
Прим. перев.: Этот материал, написанный опытным разработчиком, не задаётся целью похоронить идею микросервисов, как можно подумать, глядя на заголовок. Статья — разумное предупреждение для тех, кто решил, что микросервисы — это «серебряная пуля», которая сама по себе решает все архитектурные и эксплуатационные проблемы. Для демонстрации этого автор собрал и систематизировал популярные проблемы, зачастую встречающиеся в сегодняшних проектах, уже использующих микросервисы или мигрирующих на них.

В последние годы микросервисы стали очень популярной темой. «Микросервисное безумие» выглядит примерно так:
Велико множество случаев, когда были предприняты значительные усилия для внедрения микросервисных паттернов без обязательного понимания того, к каким минусам и плюсам это приведёт в контексте конкретной решаемой проблемы.
Я расскажу в подробностях о том, что такое микросервисы, почему их паттерн столь привлекателен и в чём заключаются некоторые из основных сложностей на пути их использования. Закончу простыми вопросами, которые стоит себе задать, когда рассматривается актуальность микросервисного паттерна для своих нужд. Эти вопросы представлены в конце статьи.
Начнём с основ. Вот пример возможной реализации гипотетической платформы шаринга видео: сначала в монолитном представлении (один большой блок), а затем — в микросервисном.
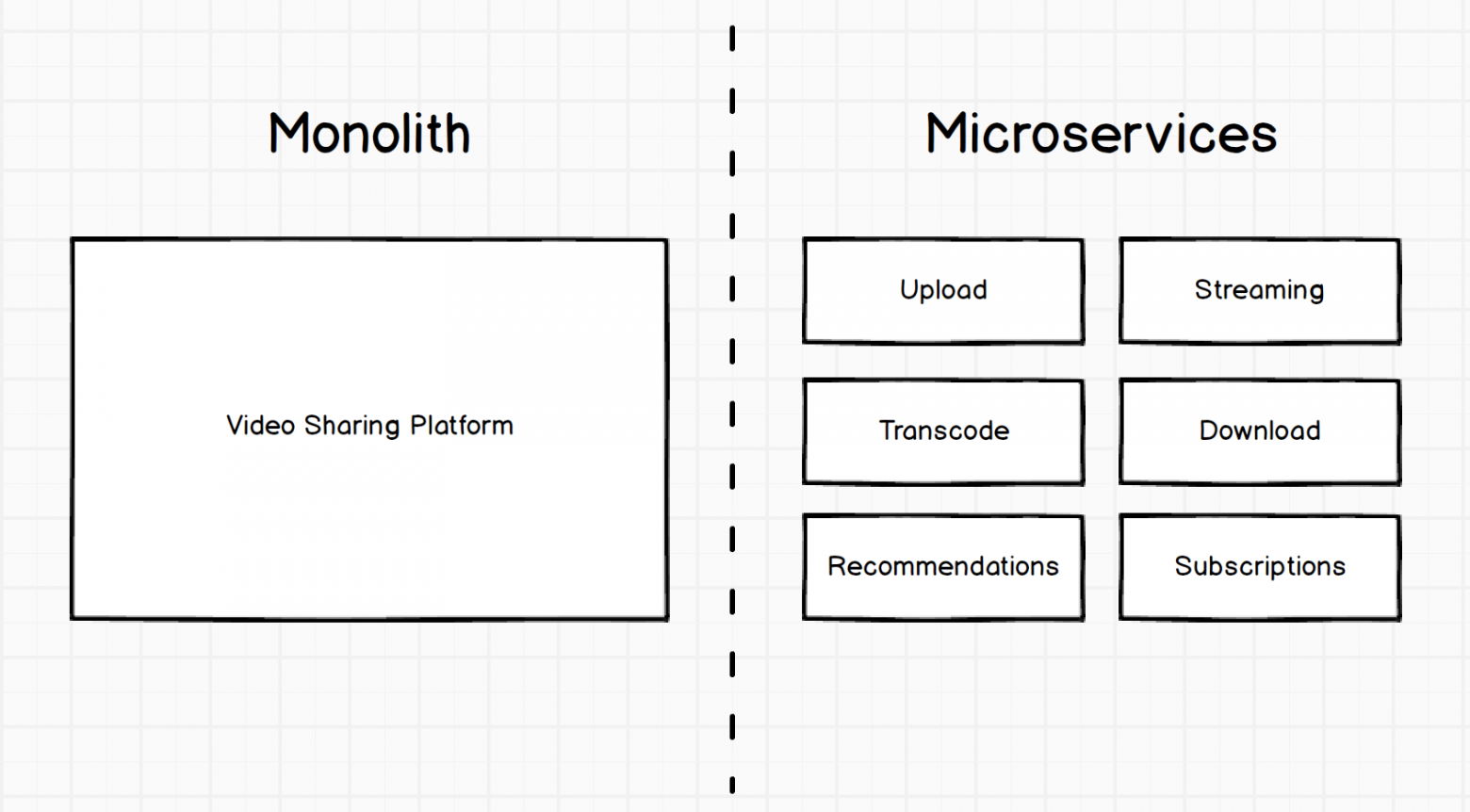
Разница между этими двумя системами заключается в том, что первая — единый большой блок, т.е. монолит. Вторая — набор из маленьких специфичных сервисов. У каждого сервиса своя конкретная роль.
Когда схема представлена на таком уровне детализации, легко увидеть её привлекательность. Тут целый набор из потенциальных плюсов:
Независимая разработка. Маленькие независимые компоненты могут создаваться маленькими независимыми командами. Группа может работать над изменениями в сервисе Upload, не затрагивая сервис Transcode и даже не зная о нём. Объём времени, необходимого для изучения компонента, значительно снижается, и разрабатывать новые функции становится проще.
Независимое развёртывание. Каждый отдельный компонент можно деплоить независимо. Это позволяет выпускать новые фичи быстро и с меньшими рисками. Исправления или фичи для компонента Streaming можно деплоить без необходимости в деплое других компонентов.
Независимая масштабируемость. Каждый компонент можно масштабировать независимо от другого. Во время повышенного пользовательского спроса, когда выходят новые передачи, компонент Download можно отмасштабировать для увеличившейся нагрузки без необходимости в масштабировании каждого компонента, что делает масштабирование гибким и снижает расходы.
Возможность повторного использования. Компоненты реализуют свою маленькую конкретную функцию. Это означает, что их проще адаптировать для использования в других системах, сервисах или продуктах. Компонент Transcode может быть использован другими подразделениями бизнеса или даже превращён в новый бизнес, предлагающий услуги транскодирования другой аудитории.
На таком уровне детализации преимущества микросервисной модели над монолитной кажутся очевидными. Если всё так, то почему паттерн вошёл в моду только теперь? Где же он был всю мою жизнь?
Есть два ответа на этот вопрос. Первый — вообще-то делали, в меру технических возможностей. Второй — недавние технологические улучшения позволили нам выйти в этом подходе на новый уровень.
Когда я начал подготовку ответа на этот вопрос, получилось длинное описание, поэтому лучше выделю его в отдельную статью и опубликую её чуть позже. Здесь же будут опущены путь от одной программы ко множеству, ESB (enterprise service bus, т.е. «сервисная шина предприятия» — прим. перев.) и SOA (service-oriented architecture, т.е. «сервис-ориентированная архитектура» — прим. перев.), проектирование компонентов и bounded contexts («ограниченный контекст» — паттерн из Domain-Driven Design — прим. перев.) и т.п.
Вместо всего этого напишу, что во многих смыслах мы уже делали всё это некоторое время, но только с недавним взрывным ростом контейнерных технологий (в особенности — Docker) и технологий оркестровки (таких, как Kubernetes, Mesos, Consul и др.) паттерн стал гораздо более целесообразным в реализации с технической точки зрения.
Если взять за данность возможность реализации микросервисного подхода, необходимо внимательно подумать о необходимости. Мы увидели высокоуровневые теоретические преимущества, но что насчёт сложностей?
Если микросервисы так прекрасны, в чём дело? Вот некоторые из самых значимых проблем, что мне довелось увидеть.
Жизнь разработчиков может стать значительно тяжелее. Если разработчик захочет поработать над фичей, затрагивающей множество сервисов [journey], ему придётся запускать все их на своей машине и подключаться к ним. Зачастую это сложнее, чем просто запустить одну программу.
Эту сложность можно частично облегчить с помощью соответствующих инструментов [tooling], но чем больше количество сервисов, составляющих систему, тем больше сложностей у разработчиков будет возникать при запуске системы в целом.
У команд, которые не разрабатывают сервисы, а поддерживают их, случится взрыв в потенциальной сложности. Вместо возможного управления несколькими запущенными сервисами, им придётся работать с десятками, сотнями или тысячами. Больше сервисов, больше способов их взаимодействия и больше возможностей для потенциальных проблем.
Глядя на два предыдущих пункта, может показаться — особенно из-за популярности DevOps как практики (большим сторонником которой я являюсь), — что эксплуатация и разработка рассматриваются отдельно. Так вот не становится ли всё лучше благодаря DevOps?
Сложность в том, что многие организации по-прежнему имеют отдельные команды разработки и эксплуатации, и в таких случаях им скорее всего придётся нелегко в адаптации микросервисов.
Для организаций, уже применяющих DevOps, всё тоже не так просто. Быть одновременно и разработчиком, и сисадмином уже тяжело (но критично для создания хорошего программного обеспечения), а с необходимостью также понимать нюансы систем оркестровки контейнеров и в особенности систем, которые стремительно развиваются, ещё тяжелее. Так я прихожу к следующему пункту.
Результаты могут быть замечательными, если работу делали эксперты. Но представьте организацию, в которой не всё идеально с работой единой монолитной системы. Почему же при росте количества систем, что усложняет эксплуатацию, ситуация станет лучше?
Да, с эффективной автоматизацией, мониторингом, оркестровкой и т.п. — всё это возможно. Однако сложностью редко является технология — обычно же это поиск людей, которые могут её эффективно использовать. Спрос на такие навыки сейчас огромен, найти их непросто.
Во всех примерах, использовавшихся для описания преимуществ микросервисов, речь шла о независимых компонентах. Однако во многих случаях компоненты не являются попросту независимыми. Если на бумаге определённые области и могут выглядеть связанными, то в действительности, когда вы докапываетесь до всех деталей, легко обнаружить, что всё гораздо сложнее, чем в предполагаемой модели.
Здесь-то всё и становится очень сложным. Если границы по-настоящему хорошо не определены, случится так, что — даже в случае теоретической возможности изолированного деплоя сервисов — всплывут взаимные зависимости между сервисами, из-за которых придётся деплоить наборы сервисов как группу.
В свою очередь это означает, что необходимо поддерживать согласованные версии сервисов, которые были проверены и протестированы в работе друг с другом. Выходит, что системы, части которой можно деплоить независимо, в действительности нет, потому что для деплоя новой фичи придётся внимательно управлять деплоем множества сервисов.
В предыдущем примере упомянута иногда возникающая необходимость одновременного выката множества версий множества сервисов при деплое фичи. Хочется сказать, что продуманные техники деплоя облегчат жизнь: например, сине-зелёный деплой [blue/green deployments] (требуют минимальных усилий в большинстве платформ для оркестровки сервисов) или параллельный запуск множества версий сервиса с возможностью выбора подходящей на стороне их пользователя.
Эти техники устраняют многие препятствия, если сервисы — stateless. Но работать со stateless-сервисами вообще-то довольно просто. Собственно, если у вас stateless-сервисы, рекомендую подумать о том, чтобы пропустить все эти микросервисы и использовать модель serverless.
В реальности же многим сервисам требуется хранить состояние [state]. Примером для платформы шаринга видео может служить услуга подписки. Пусть новая версия сервиса подписки хранит данные в БД нового вида. Если оба сервиса запущены в параллель, то у вас система, одновременно использующая две схемы. Если вы делаете сине-зелёный деплой, а другие сервисы зависят от данных в новом виде, их необходимо обновить в то же самое время. Если деплой сервиса подписки прошёл неудачно и откатывается, то скорее всего необходимо откатить и эти сервисы тоже, и далее «по каскаду».
Опять же, заманчиво думать, что с базами данных из мира NoSQL подобные связанные со схемой проблемы уйдут, но это не так. Базы данных, которые не требуют строгих схем, не означают отсутствие схем у системы, потому что по сути это просто означает необходимость управления схемой на уровне приложения, а не на уровне СУБД. Нельзя искоренить фундаментальную проблему понимания вида ваших данных и как они изменяются.
Поскольку вы создаёте большую сеть из сервисов, зависимых друг от друга, скорее всего появляется просторное поле для межсервисного взаимодействия. Возникает ряд сложностей. Во-первых, становится больше мест для потенциальных отказов. Необходимо предвидеть возможность того, что сетевые вызовы не сработают, то есть при каждом обращении одного сервиса к другому он должен хотя бы пытаться повторять свои попытки. Когда же сервису необходимо обратиться ко множеству сервисов, ситуация ещё усложнится.
Представьте, что пользователь загружает видео в сервис шаринга. Нам необходимо запустить сервис загрузки, передать данные в сервис транскодирования, обновить подписки, обновить рекомендации и так далее. Все эти вызовы требуют определённой оркестровки, а если что-то сломается, действия нужно повторить.
Логика повторных обращений может стать сложной в управлении. Попытки делать всё синхронно зачастую становятся несостоятельными, потому что имеют слишком много точек отказа. В этом случае более надёжным решением станет использование асинхронных паттернов взаимодействия. Но сложность заключается в том, что из-за асинхронных паттернов система становится stateful. А как уже рассказывалось в прошлом пункте, управлять stateful-системами и системами с распределёнными состояниями очень сложно.
Когда в микросервисной системе используются очереди сообщений для межсервисного взаимодействия, у вас по сути работает большая база данных (очередь сообщений или брокер), склеивающая все сервисы. Опять же, хоть всё это поначалу и не кажется проблемой, схема догонит вас и напомнит о себе. Сервис версии X может писать сообщения в определённом формате, поэтому сервисы, зависящие от такого сообщения, тоже необходимо обновить, когда сервис-отправитель меняет что-то в своём сообщении.
Можно иметь сервисы, которые обрабатывают сообщения во множестве разных форматов, но ими сложно управлять. При деплое новых версий сервисов будет случаться так, что две версии сервиса попытаются обработать сообщения из одной очереди и, возможно, даже из сервисов-отправителей тоже разных версий. Это может привести к запутанным, неадекватным ситуациям. Может оказаться, что для их избежания проще разрешить существовать только определённым версиям сообщений: это означает, что придётся деплоить согласованные наборы из версий для наборов из сервисов, гарантируя, что сообщения старых версий обрабатываются соответствующим образом (первыми).
Этим снова подтверждается мысль, что, если вдаваться в детали, то независимые развёртывания не всегда работают, как предполагалось.
Для преодоления упомянутых препятствий необходимо очень осторожно управлять версиями. Опять же, есть тенденция полагать, что следование стандарту вроде semver решит проблему. Это не так. Semver — соглашение, которое целесообразно использовать, но вам всё равно придётся следить за версиями сервисов и API, которые могут взаимодействовать.
Очень быстро можно прийти к значительным трудностям и оказаться в ситуации, когда вы не знаете, какие версии сервисов в действительности корректно работают друг с другом.
Общеизвестно, как тяжело управлять зависимостями в программных системах, будь то модули для Node или Java, библиотеки для Си и т.п. Очень сложно разбираться с проблемами конфликтов независимых компонентов, используемых одной сущностью.
С этими проблемами сложно совладать, когда зависимости статичны и могут быть пропатчены, обновлены, отредактированы и так далее. Если же в роли зависимостей выступают работающие сервисы, уже не получится просто обновить их: потребуется запустить несколько версий (с описанными выше проблемами) или приостановить работу системы, пока всё в целом не будет исправлено.
В ситуациях, когда во время эксплуатации необходима транзакционная целостность, микросервисы могут оказаться большой болью. Непросто работать с распределённым состоянием, а множество небольших компонентов, которые могут сломаться, делают оркестровку транзакций по-настоящему тяжёлой.
Может показаться привлекательным попробовать избежать проблемы, делая операции идемпотентными, предлагая механизмы повторных попыток и т.п. — и во многих случаях это сработает. Однако могут быть сценарии, в которых попросту нужна успешная или неуспешная транзакция, без промежуточного состояния. Сложность обходного решения этой задачи или её реализация в микросервисной модели может оказаться очень высокой.
Да, отдельные сервисы и компоненты могут деплоиться изолированно, однако в большинстве случаев будет запускаться какая-то платформа для оркестровки вроде Kubernetes. Если же вы пользуетесь управляемым сервисом вроде GKE от Google или EKS от Amazon, большая часть сложностей управления кластером решена за вас.
Однако, если вы сами управляете кластером, то работаете с большой, сложной и критически важной системой. Хоть у отдельных сервисов и могут быть все преимущества, описанные выше, необходимо очень вдумчиво управлять кластером. Развёртывание такой системы может быть сложным, обновления — сложными, failover — сложным и т.п.
Во многих случаях общие преимущества остаются, однако важно не упрощать и не недооценивать дополнительную сложность, вызванную управлением ещё одной большой и сложной системой. Управляемые сервисы способны помочь, но зачастую они слишком молоды (например, Amazon EKS был анонсирован лишь в конце 2017 года).
Избегайте безумия, принимая осмотрительные и обдуманные решения. А в помощь для этого я подготовил несколько вопросов, которые вы можете задать себе, и пояснений к ответам на них. Прим. перев.: оригинальное изображение-схема переведено и представлено в текстовом виде ниже.
Можно ли усадить всю вашу команду за один большой стол?
Ваша система является преимущественно stateless?
Вы собираете решение для одного приложения или сервиса?
У вас есть монолитные зависимости?
Есть ли у вас эксперты по контейнерам, оркестровке, DevOps?
Скачать оригинальный PDF со всеми вопросами-ответами (на английском языке) можно здесь.
Я умышленно избежал слова на «a» в этой статье. Но мой друг Zoltan, проверяя её, сделал очень хорошее замечание.
Микросервисной архитектуры не существует. Микросервисы — это просто ещё один паттерн или реализация компонентов, ни больше ни меньше. Представлены они в системе или нет — не означает, что архитектура системы готова.
Микросервисы во многом больше относятся к техническим процессам, связанным с упаковыванием и эксплуатацией, чем к самой архитектуре системы. Уместные границы для компонентов остаются одной из главных сложностей в инженерных системах.
Вне зависимости от размера ваших сервисов, находятся ли они в Docker-контейнерах или нет — всегда нужно хорошо подумать о том, как собрать систему воедино. Нет правильных ответов, но есть множество вариантов.
Читайте также в нашем блоге:
В последние годы микросервисы стали очень популярной темой. «Микросервисное безумие» выглядит примерно так:
«Netflix хороши в DevOps. Netflix делают микросервисы. Таким образом, если я делаю микросервисы, я хорош в DevOps».
Велико множество случаев, когда были предприняты значительные усилия для внедрения микросервисных паттернов без обязательного понимания того, к каким минусам и плюсам это приведёт в контексте конкретной решаемой проблемы.
Я расскажу в подробностях о том, что такое микросервисы, почему их паттерн столь привлекателен и в чём заключаются некоторые из основных сложностей на пути их использования. Закончу простыми вопросами, которые стоит себе задать, когда рассматривается актуальность микросервисного паттерна для своих нужд. Эти вопросы представлены в конце статьи.
Что такое микросервисы и почему они так популярны?
Начнём с основ. Вот пример возможной реализации гипотетической платформы шаринга видео: сначала в монолитном представлении (один большой блок), а затем — в микросервисном.
Разница между этими двумя системами заключается в том, что первая — единый большой блок, т.е. монолит. Вторая — набор из маленьких специфичных сервисов. У каждого сервиса своя конкретная роль.
Когда схема представлена на таком уровне детализации, легко увидеть её привлекательность. Тут целый набор из потенциальных плюсов:
Независимая разработка. Маленькие независимые компоненты могут создаваться маленькими независимыми командами. Группа может работать над изменениями в сервисе Upload, не затрагивая сервис Transcode и даже не зная о нём. Объём времени, необходимого для изучения компонента, значительно снижается, и разрабатывать новые функции становится проще.
Независимое развёртывание. Каждый отдельный компонент можно деплоить независимо. Это позволяет выпускать новые фичи быстро и с меньшими рисками. Исправления или фичи для компонента Streaming можно деплоить без необходимости в деплое других компонентов.
Независимая масштабируемость. Каждый компонент можно масштабировать независимо от другого. Во время повышенного пользовательского спроса, когда выходят новые передачи, компонент Download можно отмасштабировать для увеличившейся нагрузки без необходимости в масштабировании каждого компонента, что делает масштабирование гибким и снижает расходы.
Возможность повторного использования. Компоненты реализуют свою маленькую конкретную функцию. Это означает, что их проще адаптировать для использования в других системах, сервисах или продуктах. Компонент Transcode может быть использован другими подразделениями бизнеса или даже превращён в новый бизнес, предлагающий услуги транскодирования другой аудитории.
На таком уровне детализации преимущества микросервисной модели над монолитной кажутся очевидными. Если всё так, то почему паттерн вошёл в моду только теперь? Где же он был всю мою жизнь?
Если всё так здорово, то почему никто так не делал раньше?
Есть два ответа на этот вопрос. Первый — вообще-то делали, в меру технических возможностей. Второй — недавние технологические улучшения позволили нам выйти в этом подходе на новый уровень.
Когда я начал подготовку ответа на этот вопрос, получилось длинное описание, поэтому лучше выделю его в отдельную статью и опубликую её чуть позже. Здесь же будут опущены путь от одной программы ко множеству, ESB (enterprise service bus, т.е. «сервисная шина предприятия» — прим. перев.) и SOA (service-oriented architecture, т.е. «сервис-ориентированная архитектура» — прим. перев.), проектирование компонентов и bounded contexts («ограниченный контекст» — паттерн из Domain-Driven Design — прим. перев.) и т.п.
Вместо всего этого напишу, что во многих смыслах мы уже делали всё это некоторое время, но только с недавним взрывным ростом контейнерных технологий (в особенности — Docker) и технологий оркестровки (таких, как Kubernetes, Mesos, Consul и др.) паттерн стал гораздо более целесообразным в реализации с технической точки зрения.
Если взять за данность возможность реализации микросервисного подхода, необходимо внимательно подумать о необходимости. Мы увидели высокоуровневые теоретические преимущества, но что насчёт сложностей?
В чём проблема микросервисов?
Если микросервисы так прекрасны, в чём дело? Вот некоторые из самых значимых проблем, что мне довелось увидеть.
Возросшая сложность для разработчиков
Жизнь разработчиков может стать значительно тяжелее. Если разработчик захочет поработать над фичей, затрагивающей множество сервисов [journey], ему придётся запускать все их на своей машине и подключаться к ним. Зачастую это сложнее, чем просто запустить одну программу.
Эту сложность можно частично облегчить с помощью соответствующих инструментов [tooling], но чем больше количество сервисов, составляющих систему, тем больше сложностей у разработчиков будет возникать при запуске системы в целом.
Возросшая сложность для эксплуатации
У команд, которые не разрабатывают сервисы, а поддерживают их, случится взрыв в потенциальной сложности. Вместо возможного управления несколькими запущенными сервисами, им придётся работать с десятками, сотнями или тысячами. Больше сервисов, больше способов их взаимодействия и больше возможностей для потенциальных проблем.
Возросшая сложность для DevOps
Глядя на два предыдущих пункта, может показаться — особенно из-за популярности DevOps как практики (большим сторонником которой я являюсь), — что эксплуатация и разработка рассматриваются отдельно. Так вот не становится ли всё лучше благодаря DevOps?
Сложность в том, что многие организации по-прежнему имеют отдельные команды разработки и эксплуатации, и в таких случаях им скорее всего придётся нелегко в адаптации микросервисов.
Для организаций, уже применяющих DevOps, всё тоже не так просто. Быть одновременно и разработчиком, и сисадмином уже тяжело (но критично для создания хорошего программного обеспечения), а с необходимостью также понимать нюансы систем оркестровки контейнеров и в особенности систем, которые стремительно развиваются, ещё тяжелее. Так я прихожу к следующему пункту.
Необходима серьёзная компетентность
Результаты могут быть замечательными, если работу делали эксперты. Но представьте организацию, в которой не всё идеально с работой единой монолитной системы. Почему же при росте количества систем, что усложняет эксплуатацию, ситуация станет лучше?
Да, с эффективной автоматизацией, мониторингом, оркестровкой и т.п. — всё это возможно. Однако сложностью редко является технология — обычно же это поиск людей, которые могут её эффективно использовать. Спрос на такие навыки сейчас огромен, найти их непросто.
Реальные системы обычно не имеют чётко определённых границ
Во всех примерах, использовавшихся для описания преимуществ микросервисов, речь шла о независимых компонентах. Однако во многих случаях компоненты не являются попросту независимыми. Если на бумаге определённые области и могут выглядеть связанными, то в действительности, когда вы докапываетесь до всех деталей, легко обнаружить, что всё гораздо сложнее, чем в предполагаемой модели.
Здесь-то всё и становится очень сложным. Если границы по-настоящему хорошо не определены, случится так, что — даже в случае теоретической возможности изолированного деплоя сервисов — всплывут взаимные зависимости между сервисами, из-за которых придётся деплоить наборы сервисов как группу.
В свою очередь это означает, что необходимо поддерживать согласованные версии сервисов, которые были проверены и протестированы в работе друг с другом. Выходит, что системы, части которой можно деплоить независимо, в действительности нет, потому что для деплоя новой фичи придётся внимательно управлять деплоем множества сервисов.
Сложности stateful часто игнорируются
В предыдущем примере упомянута иногда возникающая необходимость одновременного выката множества версий множества сервисов при деплое фичи. Хочется сказать, что продуманные техники деплоя облегчат жизнь: например, сине-зелёный деплой [blue/green deployments] (требуют минимальных усилий в большинстве платформ для оркестровки сервисов) или параллельный запуск множества версий сервиса с возможностью выбора подходящей на стороне их пользователя.
Эти техники устраняют многие препятствия, если сервисы — stateless. Но работать со stateless-сервисами вообще-то довольно просто. Собственно, если у вас stateless-сервисы, рекомендую подумать о том, чтобы пропустить все эти микросервисы и использовать модель serverless.
В реальности же многим сервисам требуется хранить состояние [state]. Примером для платформы шаринга видео может служить услуга подписки. Пусть новая версия сервиса подписки хранит данные в БД нового вида. Если оба сервиса запущены в параллель, то у вас система, одновременно использующая две схемы. Если вы делаете сине-зелёный деплой, а другие сервисы зависят от данных в новом виде, их необходимо обновить в то же самое время. Если деплой сервиса подписки прошёл неудачно и откатывается, то скорее всего необходимо откатить и эти сервисы тоже, и далее «по каскаду».
Опять же, заманчиво думать, что с базами данных из мира NoSQL подобные связанные со схемой проблемы уйдут, но это не так. Базы данных, которые не требуют строгих схем, не означают отсутствие схем у системы, потому что по сути это просто означает необходимость управления схемой на уровне приложения, а не на уровне СУБД. Нельзя искоренить фундаментальную проблему понимания вида ваших данных и как они изменяются.
Сложности взаимодействия часто игнорируются
Поскольку вы создаёте большую сеть из сервисов, зависимых друг от друга, скорее всего появляется просторное поле для межсервисного взаимодействия. Возникает ряд сложностей. Во-первых, становится больше мест для потенциальных отказов. Необходимо предвидеть возможность того, что сетевые вызовы не сработают, то есть при каждом обращении одного сервиса к другому он должен хотя бы пытаться повторять свои попытки. Когда же сервису необходимо обратиться ко множеству сервисов, ситуация ещё усложнится.
Представьте, что пользователь загружает видео в сервис шаринга. Нам необходимо запустить сервис загрузки, передать данные в сервис транскодирования, обновить подписки, обновить рекомендации и так далее. Все эти вызовы требуют определённой оркестровки, а если что-то сломается, действия нужно повторить.
Логика повторных обращений может стать сложной в управлении. Попытки делать всё синхронно зачастую становятся несостоятельными, потому что имеют слишком много точек отказа. В этом случае более надёжным решением станет использование асинхронных паттернов взаимодействия. Но сложность заключается в том, что из-за асинхронных паттернов система становится stateful. А как уже рассказывалось в прошлом пункте, управлять stateful-системами и системами с распределёнными состояниями очень сложно.
Когда в микросервисной системе используются очереди сообщений для межсервисного взаимодействия, у вас по сути работает большая база данных (очередь сообщений или брокер), склеивающая все сервисы. Опять же, хоть всё это поначалу и не кажется проблемой, схема догонит вас и напомнит о себе. Сервис версии X может писать сообщения в определённом формате, поэтому сервисы, зависящие от такого сообщения, тоже необходимо обновить, когда сервис-отправитель меняет что-то в своём сообщении.
Можно иметь сервисы, которые обрабатывают сообщения во множестве разных форматов, но ими сложно управлять. При деплое новых версий сервисов будет случаться так, что две версии сервиса попытаются обработать сообщения из одной очереди и, возможно, даже из сервисов-отправителей тоже разных версий. Это может привести к запутанным, неадекватным ситуациям. Может оказаться, что для их избежания проще разрешить существовать только определённым версиям сообщений: это означает, что придётся деплоить согласованные наборы из версий для наборов из сервисов, гарантируя, что сообщения старых версий обрабатываются соответствующим образом (первыми).
Этим снова подтверждается мысль, что, если вдаваться в детали, то независимые развёртывания не всегда работают, как предполагалось.
Версионность может быть сложной
Для преодоления упомянутых препятствий необходимо очень осторожно управлять версиями. Опять же, есть тенденция полагать, что следование стандарту вроде semver решит проблему. Это не так. Semver — соглашение, которое целесообразно использовать, но вам всё равно придётся следить за версиями сервисов и API, которые могут взаимодействовать.
Очень быстро можно прийти к значительным трудностям и оказаться в ситуации, когда вы не знаете, какие версии сервисов в действительности корректно работают друг с другом.
Общеизвестно, как тяжело управлять зависимостями в программных системах, будь то модули для Node или Java, библиотеки для Си и т.п. Очень сложно разбираться с проблемами конфликтов независимых компонентов, используемых одной сущностью.
С этими проблемами сложно совладать, когда зависимости статичны и могут быть пропатчены, обновлены, отредактированы и так далее. Если же в роли зависимостей выступают работающие сервисы, уже не получится просто обновить их: потребуется запустить несколько версий (с описанными выше проблемами) или приостановить работу системы, пока всё в целом не будет исправлено.
Распределённые транзакции
В ситуациях, когда во время эксплуатации необходима транзакционная целостность, микросервисы могут оказаться большой болью. Непросто работать с распределённым состоянием, а множество небольших компонентов, которые могут сломаться, делают оркестровку транзакций по-настоящему тяжёлой.
Может показаться привлекательным попробовать избежать проблемы, делая операции идемпотентными, предлагая механизмы повторных попыток и т.п. — и во многих случаях это сработает. Однако могут быть сценарии, в которых попросту нужна успешная или неуспешная транзакция, без промежуточного состояния. Сложность обходного решения этой задачи или её реализация в микросервисной модели может оказаться очень высокой.
Микросервисы могут быть замаскированными монолитами
Да, отдельные сервисы и компоненты могут деплоиться изолированно, однако в большинстве случаев будет запускаться какая-то платформа для оркестровки вроде Kubernetes. Если же вы пользуетесь управляемым сервисом вроде GKE от Google или EKS от Amazon, большая часть сложностей управления кластером решена за вас.
Однако, если вы сами управляете кластером, то работаете с большой, сложной и критически важной системой. Хоть у отдельных сервисов и могут быть все преимущества, описанные выше, необходимо очень вдумчиво управлять кластером. Развёртывание такой системы может быть сложным, обновления — сложными, failover — сложным и т.п.
Во многих случаях общие преимущества остаются, однако важно не упрощать и не недооценивать дополнительную сложность, вызванную управлением ещё одной большой и сложной системой. Управляемые сервисы способны помочь, но зачастую они слишком молоды (например, Amazon EKS был анонсирован лишь в конце 2017 года).
Смерть микросервисного безумия!
Избегайте безумия, принимая осмотрительные и обдуманные решения. А в помощь для этого я подготовил несколько вопросов, которые вы можете задать себе, и пояснений к ответам на них. Прим. перев.: оригинальное изображение-схема переведено и представлено в текстовом виде ниже.
1. Размер команды
Можно ли усадить всю вашу команду за один большой стол?
- Да! Возможно, микросервисы ещё не нужны. Сложности, связанные с деплоем, разработкой, эксплуатацией и т.п., вероятно, легко решаются с помощью хороших коммуникаций и хорошей архитектуры, а микросервисы могут оказаться решением проблемы, которой у вас нет.
- Нет! Микросервисы могут помочь. Если у вас большая команда или несколько команд, строго обозначить границы компонентов с помощью одной лишь архитектуры может быть затруднительно. Выделение компонентов в изолированные сервисы может помочь в реализации этих границ.
2. Stateless/stateful
Ваша система является преимущественно stateless?
- Да! Рассмотрите serverless. Если ваша система в основном stateless, вероятно, вы можете пропустить этап микросервисов и сразу перейти к serverless — по крайней мере, частично.
- Нет! Микросервисы принесут сложности. Это не означает, что использовать микросервисы не стоит, но помните, что непросто их реализовать и ими управлять — особенно из-за того, что система со временем меняется.
3. «Пользователи» системы
Вы собираете решение для одного приложения или сервиса?
- Да! Будьте осторожны — могут встречаться «размытые» предметные области. Если всё, что вы собираете, предназначено одному и тому же приложению-пользователю, может выясниться, что сборка фич потребует одновременного обновления множества сервисов. Микросервисы могут быть уместны, однако будьте очень осторожны с проектированием предметных областей.
- Нет! Микросервисы могут оказаться очень полезными. Если вы проектируете систему, которой будут пользоваться разные приложения, микросервисы могут оказаться очень уместным паттерном, чтобы быстро доставлять новые фичи новым приложениям-«пользователям».
4. Зависимости
У вас есть монолитные зависимости?
- Да! Производительность может вызвать проблемы. В этом случае независимо масштабируемые сервисы вряд ли помогут, потому что остаётся влияние производительности зависимостей. Выходит, что одно из главных преимуществ не будет актуальным. Вдобавок, границы ваших сервисов могут быть хуже определены.
- Нет! Микросервисы могут оказаться очень полезными. Если монолиты не тянут вас на дно, может получиться достичь высокого уровня независимости, требуемой для эффективного масштабирования микросервисов.
5. Компетентность
Есть ли у вас эксперты по контейнерам, оркестровке, DevOps?
- Да! Микросервисы могут оказаться очень полезными. При наличии соответствующих кадров стоит изучить микросервисы. Имеющиеся навыки позволят разобраться с потенциальными трудностями и воспользоваться преимуществами.
- Нет! Сначала прощупайте почву! При отсутствии должной компетентности или в случае уже имеющихся трудностях с DevOps вы можете прыгнуть выше головы. Рассмотрите возможность адаптации одного простого сервиса в качестве доказательства концепции. Получите первый нужный опыт на проектах, которые не являются критичными для бизнеса.
Скачать оригинальный PDF со всеми вопросами-ответами (на английском языке) можно здесь.
Последние мысли: не путайте микросервисы с архитектурой
Я умышленно избежал слова на «a» в этой статье. Но мой друг Zoltan, проверяя её, сделал очень хорошее замечание.
Микросервисной архитектуры не существует. Микросервисы — это просто ещё один паттерн или реализация компонентов, ни больше ни меньше. Представлены они в системе или нет — не означает, что архитектура системы готова.
Микросервисы во многом больше относятся к техническим процессам, связанным с упаковыванием и эксплуатацией, чем к самой архитектуре системы. Уместные границы для компонентов остаются одной из главных сложностей в инженерных системах.
Вне зависимости от размера ваших сервисов, находятся ли они в Docker-контейнерах или нет — всегда нужно хорошо подумать о том, как собрать систему воедино. Нет правильных ответов, но есть множество вариантов.
P.S. от переводчика
Читайте также в нашем блоге:
- «Статистика The New Stack о трудностях внедрения Kubernetes»;
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- «Инфраструктура с Kubernetes как доступная услуга»;
- «Зачем нужен Kubernetes и почему он больше, чем PaaS?»;
- «Что такое service mesh и почему он мне нужен [для облачного приложения с микросервисами]?»;
- «Операторы для Kubernetes: как запускать stateful-приложения».

{kind=link}