Почему после распараллеливания выполнение вашей программы может замедлиться вдвое?
Почему после создания потока перестает работать Ctrl-C?
Представляю вашему вниманию перевод статьи David Beazley «Inside the Python GIL». В ней рассматриваются некоторые тонкости работы потоков и обработки сигналов в Python.
Как известно, в Python используется глобальная блокировка интерпретатора (Global Interpreter Lock — GIL), накладывающая некоторые ограничения на потоки. А именно, нельзя использовать несколько процессоров одновременно. Это избитая тема для холиваров о Python, наряду с tail-call оптимизацией, lambda, whitespace и т. д.
Я не испытываю глубокого возмущения по поводу использования GIL в Python. Но для параллельных вычислений с использованием нескольких CPU я предпочитаю передачу сообщений и межпроцессное взимодействие использованию потоков. Однако меня интересует неожиданное поведение GIL на многоядерных процессорах.
Рассмотрим тривиальную CPU-зависимую функцию (т.е. функцию, скорость выполнения которой зависит преимущественно от производительности процессора):
Сначала запустим ее дважды по очереди:
Теперь запустим ее параллельно в двух потоках:
Следующие результаты получены на двухъядерном MacBook:
Мне не нравятся необъяснимые магические явления. В рамках проекта, запущенного мной в мае, я начал разбираться в реализации GIL, чтобы понять, почему я получил такие результаты. Я прошел все этапы, начиная с Python-скриптов и заканчивая исходным кодом библиотеки pthreads (да, возможно, мне стоит выходить на улицу чаще). Итак, давайте разберемся по порядку.
Python threads — это настоящие потоки (POSIX threads или Windows threads), полностью контролируемые ОС. Рассмотрим поточное выполнение в процессе интерпретатора Python (написанного на C). При создании поток просто выполняет метод run() объекта Thread или любую заданную функцию:
На самом деле происходит гораздо большее. Python создает маленькую структуру данных (PyThreadState), в которой указаны: текущий stack frame в коде Python, текущая глубина рекурсии, идентификатор потока, некоторая информация об исключениях. Структура занимает менее 100 байт. Затем запускается новый поток (pthread), в котором код на языке C вызывает PyEval_CallObject, который запускает то, что указано в Python callable.
Интерпретатор хранит в глобальной переменной указатель на текущий активный поток. Выполняемые действия всецело зависят от этой переменной:
В этом вся загвоздка: в любой момент может выполняться только один поток Python. Глобальная блокировка интерпретатора — GIL — тщательно контролирует выполнение тредов. GIL гарантирует каждому потоку эксклюзивный доступ к переменным интерпретатора (и соответствующие вызовы C-расширений работают правильно).
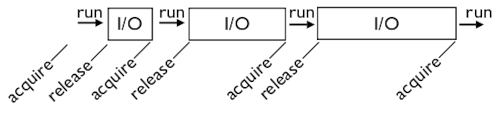
Принцип работы прост. Потоки удерживают GIL, пока выполняются. Однако они освобождают его при блокировании для операций ввода-вывода. Каждый раз, когда поток вынужден ждать, другие, готовые к выполнению, потоки используют свой шанс запуститься.
При работе с CPU-зависимыми потоками, которые никогда не производят операции ввода-вывода, интерпретатор периодически проводит проверку («the periodic check»).
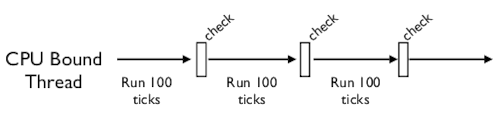
По умолчанию это происходит каждые 100 «тиков», но этот параметр можно изменить с помощью sys.setcheckinterval(). Интервал проверки — глобальный счетчик, абсолютно независимый от порядка переключения потоков.
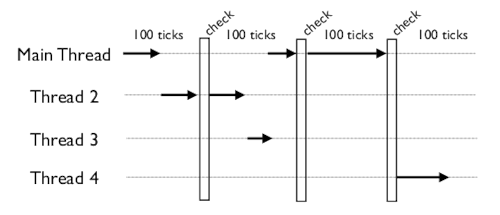
При периодической проверке в главном потоке запускаются обработчики сигналов, если таковые имеются. Затем GIL отключается и включается вновь. На этом этапе обеспечивается возможность переключения нескольких CPU-зависимых потоков (при кратком освобождении GIL другие треды имеют шанс на запуск).
Тики примерно соответствуют выполнению инструкций интерпретатора. Они не основываются на времени. Фактически, длинная операция может заблокировать всё:
Тики нельзя прервать, Ctrl-C в данном случае не остановит выполнение программы.
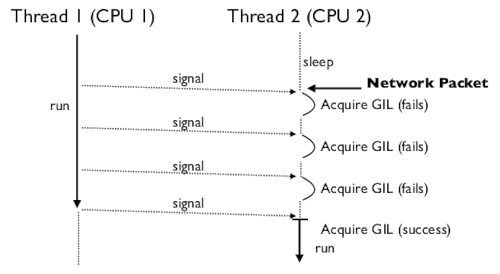
Давайте поговорим о Ctrl-C. Очень распространенная проблема заключается в том, что программа с несколькими потоками не может быть прервана с помощью keyboard interrupt. Это очень раздражает (вам придется использовать kill -9 в отдельном окне). (От переводчика: у меня получалось убивать такие программы по Ctrl+F4 в окне терминала.) Удивительно, почему Ctrl-C не работает?
Когда поступает сигнал, интерпретатор запускает «check» по��ле каждого тика, пока не запустится главный поток. Так как обработчики сигналов могут быть запущены только в главном потоке, интерпретатор часто выключает и включает GIL, пока не запустится главный поток.
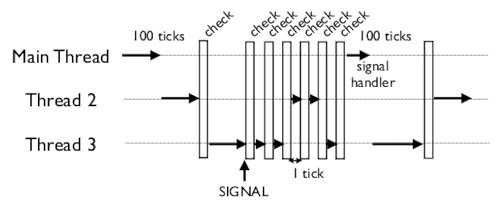
У Python нет средств для определения, какой поток должен запуститься следующим. Нет приоритетов, вытесняющей многозадачности, round-robin и т.п. Эта функция целиком возлагается на операционную систему. Это одна из причин странной работы сигналов: интерпретатор никак не может контроллировать запуск потоков, он просто переключает их как можно чаще, надеясь, что запустится главный поток.
Ctrl-C часто не срабатывает в многопоточных программах, потому что главный поток обычно заблокирован непрерываемым thread-join или lock. Пока он заблокирован, он не сможет запуститься. Как следствие, он не сможет выполнить обработчик сигнала.
В качестве дополнительного бонуса, интерпретатор остается в состоянии, где он пытается переключить поток после каждого тика. Мало того, что вы не можете прервать программу, она еще и работает медленнее.
GIL — это не обычный мьютекс. Это либо безымянный POSIX-семафор, либо условная переменная pthreads. Блокировка интерпретатора основана на отправке сигналов.
Переключение потоков таит в себе больше тонкостей, чем обычно думают программисты.
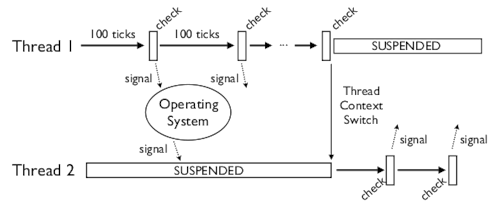
Задержка между отправкой сигнала и запуском потока может быть довольно существенной, это зависит от операционной системы. А она учитывает приоритет выполнения. При этом задачи, требующие выполнения операций ввода-вывода, имеют более высокий приоритет, чем CPU-зависимые. Если сигнал посылается потоку с низким приоритетом, а процессор занят более важными задачами, то этот поток не будет выполняться довольно долго.
В результате сигналов, которые посылает поток GIL, становится слишком много.
Каждые 100 тиков интерпретатор блокирует мьютекс, посылает сигнал в переменную или семафор процессу, который всё время этого ждет.
Измерим количество системных вызовов.
Для последовательного выполнения: 736 (Unix), 117 (Mac).
Для двух потоков: 1149 (Unix), 3,3 млн. (Mac).
Для двух потоков на двухъядерной системе: 1149 (Unix), 9,5 млн. (Mac).
На многоядерной системе CPU-зависимые процессы переключаются одновременно (на разных ядрах), в результате происходит борьба за GIL:
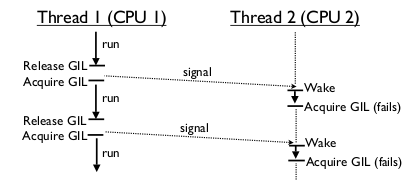
Ожидающий поток при этом может сделать сотни безуспешных попыток захватить GIL.
Мы видим, что происходит битва за две взаимоисключающие цели. Python просто хочет запускать не больше одного потока в один момент. А операционная система («Ооо, много ядер!») щедро переключает потоки, пытаясь извлечь максимальную выгоду из всех ядер.
Даже один CPU-зависимый поток порождает проблемы — он увеличивает время отклика I/O-зависимого потока.
Последний пример — причудливая форма проблемы смены приоритетов. CPU-зависимый процесс (с низким приоритетом) блокирует выполнение I/O-зависимого (с высоким приоритетом). Это происходит только на многоядерных процессорах, потому что I/O-поток не может проснуться достаточно быстро и заполучить GIL раньше CPU-зависимого.
Реализация GIL в Python за последние 10 лет почти не изменилась. Соответствующий код в Python 1.5.2 выглядит практически так же, как в Python 3.0. Я не знаю, было ли поведение GIL достаточно хорошо изучено (особенно на многоядерных процессорах). Полезнее удалить GIL вообще, чем изменять его. Мне кажется, этот предмет требует дальнейшего изучения. Если GIL остается с нами, стоит исправить его поведение.
Как же всё-таки избавиться от этой проблемы? У меня есть несколько смутных идей, но все они «сложные». Нужно, чтобы в Python появился свой собственный диспетчер потоков (или хотя бы механизм взаимодействовия с диспетчером ОС). Но это требует нетривиального взаимодействия между интерпретатором, планировщиком ОС, библиотекой потоков и, что самое страшное, модулями C-расширений.
Стоит ли оно того? Исправление поведения GIL сделало бы выполнение потоков (даже с GIL) более предсказуемым и менее требовательным к ресурсам. Возможно, улучшится производительность и уменьшится время отклика приложений. Надеюсь, при этом удастся избежать полного переписывания интерпретатора.
Оригинал был оформлен как презентация, поэтому мне пришлось немного изменить порядок повествования, чтобы статью было легче читать. Также я исключил трассировки работы интерпретатора — если вам интересно, посмотрите в оригинале.
Хабралюди, посоветуйте интересные английские статьи по Python, которые было бы хорошо перевести. У меня есть на примете пара статей, но хочется еще вариантов.
Почему после создания потока перестает работать Ctrl-C?
Представляю вашему вниманию перевод статьи David Beazley «Inside the Python GIL». В ней рассматриваются некоторые тонкости работы потоков и обработки сигналов в Python.
Вступление
Как известно, в Python используется глобальная блокировка интерпретатора (Global Interpreter Lock — GIL), накладывающая некоторые ограничения на потоки. А именно, нельзя использовать несколько процессоров одновременно. Это избитая тема для холиваров о Python, наряду с tail-call оптимизацией, lambda, whitespace и т. д.
Дисклеймер
Я не испытываю глубокого возмущения по поводу использования GIL в Python. Но для параллельных вычислений с использованием нескольких CPU я предпочитаю передачу сообщений и межпроцессное взимодействие использованию потоков. Однако меня интересует неожиданное поведение GIL на многоядерных процессорах.
Тест производительности
Рассмотрим тривиальную CPU-зависимую функцию (т.е. функцию, скорость выполнения которой зависит преимущественно от производительности процессора):
def count(n): while n > 0: n -= 1
Сначала запустим ее дважды по очереди:
count(100000000) count(100000000)
Теперь запустим ее параллельно в двух потоках:
t1 = Thread(target=count,args=(100000000,)) t1.start() t2 = Thread(target=count,args=(100000000,)) t2.start() t1.join(); t2.join()
Следующие результаты получены на двухъядерном MacBook:
- последовательный запуск — 24,6 с
- параллельный запуск — 45,5 с (почти в 2 раза медленнее!)
- параллельный запуск после отключения одного из ядер — 38,0 с
Мне не нравятся необъяснимые магические явления. В рамках проекта, запущенного мной в мае, я начал разбираться в реализации GIL, чтобы понять, почему я получил такие результаты. Я прошел все этапы, начиная с Python-скриптов и заканчивая исходным кодом библиотеки pthreads (да, возможно, мне стоит выходить на улицу чаще). Итак, давайте разберемся по порядку.
Подробнее о потоках
Python threads — это настоящие потоки (POSIX threads или Windows threads), полностью контролируемые ОС. Рассмотрим поточное выполнение в процессе интерпретатора Python (написанного на C). При создании поток просто выполняет метод run() объекта Thread или любую заданную функцию:
import time import threading class CountdownThread(threading.Thread): def __init__(self,count): threading.Thread.__init__(self) self.count = count → def run(self): while self.count > 0: print "Counting down", self.count self.count -= 1 time.sleep(5) return
На самом деле происходит гораздо большее. Python создает маленькую структуру данных (PyThreadState), в которой указаны: текущий stack frame в коде Python, текущая глубина рекурсии, идентификатор потока, некоторая информация об исключениях. Структура занимает менее 100 байт. Затем запускается новый поток (pthread), в котором код на языке C вызывает PyEval_CallObject, который запускает то, что указано в Python callable.
Интерпретатор хранит в глобальной переменной указатель на текущий активный поток. Выполняемые действия всецело зависят от этой переменной:
/* Python/pystate.c */ ... PyThreadState *_PyThreadState_Current = NULL;
Печально известный GIL
В этом вся загвоздка: в любой момент может выполняться только один поток Python. Глобальная блокировка интерпретатора — GIL — тщательно контролирует выполнение тредов. GIL гарантирует каждому потоку эксклюзивный доступ к переменным интерпретатора (и соответствующие вызовы C-расширений работают правильно).
Принцип работы прост. Потоки удерживают GIL, пока выполняются. Однако они освобождают его при блокировании для операций ввода-вывода. Каждый раз, когда поток вынужден ждать, другие, готовые к выполнению, потоки используют свой шанс запуститься.
При работе с CPU-зависимыми потоками, которые никогда не производят операции ввода-вывода, интерпретатор периодически проводит проверку («the periodic check»).
По умолчанию это происходит каждые 100 «тиков», но этот параметр можно изменить с помощью sys.setcheckinterval(). Интервал проверки — глобальный счетчик, абсолютно независимый от порядка переключения потоков.
При периодической проверке в главном потоке запускаются обработчики сигналов, если таковые имеются. Затем GIL отключается и включается вновь. На этом этапе обеспечивается возможность переключения нескольких CPU-зависимых потоков (при кратком освобождении GIL другие треды имеют шанс на запуск).
/* Python/ceval.c */ ... if (--_Py_Ticker < 0) { ... _Py_Ticker = _Py_CheckInterval; ... if (things_to_do) { if (Py_MakePendingCalls() < 0) { ... } } if (interpreter_lock) { /* даем шанс другому потоку */ ... PyThread_release_lock(interpreter_lock); /* сейчас могут запуститься другие потоки */ PyThread_acquire_lock(interpreter_lock, 1); ... }
Тики примерно соответствуют выполнению инструкций интерпретатора. Они не основываются на времени. Фактически, длинная операция может заблокировать всё:
>>> nums = xrange(100000000) >>> -1 in nums # 1 тик (6,6 с) False >>>
Тики нельзя прервать, Ctrl-C в данном случае не остановит выполнение программы.
Сигналы
Давайте поговорим о Ctrl-C. Очень распространенная проблема заключается в том, что программа с несколькими потоками не может быть прервана с помощью keyboard interrupt. Это очень раздражает (вам придется использовать kill -9 в отдельном окне). (От переводчика: у меня получалось убивать такие программы по Ctrl+F4 в окне терминала.) Удивительно, почему Ctrl-C не работает?
Когда поступает сигнал, интерпретатор запускает «check» по��ле каждого тика, пока не запустится главный поток. Так как обработчики сигналов могут быть запущены только в главном потоке, интерпретатор часто выключает и включает GIL, пока не запустится главный поток.
Планировщик потоков
У Python нет средств для определения, какой поток должен запуститься следующим. Нет приоритетов, вытесняющей многозадачности, round-robin и т.п. Эта функция целиком возлагается на операционную систему. Это одна из причин странной работы сигналов: интерпретатор никак не может контроллировать запуск потоков, он просто переключает их как можно чаще, надеясь, что запустится главный поток.
Ctrl-C часто не срабатывает в многопоточных программах, потому что главный поток обычно заблокирован непрерываемым thread-join или lock. Пока он заблокирован, он не сможет запуститься. Как следствие, он не сможет выполнить обработчик сигнала.
В качестве дополнительного бонуса, интерпретатор остается в состоянии, где он пытается переключить поток после каждого тика. Мало того, что вы не можете прервать программу, она еще и работает медленнее.
Реализация GIL
GIL — это не обычный мьютекс. Это либо безымянный POSIX-семафор, либо условная переменная pthreads. Блокировка интерпретатора основана на отправке сигналов.
- Чтобы включить GIL, проверить, свободен ли он. Если нет, ждать следующего сигнала.
- Чтобы выключить GIL, освободить его и послать сигнал.
Переключение потоков таит в себе больше тонкостей, чем обычно думают программисты.
Задержка между отправкой сигнала и запуском потока может быть довольно существенной, это зависит от операционной системы. А она учитывает приоритет выполнения. При этом задачи, требующие выполнения операций ввода-вывода, имеют более высокий приоритет, чем CPU-зависимые. Если сигнал посылается потоку с низким приоритетом, а процессор занят более важными задачами, то этот поток не будет выполняться довольно долго.
В результате сигналов, которые посылает поток GIL, становится слишком много.
Каждые 100 тиков интерпретатор блокирует мьютекс, посылает сигнал в переменную или семафор процессу, который всё время этого ждет.
Измерим количество системных вызовов.
Для последовательного выполнения: 736 (Unix), 117 (Mac).
Для двух потоков: 1149 (Unix), 3,3 млн. (Mac).
Для двух потоков на двухъядерной системе: 1149 (Unix), 9,5 млн. (Mac).
На многоядерной системе CPU-зависимые процессы переключаются одновременно (на разных ядрах), в результате происходит борьба за GIL:
Ожидающий поток при этом может сделать сотни безуспешных попыток захватить GIL.
Мы видим, что происходит битва за две взаимоисключающие цели. Python просто хочет запускать не больше одного потока в один момент. А операционная система («Ооо, много ядер!») щедро переключает потоки, пытаясь извлечь максимальную выгоду из всех ядер.
Даже один CPU-зависимый поток порождает проблемы — он увеличивает время отклика I/O-зависимого потока.
Последний пример — причудливая форма проблемы смены приоритетов. CPU-зависимый процесс (с низким приоритетом) блокирует выполнение I/O-зависимого (с высоким приоритетом). Это происходит только на многоядерных процессорах, потому что I/O-поток не может проснуться достаточно быстро и заполучить GIL раньше CPU-зависимого.
Заключение
Реализация GIL в Python за последние 10 лет почти не изменилась. Соответствующий код в Python 1.5.2 выглядит практически так же, как в Python 3.0. Я не знаю, было ли поведение GIL достаточно хорошо изучено (особенно на многоядерных процессорах). Полезнее удалить GIL вообще, чем изменять его. Мне кажется, этот предмет требует дальнейшего изучения. Если GIL остается с нами, стоит исправить его поведение.
Как же всё-таки избавиться от этой проблемы? У меня есть несколько смутных идей, но все они «сложные». Нужно, чтобы в Python появился свой собственный диспетчер потоков (или хотя бы механизм взаимодействовия с диспетчером ОС). Но это требует нетривиального взаимодействия между интерпретатором, планировщиком ОС, библиотекой потоков и, что самое страшное, модулями C-расширений.
Стоит ли оно того? Исправление поведения GIL сделало бы выполнение потоков (даже с GIL) более предсказуемым и менее требовательным к ресурсам. Возможно, улучшится производительность и уменьшится время отклика приложений. Надеюсь, при этом удастся избежать полного переписывания интерпретатора.
Послесловие от переводчика
Оригинал был оформлен как презентация, поэтому мне пришлось немного изменить порядок повествования, чтобы статью было легче читать. Также я исключил трассировки работы интерпретатора — если вам интересно, посмотрите в оригинале.
Хабралюди, посоветуйте интересные английские статьи по Python, которые было бы хорошо перевести. У меня есть на примете пара статей, но хочется еще вариантов.
