Привет Хабр! Меня зовут Когунь Андрей. В КРОК я руковожу группой разработчиков Java (у нас большая распределённая по всей стране команда). Ещё я провожу встречи московского сообщества Java разработчиков JUG.MSK. Делаю это исключительно в корыстных целях: фотографируюсь там со всеми докладчиками, и однажды открою галерею с самыми интересными людьми в мире Java-разработки. Также помогаю делать конференции для разработчиков: JPoint, Joker и DevOops — в качестве члена программного комитета. Ну и для души, так сказать, преподаю Java-технологии студентам.
В КРОК мы с коллегами в основном занимаемся заказной разработкой. Одно из наших направлений — так называемые учётные системы. Их надо делать по возможности быстро. Они типовые, различия обычно наблюдаются только в доменной модели. Поэтому мы постоянно боремся за то, чтобы писать меньше бойлерплейт-кода, будь то тривиальные геттеры-сеттеры, конструкторы и т.п. или CRUD-репозитории и контроллеры. Мы для этого активно пользуем кодогенерацию.
Про неё сейчас и расскажу: покажу как взять кодогенерацию под контроль, чтобы она стала реально полезным инструментом разработчика. Попутно расскажу про технологию Xtend и покажу практические приёмы как с ней можно работать. Покажу как создавать собственные активные аннотации, писать и отлаживать код процессора аннотаций.

О чём статья и чего в статье не будет
За много лет работы с Java мы перепробовали много чего интересного:
- поддержка генерации в IDE,
- генерация байт-кода при помощи Lombok,
- процессоры аннотаций, порождающие новый код,
- фреймворки, позволяющие по описанию модели получить готовое (почти) приложение,
- и много чего ещё, в том числе новые и не очень JVM-языки, которые позволяют писать более лаконичный код и реализовывать DSL для решения прикладных задач.
В какой-то момент, проанализировав сильные и слабые стороны всех этих подходов, их ограничения и практическую применимость, мы пришли к тому, что в нашем собственном фреймворке для быстрой разработки (jXFW) будем использовать Xtend. Использовать для кодогенерации исходного Java-кода по доменной модели и для аккумулирования того опыта, который мы накопили в работе с различными технологиями. Сейчас расскажу, как в jXFW это всё работает и покажу, как вы можете сделать то же самое для своих нужд. Причём первую версию вы сможете изготовить буквально за пару дней и дальше начать применять подход «know-how как код».
Рассказывать буду на примере упрощённого демо-проекта, который был реализован в рамках доклада на JPoint.
Ремарка: чего в статье не будет:
- Я не хочу, чтобы мы в итоге делали выводы про то, что «технология А» лучше «технологи Б». Или что там Eclipse лучше IDEA или наоборот. Поэтому я не буду напрямую сравнивать какие-то языки, технологии. Всё что упоминаю, это лишь для того, чтобы какую-то аналогию объяснить на понятных примерах.
- Я не буду делать введение в Spring и Spring Boot. Исхожу из того, что вы имеете хотя бы какой-то опыт работы с этими технологиями. Мне кажется, сейчас сложно найти джависта, который не работал с ними. Но если вы вдруг слышите о Spring и Spring Boot впервые, вам срочно надо посмотреть доклады и тренинги Евгения Борисова и Кирилла Толкачева, – там мои коллеги рассказали об этих технологиях очень подробно.
- Не буду очень сильно погружаться в Xtend. Но поскольку, как показывает мой опыт выступления на Java-конференциях, эта технология мало кем используется, сделаю небольшой ликбез. Чтобы вы уже дальше могли для себя решить, нужен вам Xtend или нет.
Короткий ликбез по Xtend
Xtend – это статически типизированный язык программирования, приемник Xpand, построенный с использованием Xtext и компилирующийся в исходный код Java. Технология Xtext нужна для того, чтобы реализовывать всевозможные DSL. По сути, Xtend это такой своеобразный DSL.
Xtend совсем не новый язык программирования. Его создали ещё в 2011, примерно тогда же, когда появлялось большинство JVM-языков. Интересно, что у Xtend был слоган: «Java 10 сегодня!» Да, сегодня Java 10 у нас уже есть, слоган морально устарел. Но, похоже, люди что-то знали про Java, когда создавали Xtend, и некоторые фичи, заложенные в Xtend, они вот как раз прямо в Java 10 и появились. В частности, вывод типа локальной переменной (var). Но есть в Xtend и такие фичи, которых у Java пока ещё нет:
- активные аннотации,
- шаблонные выражения,
- Switch Expressions.
Как работает кодогенератор в jXFW
Теперь расскажу про кодогенерацию в нашем фреймворке jXFW, чтобы наглядно показать, чем она полезна. Расскажу на примере простейшего приложения.
Запускаю Eclipse.
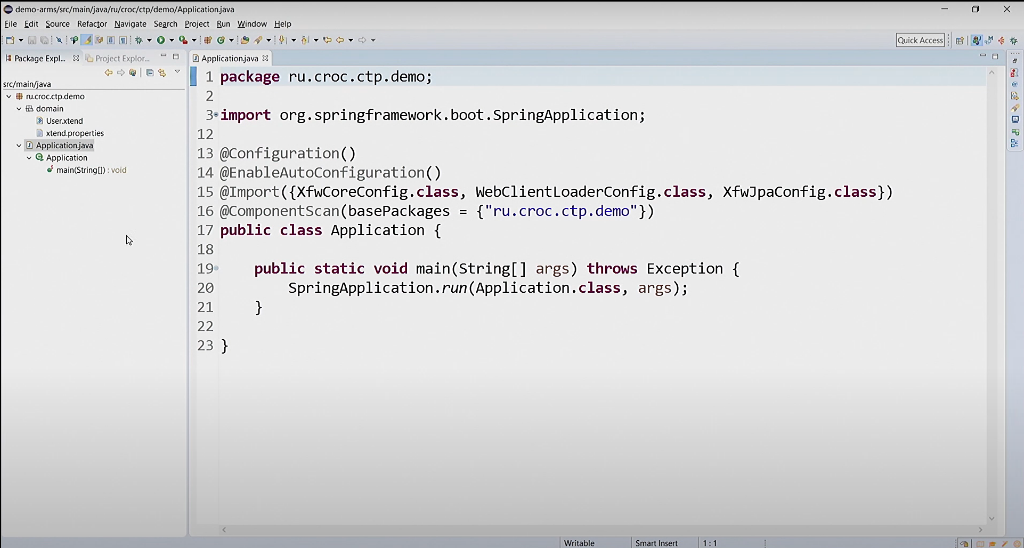
Как видите, здесь практически ничего нет. Только application.java (конфигурация для Spring Boot) и собственно исходник на Xtend, – в нём реализована доменная модель.
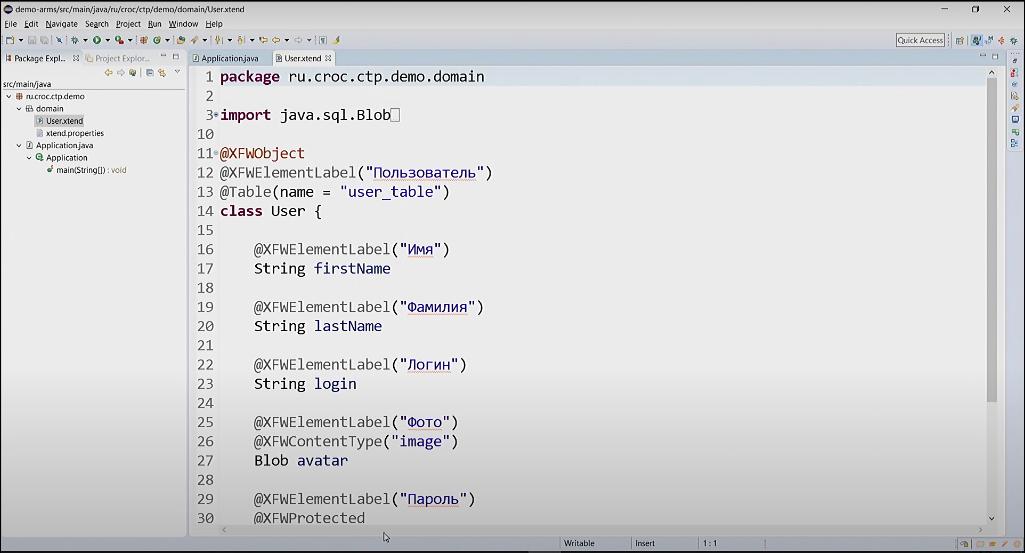
Как видите, Xtend-исходник очень похож на Java. Здесь нет ничего особенного. Просто класс с полями и несколько аннотаций. А что в итоге? jXFW генерирует два приложения (см. рисунок ниже): одно выполняется на сервере (тот самый Spring Boot) и даёт нам апишечку, а другое – на клиенте.
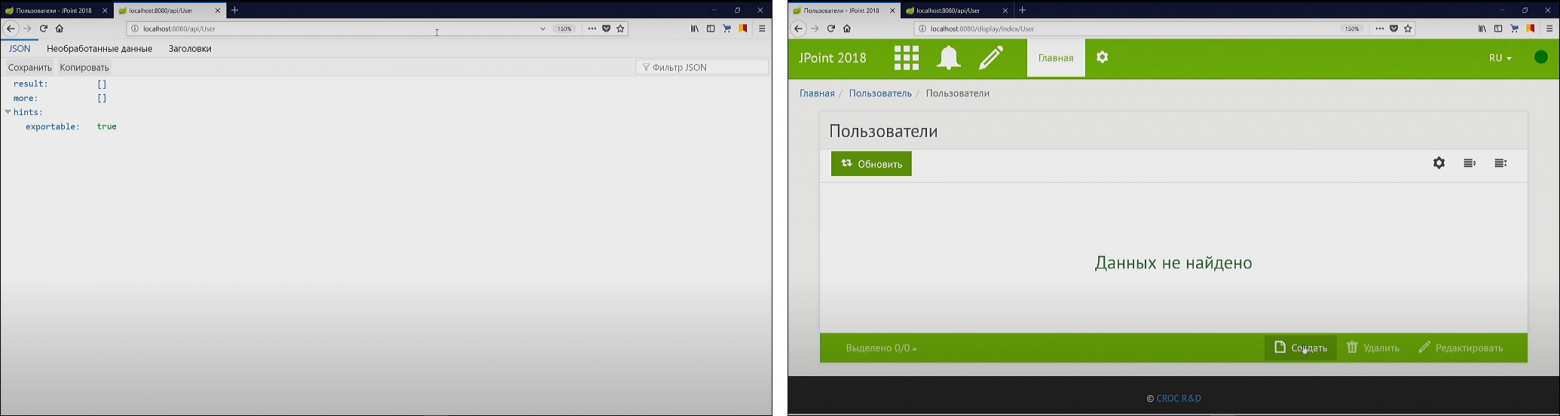
Если мы что-нибудь введём в клиентской части (например, как зовут спикера) и сохраним...
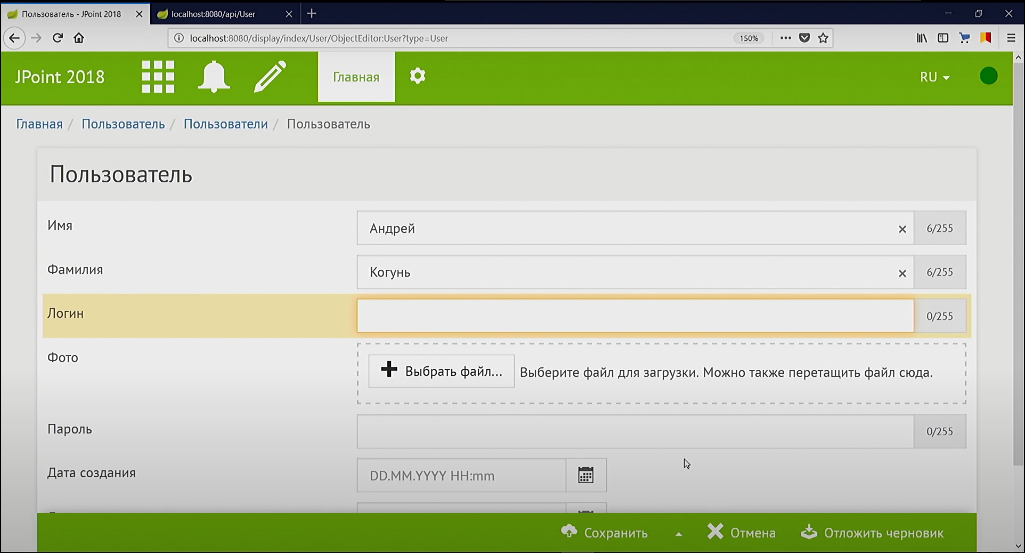
…то получим соответствующую запись и на клиенте, и на сервере.
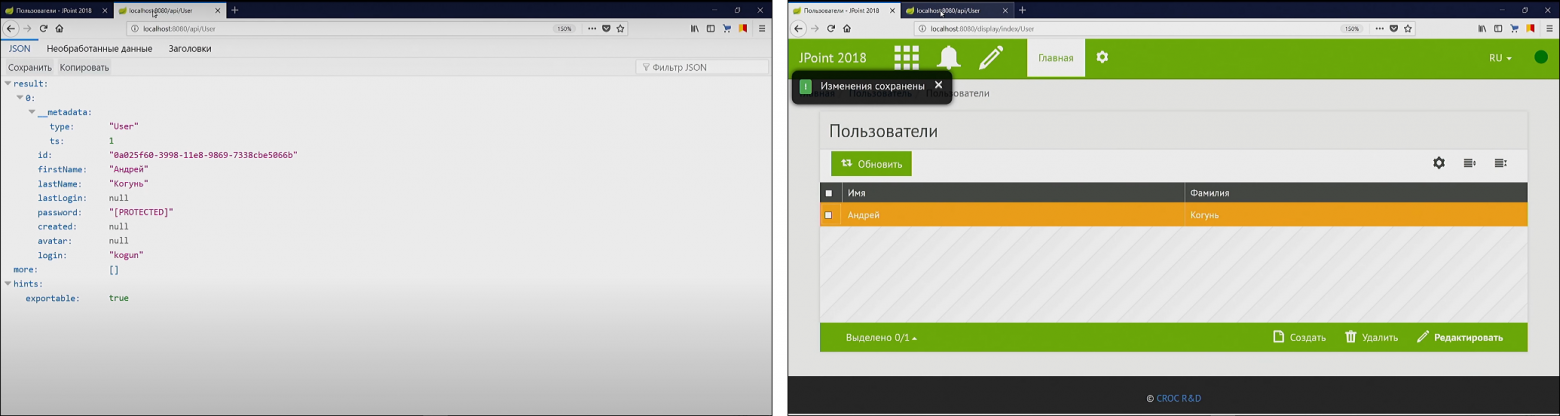
То есть всё по-честному.
Мы просто описали одну сущность доменной модели, и всё автоматически заработало.
Что за магия здесь под капотом? И как в ней замешан Xtend? Рассказываю. У нас есть класс, на нём проставлены аннотации, вернее активные аннотации. Вся магия скрывается в них. Аннотации в Xtend очень похожи на аннотации в Java. Просто в Xtend для них есть отдельное ключевое слово:annotation.

Активной аннотация становятся, если её, в свою очередь, пометить другой аннотацией: @Active, а в ней указать класс процессора, который активируется, когда эта аннотация поставлена над каким-то элементом.

Дальше всё как обычно.
Xtend из коробки имеет некоторое количество таких аннотаций.

Идея здесь примерно такая же, что и в библиотечке Lombok: пишешь только необходимый текст, ставишь аннотацию, и в итоге получаешь полный код.
Если вдруг вам ещё пока не понятно, о чём тут идёт речь, то теперь я буду рассказывать про кодогенерацию медленно и подробно. Результат, как уже сказал, доступен тут.
Как активные аннотации помогают писать меньше кода
Открываем проект jp-boot-xtend-demo. Я его получил при помощи Spring Initializr.
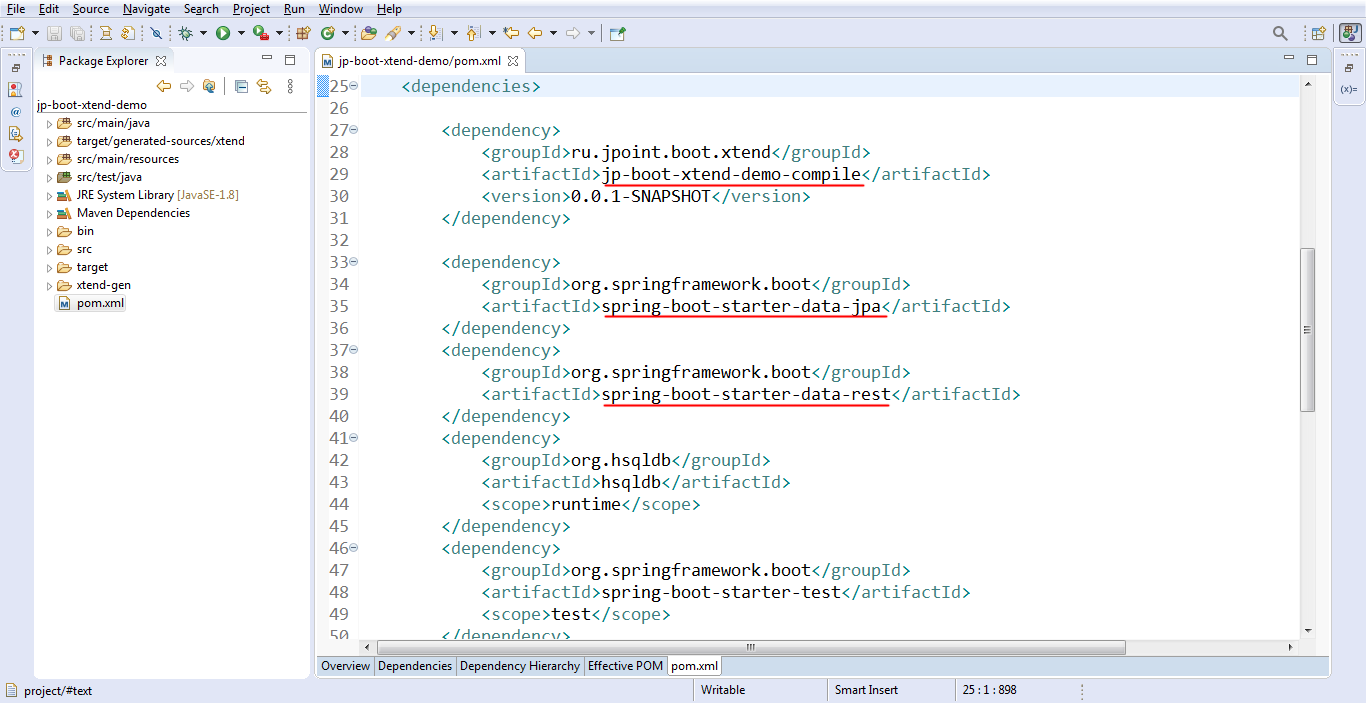
Дополнительных зависимостей здесь практически нет (см. файл pom.xml). Есть только spring-boot-starter-data-jpa и spring-boot-starter-data-rest. Плюс, подключен модуль jp-boot-xtend-demo-compile, в котором реализована наша активная аннотация. Если вам доводилось работать с процессорами аннотаций, вы наверно в курсе, что сам процессор определяется в отдельном модуле. Xtend в этом смысле не исключение.
И уже здесь, в jp-boot-xtend-demo-compile (см. файл pom.xml), мы подключаем все Xtend-зависимости, которые нам нужны: org.eclipse.xtend.lib, org.eclipse.xtend.lib.macro. Плюс, подключаем плагин xtend-maven-plugin. На случай если захотим тестировать наш Xtend-код, нам понадобится ещё несколько зависимостей: org.eclipse.xtend.core, org.eclipse.xtext.testing, org.eclipse.xtext.xbase.testing.
Кроме того, в Eclipse, я соответственно подключил плагин, который называется Xtend IDE. Актуальная инструкция как установить плагин — тут. Ещё один вариант: сразу взять дистрибутив, в котором этот плагин предустановлен — Eclipse for Java and DSL Developers.
Давайте смотреть как тут всё работает. Как и в случае с jXFW здесь есть приложение (см. файл DemoApplication.java), а также Java-класс, который будет нашей Entity, на базе которой мы будем всё строить (см. файл Country.xtend).

При необходимости мы можем сразу посмотреть на то как выглядит Java-файл, сгенерированный из этого Xtend-исходника. Он нам сразу же доступен, и мы можем им пользоваться во всём остальном коде.

Например, в нашем DemoApplication есть кусок кода, который пытается вызывать метод setName. Но пока он красненький.

Я добавляю в Xtend-исходник активную аннотацию @Accessors, и у меня в сгенерированном Java-коде автоматически появляются геттеры и сеттеры, в том числе setName.
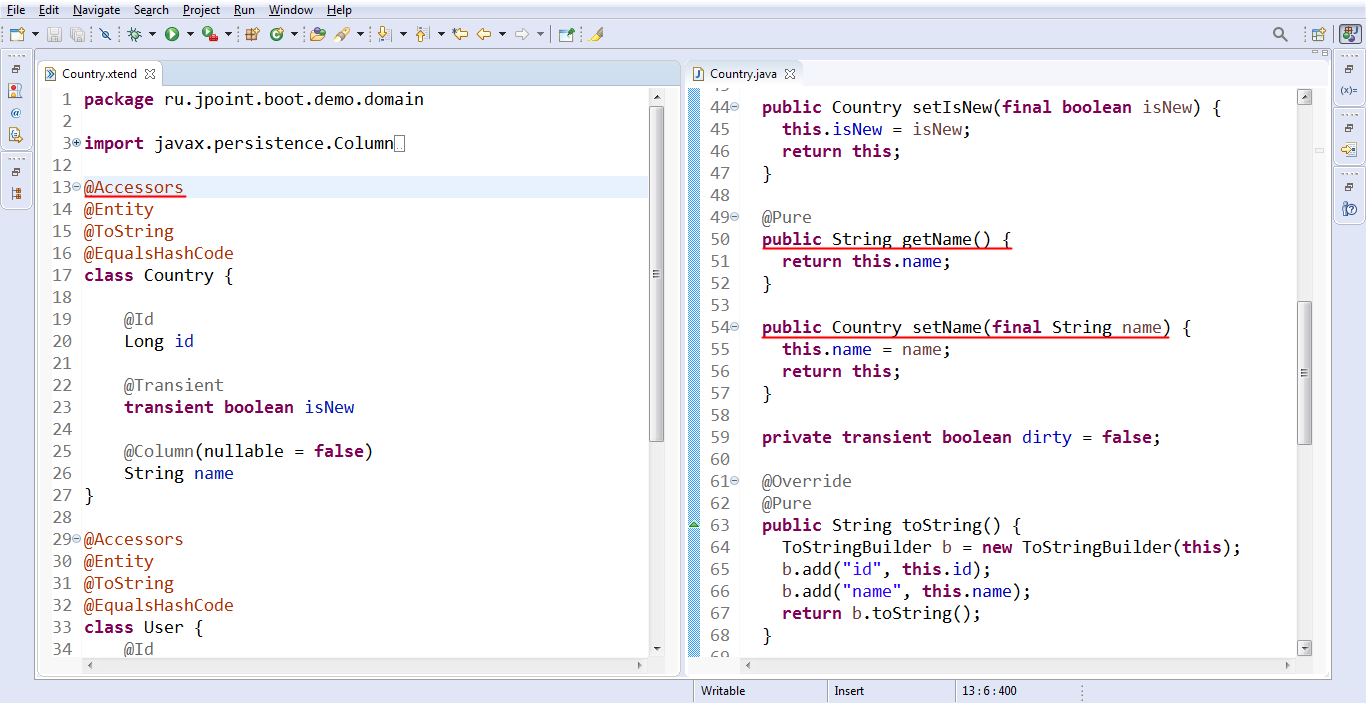
Возможностей управлять активной аннотацией у меня конечно не много, но по крайней мере, я могу сказать что «мне нужны только геттеры».
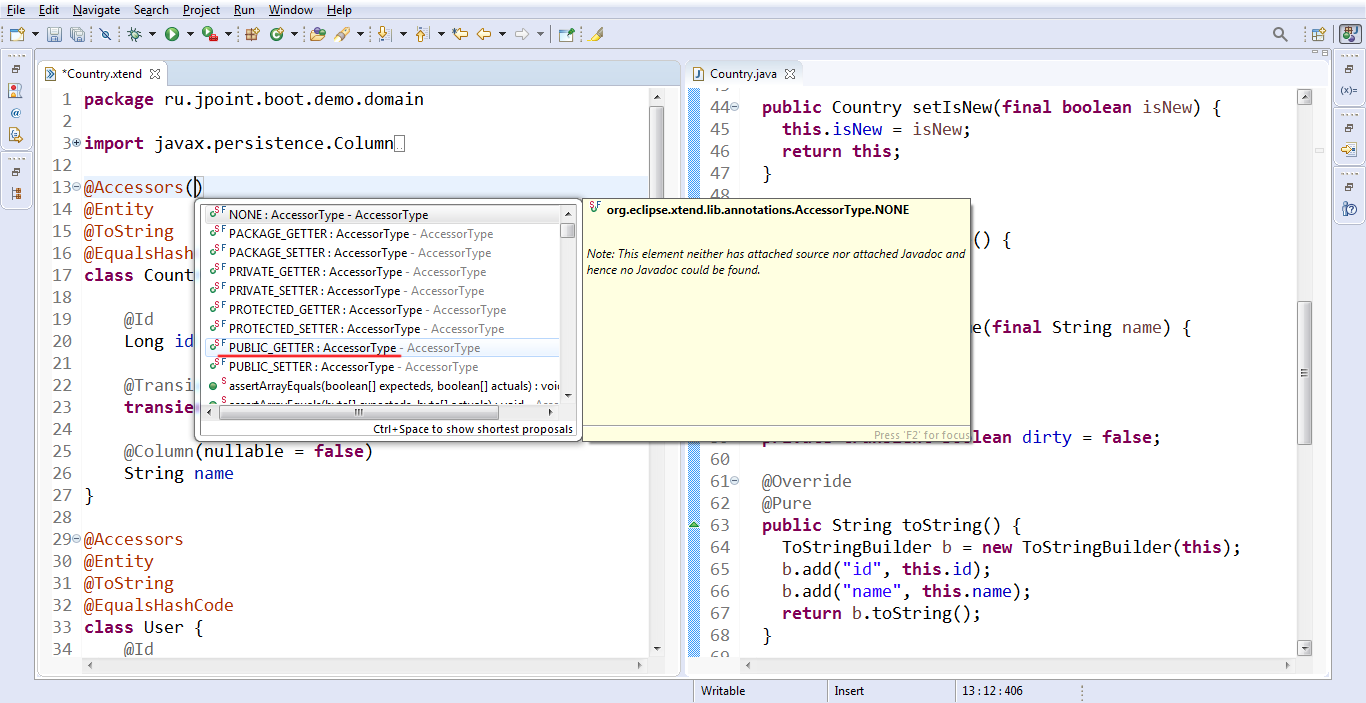
Тут я ещё вписал в Xtend-файл аннотации @ToString и @EqualsHashCode, и в итоге получил Java-исходник прямо такой, как и хотел.
Небольшой лайфхак, который избавит вас от необходимости после каждой правки Xtend-исходника отыскивать в target сгенерированный Java-файл. В Eclipse есть специальная оснастка: Generated Code. Что она делает? Встаньте на любую строчку в Xtend-исходнике, и увидите в окне Generated Code Java-код, который для неё сгенерирован. А оттуда при необходимости уже можете пойти непосредственно в Java-исходник. Вот такая удобная штука.
Самый маленький кодогенератор на основе аннотаций
В принципе, всё хорошо работает. Но как только мы начинаем работать с кодогенерацией, тут же возникает вопрос: «А можно такой же, но только с перламутровыми пуговицами?» Так… Что бы я ещё хотел? Я бы хотел наверно, чтобы у меня сеттеры мои вызывались в цепочке — т.е. не просто устанавливалось значение, но ещё, чтобы и сам объект возвращался из этого сеттера, и я мог на нём следующий позвать.
«Из коробки» в Xtend такой аннотации нет. Поэтому нам придётся её делать ручками. И какие тут есть варианты?
В принципе, мы знаем, что существует аннотация @Accessors — мы посмотрим на её исходный код, увидим, что там есть Accessors Processor, специально написанный. И вот мы уже смотрим на Xtend-код и пытаемся понять, а в каком месте мы могли бы здесь что-то подкрутить, чтобы у нас работало так, как надо. Но это не очень продуктивный путь. Мы по нему не пойдём.
Мы будем писать полностью новую аннотацию. И вот почему. Дело в том, что в активных аннотациях, которые применяются в Xtend, есть возможность привязаться к конкретной фазе компиляции. Т.е. в тот момент, когда AST у нас уже есть, а исходных файлов ещё нет — мы можем как угодно этот наш AST менять. И это очень удобно.
Соответственно, вот эта наша аннотация (это я уже зашёл в проект jp-boot-xtend-demo-compile; см. файл EntityProcessor.xtend) @Active— она нам говорит про те самые четыре фазы, к которым мы можем привязываться. На каждой фазе работает свой собственный Participant-вариант, и мы можем реализовать тот, который нам нужен.
В принципе, есть базовый специальный класс —AbstractClassProcessor, в котором мы оверрайдим метод doTransform. В него нам будут приходить соответственно описания наших классов, помеченных этой аннотацией. И дальше мы, соответственно, что-то делаем.
Ну и вот весь код, собственно говоря, который нам нужно написать, чтобы наши сеттеры стали правильными — такими, как мы хотим.
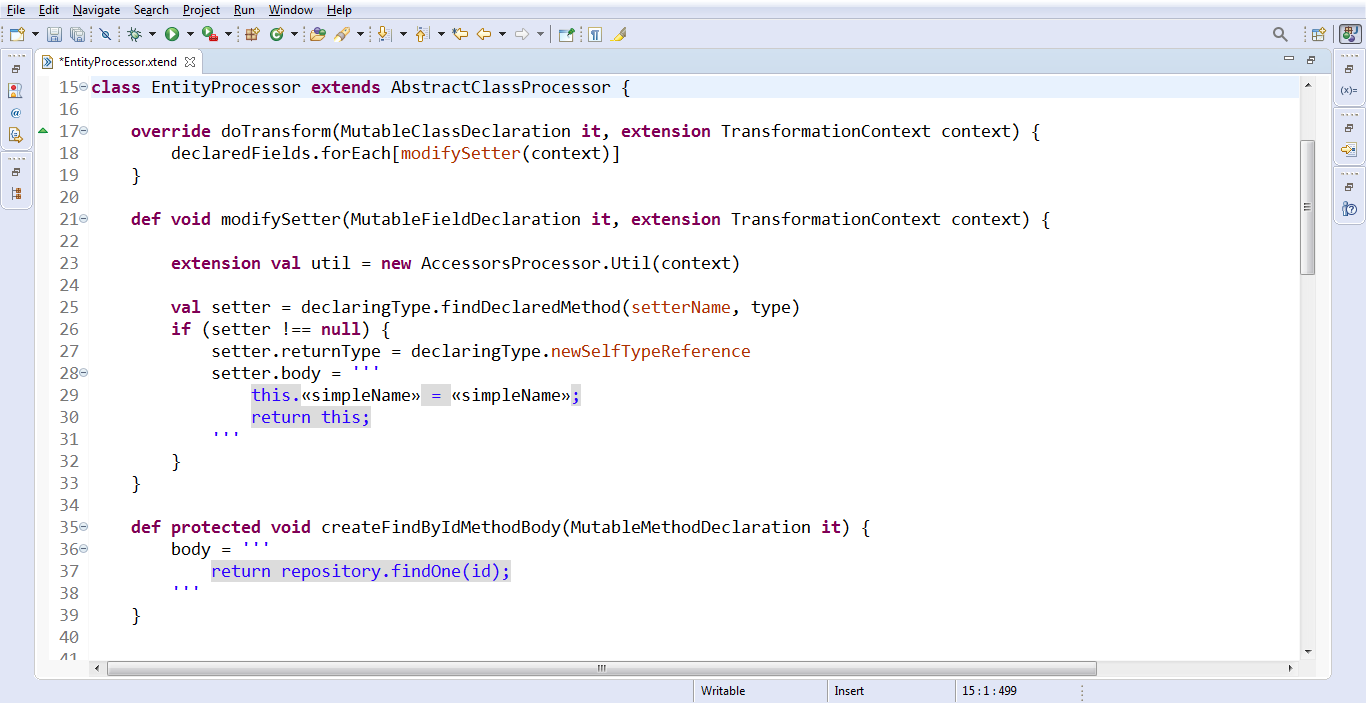
Мне кажется, это самый маленький по объёму код — для генерации при помощи аннотаций – который я видел в жизни.
Что здесь делает Xtend? У него есть вот эти самые шаблонные выражения. Мы ставим три одинарные кавычки, и дальше пишем то, что хотим получить на выходе. И при этом форматируем так, как нам удобно.

А когда ставим фигурные кавычки, — и пользуем simpleName от нашего филда в данном случае, который по совместительству является аргументом, — то сюда подставляется нужное значение.
Код написан на Xtend. Мне кажется читать его, с одной стороны легко, потому что его мало. С другой стороны, он может мне быть понятен сходу. Например, почему мы позвали метод modifySetter, который я определил чуть ниже, и передали в него всего один аргумент?
Дело в том, что в Xtend есть такая вещь как Extension-методы. И у объекта того типа, которым является первый аргумент, можно этот Extension-метод позвать. Хорошо, а почему мы тогда его здесь не указали? Да потому что мы внутри лямбды, а в ней есть переменная it. Когда у нас есть переменная it, к лямбде можно обращаться, не указывая её. То же самое вот с it, который мы указали в качестве аргумента. Поэтому declaredFields-property у MutableClassDeclaration— мы зовём напрямую, безо всяких префиксов.
Это вот всё, что в принципе придётся знать про Xtend.
«А можно такой же, но только с перламутровыми пуговицами?»
Давайте теперь посмотрим как это работает. Я определяю аннотацию @Entity. Затем иду вот в этот наш класс.
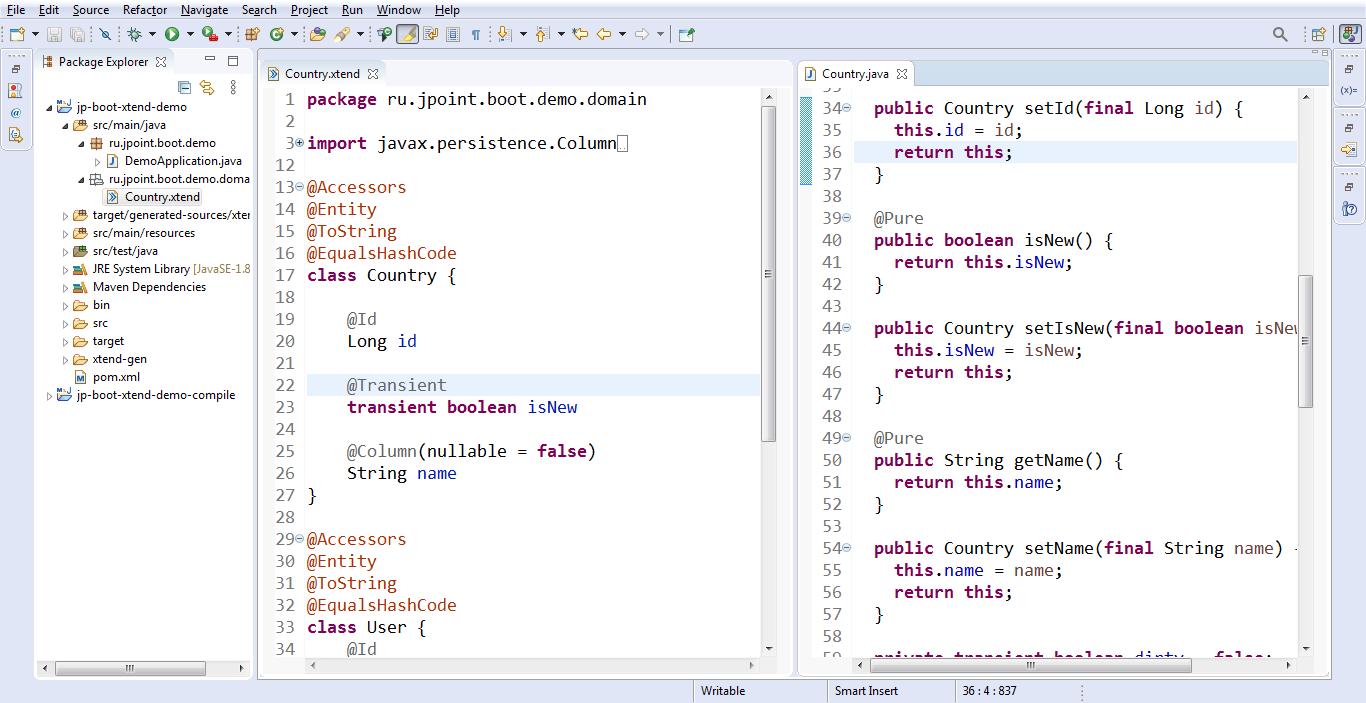
Заменяю текущую @Entity с javax.persistence на свою —на активную аннотацию.
И вот теперь сеттер у нас такой как надо. Т.е. из Country возвращается this— мы возвращаемое значение поменяли с void на тип объекта, над которым стоит аннотация: @Id Long id.
Но, допустим, я хочу, чтобы айдишник сеттился немножко по-другому (всё к той же идее «хочу такое же, но с перламутровыми пуговицами»). Тогда я вписываю в свой класс setID. И оно даже отчасти работает. Ведь сеттер появился в нужном месте — сразу после id.
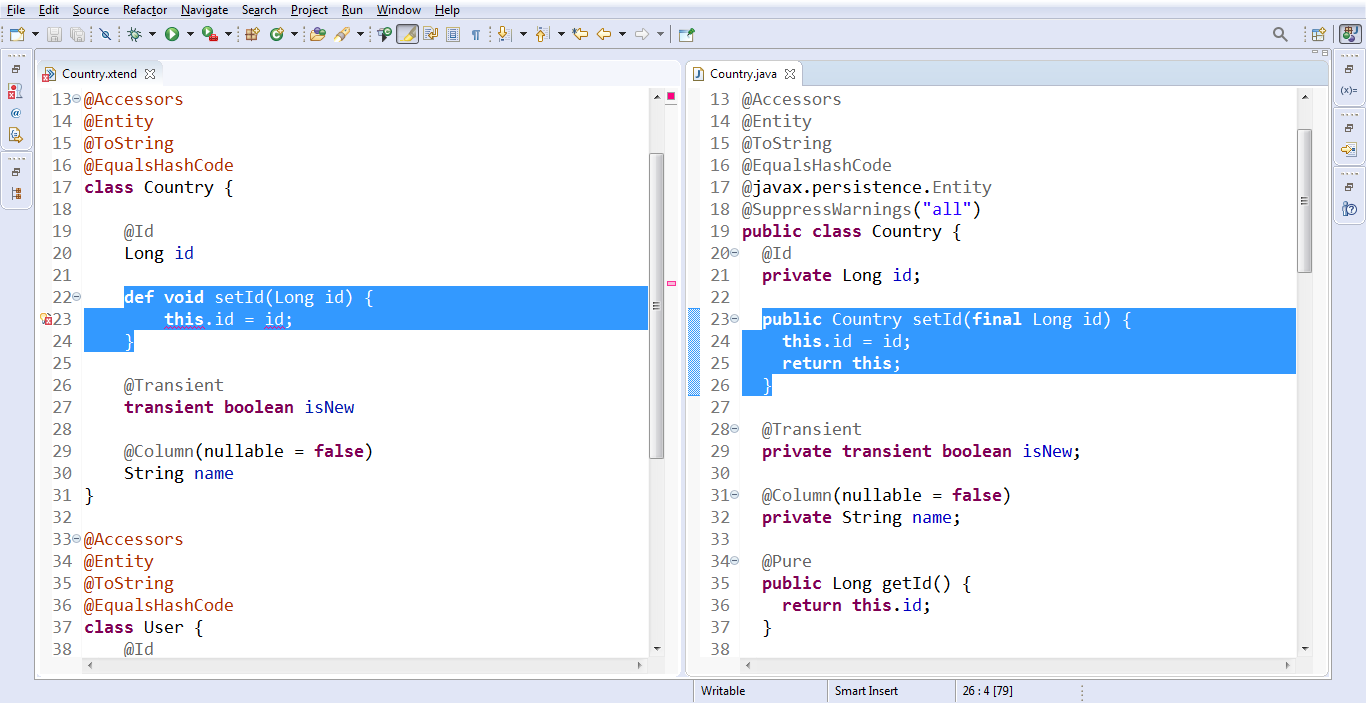
Вот только Eclipse мне здесь немножко подсвечивает и возмущается: «ты мне, вообще, о чём здесь говоришь?»

И хотя в том коде джавовом, который получился, ошибки нет, — он скомпилируется и всё будет работать — в коде есть проблема. Она заключается в том, что мы подменяем тело метода, который определили в Xtend-исходнике.
Поэтому нам надо внимательно следить за тем, чтобы таких казусов не возникало, — когда пишем что-то на Xtend. Как такое отследить? Например, можно у того Transformation-контекста, который сюда приходит, прописать метод isThePrimaryGeneratedJavaElement, и соответственно передать туда сеттер. Получается прямо в таком же стиле, как мы обычно пишем на Java.

То же самое можно написать и по-другому, если вам так привычней.

Теперь всё работает как надо. Ошибки компиляции больше нет, а сеттерный айдишник стал такой как я и хотел.

Насколько это сложно прикручивать новые улучшения? Не увеличивают ли они сложность кода?
Давайте на примере посмотрим. Допустим, мы хотим ещё кое-что улучшить: добавить специальный филд, который можно будет проставлять в сеттере, и который будет признаком того, что наш объект изменился.

Не знаю, для чего в жизни это может пригодиться вам, но лично мне в работе такая штука нужна. Что мы тут указываем? Мы здесь указали имя филда. И дальше опять вот эта наша квадратная скобочка – открываем лямбду; здесь дальше соответственно указываем, что нас интересует. Причём, нам важно, чтобы поле было транзиентное.
И теперь, вот здесь в сеттере – тоже важно, чтобы такое поведение было на все поля, кроме транзиентных. Потому что когда мы меняем транзиентное поле, мы в общем-то не ожидаем, что наш объект будет dirty — ведь эти значения не попадают в хранилище.
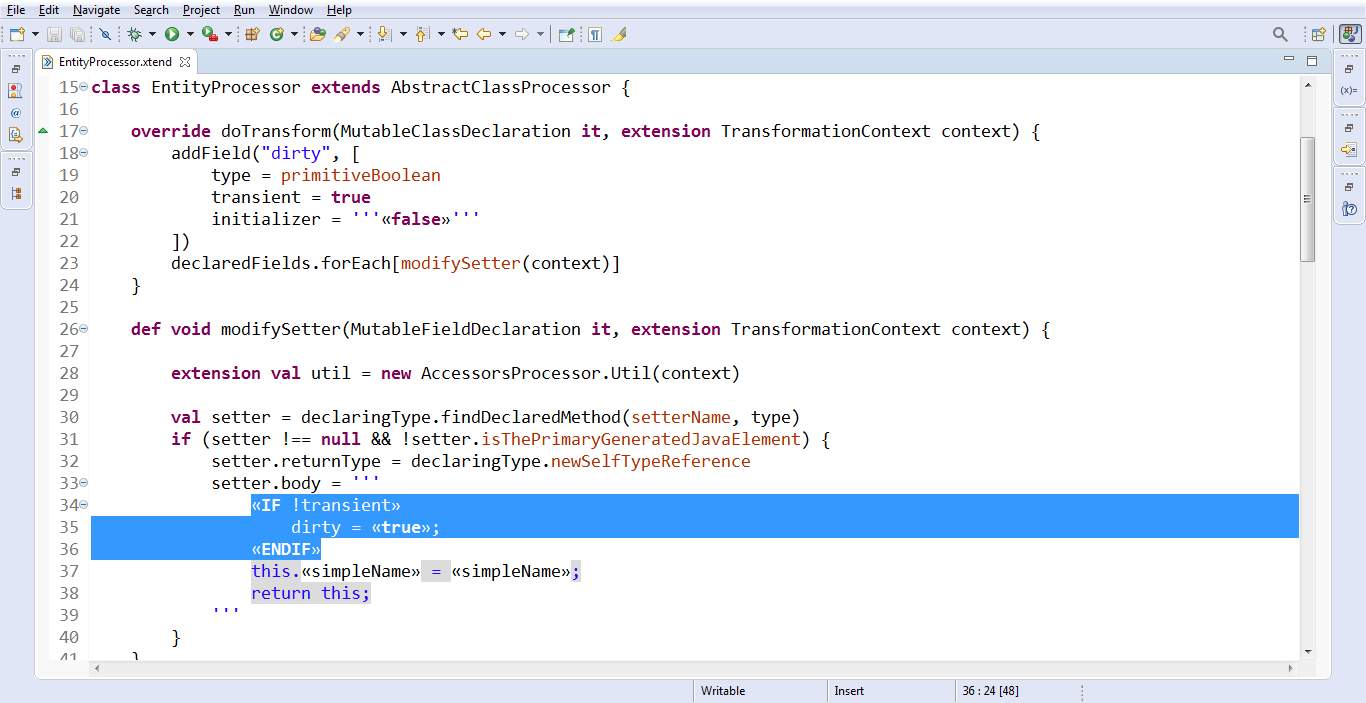
Давайте посмотрим, насколько это нам помогло.

Да, всё хорошо! Причём dirty написано ровно в том месте, где и должно. Нет никаких выкрутасов с отступами и т.д. Код выглядит хорошо и там, и там. Несмотря на то, что получился в результате кодогенерации. Плюс, как видите, код всё ещё остался простым для понимания.
Пишем процессор на смешанном диалекте Xtend и Java
@Entity больше мучить не будем. Убираю её в комментарии. И объявляю ту же самую аннотацию, но на Java (см. файл Entity.java). Здесь, как и на Xtend, всё просто, только чуть больше букв.
Процессор тоже можно писать на Java (см. файл JavaEntityProcessor.java).

Что я тут сделал? Я добавил обработчик для ещё одной фазы: doRegisterGlobals и докинул в контекст классы, которые мне понадобятся: Service и Repository. Плюс, заоверрайдил метод doTransform— тот самый doTransform, который написал чуть раньше на Xtend. Причём я тут нормально навигируюсь по коду. Могу попадать в Xtend-код…

…и обратно в Java-код.

Дальше (см. метод doTransform) я добавляю к нашей entity аннотацию. Обратите внимание, здесь, в отличие от Xtend все методы надо вызывать явно — через context.
Затем идёт метод, который создаёт репозиторий: createRepository. Важный момент: для всего того что мы генерируем, важно указывать PrimarySource: context.setPrimarySourceElement(repositoryType, entity);. Зачем? Чтобы при кодогенерации, — когда у нас появляется Java-файл, — он был связан со своим Xtend-источником.
Дальше немного скучного кода: пользую типы из Spring Data, чтобы указать какой у репозитория должен быть интерфейс.

Дальше прохожусь по всем филдам, и выбирай из них те, которые не транзиентные и не являются айдишниками.

И смотрите, здесь видно, что лямбды в Java очень хорошо дружат с лямбдами в Xtend. Одно на другое взаимозаменяется. Т.е. функциональные интерфейсы все здесь работают. И API был задизайнен так, что сюда джавововые лямбды нормально встают.
Дальше добавляем к нашим филдам всякие разные findBy-методы. Причём смотрим на аннотацию ‘@Column’, которая стоит над филдом. Если она имеет установленный атрибут признака уникальности значения (isUnique), просто возвращаем entityType. Если нет, возвращаем List. В конце ставим аннотацию @Param, которая нужна для того чтобы работал Spring Data Rest.

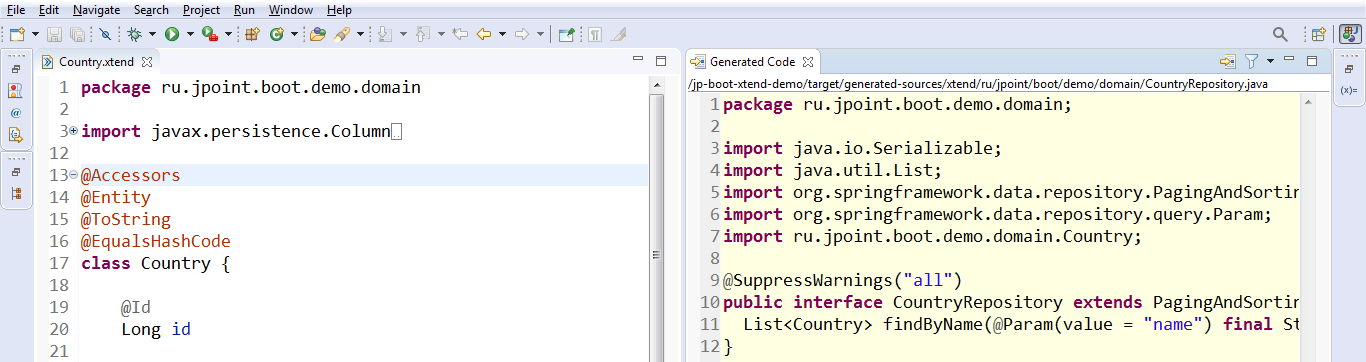
Всё! Для Repository генератор готов. Теперь если откроем Xtend-исходник, на основе которого будет генерироваться Java-код, и посмотрим на Gentrated Code, то здесь у нас добавился ещё и репозиторий. Мы можем смотреть на него, вот он такой.
Дальше пишем генератор для Service. Там всё почти всё так же как и с Repository.
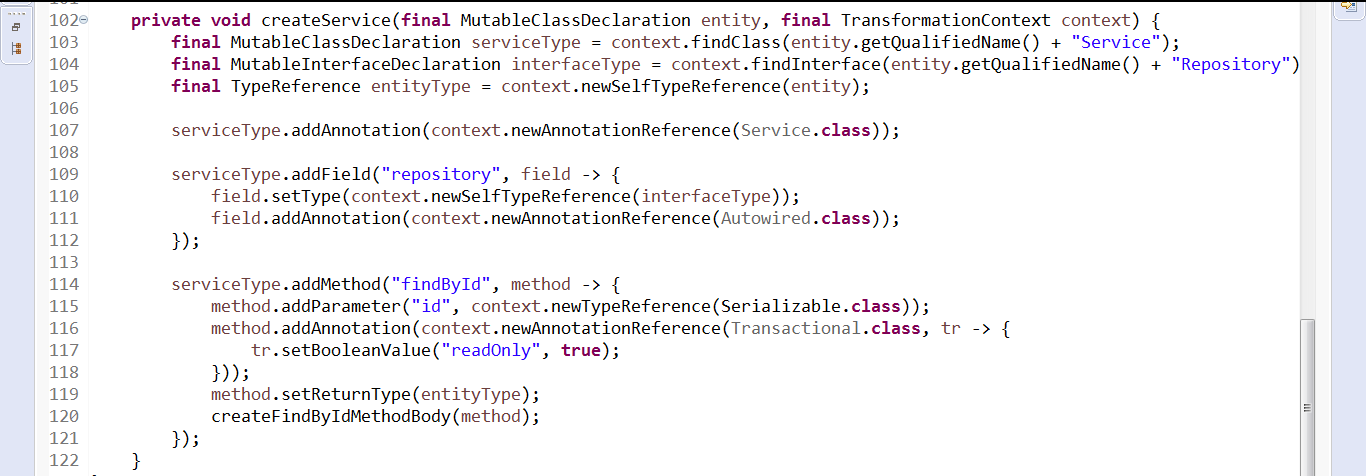
Вот и всё. Процессор готов. Можно запускать сгенерированное приложение.
Ещё несколько улучшений, и запускаем сгенерированное приложение
Хорошо, сервис и репозиторий есть. Но как нам узнать, что у нас с моделью нашей всё хорошо? Добавим ещё одну фазу — фазу валидации. Я добавляю два валидатора.

Теперь, если разработчик, который пишет Extend-код, вдруг забудет поставить перед своим классом аннотацию @ToString, валидатор выведет на экран Warning.

Или если разработчик поставит аннотацию @ManyToOne, а под ней ещё и @Column, то это уже ошибка. А ошибиться-то очень легко. Мы же программируем очень часто на копи-пасте, особенно когда есть возможность всё в один и тот же файл писать, как в Xtend. Скопировали, вроде работает — успокоились. Но можно нарваться на коварную ошибку.
Допустим, у меня в Country.xtend у филда lastName прописано nullable = false, и я хочу, чтобы у Country тоже было nullable = false. Так неправильно. Поэтому Eclipse предупреждает меня. Но при этом генерируется Java код, в котором вроде как нет проблем.
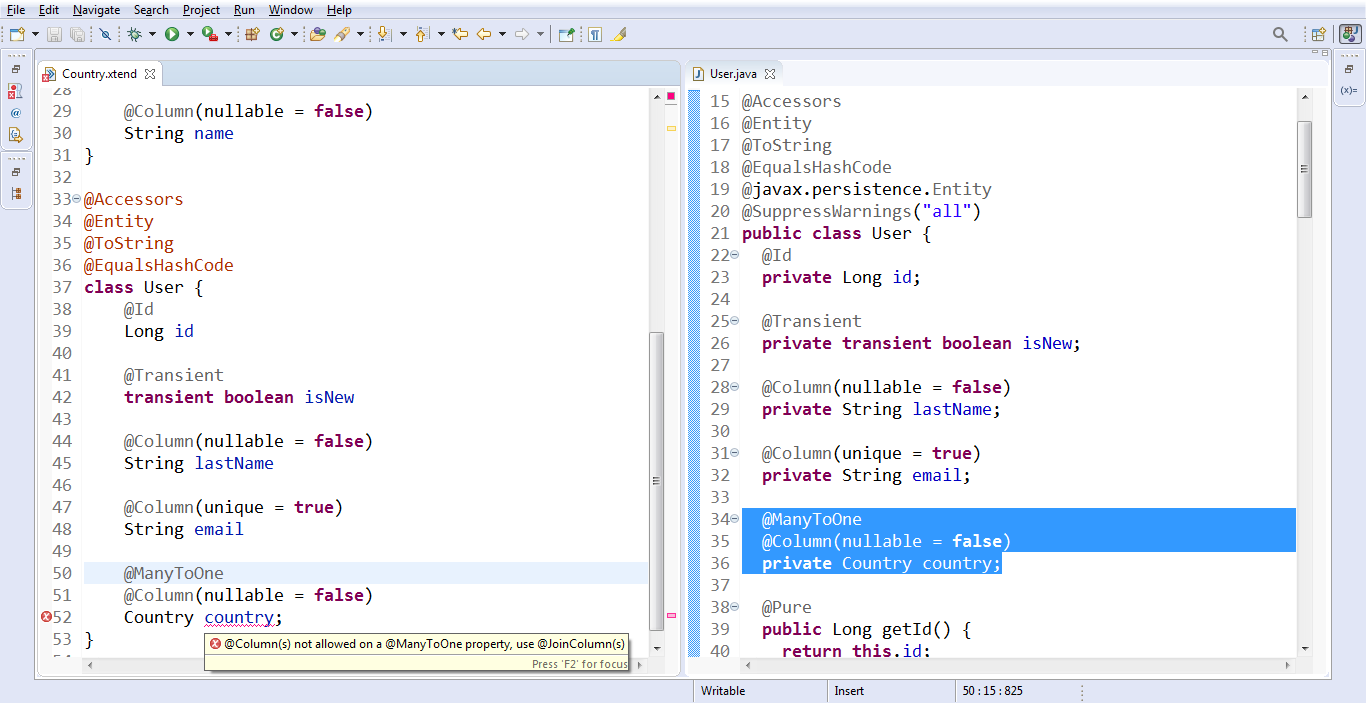
Я меняю на @JoinColumn(nullable = false), и теперь всё хорошо. Можно запускать приложение.
Давайте наберём в браузере localhost:8080…

…затем localhost:8080/users/search.
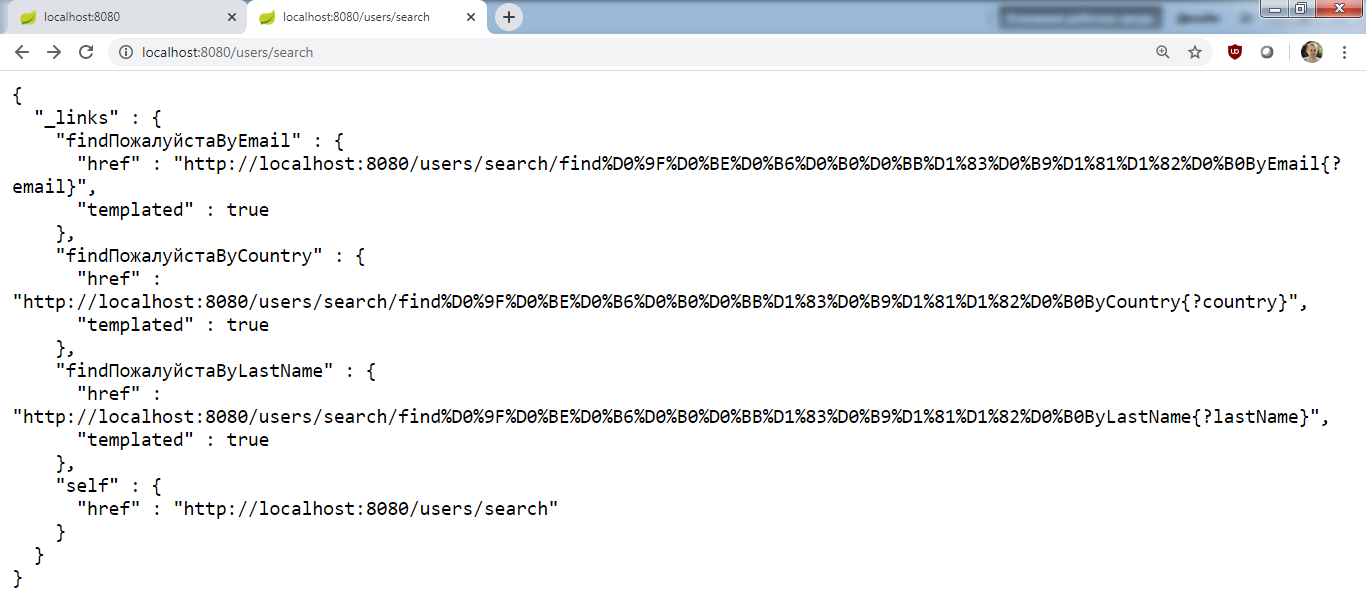
Все наши findBy на месте. Приложение работает!
Пишите меньше кода, делайте меньше ошибок, применяйте технологии правильно
Ну вот и всё. Теперь вы тоже можете брать кодогенерацию под контроль, эффективно использовать её в своей работе. То есть проводить время с пользой: пару дней потерять на то, чтобы создать кодогенаратор, а потом «за 5 минут долететь». Будете писать меньше кода, будете делать меньше ошибок.
Вы теперь умеете создавать собственные активные аннотации, писать и отлаживать код процессора. Причём делать всё это на смешанном диалекте Java и Xtend, без необходимости переносить всю свою кодовую базу на Xtend.
Демо-проект, который мы с вами прямо в этой статье сейчас разработали, — я заопенсорсил на гитхабе. Скачивайте, изучайте, пользуйте. А если информацию легче воспринимаете на слух и с видео, вот мой доклад с конференции JPoint, где рассказываю всё то же самое, что и здесь в статье.
У меня всё. Пишите меньше скучного кода, делайте меньше ошибок, применяйте технологии осознанно. Буду рад ответить на ваши вопросы. Можете писать мне на akogun@croc.ru. Кстати, помните, я в начале статьи говорил, что участвую в подготовке конференций для джавистов? JPoint 2020 из-за известных причин будет проходить онлайн, но это даже совсем неплохо, у нас много отличных спикеров, которые не смогли бы приехать и выступить очно, а сама конференция будет идти целых 5 дней! С 29 июня по 3 июля — jpoint.ru. Приходите!
