Comments 142
sphinx
причем тут сфинкс, где тут полнотекстовый поиск?
он отлично подходит не только для фултекста, но и для фильтрации и сортировки.
он спрашивает как уменьшить время в 10 раз
кажется, вы изрядно тупите
Как обычно 3 способа решения проблемы со скоростью:
1. оптимизировать запрос (ниже там с иннер джоин предложили вариант, автор не отписался какое время выполнения стало)
2. увеличить ресурсы: больше памяти, круче железо
3. использовать другое ПО
я просто предложил третий вариант
1. оптимизировать запрос (ниже там с иннер джоин предложили вариант, автор не отписался какое время выполнения стало)
2. увеличить ресурсы: больше памяти, круче железо
3. использовать другое ПО
я просто предложил третий вариант
извините, если резко ответил в предыдущем комменте, но у автора поста вопрос не стоял в том, что «подскажите, какой ПО мне нужно использовать, чтобы уменьшить время выполнения этого запроса?»
он спросил: «как, используя текущее ПО, мне изменить _запрос_, чтобы он выполнялся быстрее
sphinx — крутая штука, несомненно, но не стоит уж из пушки по воробьям-то)
он спросил: «как, используя текущее ПО, мне изменить _запрос_, чтобы он выполнялся быстрее
sphinx — крутая штука, несомненно, но не стоит уж из пушки по воробьям-то)
третий вариант былбы использовать oracle вместо mssql
а так это совершенно разные задачи
а так это совершенно разные задачи
Поле CityId проиндексировано?
А я думал, в статье и будет рассказано, как это сделать.
Почему не join'ите наоборот города right join persons?
Во первых мне непонятно почему Left Join, вероятно именно из-за него оптимизатор не срабатывает, ибо понимает что c.Name может быть NULL, поэтому сканирует все 10млн записей для корректной сортировки. Inner Join не решает проблему?
Да, Inner решает. Действительно, не дописал, что есть Null. Сейчас поправлю.
NULL же не мешает делать выборку по Inner Join. Или нужны записи People, у которых CityId = NULL?
Логично, что нужны. «Правильного» решения для них нет.
«Неправильное» — это генерить отдельную вьюху, которая будет делать денормализацию (и подставлять пустые строки там, где null), и всю ее покрывать индексами. Тогда просядет все редактирование, но зато вот такие выборки будут летать.
«Неправильное» — это генерить отдельную вьюху, которая будет делать денормализацию (и подставлять пустые строки там, где null), и всю ее покрывать индексами. Тогда просядет все редактирование, но зато вот такие выборки будут летать.
Ничего логичного, в задаче про это ничего не сказано. Можно UNION попробовать для двух селектов (один выбирает NULL'ы, второй делает Inner).
Во-первых, замучаешься строить union для всех таблиц в звезде (общий случай). Во-вторых, запросы поверх юниона делать неудобно и медленно.
Вы сейчас думаете о том как этом можно применить к общему случаю. Я понимаю, что это с одной стороны правильно, но задача стоит другая — нужно оптимизировать конкретный запрос. Поэтому все рассуждения поверх этого оторваны от задачи и к решению не имеют отношения. Главное — идея понятна (надеюсь) и в этом направлении есть возможность экспериментировать.
Никакой магии: 6 сек, как минимум, потому, что top 100 применяется ко всему результирущему набору.
Т.е. сначала сделается leftjoin 100млн * 10, затем отсортируется, затем от всего этого возьмется первые 100, остальные будут отброшены. Сервер оптимизирует как может, но все равно данных хватает на 6 секунд
Т.е. сначала сделается leftjoin 100млн * 10, затем отсортируется, затем от всего этого возьмется первые 100, остальные будут отброшены. Сервер оптимизирует как может, но все равно данных хватает на 6 секунд
Попробуйте примерно так
with Data (
select t.*, ROW_NUMBER() over(ORDER BY Name DESC) as RN from
(select p.Name, c.Name as City from People p
left join Cities c on c.Id=p.CityId
order by c.Name) as t
)
select * from Data
where RN < 100;
Извлекает ровно 100, а не все и не 100тыс
with Data (
select t.*, ROW_NUMBER() over(ORDER BY Name DESC) as RN from
(select p.Name, c.Name as City from People p
left join Cities c on c.Id=p.CityId
order by c.Name) as t
)
select * from Data
where RN < 100;
Извлекает ровно 100, а не все и не 100тыс
Кажется будет тоже самое.
Сначала произойдёт соединение, потом отсортирует, а потом только выберет 100 первых по сортировке.
Сначала произойдёт соединение, потом отсортирует, а потом только выберет 100 первых по сортировке.
Немного подправил (в подзапросах с order обязательно должен быть TOP), и проверил. Выдает те-же 6 сек.
План запроса говорит, что сперва отрабатывает полностью и независимо внутренний подзапрос.
План запроса говорит, что сперва отрабатывает полностью и независимо внутренний подзапрос.
Прошу прощения, но откуда 1 млрд. записей, там ведь left а не cross join?
Вроде как с подобным бороться радикальными способами — не создавать nullable полей.
Во всех таблицах на которые есть ссылки создается запись с ID 0, а потом в связанных таблицах используется 0 вместо null, при этом индексы начинают работать.
Во всех таблицах на которые есть ссылки создается запись с ID 0, а потом в связанных таблицах используется 0 вместо null, при этом индексы начинают работать.
Возможен ли следующий запрос в MSSQL?
select top 100 p.Name, c.Name as City from People p
left join (select * FROM Cities order by Name) c on c.Id=p.CityId
а почему не "...order by p.CityId "? Вам обязательно нужна сортировка по алфавиту?
А если View сделать и из нее Top 100 выбирать?
Не помню, к сожалению, можно ли во View еще и индекс делать.
Не помню, к сожалению, можно ли во View еще и индекс делать.
Сейчас, догенерирую тестовые данные и посмотрим…
Не очень понятен смысл такой выборки. Поэтому и решение предложить трудно. Сформулируйте задачу.
Что тут непонятного? Нужно выбрать данные из таблицы, отсортированные по полю из другой таблице, связанной по форейн кею. Имхо ооочень распространенная задача.
Если речь об общем случае, то нужно тупо денормализовать базу и внести поле city_name в таблицу people.
Иначе, сервер будет всегда шастать по всей таблице people и состыковывать каждую ее запись с каждой внешней и только потом сортировать и отбрасывать. Индекс нифига не поможет.
ЗЫ Одноименное поле («name») — это зло.
ЗЫЫ Название таблицы во множественном числе (People, Cities) — это зло в квадрате.
ЗЫЫЫ Ключевое поле таблицы («id») без имени таблицы — это зло в кубе.
Иначе, сервер будет всегда шастать по всей таблице people и состыковывать каждую ее запись с каждой внешней и только потом сортировать и отбрасывать. Индекс нифига не поможет.
ЗЫ Одноименное поле («name») — это зло.
ЗЫЫ Название таблицы во множественном числе (People, Cities) — это зло в квадрате.
ЗЫЫЫ Ключевое поле таблицы («id») без имени таблицы — это зло в кубе.
ваши ЗЫ непонятны, неаргументированны и 99%, что неправильны
Да, денормализация в данном случае поможет, а если нужно сортировать + еще вытягивать n полей по лефт джойнам?
Так вытягивайте, кто мешает?
Вытягивание не будет занимать много времени, запись ищется по ключу.
Главное, что индекс по внесенному полю отменил полный перебор записей в основной (большой) таблицы. Все остальные операции по сравнению с этим перебором блекнут…
Вытягивание не будет занимать много времени, запись ищется по ключу.
Главное, что индекс по внесенному полю отменил полный перебор записей в основной (большой) таблицы. Все остальные операции по сравнению с этим перебором блекнут…
вот нельзя денормализовать так просто
город пусть он втащит, но большинство сущностей именно сущности а не одно поле.
у меня например надо было сделать грид, в котором отображаются кроме полей собственно документа, еще именна статуса, назначенные пользователи ит д. и они могут быть как назначены так и не назначены, а грид сортировать надо, причем по каждой колонке
город пусть он втащит, но большинство сущностей именно сущности а не одно поле.
у меня например надо было сделать грид, в котором отображаются кроме полей собственно документа, еще именна статуса, назначенные пользователи ит д. и они могут быть как назначены так и не назначены, а грид сортировать надо, причем по каждой колонке
все ваше зло — ничто, и более того — добро, если пользуешься ОРМ.
Вы же пользуетесь ORM, правда?:)
Вы же пользуетесь ORM, правда?:)
ЗЫЫЫ Называть таблицы и поля с заглавной буквы — это тоже зло.
И, кстати, если не ошибаюсь, при сортировке по возрастанию MS SQL загоняет NULL в конец (как будто они больше всех), что возможно не следует логике приложения.
То есть при сортировке по возрастанию, в каком-то смысле логично получить вначале людей, вообще не привязанных к городу…
И, кстати, если не ошибаюсь, при сортировке по возрастанию MS SQL загоняет NULL в конец (как будто они больше всех), что возможно не следует логике приложения.
То есть при сортировке по возрастанию, в каком-то смысле логично получить вначале людей, вообще не привязанных к городу…
А почему одноименное имя — зло? Имхо, City.Name вполне нормально и очевидно читается.
Число мы тоже стараемся использовать единственное, согласен.
А вот ключевое имя — да, стремимся имя таблицы выключать: CityID. В тоже время не вижу страшного в случае сокращенного написания («ID») в случае чрезмерно длинного названия таблицы: если DriverDocumentID — это нормально, то DriverrToDriverDocumentID — уже перебор (пример условный, конечно).
Число мы тоже стараемся использовать единственное, согласен.
А вот ключевое имя — да, стремимся имя таблицы выключать: CityID. В тоже время не вижу страшного в случае сокращенного написания («ID») в случае чрезмерно длинного названия таблицы: если DriverDocumentID — это нормально, то DriverrToDriverDocumentID — уже перебор (пример условный, конечно).
Не хочется долго распространятся, приведу идеальный (для меня) вариант:
CREATE TABLE city (
city_id,
city_name
)
CREATE TABLE user (
usr_id,
usr_name,
home_city REFERENCES city
)
И теперь не нужны точки и нет пересечений имен:
SELECT usr_id, usr_name, city_name FROM user
LEFT JOIN city ON home_city = city_id
CREATE TABLE city (
city_id,
city_name
)
CREATE TABLE user (
usr_id,
usr_name,
home_city REFERENCES city
)
И теперь не нужны точки и нет пересечений имен:
SELECT usr_id, usr_name, city_name FROM user
LEFT JOIN city ON home_city = city_id
Ну не знаю… По моему, порожденные свойства в классах будут выглядеть не ахти. user.usr_name — брр. Хотя понятно, что в ORM'е все можно переименовать, но все-таки.
Хотя понятно, что на вкус и на цвет товарищей нет, и главное — чтобы вся команда придерживалась единого стиля.
Хотя понятно, что на вкус и на цвет товарищей нет, и главное — чтобы вся команда придерживалась единого стиля.
Вы хотите сказать, что ORM строит имя именно так?.. Это ужасно тогда. Вот почему:
CREATE TABLE city (
city_id,
city_name
)
CREATE TABLE user (
usr_id,
usr_name,
home_city REFERENCES city,
current_city REFERENCES city
)
SELECT usr_id, usr_name, city_name FROM user
LEFT JOIN city ON home_city = city_id
LEFT JOIN city ON current_city = city_id
Как теперь отличить имя города-происхождения от имени текущего города?.. По логике ORM это всегда «city.city_name» получается?
ЗЫ В моей библиотеке это будет: home_city_name и current_city_name
CREATE TABLE city (
city_id,
city_name
)
CREATE TABLE user (
usr_id,
usr_name,
home_city REFERENCES city,
current_city REFERENCES city
)
SELECT usr_id, usr_name, city_name FROM user
LEFT JOIN city ON home_city = city_id
LEFT JOIN city ON current_city = city_id
Как теперь отличить имя города-происхождения от имени текущего города?.. По логике ORM это всегда «city.city_name» получается?
ЗЫ В моей библиотеке это будет: home_city_name и current_city_name
Там надо отталкиваться от того, что сама логика работы с ORM'ом основывается на работе с объектами, а не с результатами выполнения запросов. Так что нет ничего страшного в том, что в двух разных объектах имеются одинаковые поля.
Так что будет City.Name, User.Name, или User.City.Name если мы обращаемся к названию города текущего пользователя.
Так что будет City.Name, User.Name, или User.City.Name если мы обращаемся к названию города текущего пользователя.
Ну и, соответственно, в вашем примере — User.HomeCity.Name, User.CurrentCity.Name.
Не, ну навскидку:
CREATE TABLE supir_pupir_prefix_cities ( id, name ) CREATE TABLE supir_pupir_prefix_users ( id, name, home_city REFERENCES supir_pupir_prefix_cities, current_city REFERENCES supir_pupir_prefix_cities ) SELECT user.id, user.name, home_city.name, current_city.name FROM supir_pupir_prefix_users AS user LEFT JOIN supir_pupir_prefix_cities AS home_city ON user.home_city = home_city.id LEFT JOIN supir_pupir_prefix_cities AS current_city ON user.current_city = current_city.id
Я считаю, что нужно home_city изменить на city_id.
Для меня важно не пересечение имен, а наглядность соотвествия.
Для меня важно не пересечение имен, а наглядность соотвествия.
когда имена таблицы и полей не больше четырёх символов, то это красиво и логично смотрится :)
а если имена таблиц состоят из трёх-четырёх длинных слов, то имена полей будут состоять уже из семи-восьми слов? :)
TABLE process_customer(
process_customer_process_id,
)
а если имена таблиц состоят из трёх-четырёх длинных слов, то имена полей будут состоять уже из семи-восьми слов? :)
TABLE process_customer(
process_customer_process_id,
)
Во, я ждал аргументации :) Не нужны точки — это по вашему весомый аргумент? :)
Однако-же
Остальные правила я так понимаю произрастают из этого.
SELECT user_id, user_name, city_name FROM user LEFT JOIN city ON home_city = city_id
SELECT user.id, user.name, city.name FROM user LEFT JOIN city ON home_city = city.id
Однако-же
SELECT user_name FROM user WHERE user_id = 5
SELECT name FROM user WHERE id = 5
Остальные правила я так понимаю произрастают из этого.
ыыы… а какая разница, как названы таблицы и поля? :)
да хоть циферьками, всё равно обращение к ним из кода идёт по именованым константам или переменным, и только в одном месте.
да хоть циферьками, всё равно обращение к ним из кода идёт по именованым константам или переменным, и только в одном месте.
использование атомов ( tenshi.habrahabr.ru/blog/97670/ ) позволяет не заморачиваться с инфраструктурой именованных констант и находить места использования каждого поля простым поиском по исходникам.
«select * from People p
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name] „
Что-то я вообще не понимаю такой оптимизации…
Зачем отобранных людей из данного одного города сортировать по имени этого города?
Оно же будет одинаковым у всех выбранных записей…
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name] „
Что-то я вообще не понимаю такой оптимизации…
Зачем отобранных людей из данного одного города сортировать по имени этого города?
Оно же будет одинаковым у всех выбранных записей…
Покажите, пожалуйста, план выполнения запроса и список всех индексов по данным таблицам.
Я имел ввиду план который можно прочитать, а то на картинке ничего не прочитать.
Вот так прочитаете: habreffect.ru/files/1d8/c797be1a8/Plan.png
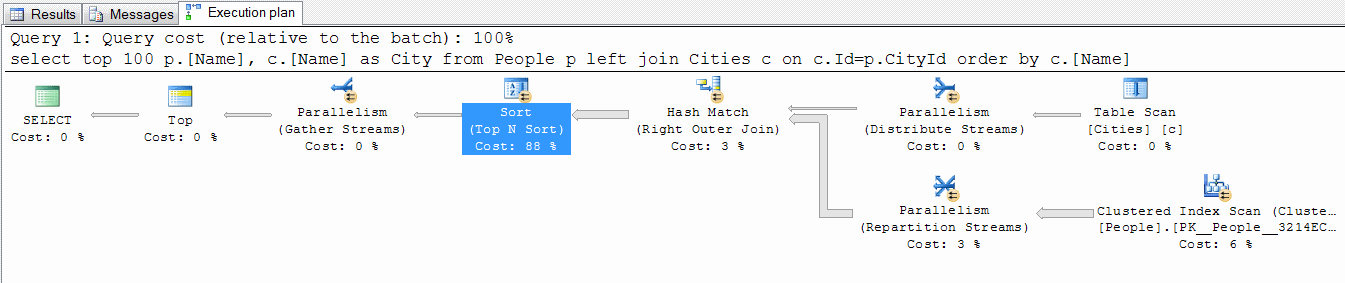{kind=link}
На картинке все прочитать. Просто картинки имеют max-width: 100%.
Добавьте дополнительное условие в первый WHERE, например AND CityId IS NOT NULL. Условие должно быть обязательно по индексированному полю!
Не знаю как работает оптимизатор запросов в MSSQL, но в PostgreSQL, на больших таблицах, такой «финт ушами» позволяет уменьшить время выполнения запроса на 3 порядка.
Не знаю как работает оптимизатор запросов в MSSQL, но в PostgreSQL, на больших таблицах, такой «финт ушами» позволяет уменьшить время выполнения запроса на 3 порядка.
Не проще ли тогда заменить Left Join на Inner Join??? Но автору, как я понял, надо именно с NULLами, поэтому метод не катит…
может тогда (People InnerJoin Cities) UNION (People WHEW CityID IS NULL)?
NULL теоретически должен изди первым…
Только надо убедится что сортировка будет выполнятся до юниона а лимит после. Например, в MySQL
Только надо убедится что сортировка будет выполнятся до юниона а лимит после. Например, в MySQL
SELECT field FROM t1 UNION SELECT field FROM t2 ORDER BY field LIMIT 100 выберет 100 записаей, но листаться и объединятся будут все, т.к. ORDER сработает после UNION, незнаю решат ли проблему скобочки, можно попробовать сделать что-то типа SELECT field FROM t1 UNION SELECT * FROM ( SELECT field FROM t2 ORDER BY field) tt LIMIT 100Результат сравнения NULL _теоретически_ (по стандарту) с чем бы то ли было — Unknown, т.о. порядок их вмешания в общую кучу неопределен. Конкретно для MSSQL можно даже включить режим соответствия стандарту через SET ANSI NULL.
Другое дело, что да, большинство серверов плюют на стандарт и дают некую стабильность такой сортировки, что приводит к таким вот решениям :(
Другое дело, что да, большинство серверов плюют на стандарт и дают некую стабильность такой сортировки, что приводит к таким вот решениям :(
Какой там джойн без разницы… Главное применить дополнительный фильтр по индексированному полю.
В чем суть запросов как у автора: поскольку нет дополнительных полей фильтрации, оптимизатор выбирает самую простую методику — full join + sequence scan по обоим таблица. А поскольку sequence scan очень не быстрая операция (еще бы, поднять с жесткого диска таблицу в 10 млн. записей), то и запрос получается очень медленным. При дополнительном фильтре получает index scan по большой таблице и, соответственно, join результатов с меньшей таблицей, отсюда и скорость выполнения (индекс зачастую помещается полностью в память, как и результат таких join-ов).
В чем суть запросов как у автора: поскольку нет дополнительных полей фильтрации, оптимизатор выбирает самую простую методику — full join + sequence scan по обоим таблица. А поскольку sequence scan очень не быстрая операция (еще бы, поднять с жесткого диска таблицу в 10 млн. записей), то и запрос получается очень медленным. При дополнительном фильтре получает index scan по большой таблице и, соответственно, join результатов с меньшей таблицей, отсюда и скорость выполнения (индекс зачастую помещается полностью в память, как и результат таких join-ов).
вот такая штука получилась:
Таблички
— CREATE TABLE [dbo].[Cities] (
[Id] uniqueidentifier NOT NULL PRIMARY KEY,
[Name] nvarchar(50) NOT NULL,
)
ON [PRIMARY]
GO
CREATE TABLE [dbo].[People] (
[Id] uniqueidentifier NOT NULL PRIMARY KEY,
[Name] nvarchar(50) NOT NULL,
[CityId] UNIQUEIDENTIFIER FOREIGN KEY REFERENCES dbo.Cities (id)
)
ON [PRIMARY]
GO
— Запрос:
— SELECT TOP 100 People.NAME, dbo.Cities.[Name]
FROM dbo.Cities JOIN people ON cities.Id = people.cityid
ORDER BY dbo.Cities.[Name]
— (100 row(s) affected)
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 5 ms.
-----
Таблички
— CREATE TABLE [dbo].[Cities] (
[Id] uniqueidentifier NOT NULL PRIMARY KEY,
[Name] nvarchar(50) NOT NULL,
)
ON [PRIMARY]
GO
CREATE TABLE [dbo].[People] (
[Id] uniqueidentifier NOT NULL PRIMARY KEY,
[Name] nvarchar(50) NOT NULL,
[CityId] UNIQUEIDENTIFIER FOREIGN KEY REFERENCES dbo.Cities (id)
)
ON [PRIMARY]
GO
— Запрос:
— SELECT TOP 100 People.NAME, dbo.Cities.[Name]
FROM dbo.Cities JOIN people ON cities.Id = people.cityid
ORDER BY dbo.Cities.[Name]
— (100 row(s) affected)
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 5 ms.
-----
а если CityId будет NULL?
А в какое место выборки при сортировке по городу вставлять «бомжей» тогда? :)
Туда же, куда вставляется NULL при любой другой сортировке
тогда я предлагаю выбрать их отдельно, присоединить юнионом и поместить в нужную позицию.
Вы ведь в курсе, что по стандарту результат сравнения NULL с любыми другими операндами — Unknown? Т.е. даже NULL = NULL — это Unknown, а уж NULL < 'строка' — подавно.
Сделано это на самом деле не потому, что люди, писавшие стандарт такие вредные, а именно для того, чтобы избежать такого abuse, которое хочет устроить автор топика. Вот везде логично предлагают делать явный UNION и пропихивать эти дополнительные строчки именно в то место топпинга, в котором они нужны.
Сделано это на самом деле не потому, что люди, писавшие стандарт такие вредные, а именно для того, чтобы избежать такого abuse, которое хочет устроить автор топика. Вот везде логично предлагают делать явный UNION и пропихивать эти дополнительные строчки именно в то место топпинга, в котором они нужны.
select * from emp order by sal desc NULLS FIRST; select * from emp order by sal desc NULLS LAST;
Это Oracle. В MsSql не уверен, но тоже думаю, что проблем с сортировкой нет.
В MSSQL там прибит определенный порядок, в противоречии со спецификацией. Эту «приятную особенность» можно даже выключить (через SET ANSI NULLS), но так почти никто не делает.
Вопрос в том, что это хак — со всеми вытекающими последствиями. Тот, кто им пользуется, должен быть готов к тому, что в том числе будет такой план выполнения запроса, что всё будет медленно и печально.
Вопрос в том, что это хак — со всеми вытекающими последствиями. Тот, кто им пользуется, должен быть готов к тому, что в том числе будет такой план выполнения запроса, что всё будет медленно и печально.
Сделать ещё
UNION SELECT TOP 100 People.NAME, NULL
FROM people WHERE people.cityid IS NULL
и из этого всего выбрать TOP100.
Как идея? :)
UNION SELECT TOP 100 People.NAME, NULL
FROM people WHERE people.cityid IS NULL
и из этого всего выбрать TOP100.
Как идея? :)

у вас точно 10 млн people?
SET STATISTICS TIME ON;
SELECT COUNT(*) FROM dbo.Cities;
SELECT COUNT(*) FROM people;
SELECT TOP 100 People.NAME, dbo.Cities.[Name]
FROM people RIGHT JOIN dbo.Cities ON dbo.Cities.Id = people.cityid
ORDER BY dbo.Cities.NAME desc;
— SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 5 ms, elapsed time = 5 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
— 100
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
— 10000000
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 1875 ms, elapsed time = 952 ms.
NAME Name
— — Annette Wallace149
Holly059 Wallace149
<<>>
Mike8 Wallace149
(100 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 150 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SELECT COUNT(*) FROM dbo.Cities;
SELECT COUNT(*) FROM people;
SELECT TOP 100 People.NAME, dbo.Cities.[Name]
FROM people RIGHT JOIN dbo.Cities ON dbo.Cities.Id = people.cityid
ORDER BY dbo.Cities.NAME desc;
— SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 5 ms, elapsed time = 5 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
— 100
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
— 10000000
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 1875 ms, elapsed time = 952 ms.
NAME Name
— — Annette Wallace149
Holly059 Wallace149
<<>>
Mike8 Wallace149
(100 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 150 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
В Вашем плане наибольшую стоимость имеет сортировка.
Предлагаю сделать кластеризованный индекс по CityId в таблице People. В таблице City города пересортировать чтобы первый по алфавитому порядку имели бы меньший Id.
В запросе выбирать первые 100 записей из People а затем join-ить с City чтобы получить наименование городов.
Имхо, это должно помочь оптимизатору с сортировкой.
Предлагаю сделать кластеризованный индекс по CityId в таблице People. В таблице City города пересортировать чтобы первый по алфавитому порядку имели бы меньший Id.
В запросе выбирать первые 100 записей из People а затем join-ить с City чтобы получить наименование городов.
Имхо, это должно помочь оптимизатору с сортировкой.
интересно а расплодившиеся на хабре ms евангелисты почтут за честь помочь с проблемкой или в обычной манере продолжат ездить по ушам?
Извеняюсь я мускульный человек, а можно сделать запрос на запрос?
SELECT TOP 100 *
FROM (
select * from People p
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name]
) all_people
П.С. В Мускуле всречался с похожей проблемой, выходил из неё именно селектором на селектор
SELECT TOP 100 *
FROM (
select * from People p
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name]
) all_people
П.С. В Мускуле всречался с похожей проблемой, выходил из неё именно селектором на селектор
Думаю, что можно. Но приведенный запрос справедлив лишь для истинно равномерного распределения. Если бы автор был уверен в том, что данные действительно всегда равномерно распределены, то он использовал бы подобный запрос. В общем случае, автор надеется что сервер поймёт какое распределение у данных и воспользуется этим. А если через секунду распределение измениться, а план выполнения запроса уже закешировался? Серверу дороже каждый раз переоценивать распределение всех данных, чем сформировать универсальный план.
Положите город в таблицу с людьми прямо текстом ;-) Лучшее решение. Ну или используйте foreign key'и.
> Нужно выбрать первых 100 записей People, отсортированных по Cites.
Что это за выборка? В чем ее смысл? Сто Аайрон Аайронсонов из Алма-аты?
Или это чисто теоретическая задача?
Что это за выборка? В чем ее смысл? Сто Аайрон Аайронсонов из Алма-аты?
Или это чисто теоретическая задача?
Задача вполне реальная. Есть таблица с основной сущностью, от нее по принципу «звезда» отходит множество измерений. Пользователю нужно ее отобразить в гриде, предоставив сортировку по полям.
Начиная с некоторого размера основной таблицы сортировка сводится к тому, что выбирается окно с одинаковыми (крайними) значениями, (вроде «Алматы») но при этом система начинает жутко тормозить.
Начиная с некоторого размера основной таблицы сортировка сводится к тому, что выбирается окно с одинаковыми (крайними) значениями, (вроде «Алматы») но при этом система начинает жутко тормозить.
Сделайте денормализацию вашей базы данных, добавьте в таблицу People поле CityName.
Мдас, ну не получается селектом, напиши процедуру, ведь MSSQL это умеет.
Поле City.Name для Person`а не проиндексировано, именно поэтому на sort уходит 99%.
Его конечно и невозможно проиндексировать, но можно изъе… ся. Будем надеяться, что у нас один язык (русский к примеру или английский), т.е. не i18n.
При создании таблицы Cities и прочих тупеньких справочников а ля Id, Name, вставляем данные, упорядочив их по Name`у. Таким образом Id`шники будут тоже упорядочены.
При изменении таблицы будет конечно гемор, но на эту тему можно написать какую-нить процу, которая будет хитро всё обновлять во всех местах.
А уже в самом запросе делаем любые join`ы, но order by идёт по Person.CityId.
Вот когда в SQL`ях можно будет создвать индексы на поля в других таблицах — проблема убежит. Хотя м.б. кто-то уже так умеет.
Его конечно и невозможно проиндексировать, но можно изъе… ся. Будем надеяться, что у нас один язык (русский к примеру или английский), т.е. не i18n.
При создании таблицы Cities и прочих тупеньких справочников а ля Id, Name, вставляем данные, упорядочив их по Name`у. Таким образом Id`шники будут тоже упорядочены.
При изменении таблицы будет конечно гемор, но на эту тему можно написать какую-нить процу, которая будет хитро всё обновлять во всех местах.
А уже в самом запросе делаем любые join`ы, но order by идёт по Person.CityId.
Вот когда в SQL`ях можно будет создвать индексы на поля в других таблицах — проблема убежит. Хотя м.б. кто-то уже так умеет.
Id — Guid. Не так то просто его поп орядку расположить при вставке
А, вижу.
Для данного подхода guid излишен — для таких малых справочников integer`а хватит.
Хотя я тут ещё вариант подумал — «типа» денормализация, как выше товарищ предлагал.
Сделать view`шку, в которой заджойнить City.Name, и уже в этой вьюшке его проиндексировать. По-мойму в SQL-сервере это возможно.
Для данного подхода guid излишен — для таких малых справочников integer`а хватит.
Хотя я тут ещё вариант подумал — «типа» денормализация, как выше товарищ предлагал.
Сделать view`шку, в которой заджойнить City.Name, и уже в этой вьюшке его проиндексировать. По-мойму в SQL-сервере это возможно.
Почитайте про sequential guid. Некоторые ОРМы их потдерживают. Например НХибирнейт.
В таблице в реальности есть множество свойств. А ID можно отсортировать только по одному из них.
Я хз че тут понаворочено, но замечаю, что избавляемся от LEFT JOIN где только можно.
Всегда можно быстро выгребсти отсортированный список городов (а можно еще до кучи закешить города->количество_пиплов), взять первый, а потом выгрести из пиплов столько сколько нужно вторым запросом по этому городу.
Всегда можно быстро выгребсти отсортированный список городов (а можно еще до кучи закешить города->количество_пиплов), взять первый, а потом выгрести из пиплов столько сколько нужно вторым запросом по этому городу.
«Интересно, что ДАЖЕ ЕСЛИ поле City было бы NotNull но использовался LeftJoin – то запрос тормозит. „
Как верно написали выше, Left Join автоматически приводит к выводу всей таблицы. Поэтому вы всегда сначала выбираете весь people, а потом всегда его пересортировываете.
Поэтому — медленно.
Как верно написали выше, Left Join автоматически приводит к выводу всей таблицы. Поэтому вы всегда сначала выбираете весь people, а потом всегда его пересортировываете.
Поэтому — медленно.
первоначальный запрос выберет 100 записей людей из первого города, если не найдет доберет оставшихся из второго города и так далее.
так как привязка к городу обязательна, нет смысла в outer join-ах.
если это не подходит, можно, сосчитав count(*) ом количество людей по городам, сделать select from people where cityid in(… )
количество вернувшихся записей — можно отсекать в коде. в вернувшемся курсоре проходить по нужному кол-ву записей, потом курсор закрывать. это должно быть быстрее, чем top c fullscan-ом вдогонку.
PS я сначала написал, а потом только прочитал предыдущий комментарий :)
так как привязка к городу обязательна, нет смысла в outer join-ах.
если это не подходит, можно, сосчитав count(*) ом количество людей по городам, сделать select from people where cityid in(… )
количество вернувшихся записей — можно отсекать в коде. в вернувшемся курсоре проходить по нужному кол-ву записей, потом курсор закрывать. это должно быть быстрее, чем top c fullscan-ом вдогонку.
PS я сначала написал, а потом только прочитал предыдущий комментарий :)
Народ, а почему никто не смотрит на план выполнения запроса? Он же не просто так приведен.
Смотрим — насколько я понимаю (не спец в SQLServer), он делает Full Scan Cities, затем по индексу приджойнивает таблицу People.
А нам, по идее, — нужно сделать наоборот — один раз пройтись по People, при этом джойня (по индексу) таблицу Cities, затем отсортировать и выбрать 100 первых.
В оракле было бы так:
p.s.: сущности именуются в именительном падеже (City, а не Cities)
Смотрим — насколько я понимаю (не спец в SQLServer), он делает Full Scan Cities, затем по индексу приджойнивает таблицу People.
А нам, по идее, — нужно сделать наоборот — один раз пройтись по People, при этом джойня (по индексу) таблицу Cities, затем отсортировать и выбрать 100 первых.
В оракле было бы так:
select person, city from (select /*+ ordered use_nl(p c) index(c cities$cityid) */ rownum r, p.name person, c.name city from person p left join cities c on p.cityid = c.cityid order by c.name) where r <= 100
p.s.: сущности именуются в именительном падеже (City, а не Cities)
Вообще, есть правило — при джойне таблиц, различающихся в несколько раз, один проход надо проводить по большой таблице. Тогда будет быстро.
«насколько я понимаю (не спец в SQLServer), он делает Full Scan Cities, затем по индексу приджойнивает таблицу People.»
А вы неправильно понимаете. Он одновременно читает две таблицы полностью, потом делает джойн. Почему он читает Cities целиком? Потому что у него есть статистика, которая говорит, что будут задействованы все значения, а не только часть — поэтому выгоднее прочитать сто строк в память.
" один раз пройтись по People, при этом джойня (по индексу) таблицу Cities, затем отсортировать и выбрать 100 первых."
Вот он так и делает, только Cities берет не по индексу с диска, а из памяти (что эффективнее).
«сущности именуются в именительном падеже (City, а не Cities)»
А не надо путать падеж и число. И соглашений об именовании таблиц в базе, как бы, больше одной.
А вы неправильно понимаете. Он одновременно читает две таблицы полностью, потом делает джойн. Почему он читает Cities целиком? Потому что у него есть статистика, которая говорит, что будут задействованы все значения, а не только часть — поэтому выгоднее прочитать сто строк в память.
" один раз пройтись по People, при этом джойня (по индексу) таблицу Cities, затем отсортировать и выбрать 100 первых."
Вот он так и делает, только Cities берет не по индексу с диска, а из памяти (что эффективнее).
«сущности именуются в именительном падеже (City, а не Cities)»
А не надо путать падеж и число. И соглашений об именовании таблиц в базе, как бы, больше одной.
А, тут же не nested_loops, а hash join. Тогда да — один раз прочитать то, один раз другое, и джойн по хешу.
«Потому что у него есть статистика, которая говорит, что будут задействованы все значения, а не только часть — поэтому выгоднее прочитать сто строк в память.» — сто каких строк он будет читать? Сто первых строк из Cities? Сомневаюсь.
«Потому что у него есть статистика, которая говорит, что будут задействованы все значения, а не только часть — поэтому выгоднее прочитать сто строк в память.» — сто каких строк он будет читать? Сто первых строк из Cities? Сомневаюсь.
как насчет group by?
вместо order в конце сделать group by по городам. а вообще постараться уйти от джойнов. возможно просто select distinct. у нас же нет условия уникальности на выходе…
Если честно, то предложенное решение очень костылявое — в исходном запросе order by nulls last и order by nulls first дадут разные результаты.
А если NULLы не нужны — зачем заморачиваться с left join'aми — inner join и будет быстро работать.
А если NULLы не нужны — зачем заморачиваться с left join'aми — inner join и будет быстро работать.
select top 100 p.name person, c.name city from person p, cities c where p.cityid = c.cityid order by c.name
Чуть ниже есть еще один мой длинный комментарий, однако, увидев этот пост, хочу к нему тоже добавиться ;)
По, идее, такой запрос решит проблему «бомжей»:
По, идее, такой запрос решит проблему «бомжей»:
select top 100 person , city from ( select top 100 p.name person , c.name city from person p , cities c where p.cityid = c.cityid order by city , person ) union ( select top 100 p.name person , null city from person p where p.cityid is null order by person ) order by city , person
Ниже много букв:
Решать такую задачу чисто на языке SQL — нерационально (особенно, учитывая факт, что оптимизатор SQL не справляется).
Однако из чисто академических интересов, попробуем решить задачу, подсказав оптимизатору последовательность запросов.
Общий план таков:
1) считаем кол-во жителей в каждом городе
2) отбираем минимально достаточное количество городов, в алфавитном порядке так,
чтобы суммарное количество в них было как раз больше 100, но при удалении хоть
одного города меньше 100
3) из полученного списка городов, отбираем всех жителей и выводим первые 100
Стадия 1. Посчитаем количество жителей в каждом городе.
Стадия 2. отбираем минимально достаточное количество городов
Стадия 3. выводим жителей
Несколько замечаний:
* Создание временных табилц можно не делать, но тогда вместо из названия в тех местах, где они используются надо подставить сами запросы — SQL получится многоэтажным :)
* Все выше написанное — теория — проверить не могу — нет MSSQL'я
* Если в таблице enough нет 100 жителей, то придется еще такую структуру добавить:
P.S. может у кого-то хватит терпения проверить? ;-) А если даст положительный результат — объединить все запросы в один, еще раз проверить, постануть его сюда и отчитаться…
Решать такую задачу чисто на языке SQL — нерационально (особенно, учитывая факт, что оптимизатор SQL не справляется).
Однако из чисто академических интересов, попробуем решить задачу, подсказав оптимизатору последовательность запросов.
Общий план таков:
1) считаем кол-во жителей в каждом городе
2) отбираем минимально достаточное количество городов, в алфавитном порядке так,
чтобы суммарное количество в них было как раз больше 100, но при удалении хоть
одного города меньше 100
3) из полученного списка городов, отбираем всех жителей и выводим первые 100
Стадия 1. Посчитаем количество жителей в каждом городе.
create table tmp as
select
Cities.Id
, Cities.Name
, cnt.people
from
(
select
CityId
, count(Name) people
from
People
group by
CityId
) as cnt
join Cities on (Cities.Id = cnt.CityId)
Стадия 2. отбираем минимально достаточное количество городов
create table enough as
select
t2.Id as Id
, max(t2.Name) as Name
, sum(t1.people)+t2.people as people
from
tmp t1,
join tmp t2 on (t1.Name < t2.Name)
group by
t2.Id
having
sum(t1.people) < 100
Стадия 3. выводим жителей
select
top 100 p.Name PersonName
, c.Name CityName
from
People p
join enough c on p.CityId = c.Id
order by
c.Name
, p.Name
Несколько замечаний:
* Создание временных табилц можно не делать, но тогда вместо из названия в тех местах, где они используются надо подставить сами запросы — SQL получится многоэтажным :)
* Все выше написанное — теория — проверить не могу — нет MSSQL'я
* Если в таблице enough нет 100 жителей, то придется еще такую структуру добавить:
select
top 100 Name PersonName
, Name CityName
from
(select *** запрос на Стадии 3 (см.выше) ***)
union (select top 100 Name as PersonName, null as CityName from People where IdCity is null)
order by
CityName
, PersonName
P.S. может у кого-то хватит терпения проверить? ;-) А если даст положительный результат — объединить все запросы в один, еще раз проверить, постануть его сюда и отчитаться…
Sign up to leave a comment.
О, эти планы запросов