (probability of default), отвечающие на фундаментальный вопрос банков: каковая вероятность того, что заемщик не вернет кредит. Информации по данным моделям, обзорных статей, описания подводных камней и т.п. достаточно мало и начинающий специалист может столкнуться с настоящим информационным голодом и даже провалить собеседование из-за незнания элементарной терминологии. Именно этот информационный пробел мне хотелось бы заполнить данной статьей. За время работы в банковской сфере мне удалось поучаствовать в разработке нескольких десятков моделей данного класса, и я хотел бы сосредоточится не на конкретной технике моделирования (она может быть разной в каждом конкретном случае), а на практических аспектах разработки и подводных камнях, которые удивили меня в свое время.
Большое количество data scientist-ов работает или будет работать в банках и создавать модели PD, при этом информации по данным моделям в интернете достаточно мало. Хотелось бы посвятить эту статью практическим аспектам разработки таких моделей.
Определение модели PD
В первую очередь следует определить, что такое собственно дефолт и какое именно событие мы пытаемся предсказать, вкратце:
Дефолт - невыполнение договора займа, то есть неоплата своевременно процентов или основного долга.
Следует понимать, что дефолт во��можен теоретически по любым обязательствам, т.е. даже муниципалитет, страна, любая транснациональная корпорация могут допустить дефолт и поэтому невозможно дать деньги в долг, не принимая во внимания тот факт, что есть вероятность дефолта по данным обязательствам. Поскольку выдача денег в долг — это основной бизнес банков (в целом они берут депозиты под небольшой процент с правом вкладчика забрать вклад в любой момент и выдают с наценкой, но на длительный срок, т.е. превращают короткие деньги в длинные), то модели PD это их основные модели (порядка 80-90% от общего числа моделей – экспертная оценка). Такие модели создаются отдельно для каждого сектора, региона, кредитного продукта и постоянно обновляются, чтобы отражать текущую ситуацию, таким образом у data scientist-ов всегда есть работа ?.
В целом поведение каждого заемщика описывается тремя связными моделями, которые имеет смысл рассматривать в совокупности:
PD – Probability of Default
LGD – Loss Given Default
EAD – Exposure at Default
Так, например, по потребительскому кредиту PD = 5%, LGD = 80% (т.е. ожидаем, что в случае дефолта удастся вернуть только 20% от выданной суммы), EAD = 1 000 000 рублей (это сумма под риском, т.е. сколько денег все еще находится в пользовании заемщика, сумма долга). Казалось бы, моделей LGD и EAD столько же сколько и моделей PD, но на самом деле они не являются полноценными моделями. LGD зачастую достаточно сложно моделировать (т.к. в целом данных меньше – это только заемщики вышедшие в дефолт, а качество данных ниже) и зачастую она определяется стоимость залога (например, при ипотечном кредите), если залога нет то часто принимается в виде константы или строится обобщенная модель для нескольких секторов/продуктов и т.п. EAD в большинстве случаев просто равна непогашенной части долга, модели имеет смысл строить только в случае открытых кредитных линий и т.п.
Таким образом, основная модель, описывающая поведение заемщика — это модель PD.
Целевая переменная
Давайте постараемся разобраться в том, что такое дефолт. Казалось бы, это простой вопрос: дефолт = банкротство. Но на самом деле, зачастую формальное юридическое банкротство может произойти (а может вообще не произойти) через несколько лет после того, как заемщик перестал выполнять свои обязательства. Фактически по каждому виду заемщиков существует множество критериев дефолта, и сложные логические правила, которые позволяют говорит о том, что заемщик вошел в дефолт и возможно вышел из дефолта. Фактически таких критериев и правил может быть несколько сотен или даже тысяч (sic!). И в них придется разбираться (хотя бы в самых основных). В частности, во многих случаях моделисту необходимо будет самостоятельно построить целевую переменную.
• т.е. мы ожидаем увидеть
Заемщик 1 | 0 |
Заемщик 2 | 1 |
Заемщик 3 | 1 |
Заемщик 4 | 0 |
где 1 – дефолт, 0 – отсутствие дефолта
• а фактически мы видим
Заемщик 1 | Критерий 1 | 01.08.2023 | 03.08.2023 |
Заемщик 2 | Критерий 1 | 04.09.2023 | |
Заемщик 3 | Критерий 2 | 01.09.2007 | |
Заемщик 4 | Критерий 457 | 04.07.2022 | 04.08.2023 |
т.е. такой-то критерий начал выполнятся по такому-то заемщику в такой день и перестал (или не перестал) выполняться в другой день.
Data scientist-у во многих случаях придется самостоятельно построить целевую переменную на дату отсечения (cutoff date) с определенным горизонтом по имеющимся критериям дефолта.
Критерии дефолта
Давайте рассмотрим, как��е именно бывают критерии дефолта. К самым явным можно отнести:
Просрочка 90+
Банкротство
Ущерб обеспечению
Дефолт по иным кредитным обязательствам
Просрочка 60+ с дополнительными условиями
Основным критерием в современном банкинге можно считать критерий просрочка 90+ (90-days past due). Это критерий упоминается в Basel II, и существуют попытки построить модели на этом единственно критерии. Следует, однако, понимать, что бывают сложные ситуации, когда просрочка отсутствует, но компания проходит через процедуру банкротства или когда нанесен ущерб обеспечению (например, имущество уничтожено в результате пожара) или заемщик исправно платит ипотеку, но у него просрочка по потребительскому кредиту в том же банке и т.п. Во всех случаях, когда очевидно, что нормальных долгосрочных выплат по кредиту уже не будет, банку следует перестать на эти выплаты рассчитывать и начать процедуру принудительного взыскания (чем раньше начнет, тем больше шансов взыскать хоть что-нибудь).
“Просрочка 90+” это важный, но не единственный критерий дефолта.
Горизонт дефолта
Когда мы говорим про вероятность дефолта следует всегда принимать во внимание фактор времени, т.е. PD – это вероятность дефолта в течение какого срока недели, полугода, года, семи лет, до момента погашения? Стандартный ответ на этот вопрос это 1 год. таким образом в большинстве случаев PD – это вероятность дефолта в течение 1 года.
В целом считается, непосредственно после выдачи кредита дефолт произойти не может, т.к. у заемщика есть денежные средства, и он еще не успел их потрать. Так дефолт в течение полугода после выдачи рассматривается как один из критериев мошенничества (и такие события могут использоваться в соответствующей модели), т.е. кредит изначально брали без намерения его вернуть. В то же время обычный дефолт происходит как правило против воли заемщика в следствии неблагоприятных экономических обстоятельств, например, потери работы, падения прибыли, неудачных инвестиций и т.п. Таким образом, после выдачи кредита происходит его вызревание.

Если мы берем когорту заемщиков, получивших кредит в течение одного месяца, чтобы выяснить уровень дефолтов (DR – default rate) через год, нам следует подождать один год, и мы на основании критериев дефолта сможем точно сказать был дефолт по каждому конкретному заемщику или нет и таким образом построить модель, которая сможет предсказывать подобные события по другим похожим заемщикам. В реальности, зачастую, возможности ждать год нет и приходится обходится имеющимся набором данных и проводить перекалибровку модели (это можно сделать, например, изменив свободный член в скоре логистической регрессии), т.е. модель построенную на одном горизонте превращать в модель, построенную на другом горизонте, если примерно известно какой уровень дефолтов ожидается на этом более длинном горизонте. Например, был запущен новый кредитный продукт и уже через 3 месяца после запуска продукта может быть необходимо перестроить модель, несмотря на то что фактически вызревания кредита еще не произошло и годичные данные еще не накоплены.
Необходимо понимать какой горизонт дефолта нужен для бизнеса и при необходимости уметь производить перекалибровку модели на нужный горизонт.
Факторы модели
Факторы (features) — это, наверное, основной драйвер успеха или неудачи в построении модели. Бывают случаи, когда входные данные содержат видео/изображения/запись голоса/расшифровку речи заемщика, но в подавляющем большинстве случаев в банках используются анкетные данные (tabular data) клиентов. Здесь приведен предельно краткий (в целом их может быть несколько тысяч) список возможных факторов модели. Обращаю ваше внимание, что всеми любимые (потому что их легко собрать) факторы вроде пола и возраста зачастую почти не имеют предсказательной силы, в то время как факторы, характеризующие финансовую дисциплину и надежность клиента могут иметь большое значение.
Слабые факторы
Пол
Возраст
Регион
Сильные факторы
Наличие просрочки в прошлом
Просрочки по налоговым выплатам
Число лет кредитной истории
Число лет на текущей работе
Тип кредита
Годовой доход
В целом извлечение информации из внутрибанковских и внешних баз данных и превращение их в значимые факторы могут занимать основную часть времени моделиста и быть основной частью его работы.
Коэффициент Джини и другие метрики качества
После построения модели необходимо каким-нибудь образом измерить ее качество (особенно способность модели к ранжированию клиентов, т.к. именно эта ха��актеристика модели важна для бизнеса), наиболее очевидным выбором кажутся такие метрики как precision и recall (и их производные F1, F2), так как они легко интерпретируются и имеют очевидный экономический смысл. Тем не менее, фактически их в банках почти не используют, поскольку для их определения нужно задать порог отсечения (threshold), после которого мы перестаем выдавать кредиты. В реальности этот порог зависит от большого числа факторов (сколько кредитов данного вида банк хочет выдать, какую долю рынка занять, на какую прибыль рассчитывает и т.п.) и определяется бизнес-подразделениями банка. Поэтому наибольшей популярностью пользуются метрики, не зависящие от порога непосредственно и, в частности, ROC AUC (вероятность того, что дефолтный заемщик будет иметь PD выше, чем не дефолтный) и ее производная Gini = 2 * ROC AUC – 1.
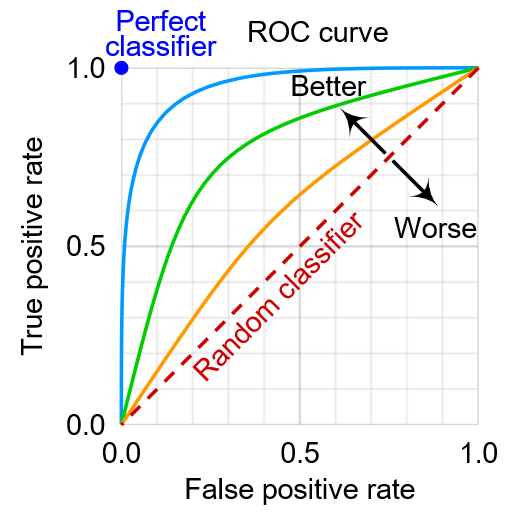
Коэффициент Джини (не путать с показателем степени расслоения общества) является стандартной метрикой качества оценивающей способность модели к ранжированию в банковской сфере и повсеместно используется для сравнения качества моделей между собой. В целом он ведет себя как корреляция, т.е. если Джини = 0, то нет связи между целевой переменной и PD, если Джини = 1, то все дефолтеры получают PD выше, чем заемщики исполняющие обязательства, если Джини = -1, то модель ранжирует заемщиков обратном порядке. В целом Джини меньше 30% говорит о плохом качестве модели, Джини больше 60% об очень хорошем качестве (конечно, в частных случаях пороги могут быть совсем другими). Аналогия между корреляцией и Джини более глубокая, чем представляется на первый взгляд, я исследовал эту связь в отдельной статье. Стоит также отметить, что если соединить данные по двум сегментом с разным уровнем дефолта в один (например, ипотека и потреб кредиты) и построить одну общую модель вместо двух отдельных, то Джини по общей модели будет выше, чем Джини по каждой из отдельных моделей (т.к. модель просто даст всем ипотечникам PD ниже, чем по потреб кредитам). Это помогает формально улучшить показатели, но фактически не приносит никакой экономической выгоды банку.
Основной метрикой оценивающей способности модели к ранжированию является коэффициент Джини, не зависящий от конкретного порога отсечения.
Логистическая регрессия и другие виды моделей
Один из основных вопросов, который задают молодые data scientist-ы приходящие в банковскую сферу состоит в том, почему там до сих пор так активно используется логистическая регрессия. Постараемся ответить на этот вопрос. Основным аргументом против логистической регрессии в пользу бустинга, случайного леса, нейронных сетей и т.п. считается качество моделей. Т.к. логистическая регрессии — это простейшая модель, она не может учесть всех нюансов взаимодействия данных между собой и потому ее производительность существенно ниже производительности более сложных моделей. Этот эффект действительно наблюдается во многих сферах моделирования, но не в банковской сфере. В целом если сделать предварительное преобразование факторов (т.е. трансформацию каждого отдельного фактора) и использовать грамотно подобранную регуляризацию, зачастую можно достичь почти такой же производительности логистической регрессии OOT (out of time), как у бустинга/нейронных сетей и т.п. Судя по всему, этот эффект связан с природой данных лежащих в основе моделей PD. В добавок к этому логистическая регрессия это стандартный вид модели, который достаточно легко объяснить начальству или регулятору, в то время как со сложными моделями могут возникнуть трудности и ненужные вопросы.
Логистическая регрессия | Бустинг (catboost), случайный лес, нейронные сети и т.п. |
Если совершить предварительное преобразование факторов, по качеству не сильно уступает более продвинутым вариантам | Лучшее качество предсказания |
Не склонна к переобучению | Можно легко переобучить |
Имеет очевидную интерпретацию | Интерпретация только с помощью shap и т.п. |
Легко документируется | Сложно документировать |
Легко объяснить регулятору | Сложно объяснить регулятору |
Причина использования «устаревшей» логистической регрессии в том, что правильно построенная регрессия на банковских данных имеет почти такую же производительность, как и более сложные модели, при этом ее гораздо легче интерпретировать и документировать.
Применение моделей PD
В целом существуют два основных вида моделей PD и соответственно два основных направления их применения аппликативные модели (application scoring) и поведенческие модели (behavior scoring).
Аппликативные модели PD могут, собственно говоря, не иметь PD, т.е. если используется логистическая регрессия, само логистическое преобразование не производится и используется непосредственно скор: линейная комбинация преобразованных факторов модели. В этом случае важна в первую очередь способность модели к ранжированию, т.е. к выстраиванию потенциальных клиентов в очередь от худшего к лучшему. Такие модели используются при принятии решения о выдаче кредита, т.е. устанавливается некоторый threshold и все клиентам ниже threshold-а кредит выдается, а тем, кто выше приходит отказ.
В случае поведенческих моделей кредит уже выдан и нам нужно предсказать поведение заемщика после его выдачи. При этом важен конкретный горизонт и предполагаемый уровень дефолтов. Для расчета резервов и капитала может использоваться более стабильная калибровка TTC (through the cycle – средний годовой DR за 5-7 лет – т.е. за время полного экономического цикла), для расчета текущей стоимости портфеля более актуальная PIT (point in time – среднегодовой DR на текущий момент за последние полгода/год). Следует понимать, что зачастую поведенческие и аппликативные модели могут ничем не отличаться кроме калибровки, т.е., по сути, одна модель (те же факторы, веса и т.п.) может использоваться сначала как аппликативная, потом PIT, потом TTC.
Аппликативные модели (application scoring)
Используются на этапе обращения заемщика в банк для принятия решения о выдаче кредита
Может существовать в виде скоринга без каких-либо вероятностей
Поведенческие модели (behavior scoring)
Используется для учета возможного поведения заемщика после выдачи кредита
Может быть калибрована TTC (through the cycle – средний годовой DR за 5-7 лет) для расчета резервов и капитала или PIT (point in time – годовой DR на текущий момент рассчитанный за последние полгода/год) для расчета текущей стоимости портфеля и т.п.
Аппликативные модели используются для принятия решения о выдаче кредита и потому важная их способность к ранжированию, поведенческие модели используются для описания поведения клиента после выдачи.
Расчет резервов и капитала
Основное приложение поведенческих моделей — это расчет банковских резервов и капитала.
Резервы = ожидаемые потери = expected loss
Капитал = не ожидаемые потери = unexpected loss
Ожидаемые потери — это фактически математическое ожидание потерь по данному портфелю, они рассчитываются для каждого клиента по формуле EL = PD * LGD * EAD, а после этого суммируются. Согласно требованиям регулятора Банки обязаны формировать резервы под ожидаемые потери и хранить их на случай собственного дефолта. В случае дефолта по кредиту PDв формуле заменяется на 1 и объем резервов по нему резко возрастает.
Не ожидаемые потери — это квантиль возможных потерь банка по портфелю минус ожидаемые потери. Банки обязаны формировать капитал под не ожидаемые потери. В совокупности с резервами капитал позволяет с высокой вероятностью (0,999) покрыть возможные потери банка в случае его собственного банкротства и дает время (год) регулятору распродать его активы. Существует множество вариантов расчет капитала, одна из простейших формул:

Поведенческие модели используются для расчета капитала и резервов, которые банки обязаны формировать согласно требованиям регулятора.
Техническая сторона вопроса
Следует упомянуть, что в достаточно стандартной ситуации при создании розничной модели мы можем иметь 10 млн. строк и порядка 2000 столбцов (факторов), файл такого размера зачастую невозможно эффективно обрабатывать одним куском на одном компьютере. В этом случае можно выгружать только часть выборки (например, все дефолты и только 5% не дефолтов), но даже в этом случае объем может быть слишком велик. Поэтому может возникнуть необходимость выгружать данные кусками на различные компьютеры (nodes), контейнеры (pods) и оркестратор (k8s). Одно из возможных решений GCP (Google Cloud Platform). Следует быть готовы к тому, что выгрузка факторов, их преобразование, обучение модели может занять несколько дней и даже недель.
При создании моделей (особенно розничных) нужно быть знакомым с технологиями работы с большими объемами данных.
Примеры моделей PD
Ниже приведены несколько примеров моделей PD. В целом если банк ведет бизнес в разных странах для каждой страны стараются строить свой собственный набор моделей (т.к. там другой набор юридических ограничений, условий ведения бизнеса и т.п.) Модели вытекают из кредитного процесса, поэтому модели по разным кредитным продуктам будут существенно отличаться (так данные доступные для ипотеки могут быть недоступны при POS кредитовании и т.п.). Разные модели соответствуют разным сегментам, так модели по среднему и малому бизнесу будут существенно отличаться. У большинства банков данных по среднему бизнесу может быть крайне мало для построения полноценной модели. Особняком стоят модели по сегментам, где в принципе не было дефолтов (крупные компании, муниципалитеты и т.п.) Зачастую здесь могут помочь кредитные рейтинги (это в целом тот же скор балл, что используется в моделях PD) или курсы облигаций (превышение YTM над КБД). При отсутствии данных по сегменту можно стараться использовать данные по похожему сегменту с определенными поправками.
Модель PD средний бизнес
Модель PD малый бизнес
Модель PD муниципалитет
Модель PD автокредит
Модель PD ритейл странах Х
Модель PD ипотека
Существует множество различных сегментов требующих построения своих моделей PD, при недостатке данных можно с осторожностью стараться использовать данные похожих сегментов, кредитные рейтинги, курсы облигаций и т.п.
Заключение
Работа в банке и моделирование PD может показаться занятием скучным заполненным кучей непонятных терминов и бумажной отчетностью, но в этой работе есть много увлекательных моментов (помимо оплаты). Есть существенная творческая составляющая, возможность создать модели, которые непосредственно влияют на судьбы миллионов людей и принимаю решения на уровне недоступном человеку. Удачи вам в вашей работе и спасибо что прочитали!
