Comments 56
Интересная статья и с подключением. но я бы ещё куда-нибудь бы вывел стат-анализаторы и шаред код, который ютилсы и собственноручные экзепты ну и всякое такое на верхний уровень (ну или хотя бы об него заикнулся, куда класть)
так же о каких попугаях-в-банке идёт речь когда приводится какая-то статистика?
и было бы просто супер, если добавите в конец статьи (ну или в начало) итоговую предполагаемую структура 1 куском
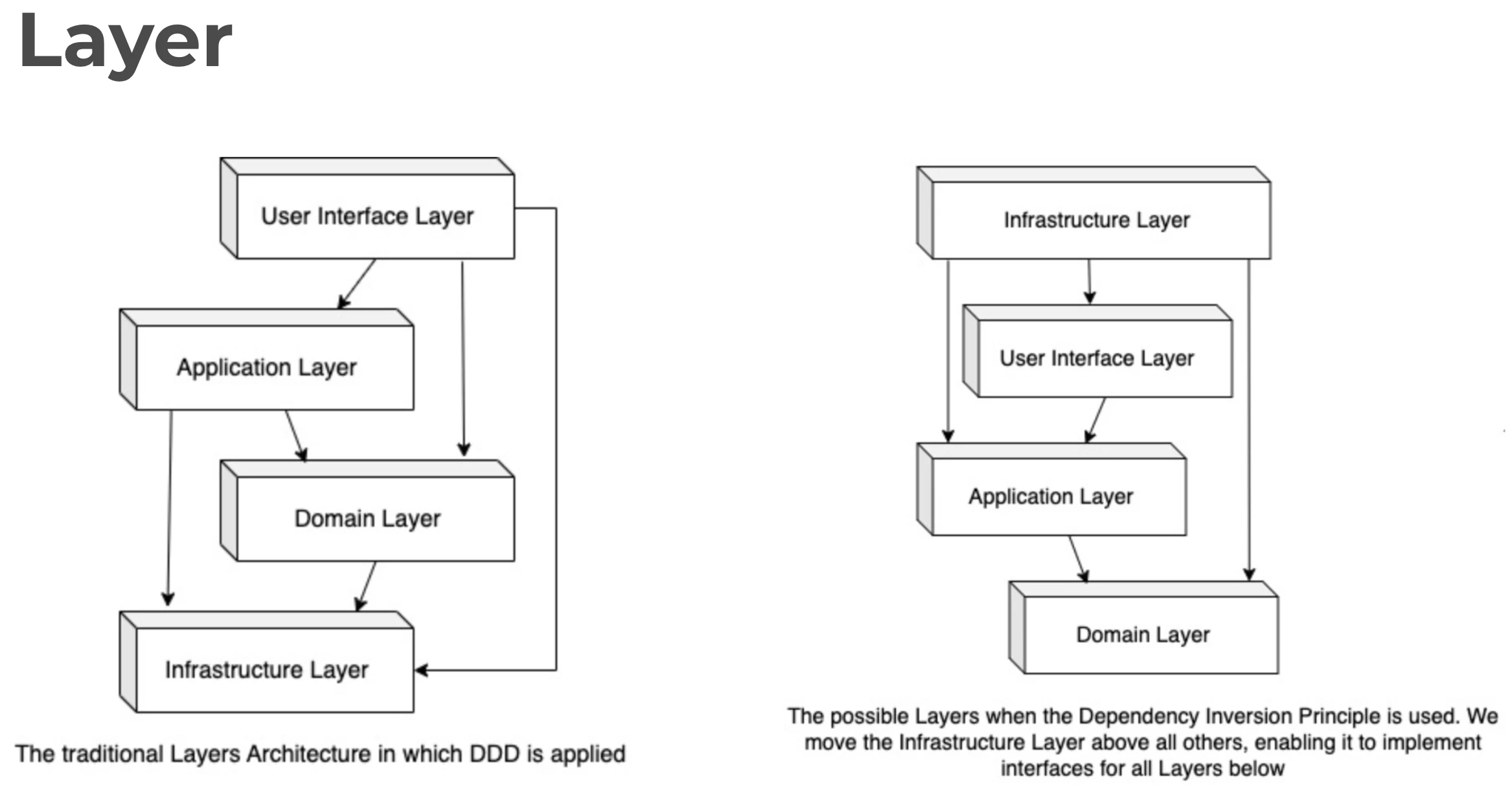
Неправильная картинка, в оригинале раза в два больше стрелок между слоями. Но за определение "чистой архитектуры" спасибо. А то ее как только не интерпретируют.
Спасибо! Уже рисую более осмысленные и формальные картинки — загружу в ближайшее время. Буду признателен, если поделитесь хорошим референсом!
https://static-careers.moneyforward.vn/mceu_69894165211698667837967.png
{kind=link}
Пожалуй, вот эта вносит меньше всего путаницы, потому что стрелка на картинке слева нарушает инверсию контроля. "Чистая архитектура" не может использовать Инфраструктуру напрямую. Картинка справа это объясняет. А если присмотреться еще, то по графу видно, что Интерфейс и вовсе избыточен.
Ни за что не поверю, что введением какого-то "правильного слоя" можно будет легко переключаться между постгресом, MongoDB и SQLite в реальном проекте. Вот там на картинке нарисована одна стрелка между "Порты" и "Postgres" а на самом деле там должно быть нарисовано 1000 стрелок. Поддерживать, тестировать и оптимизировать коммерческий облачный проект под разные системы никто не будет. В лучшем случае можно будет между похожими базами переключаться - постгрес, MSSQL, Oracle.
Этот подход сработает исключительно в тех случаях, где интерфейс крайне простой и небольшой. Пример - объектное хранилище. Там всего 3 метода: создать, прочитать, удалить. Это можно конечно реализовать и для локальной ФС, чтоб на машинах разработчиков запускать и in-memory для тестов и для прода через S3.
Картинка эта неправильна
Ни за что не поверю, что введением какого-то "правильного слоя" можно будет легко переключаться между постгресом, MongoDB и SQLite в реальном проекте
Получается вы мне не поверите если я скажу что можно это сделать паттерном мост?
(Вы работаете в ВК программистом? Даже руководитель комманды. Извините, у меня аж дыхание чучуть перехватило)
Я имею ввиду в реальном проекте, а не в примере TodoList из книжки. Потому что нет никакой потребности в возможности хранить одно и тоже либо в монге либо в постгресе и переключаться между ними опцией в конфиге.
Для какого-то набора объектов будет нужна согласованность данных и нормальная поддержка транзакций - в постгресе это доступно из коробки на высочайшем уровне, в MongoDB замучаетесь писать костыли и всё-равно не будет нормально работать. Возможно получится обособить часть объектов, для которых будет важна масштабируемость, но структура и правила работы с ними будут проще - тогда их можно будет хранить в MongoDB.
То есть не делают несколько реализаций одного интерфейса, делают 2 адаптера с разным набором функций каждый из которых ходит в свою систему хранения данных.
Да, есть, конечно, примеры, когда ваш паттерн "мост" необходимо использовать, но это точно не реализация основного репозитория.
Я имею ввиду в реальном проекте, а не в примере TodoList из книжки.
Вы сейчас называете опыт программистов накопленный десятилетиями просто каким-то развлечением? Или вы не знаете как примеры из книжки применять на реальные проекты?
В реальном проекте он может и не понадобиться, а может и понадобиться (санкции? Пожелание заказчика? Ещё что-то?). И темболее сначала вы говорили что просто не верите, теперь вот не верите, а если поверите оно и не нужно вообще.
Да, есть, конечно, примеры, когда ваш паттерн "мост" необходимо использовать, но это точно не реализация основного репозитория.
Ну и, вот так сходу, принижать то чего вы даже не знали, как-то так себе.
Вы представляете репозиторий как любой доступ к базе или что? Помоему репозиторий это обёртка в которой данные пришедшие от бд преобразуются во внутренний программный объект?
То есть не делают несколько реализаций одного интерфейса
А для чего ещё интерфейсы нужны, если не реализовывать их? Чтобы всем рассказывать что у нас DDD? Или чистая архитектура...
Вы сейчас называете опыт программистов накопленный десятилетиями просто каким-то развлечением? Или вы не знаете как примеры из книжки применять на реальные проекты?
В реальном проекте он может и не понадобиться, а может и понадобиться (санкции? Пожелание заказчика? Ещё что-то?). И темболее сначала вы говорили что просто не верите, теперь вот не верите, а если поверите оно и не нужно вообще.
Так оно применяется в других случаях, не в тех, что описаны в статье, когда надо данные информационной системы где-то хранить и для доступа к этим данным нужно 1000 функций.
Пример где это необходимо - игра, у каждого игрового объекта должно быть реализованы 3 функции: draw(...), move(...), checkCollision(). В игре одновременно присутствуют объекты разных типов их удобно хранить в одном массиве и обрабатывать похожим образом. Почему тут это работает? Потому что в интерфейсе 3 функции а не 1000. (Ну ладно, в реальной игре будет 50 а не 3, но никак не 1000)
Еще пример - линукс поддерживает разные файловые системы, конечно было бы круто все данные на ext4 хранить, но реальность такова, что кто-то может в компьютер воткнуть карту памяти из фотоаппарата с файловой системой exFat.
Ну и, вот так сходу, принижать то чего вы даже не знали, как-то так себе.
Статья про Golang написана, там это называется "interface", https://go.dev/tour/methods/9
Вы представляете репозиторий как любой доступ к базе или что? Помоему репозиторий это обёртка в которой данные пришедшие от бд преобразуются во внутренний программный объект?
Ну да, примерно это
А для чего ещё интерфейсы нужны, если не реализовывать их? Чтобы всем рассказывать что у нас DDD? Или чистая архитектура...
В статье написано, что при плохой структуре кода замена базы потребует 200 изменений в коде, а при хорошей - 10. Далее идет картинка Гибкость замены компонентов, на которой нарисовано, как PostgreSQL меняется на MongoDB. И это я хочу оспорить.
Если в реальности будет такая задача стоять, то возможно 2 варианта, либо данные очень простые и их можно где угодно хранить, но если данные сложные, то скорее всего вместо PostgreSQL потребудется поддержать другую реляционную СУБД, Oracle или MSSQL. Это будет делаться исключетельно по просьбе крупного клиента за большие деньги. И скорее всего это не будет полная реализация всех функций репозитория для обоих баз.
Либо будет доступ к базе через ORM, либо будет базовая реализация 990 функций репозитория на стандартном SQL и различная реализация с оптимизациями и кастомными фичами Postgres и Oracle оставшихся 10 функций. Но все 1000 функций 2 раза писать - это жесть.
Так оно применяется в других случаях, не в тех, что описаны в статье, когда надо данные информационной системы где-то хранить и для доступа к этим данным нужно 1000 функций.
Почему вы мне все пытаетесь рассказать где применяется то чего вы даже не знали? И что это за 1000 функций? Вы каждый отдельный sql запрос оборачиваете в функцию?
Статья про Golang написана, там это называется "interface", https://go.dev/tour/methods/9
В го паттерн мост это интерфейс?
В статье написано, что при плохой структуре кода замена базы потребует 200 изменений в коде, а при хорошей - 10. Далее идет картинка Гибкость замены компонентов, на которой нарисовано, как PostgreSQL меняется на MongoDB. И это я хочу оспорить.
Техническое и информационная часть статьи оставляет желать лучшего впринципе.
но если данные сложные, то скорее всего вместо PostgreSQL потребудется поддержать другую реляционную СУБД
Подскажите, а что за "сложные данные" не поддерживаются постгресом?
Это будет делаться исключетельно по просьбе крупного клиента за большие деньги
Вот вам ещё 1 пример где это можно использовать, продавать продукт где то, что вы хотите продать за большие деньги идет из коробки.
Либо будет доступ к базе через ORM, либо будет базовая реализация 990 функций репозитория на стандартном SQL и различная реализация с оптимизациями и кастомными фичами Postgres и Oracle оставшихся 10 функций. Но все 1000 функций 2 раза писать - это жесть.
Да уж, с вашим статусом разработчика такой компании все это звучит... так себе, не чего личного.
И не обязательно реализовывать все фичи репозитория (я не понимаю это программный репозиторий или вы так базу данных называете). Можно реализовать скелет например sql и дальше его расширять и вытягивать какие угодно фичи с уже готовым скелетом
Как бы понятнее сказать, при правильной архитектуре вы точечно получаете функционал от бд который вам нужен, а вы про какие-то 1000 функций реализованных по 2 раза
Вы сейчас называете опыт программистов накопленный десятилетиями просто каким-то развлечением? Или вы не знаете как примеры из книжки применять на реальные проекты?
Ну справедливости ради вот эта идея бесшовной замены постгреса на монгу выглядит утопичной. На простом круде это сработает, но на более сложном примере начнутся нюансы.
Это разные базы данных про разные вещи. Например, простой select for update для нескольких записей просто так не сделаешь. Каскадного удаления тоже нет. И это первое, что пришло в голову.
А вот примеры из книжек как раз слишком удобные, там всегда всё слишком легко получается
Я не знаю что для вас является швом. Человек писал что низачто не поверит, я указал на путь который сам использую в боевом проекте. Справедливости ради, в этом моменте изначальный вопрос с "как?" Перешёл на "зачем?".
По поводу примеров - за вас никто не напишет хороший и бесшовный код, не по ссылке, не в книжке, пишите его сами.
Спасибо за замечание! Полностью согласен — в продакшене нюансов всегда больше. В статьях мы формируем стандарт структуры микросервиса, который можно адаптировать под конкретные случаи. Схема упрощена для наглядности — уже работаю над более детализированной версией, загружу её в ближайшее время.
Не только можно, но и нужно абстрагироваться от инфраструктуры. Если знания о конкретной бд протекают в домен, значит домен сделан плохо. Компании платят за внедрение DDD Lite когда команда перестает вывозить когнитивную нагрузку.
Знания о конкретной БД в домен не протекают, но реализация настолько объемная, что просто так, "чтобы было" никто не будет поддерживать вторую СУБД.
Я не говорю, что это нельзя сделать, это вообще такая простая и базовая вещь с точки того, как это можно написать в коде, что её наверное на 5й день изучения программирования изучают. Это есть везде, но делается по-разному. В C и ассемблере это указатели на функции (и структуры с набором указателей на функции), в C++ - наследование и виртуальные функции, в Java и Go - интерфейсы. Я не понимаю, зачем этот подход преподносить как какую-то чудесную хитрость чистой архитектуры от дядюшки Боба, это используется уже лет 50 точно в программах чуть сложнее Hello world.
Проблема не в том, что это сложно написать в коде, а в том, что количество кода, который реализует доступ к базе обычно большое и если этот код продублировать, то это потребует почти в 2 раза больше усилий на добаботку функций по работе с базой, поддержку этого кода и тестирование.
Немного неправильно написал. В коде это легко написать плохо, продублировав все функции. Сложно сделать хорошо. Примеры как можно сделать лучше:
Можно поднапрячься, избавиться от хитрых запросов и использовать ORM
Написать всё по-максимуму на чистом SQL и сделать базовую реализацию для всех СУБД и только небольшую часть продублировать и оптимизировать для разных.
Еще что-то можно придумать, например, написать библиотеку общих кусков запросов, которая будет использоваться и в реализации для Oracle и для PostgreSQL. Ну к примеру есть набор условий, что пользователь активен, можно сделать функцию
applyUserActiveFilter(query).Часть логики перенести в базу и написать в виде функций и триггеров в базе.
Да, все решения будут выглядеть не очень круто, но зато смогут сэкономить много усилий и сберечь от багов, когда в одном месте поменяли а во втором - забыли.
В C и ассемблере это указатели на функции (и структуры с набором указателей на функции), в C++ - наследование и виртуальные функции, в Java и Go - интерфейсы. Я не понимаю, зачем этот подход преподносить как какую-то чудесную хитрость чистой архитектуры от дядюшки Боба, это используется уже лет 50 точно в программах чуть сложнее Hello world.
Вы продолжаете реально топить что интерфейс сам по себе в го добавляет какой-то гибкости? И кто, кроме может автора статьи, вообще говорит что само по себе использование интерфейса что-то вообще даёт? Я вам привёл пример паттерна мост, чистый, самый простой интерфейс сам по себе не имеет никакого отношения к этому.
Ну наверное если описали интерфейс, то где-то будет переменная такого типа, иначе зачем описывали? И наверняка будет больше одной реализации этого интерфейса, иначе можно было бы обойтись просто ссылкой на структуру.
А если есть переменная типа интерфейс и 2 реализации интерфейса, то это уже добавляет гибкость. В переменную можно записать либо указатель на первую структуру, которая реализует интерфейс либо на вторую.
Под гибкостью я понимаю гибкость архитектуры, а не гибкость, которая появляется за счет того что у нас 1 интерфейс и 3, 4, 5, n реализаций...
А чем отличается проект с гибкой архитектурой от проекта с негибкой архитектурой?
Своим видом через 5 лет. Онбордингом, способом расширения архитектуры (клиентским кодом), где интерфейс это осознанная точка роста, а не просто реализация из книжки которая познается на 5ый день обучения, как вы говорили ранее, 1 интерфейс 5ть реализаций, это не гибкость а микросервис какой-то.
Интерфейс это контракт с уже существующей логикой программы при расширении функционала
По моим наблюдениям, переход на DDD увеличивает кодовую базу от двух до четырех раз.
Абсолютно реальный проект с большим объёмом бизнес-логики и базами данных на десятки таблиц. Persistence layer сделан для работы с MSSQL или с Oracle. Переключение между MSSQL и Oracle делается в одном параметре в файле настроек проекта. ORM не используется. Всё построено на прямых sql запросах.
Ну а как это сделано? Абсолютно все запросы продублированы для обоих СУБД или все-таки есть общая часть?
Код sql запросов отдельно для каждой СУБД. И общий функционал, который запускает запросы и обрабатывает результаты запросов. Для каждой СУБД используется свой OLE DB провайдер.
Детально можно посмотреть здесь https://habr.com/ru/articles/928616/
Примеры кода на C#
Пример из жизни и из реальной практики. У нас есть библиотека запуска джоб у которой поставлялся адаптер для mongodb. Организация начала переход к postgres и нам нужно было избавиться от ее использования. Мы написали свой адаптер для postgres, т.к. дизайн либы изначально имел точку расширения и абстрактный интерфейс для этого. В результате переезда мы просто подменили зависимости при регистрации и в бизнес коде в итоге было ноль изменений. Остальная часть системы вообще не была затронута и не заметила смену базы данных.
Вообще, с адаптерами довольно приятно получается, зависимости разных микросервисов как бы сами за себя говорят, что происходит. Можно ещё кстати в pkg/ класть открытые интерфейсы для взаимодействия между сервисами.
Однако, не видет ли строгое следование clean architecture к ненужной обфускации? Нужно ли воспринимать микросервис через некую дополнительную абстракцию в виде домена, портов и т.п.? Думаю, что микросервис очень мал для такого, обычно достаточно разбить его на некие компоненты, дополнительно добавив интерфейсы для их взаимодействия, где не нужно зависеть от реализации. Однако, я могу быть не прав.
Не совсем понял из примера, а если доменов несколько, что в таком случае делать?
Я сам программист никогда не понимал и не понимаю программистов, которые дают какие-то имена, и потом пишут комментарий к имени.
Например так
persistence/ # Реализации репозиториев
driven/ ... и т.п.
Почему нельзя написать repository и т.д.? Там точно должны лежать репозитории?
У вас репозиторий это порт, по идее он в слое инфраструктуры или это часть бизнес логики. Так в каком слое он должен быть? А что если он хранит dto из слоя доменов? Так может быть? А репозитории может хранить данные как кэш, и периодически обновляться сам? Например, репа категории или складов. Где тогда он должен быть, почему это порт?
Как-то быстро оборвалась статья только я начал погружаться.
Гексогональная архитектура это круто!
Но зачем вы порты вместо стандартных левых и правых называете ведомый и ведущий? А во вторых на картинке вы показываете как домен обращается через порты к базам данных, что крайне не верно! О чем вы сами в начале статье говорите как о плюсе чистой архитектуры, домен через порты не должен ходить в базу, он вообще просто должен принимать данные и отдавать
Подскажите, хотелось бы честно, вы использовали нейросети для построения архитектуры? (Возможно и статьи). Я просто как-то просил DeepSeek написать гексогональную архитектуру и было что-то похожее.
Большое спасибо за разбор! Давайте по пунктам.
Обрыв статьи. Моя ошибка, что не пометил статью как серию из нескольких. Сознательно оставил пространство для дискуссии — финальный стандарт должен быть основан на диалоге с сообществом.
«Ведомый/ведущий» — влияние коллеги, который предложил интегрировать гексагональную архитектуру.
Про домен. Здесь вы правы. Визуально это действительно выглядит как нарушение инкапсуляции. Выше отвечал на комментарии про картинки, уже исправляю.
Нейросети — конкретно GPT o1-Pro — я использовал исключительно как второе мнение. Все приведенные примеры написаны мной. Ссылка на исходники указана в статье.
А почему у вас бизнес логика в инфраструктурном слое?
Если честно хотелось покопаться в структуре кода, но пока пытался из этой каши приведённых вами кусков расположения папок что-то понять, уже как-то и перехотелось.
Спасибо, что показали свой вариант структуры проекта.
Думаю, DDD всё же про другое, а не про «всё разложить по папочкам (ports, adapters, domain)» и вся логика будет в domain. Хотя вы несколько пунктов привели DDD, но по факту это декларация. Особенно картинка показывает это с подписью DDD, но там слои и при чём тут DDD.
Часто в последнее время «мешают коней и людей», подозреваю, что всё смешалось из-за наличия множества интерпретаций, личного мнения некоторых терминов. Что такое DDD, есть короткая статья, например https://habr.com/ru/articles/580972.
По моему личному мнению, если вам нужно в микросервисе использовать подходы DDD, то у вас модульный монолит и это, соответственно, будет за собой тянуть подходы, которые используются в «больших фреймворках».
Интерфейсы не показали(почему интерфейсы экспортируемые и для кого), где будут у вас лежать и где будет логика, то есть как будете разграничивать слои и не допускать проникновения логики одного слоя в другой (особенно в domain).Мне действительно было интересно поглядеть, как вы реализовывали логику всю в domain с сокрытием состояния и все эти агрегаты с тестами, но в репозитории, к сожалению, пустые пакеты.
А то что пакет domain — верхний уровень зависимостей и оттуда пробрасываются структуры между сервисами, то я думаю, это верно, но DDD классический тут не при чём.
Какая-то каша спорной структуры, посредственного описания архитектуры и полное непонимание что такое DDD.
DDD не про архитектуру. Больше про изолированные контексты и единой точки к ним. Он может реализован в одном слое. А разделение по слоям - это и есть архитектура. Наиболее популярные: луковая, гексогональная, чистая от Роберта Мартина и т.д. Все они по сути одинаковы - делим проект на бизнес логику, логику вызова той самой бизнес логики и инфраструктуру.
Впечатление, что студент сдал курсовую работу, скачанную из интернета, или, как сейчас актуально, LLM) Рассмешил
какая-то каша. Порты driven/driving, а адаптеры primary/secondary - зачем по-разному называть? Неясно.
Нет слоя портов. Порты - это интерфейсы, а они должны лежать там же, где и потребители этих интерфейсов то есть в слое application.
В инфраструктуре часть адаптеров лежит в папке адаптерс, а часть вне ее...
Первая картинка - вообще я считаю шедевр:
Нарисована в пеинте
Не правила зависимостей, а правило зависимостей - оно одно
Домен зависит от инфры...
ДДД вообще к этому не имеет отношения
В общем, я очень за изучение этой темы кем бы то ни было, но я не понимаю, зачем писать статью, если нет понимания. Сколько статей или репозиториев про чистую архитектуру и ддд не встречаешь - везде какие-то элементарные ошибки. Еще ладно в каких-то сложных вещах, но обычно в самых простых, вроде базового правила зависимостей.
И это порочный круг, изучают тему по статьям, а потом пишут свои. Сломанный телефон в итоге все приходят к мнению, что чистая архитектура - это сложно и переусложнение. Не удивительно - по всей той каше, что в статьях неясно, как разобраться можно.
Спасибо. Именно из‑за каши в понятиях и структуре я пишу эту серию статей. Благодаря вам и сообществу Хабра есть возможность сделать что‑то общее и верное.
Картинки я поменяю сегодня, отвечал ранее.
Буду рад, если поделитесь — как вы понимаете чистую архитектуру?
Очень хороший вопрос про понимание чистой архитектуры. В моём понимании все ныне известные виды архитектуры - чистая, луковая, гексагональная, многослойная - это варианты (проекции) какой-то общей архитектуры. И совершенно непонятно почему не обсуждается (по крайней мере не встречал подобных обсуждений) вопрос построения единой архитектуры.
Не варианты одной, а скорее каждая следующая вводит какие-то новые понятия, которых не было в предыдущих. По этой причине например слои есть везде, а вот правила зависимостей нет в многослойной т.к. оно сформулировано в чистой. Луковая и порты адаптеры тоже вводят какие-то понятия, вроде собственно "порты" и "адаптеры" или разделения приложения на domain logic и application logic слои.
Там много мелких и не очень различий, но основное, что надо понимать это именно правило зависимостей. Его понимание по моим наблюдениям представляет самую большую сложность. И начинается с прочтения статьи с сайта Uncle Bob.
а почему адаптеры primary/secondary?
может лучше контроллеры на входе, а адаптеры на выходе?
потому что идея адаптеров пришла из статьи про "порты адаптеры", где они так определяются. Если использовать для входа одно название, а для выхода другое, то это уже не так, как написано в статье. Из чего получаем n+1 интерпретацию, где n уже около миллиона.
В целом проблемы нет, можно называть как душе угодно и оно возможно даже будет компилироваться, но это не то, что можно загуглить и прочитать где-то и не то, что в оригинале называется "порты адаптеры".
func NewUser(email string) (*User, error) {
if !isValidEmail(email) {
return nil, ErrInvalidEmail
}
return &User{Email: email}, nil
}
Не совсем про архитектуру, но мне понравился подход из книги zero2production, правда для rust. Там для таких кастомных типов как email вводился отдельный тип, который и валидирует данные.
Так не нужно везде, где принимается email валидировать строку или предполагать, что вызывающий это уже сделал. И везде где используется этот тип Email будет гарантированно валидный адрес.
Правда в go словно это с трудом приживается.
Go-микросервисы: Стандартизация архитектуры с Clean Architecture и DDD