Cozypkg: как мы упростили локальную разработку с Helm + Flux
Средний
7 мин
Кейс

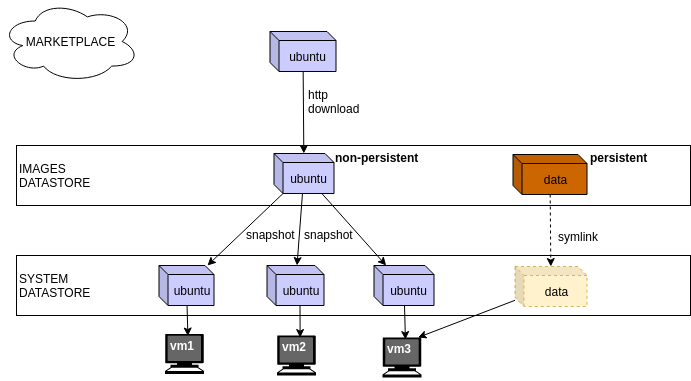
Привет! Я Андрей Квапил (или kvaps) и в этой статье я опишу наш путь организации доставки приложений в Kubernetes, объясню недостатки классического GitOps в локальной разработке и покажу, как новая утилита cozypkg решает эти проблемы. Материал рассчитан на разработчиков, знакомых с Helm и Flux.
У нас есть общий репозиторий — в нем мы описываем общую конфигурацию всех компонентов, а также темплейты для их деплоя. Для того чтобы максимально упростить процесс поддержки каждого из компонентов, мы следуем определенному процессу.В основе этого процесса лежит идея о том, что каждый компонент — это Helm-чарт.