Аннотация
В данной статье рассматривается влияние бакетизации на мощность статистических критериев в условиях различных распределений данных и при разном объеме выборки. Особое внимание уделено зависимости мощности критерия от количества бакетов и размера выборки. Исследование предоставляет важные выводы для проектирования и анализа A/B тестирования и других форм экспериментальных исследований.
Введение
В А/В экспериментах часто применяется метод бакетизации для оптимизации вычислений. Бакетизация предполагает разделение выборки на несколько групп (бакетов), внутри которых данные обрабатываются отдельно. В данной работе исследуется, как бакетизация влияет на мощность статистических критериев, используемых для анализа результатов экспериментов.
Методология
Бакетизация — это процесс разделения общей выборки случайным образом на несколько подгрупп (buckets), которые затем анализируются отдельно. Этот метод широко используется в статистических исследованиях, особенно в A/B тестировании.
Что часто выделяют в плюсах бакетизации?
ПРИМЕНЕНИЕ БАКЕТИЗАЦИИ:
Уменьшение влияния выбросов: Разделяя общую выборку на множество меньших групп, можно уменьшить влияние аномальных значений в каждой группе, что делает результаты теста более стабильными и надежными.
Улучшение оценки эффектов: Бакетизация позволяет точнее оценить эффекты введенных изменений, поскольку сравнение проводится внутри более однородных и сопоставимых групп.
Контроль над гетерогенностью данных: Разделение выборки на группы помогает контролировать гетерогенность данных, например, когда участники имеют различный демографический или географический фон.
КАК ИСПОЛЬЗОВАТЬ БАКЕТИЗАЦИЮ:
Определение размера бакета: Необходимо определить оптимальное количество и размер бакетов. Слишком маленькое количество бакетов может не обеспечить достаточного контроля над вариативностью, в то время как слишком большое количество может привести к избыточной сегментации и потере статистической мощности.
Рандомизация: Участники должны быть случайным образом распределены по бакетам для минимизации любых систематических ошибок и обеспечения сопоставимости групп.
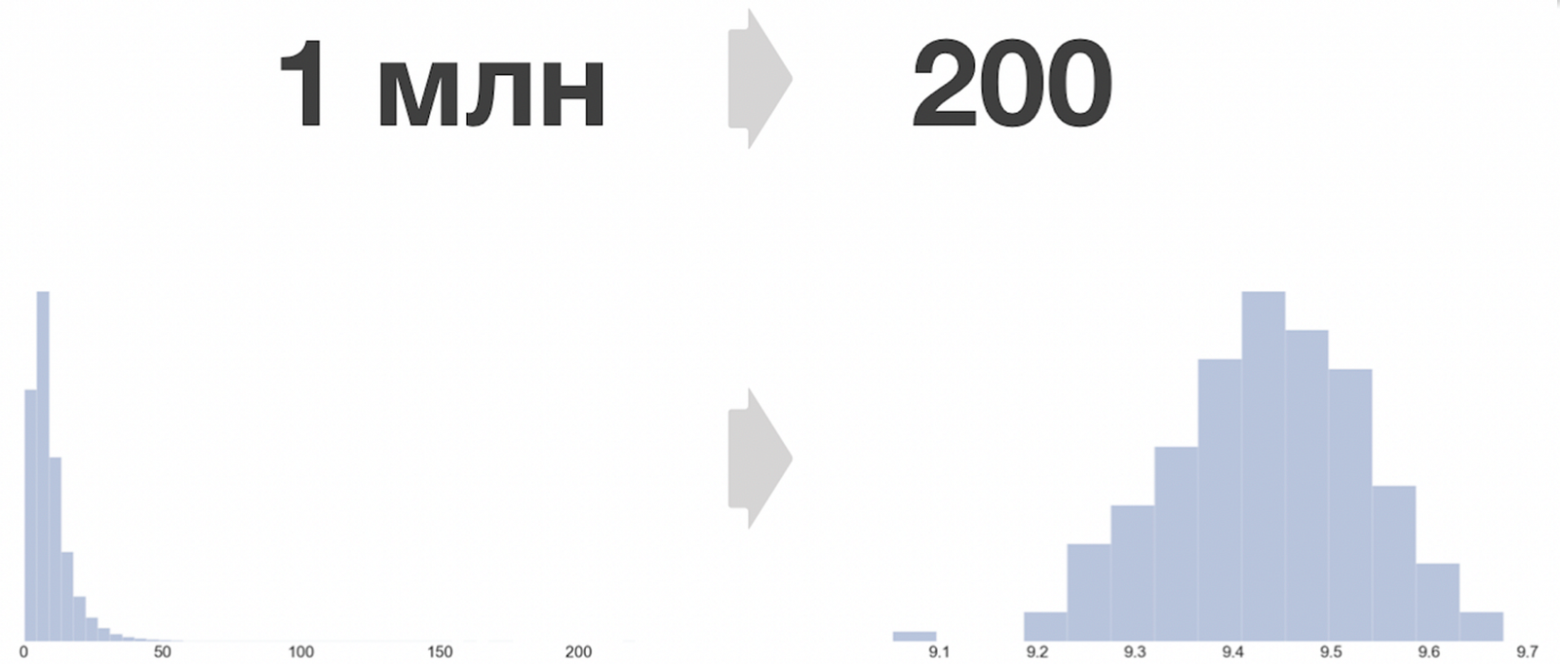
Анализ данных: При бакетизации делается переход в наблюдениях от пользователей в бакеты. Получается, из миллионов наблюдений идет переход к тысячам наблюдений.
А теперь к данному исследованию
Для анализа использовались синтетические данные, сгенерированные из различных распределений. Мощность критериев оценивалась в трех различных условиях:
С использованием и без использования бакетизации.
При изменении количества бакетов с фиксированным числом пользователей.
При изменении числа пользователей с фиксированным количеством бакетов.
Для ускорения вычислений использовалось распараллеливание.
Какие критерии использовались
Критерий Стьюдента (с использованием дельта-метода при бакетизации)
def t_test_deltamethod(x_0: np.array, y_0: np.array, x_1: np.array, y_1: np.array) -> float: n_0 = y_0.shape[0] n_1 = y_1.shape[0] mean_x_0, var_x_0 = np.mean(x_0), np.var(x_0) mean_x_1, var_x_1 = np.mean(x_1), np.var(x_1) mean_y_0, var_y_0 = np.mean(y_0), np.var(y_0) mean_y_1, var_y_1 = np.mean(y_1), np.var(y_1) cov_0 = np.mean((x_0 - mean_x_0.reshape(-1, )) * (y_0 - mean_y_0.reshape(-1, ))) cov_1 = np.mean((x_1 - mean_x_1.reshape(-1, )) * (y_1 - mean_y_1.reshape(-1, ))) var_0 = var_x_0 / mean_y_0 ** 2 + var_y_0 * mean_x_0 ** 2 / mean_y_0 ** 4 - 2 * mean_x_0 / mean_y_0 ** 3 * cov_0 var_1 = var_x_1 / mean_y_1 ** 2 + var_y_1 * mean_x_1 ** 2 / mean_y_1 ** 4 - 2 * mean_x_1 / mean_y_1 ** 3 * cov_1 rto_0 = np.sum(x_0) / np.sum(y_0) rto_1 = np.sum(x_1) / np.sum(y_1) statistic = (rto_1 - rto_0) / np.sqrt(var_0 / n_0 + var_1 / n_1) pvalue = 2 * np.minimum(stats.norm(0, 1).cdf(statistic), 1 - stats.norm(0, 1).cdf(statistic)) return statistic, pvalue
Результаты
В этом разделе представлены ключевые результаты исследования, целью которого было оценить влияние бакетизации на мощность статистических критериев при различных условиях эксперимента. Результаты сгруппированы по трем основным направлениям: влияние использования бакетизации, влияние количества бакетов и влияние размера выборки на мощность критериев. Каждый раздел сопровождается соответствующими графиками, которые иллюстрируют наблюдаемые тенденции и статистические выводы.
Какие данные использовались:
В рамках этой работы были выбраны два разных распределения: нормальное и логнормальное.
Причины выбора таких распределений:
Нормальное распределение было выбрано, чтобы сравнивать сравнимое: после бакетизации плотность распределения стремится к нормальному.
Логнормальное распределение было выбрано, чтобы приблизить данные к реальным, потому что большинство метрик имеет логнормальную плотность распределения.
Для нормального распределения использовались параметры: среднее = 50, дисперсия = 10.

Для логнормального распределения использовались параметры: среднее = log(50), дисперсия = 0.75.
, дисперсия = 0.75")
Результаты 1: Мощность критерия с применением бакетизации и без
Параметры эксперимента:
num_users = 1000000 num_buckets = 10000 alpha = .05 lifts = np.asarray([1., 1.0001, 1.0002, 1.0005, 1.001, 1.002]) num_simulations = 1000
Мощность критерия оценивалась в двух группах: с использованием бакетизации и без её применения. Результаты показывают, что мощность критерия остается почти неизменной независимо от применения бакетизации.
Для нормального распределения
")
Зависимость мощности критерия от лифта (относительное разница) import numpy as np from scipy.stats import ttest_ind from concurrent.futures import ThreadPoolExecutor, as_completed from tqdm import tqdm # Настройка параметров симуляции num_users = 1000000 num_buckets = 10000 mean_control = 50 std_dev = 10 alpha = .05 lifts = np.asarray([1., 1.0001, 1.0002, 1.0005, 1.001, 1.002]) num_simulations = 1000 def run_simulation(lift): mean_treatment = mean_control * lift control_group = np.random.normal(mean_control, std_dev, num_users) treatment_group = np.random.normal(mean_treatment, std_dev, num_users) bucket_indices = np.random.randint(0, num_buckets, num_users) bucket_sums_control = np.bincount(bucket_indices, weights=control_group, minlength=num_buckets) bucket_sums_treatment = np.bincount(bucket_indices, weights=treatment_group, minlength=num_buckets) bucket_counts = np.bincount(bucket_indices, minlength=num_buckets) bucket_means_control = bucket_sums_control / bucket_counts bucket_means_treatment = bucket_sums_treatment / bucket_counts t_stat_ind, p_value_ind = ttest_ind(treatment_group, control_group) t_stat_agg, p_value_agg = t_test_deltamethod(bucket_sums_control, bucket_counts, bucket_sums_treatment, bucket_counts) return (p_value_ind <= alpha, p_value_agg <= alpha) # Параллельное выполнение с визуализацией прогресса results = [] with ThreadPoolExecutor(max_workers=4) as executor: future_to_lift = {executor.submit(run_simulation, lift): lift for lift in lifts for _ in range(num_simulations)} results = [] for future in tqdm(as_completed(future_to_lift), total=len(future_to_lift), desc='Simulating'): results.append(future.result()) # Обработка результатов TPR = {lift: 0 for lift in lifts} TPR_b = {lift: 0 for lift in lifts} for result, lift in zip(results, future_to_lift.values()): TPR[lift] += result[0] TPR_b[lift] += result[1] for lift in lifts: TPR[lift] /= num_simulations TPR_b[lift] /= num_simulations fig = go.Figure() fig.add_trace(go.Scatter(x=(np.asarray(list(TPR.keys()))-1)*100, y=list(TPR.values()), mode='lines+markers', name='Individual Data')) fig.add_trace(go.Scatter(x=(np.asarray(list(TPR.keys()))-1)*100, y=list(TPR_b.values()), mode='lines+markers', name='Aggregated Data')) fig.update_layout(title='TPR Individual Data vs Aggregated Data (normal distribution)', xaxis_title='Lift %', yaxis_title='Power', height=600, width=1000, template='plotly_white') fig.show()Для логнормального распределения:
")
Зависимость мощности критерия от лифта (относительное разница) ... num_users = 1000000 num_buckets = 10000 mean_control = np.log(50) std_dev = .75 alpha = .05 lifts = np.asarray([1., 1.0001, 1.0002, 1.0005, 1.001, 1.002]) num_simulations = 1000 def run_simulation(lift): mean_treatment = mean_control * lift control_group = np.random.lognormal(mean_control, std_dev, num_users) treatment_group = np.random.lognormal(mean_treatment, std_dev, num_users) ...
Результаты 2: Влияние количества бакетов на мощность критерия
Параметры эксперимента:
num_users = 100000 # Общее число пользователей num_simulations = 500 # Количество симуляций для каждого количества бакетов mean_control = np.log(50) # Среднее значение логнормального распределения sigma = 0.75 # Стандартное отклонение логнормального распределения alpha = 0.05 # Уровень значимости lift = 1.001 # Значение lift # Диапазон количества бакетов для тестирования bucket_ranges = [1, 5, 10, 20, 30, 50, 70, 100, 500, 1000, 2000, 3000, 5000, 7000, 10000, 11000, 12000, 15000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000]
Анализ показал, что изменение количества бакетов не оказывает значительного влияния на мощность критерия при фиксированном числе пользователей. Однако было замечено, что с уменьшением числа бакетов увеличивается вариативность результатов. Вариативность мощности связана с небольшой выборкой наблюдений (100к) из-за большой вычислительной нагрузкой для локального компьютера.

num_users = 100000 # Общее число пользователей num_simulations = 500 # Количество симуляций для каждого количества бакетов mean_control = np.log(50) # Среднее значение логнормального распределения sigma = 0.75 # Стандартное отклонение логнормального распределения alpha = 0.05 # Уровень значимости lift = 1.001 # Значение lift # Диапазон количества бакетов для тестирования bucket_ranges = [1, 5, 10, 20, 30, 50, 70, 100, 500, 1000, 2000, 3000, 5000, 7000, 10000, 11000, 12000, 15000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000] def run_simulation(num_buckets): power_individual = 0 power_aggregated = 0 for _ in range(num_simulations): # Генерация данных mean_treatment = mean_control * lift control_group = np.random.lognormal(mean_control, std_dev, num_users) treatment_group = np.random.lognormal(mean_treatment, std_dev, num_users) # Бакетизация bucket_indices = np.random.randint(0, num_buckets, num_users) bucket_sums_control = np.bincount(bucket_indices, weights=control_group, minlength=num_buckets) bucket_sums_treatment = np.bincount(bucket_indices, weights=treatment_group, minlength=num_buckets) bucket_counts = np.bincount(bucket_indices, minlength=num_buckets) # T-тесты _, p_value_ind = ttest_ind(treatment_group, control_group) _, p_value_agg = t_test_deltamethod(bucket_sums_control, bucket_counts, bucket_sums_treatment, bucket_counts) # Обновление мощности if p_value_ind <= alpha: power_individual += 1 if p_value_agg <= alpha: power_aggregated += 1 return num_buckets, power_individual / num_simulations, power_aggregated / num_simulations # Выполнение симуляций с распараллеливанием results = [] with ThreadPoolExecutor(max_workers=4) as executor: futures = {executor.submit(run_simulation, num_buckets): num_buckets for num_buckets in bucket_ranges} for future in tqdm(as_completed(futures), total=len(futures), desc="Simulating"): result = future.result() results.append(result) print(f"Num Buckets: {result[0]}, Power Individual: {result[1]}, Power Aggregated: {result[2]}") # Сортировка результатов по количеству бакетов для вывода print(results.sort(key=lambda x: x[0])) num_buckets = [result[0] for result in results] power_individual = [result[1] for result in results] power_aggregated = [result[2] for result in results] fig = go.Figure() fig.add_trace(go.Scatter(x=num_buckets, y=power_individual, mode='lines+markers', name='Individual Data')) fig.add_trace(go.Scatter(x=num_buckets, y=power_aggregated, mode='lines+markers', name='Aggregated Data')) fig.update_layout( title='Statistical Power vs Number of Buckets', xaxis_title='Number of Buckets', yaxis_title='Power', height=600, template='plotly_white' ) fig.show()
Результаты 3: Влияние размера выборки на мощность критерия
Параметры эксперимента:
num_buckets = 10000 num_simulations = 1000 # Количество симуляций для каждого количества бакетов mean_control = np.log(50) # Среднее значение логнормального распределения sigma = 0.75 # Стандартное отклонение логнормального распределения alpha = 0.05 # Уровень значимости lift = 1.001 # Значение lift user_ranges = [10000, 100000, 500000, 1000000]
Результаты показывают, что мощность критерия увеличивается с ростом числа пользователей в каждом бакете. Это подчёркивает значимость адекватного размера выборки для повышения эффективности статистического анализа.

num_buckets = 10000 num_simulations = 1000 # Количество симуляций для каждого количества бакетов mean_control = np.log(50) # Среднее значение логнормального распределения sigma = 0.75 # Стандартное отклонение логнормального распределения alpha = 0.05 # Уровень значимости lift = 1.001 # Значение lift user_ranges = [10000, 100000, 500000, 1000000] def run_simulation(num_users): power_individual = 0 power_aggregated = 0 for _ in range(num_simulations): # Генерация данных mean_treatment = mean_control * lift control_group = np.random.lognormal(mean_control, std_dev, num_users) treatment_group = np.random.lognormal(mean_treatment, std_dev, num_users) # Бакетизация bucket_indices = np.random.randint(0, num_buckets, num_users) bucket_sums_control = np.bincount(bucket_indices, weights=control_group, minlength=num_buckets) bucket_sums_treatment = np.bincount(bucket_indices, weights=treatment_group, minlength=num_buckets) bucket_counts = np.bincount(bucket_indices, minlength=num_buckets) # T-тесты _, p_value_ind = ttest_ind(treatment_group, control_group) _, p_value_agg = t_test_deltamethod(bucket_sums_control, bucket_counts, bucket_sums_treatment, bucket_counts) # Обновление мощности if p_value_ind <= alpha: power_individual += 1 if p_value_agg <= alpha: power_aggregated += 1 print(power_individual) return num_users, power_individual / num_simulations, power_aggregated / num_simulations results = [] with ThreadPoolExecutor(max_workers=4) as executor: futures = {executor.submit(run_simulation, num_users): num_buckets for num_users in user_ranges} for future in tqdm(as_completed(futures), total=len(futures), desc="Simulating"): result = future.result() results.append(result) print(f"Num Users: {result[0]}, Power Individual: {result[1]}, Power Aggregated: {result[2]}") print(results.sort(key=lambda x: x[0])) num_users = [result[0] for result in results] power_individual = [result[1] for result in results] power_aggregated = [result[2] for result in results] fig = go.Figure() fig.add_trace(go.Scatter(x=num_users, y=power_individual, mode='lines+markers', name='Individual Data')) fig.add_trace(go.Scatter(x=num_users, y=power_aggregated, mode='lines+markers', name='Aggregated Data')) # Добавление заголовка и меток осей fig.update_layout( title='Statistical Power vs Number of Users for 10k buckets', xaxis_title='Number of Users', yaxis_title='Power', height=600, template='plotly_white' ) fig.show()
Исследование показало следующее:
Мощность критерия с бакетизацией и без: Мощность критериев была почти одинаковой вне зависимости от применения бакетизации, что указывает на незначительное влияние бакетизации на общую эффективность статистических тестов при данном распределении данных.
Зависимость мощности от количества бакетов: Мощность критериев оказалась почти не зависимой от количества бакетов при фиксированном числе пользователей. Однако, чем меньше бакетов, тем выше была вариативность между результатами с бакетизацией и без неё.
Зависимость мощности от количества пользователей: Наблюдалось увеличение мощности с ростом числа пользователей при неизменном количестве бакетов. Этот результат подчеркивает важность достаточного размера выборки для повышения эффективности статистических критериев.
Заключение
Возможно, для других распределений результаты будут несколько отличаться. Это можно сделать следующим шагом.
Использование бакетизации оправдано. Единственное, не стоит выбирать меньше 1000 бакетов, потому что дисперсия разницы мощности с бакетизацией и без растет с уменьшением кол-ва бакетов. Мощность критериев критически не отличается, чтобы исключать бакетизацию из инфраструктуры.
Про выигрыш в скорости вычислений можно почитать в отдельной статье.
