Итак, кто не против, чтобы одежду ему подбирала программа, машина, нейросеть?
Любой набор изображений возможно проанализировать с помощью метода главных компонент. Этот метод уже довольно успешно применяется при распознавании лиц. Мы же попробуем использовать его на примере женских платьев.

Исходные данные: 807 фотографий платьев из Amazon. Все изображения имеют одинаковые размеры, но позы моделей различаются (хотя они, как правило, имеют сходное расположение в кадре). В идеальном варианте, главные компоненты должны определяться непосредственно стилем платья. В нашем случае многие из них будут связаны и с позой модели. Несмотря на это, с имеющимся набором данных еще многое можно сделать.


Собственно платье является первым главным компонентом, который определяет наибольшее различие. В общем, отслеживаются различия между светлыми и темными платьями.


Второй компонент сравнивает короткие и длинные платья.


Красноватые и голубоватые оттенки.


Модели с короткими волосами и платьями без рукавов и длинными волосами с длинными рукавами.


Модели с ногами вместе и врозь, и так далее.
Имея набор подобных компонентов возможно уменьшить изображение, например, от 60 000 точек данных (значений пикселей) до всего нескольких точек.
Давайте попробуем воссоздать это платье из компонентов.

Следующие изображения являются воссозданным платьем, соответственно, из одного, двух, четырех, девяти, десяти, пятнадцати, тридцати, сорока и семидесяти компонентов.









Как можно увидеть, чем больше используется компонентов, тем более точным и подробным получается воссозданное платье.
Данные, необходимые для получения изображения платья из 10 компонентов теперь выглядят следующим образом: [-17541,81, -12749,33, -3766,29, 2005,28, 4193,08, 6832,55, -6704,90, -2135,51, 1112,27, 7627,80].
Так что, если нужно хранить миллион фотографий, можно сэкономить уйму дискового пространства, храня только значения компонентов вместо значений всех пикселей для каждого платья.
Метод работает даже для платьев, которые не вошли в обучающую выборку:



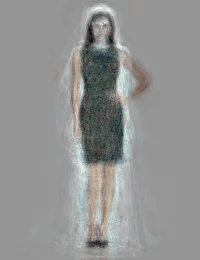
Хотя результат не так хорош в случае с комбинациями, которые не встречались в обучении:


Также не получится воссоздать аксессуары, которых не было в обучающей выборке (обратите внимание, что очки и сумочка исчезли):


И хотя в обучающей выборке были лишь платья, данных вполне достаточно для воссоздания различных видов одежды, как, например, костюмов и комбинезонов:



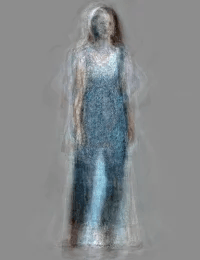
Еще я вручную сгруппировала фотографии платьев на те, которые мне понравились (287) и не понравились (520 фотографии).
Теперь воспользовавшись логистической регрессией применительно к данным компонентов можно предсказать понравится мне платье или нет.
Отсортировав платья по полученной оценке мы можем увидеть самые красивые и самые уродливые платья из всей выборки.
Самые красивые платья:



И самые уродливые:



Довольно точно. После этого можно придумать что-нибудь, что отслеживало бы новые платья, размещенные на Amazon, и присылало мне каталог подходящих для меня платьев.
Интересно посмотреть и на случаи неверного определения. Ниже — три «самых уродливых красивых платья», которые я определила как «в моем стиле», но программа решила, что мне они совершенно не понравятся:



Возможно тут дело в специфическом оттенке синего.
А вот «самые красивые уродливые платья», которые я отнесла к невзрачным, а программа предсказала противоположное:



Ну они не так уж и плохи. Мне в принципе нравятся, но думаю, они бы смотрелись лучше если их немного поменять (сделать менее облегающими, убрать слишком пестрый узор, выбрать более яркий оттенок).
При создании изображений не обязательно ограничивать себя уже известными комбинациями компонентов платьев. Можно просто использовать случайные значения для каждого компонента и посмотреть что из этого выйдет!












Это совершенно новые платья, придуманные программой! При большом количестве и хорошем качестве данных, это может оказаться перспективным инструментом для создания новых фасонов платьев! Код можно скачать здесь.
Итак, машины уже рисуют картины, пишут музыку и определяют наш стиль, что дальше?
Любой набор изображений возможно проанализировать с помощью метода главных компонент. Этот метод уже довольно успешно применяется при распознавании лиц. Мы же попробуем использовать его на примере женских платьев.
Исходные данные: 807 фотографий платьев из Amazon. Все изображения имеют одинаковые размеры, но позы моделей различаются (хотя они, как правило, имеют сходное расположение в кадре). В идеальном варианте, главные компоненты должны определяться непосредственно стилем платья. В нашем случае многие из них будут связаны и с позой модели. Несмотря на это, с имеющимся набором данных еще многое можно сделать.
Собственно платье является первым главным компонентом, который определяет наибольшее различие. В общем, отслеживаются различия между светлыми и темными платьями.
Второй компонент сравнивает короткие и длинные платья.
Красноватые и голубоватые оттенки.
Модели с короткими волосами и платьями без рукавов и длинными волосами с длинными рукавами.
Модели с ногами вместе и врозь, и так далее.
Использование компонентов для воссоздания изображения
Имея набор подобных компонентов возможно уменьшить изображение, например, от 60 000 точек данных (значений пикселей) до всего нескольких точек.
Давайте попробуем воссоздать это платье из компонентов.
Следующие изображения являются воссозданным платьем, соответственно, из одного, двух, четырех, девяти, десяти, пятнадцати, тридцати, сорока и семидесяти компонентов.
Как можно увидеть, чем больше используется компонентов, тем более точным и подробным получается воссозданное платье.
Данные, необходимые для получения изображения платья из 10 компонентов теперь выглядят следующим образом: [-17541,81, -12749,33, -3766,29, 2005,28, 4193,08, 6832,55, -6704,90, -2135,51, 1112,27, 7627,80].
Так что, если нужно хранить миллион фотографий, можно сэкономить уйму дискового пространства, храня только значения компонентов вместо значений всех пикселей для каждого платья.
Метод работает даже для платьев, которые не вошли в обучающую выборку:
Хотя результат не так хорош в случае с комбинациями, которые не встречались в обучении:
Также не получится воссоздать аксессуары, которых не было в обучающей выборке (обратите внимание, что очки и сумочка исчезли):
И хотя в обучающей выборке были лишь платья, данных вполне достаточно для воссоздания различных видов одежды, как, например, костюмов и комбинезонов:
Использование компонентов для прогнозирования
Еще я вручную сгруппировала фотографии платьев на те, которые мне понравились (287) и не понравились (520 фотографии).
Теперь воспользовавшись логистической регрессией применительно к данным компонентов можно предсказать понравится мне платье или нет.
Отсортировав платья по полученной оценке мы можем увидеть самые красивые и самые уродливые платья из всей выборки.
Самые красивые платья:
И самые уродливые:
Довольно точно. После этого можно придумать что-нибудь, что отслеживало бы новые платья, размещенные на Amazon, и присылало мне каталог подходящих для меня платьев.
Интересно посмотреть и на случаи неверного определения. Ниже — три «самых уродливых красивых платья», которые я определила как «в моем стиле», но программа решила, что мне они совершенно не понравятся:
Возможно тут дело в специфическом оттенке синего.
А вот «самые красивые уродливые платья», которые я отнесла к невзрачным, а программа предсказала противоположное:
Ну они не так уж и плохи. Мне в принципе нравятся, но думаю, они бы смотрелись лучше если их немного поменять (сделать менее облегающими, убрать слишком пестрый узор, выбрать более яркий оттенок).
Создание новых платьев
При создании изображений не обязательно ограничивать себя уже известными комбинациями компонентов платьев. Можно просто использовать случайные значения для каждого компонента и посмотреть что из этого выйдет!
Это совершенно новые платья, придуманные программой! При большом количестве и хорошем качестве данных, это может оказаться перспективным инструментом для создания новых фасонов платьев! Код можно скачать здесь.
Итак, машины уже рисуют картины, пишут музыку и определяют наш стиль, что дальше?
Конспект
- Любой набор изображений можно проанализировать с помощью метода главных компонент.
- Исходная выборка: 807 фотографий платьев из Amazon.
- Платье является главным компонентом, другие компоненты: длина и оттенок платья, длина рукава и волос модели, поза модели и другие.
- Компоненты можно использовать для уменьшения размера хранящейся фотки, прогнозирования и даже придумывать новые фасоны.
