
В комментариях к нашей прошлой статье было много вопросов о технологиях, которые мы используем. В этой статье я — Игорь Мосягин, R&D разработчик Lamoda — о них расскажу. Под катом вы найдёте исчерпывающий перечень языков, инструментов, платформ и технологий, которые прошли через наши руки. Фронтенд, бэкенд, БД, брокеры сообщений, кеши и мониторинг, разработка и балансировка — подробный рассказ о том, что мы используем сегодня, а от чего отказались.
Я и мои коллеги готовы подискутировать в комментариях или на стенде компании на HighLoad++ 2018.
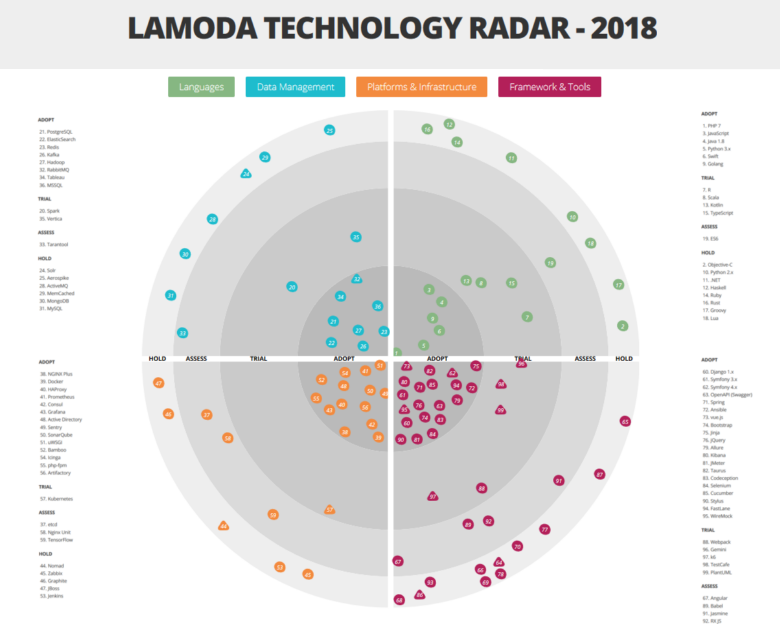
Рассмотреть радар крупно и подробно можно здесь.
Как мы уже говорили, в Lamoda задействовано огромное количество различных технологий и инструментов. И это не случайно. Иначе нам не справиться с нагрузкой! У нас большой автоматизированный склад. Наш call-center обслуживают 500 сотрудников, а выстроенные нами процессы позволяют перезвонить клиенту в течение 5 минут после оформления заказа. Наша служба доставки работает по 15-минутным интервалам. А ведь кроме собственных систем, у нас есть B2B интеграция с другими интернет-магазинами. С таким многообразием решаемых задач и требованиями такого динамичного бизнеса, как e-commerce, неизбежно разрастание технического стека, ведь каждую задачу мы хотим решать наиболее подходящими технологиями. Разнообразие неизбежно. Об основных представителях нашего стека мы расскажем далее. Но начнем с механизмов, позволяющих не «заблудиться» в этом многообразии.
Мы активно движемся в направлении микросервисной архитектуры. Большая часть систем уже построена в соответствии с этой идеологией — два года назад мы прошли переходный этап со своими проблемами и их решениями. Но на деталях этого процесса здесь мы останавливаться не будем — гораздо больше об этом расскажет доклад Андрея Евсюкова "Особенности микросервисов на примере e-Com-платформы".
Чтобы не усугублять технологическое многообразие, у нас введена «диктатура опробованных практик», в соответствии с которой создателям новых фишек рекомендовано использовать те технологии и инструменты, которые уже задействованы где-то в компании. Большинство сервисов общаются друг с другом через API (мы используем свою модификацию второй версии стандарта JSONRPC), но там, где это позволяет бизнес-логика, мы также используем шину данных для взаимодействия.
Использование иных технологий не запрещено. Однако любая новая идея должна пройти проверку в специально созданном архитектурном комитете, куда входят руководители основных направлений.
Рассматривая очередное предложение, комитет либо дает добро на эксперимент, либо предлагает какую-то замену из уже существующего стека. Кстати, решение это во многом зависит от текущих обстоятельств в бизнесе. Например, если команда придет накануне распродажи Black Friday и объявит, что будет внедрять в продакшн технологию, о которой ранее комитет никогда не слышал, скорее всего, она получит отказ. С другой стороны, тому же эксперименту может быть дан зеленый свет, если новая технология или инструмент будет внедряться в менее критичных для бизнеса обстоятельствах, при этом внедрение начнётся с тестирования вне продакшна.
Архитектурный комитет также отвечает за ведение Technology radar, раз в 2-3 месяца внося необходимые изменения. Одно из назначений этого ресурса — как раз дать командам представление о том, какая экспертиза уже есть в компании.
Но перейдем к самому интересному — к разбору секторов нашего радара.
Стоит отметить, что мы используем немного нестандартную трактовку категорий принятия технологии:
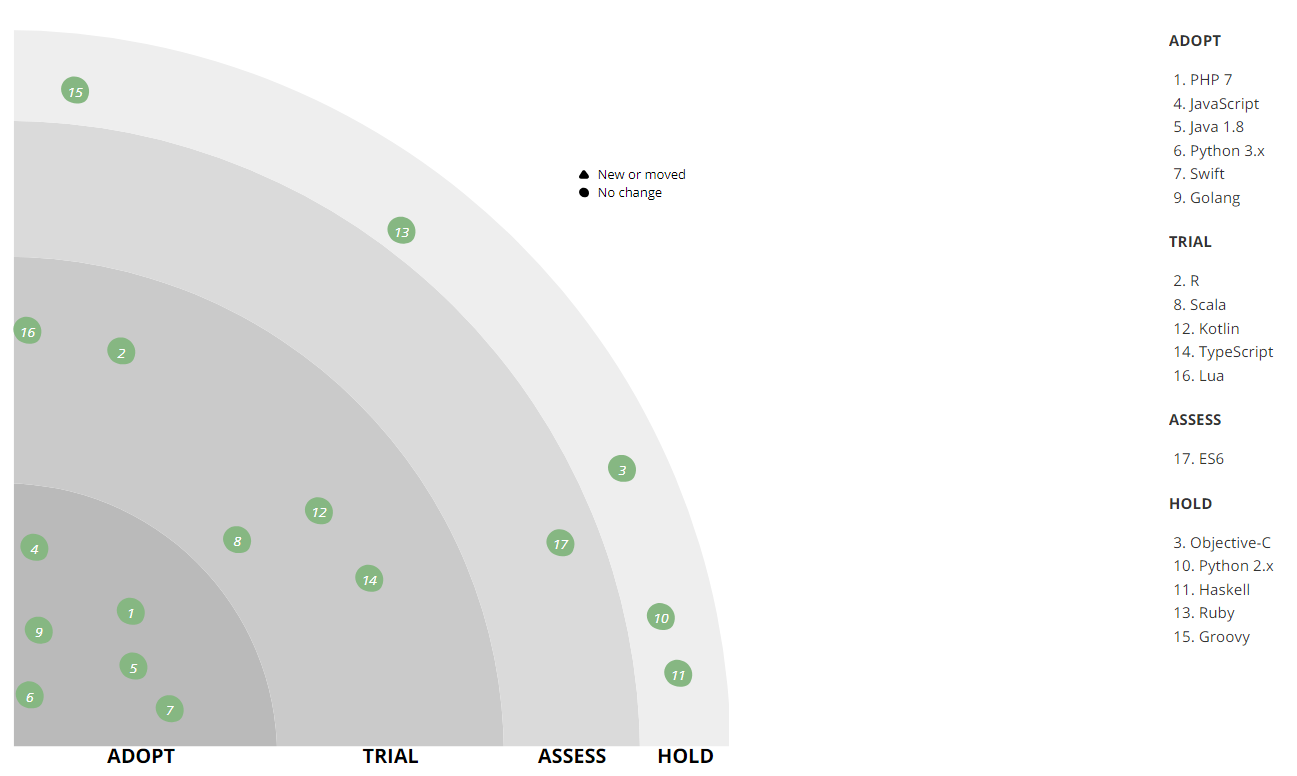
Первый важный для нас язык, на котором хочется остановиться, — это PHP. Сегодня он решает лишь часть задач бэкенда магазина, а изначально на PHP работал весь бэкенд. По мере масштабирования бизнеса на фронтенде стала заметна нехватка скорости и производительности — тогда еще мы использовали PHP 5, поэтому ему на смену пришел Python (сначала 2.x, а затем и 3.x). Однако PHP позволяет писать богатые бизнес-модели, поэтому этот язык остался в бэкофисе для автоматизации различных операционных процессов, в частности, интеграции со сторонними интернет-магазинами или службами доставки, а также автоматизации студии контента, оформляющей карточки товаров. Сейчас мы уже используем PHP 7. На PHP мы написали множество библиотек для внутреннего использования: интеграция и обёртки над нашей инфраструктурой, слой интеграции между сервисами, различные переиспользуемые хелперы. Первую партию библиотек уже стали выносить в open source на наш github.com, в скором времени доедут и остальные, наиболее «созревшие». Одной из первых была стейт-машина, которая, присутствуя почти во всех приложениях, следит за тем, чтобы с заказом перед отправкой произвели все необходимые действия.
Со временем Python для бэкенда магазина также стало недостаточно. Теперь мы отдаем предпочтение более производительному и легковесному Go.
Пожалуй, переход на Go стал важным изменением, поскольку позволил экономить много аппаратных и человеческих ресурсов — эффективность повысилась в разы. Первыми, кто сделал первые проекты на Go, были RnD, они не хотели бороться с техническими ограничениями Python. Затем в команде мобильной разработки появились люди, которые были хорошо с ним знакомы и продвигали его на продакшн. С их подачи мы провели тесты и были более чем удовлетворены результатом. В отдельных кейсах после того, как часть проекта переписывали с Python на Go, загрузка нод кластера существенно падала. К примеру, переписывание движка расчета скидок для корзины с питона на Go позволило обрабатывать в 8 раз больше запросов на тех же аппаратных мощностях, а среднее время ответа API уменьшилось в 25 раз. Т.е. Go оказался эффективнее Python (если на нем правильно писать), пусть даже и не таким удобным для разработчика.
Поскольку мобильной разработке приходилось взаимодействовать с десятками внутренних API, был создан кодогенератор, который по описанию API сервиса (по спецификации Swagger) может генерировать клиент на Go. Так на Go постепенно стали переписываться существующие сервисы и инструменты, особенно те, что создавали «бутылочное горлышко» для нагрузки. Помимо упрощения жизни разработчику мобильного бэкенда, мы упростили следование внутренним соглашениям о том, как разрабатывать API, как называть методы, как передавать параметры и тому подобное. Такая стандартизация сделала разработку и внедрение новых сервисов проще для всех команд.
На сегодняшний день Go уже используется почти везде — во всех real-time взаимодействиях с пользователями — в бэкенде сайта и мобильных приложений, а также сервисов, с которыми они связаны. А там, где нет потребности в быстрой обработке и ответе, например, в задачах взаимодействия с data warehouse, остался Python, так как для задач обработки данных ему нет равных (хотя и здесь есть проникновение Go).
Как видно на радаре, у нас в активе есть Java. Она используется в системе автоматизации работы со складом (WMS — Warehouse Management System), помогая быстрее собирать заказы. Пока что у нас там достаточно старый стек и старая модель архитектуры — монолит, крутящийся на Wildfly 10 и 8 Java Hotspot, а ещё там есть remoting и Rich client на Netbeans Application Platform (сейчас эта функциональность переносится в web). Здесь же у нас в арсенале стандартные для компании хранилища и даже свой собственный мониторинг. К сожалению, мы не нашли инструмента, который может хорошо визуализировать работу склада и важных процессов на нём (когда какой-то участок перегружен, например), и сделали такой инструмент сами.
В качестве основного языка для машинного обучения мы используем Python: строим рекомендательные системы и ранжируем каталог, исправляем опечатки в поисковых запросах, а также решаем другие задачи в связке со Spark на Hadoop кластере (PySpark). Python помогает нам автоматизировать расчет внутренних метрик и проведение AB тестирования.
Фронтенд десктопного интернет-магазина, а также мобильных сайтов написан на JavaScript. Сейчас фронтенд постепенно переходит на спецификацию ES6, создавая в соответствии с ней новые проекты. В качестве основного фреймворка мы используем vue.js, но на нем остановимся подробнее в разделе инструментов.
Разработка приложений под мобильные платформы — отдельный юнит в компании, куда входят группы бэкенда, а также Android и iOS-приложений со своими стеками технологий и инструментами, которые из-за различий платформ далеко не всегда удается унифицировать в масштабах всего юнита.
Уже два года вся новая Android-разработка ведется на Kotlin-е, позволяющем писать более краткий и понятный код. Среди наиболее часто используемых фич наши разработчики называют: smartcast, sealed-классы, extension-функции, typesafe-билдеры (DSL), функционал stdlib.
iOS-разработка ведется на Swift, который пришел на смену Objective-C.
Спектр задач Lamoda не ограничивается разработкой «витрины» под разные платформы, соответственно, у нас есть некоторое количество языков, которые используются только в рамках своих систем, работают там хорошо, но не будут внедряться в других частях инфраструктуры:
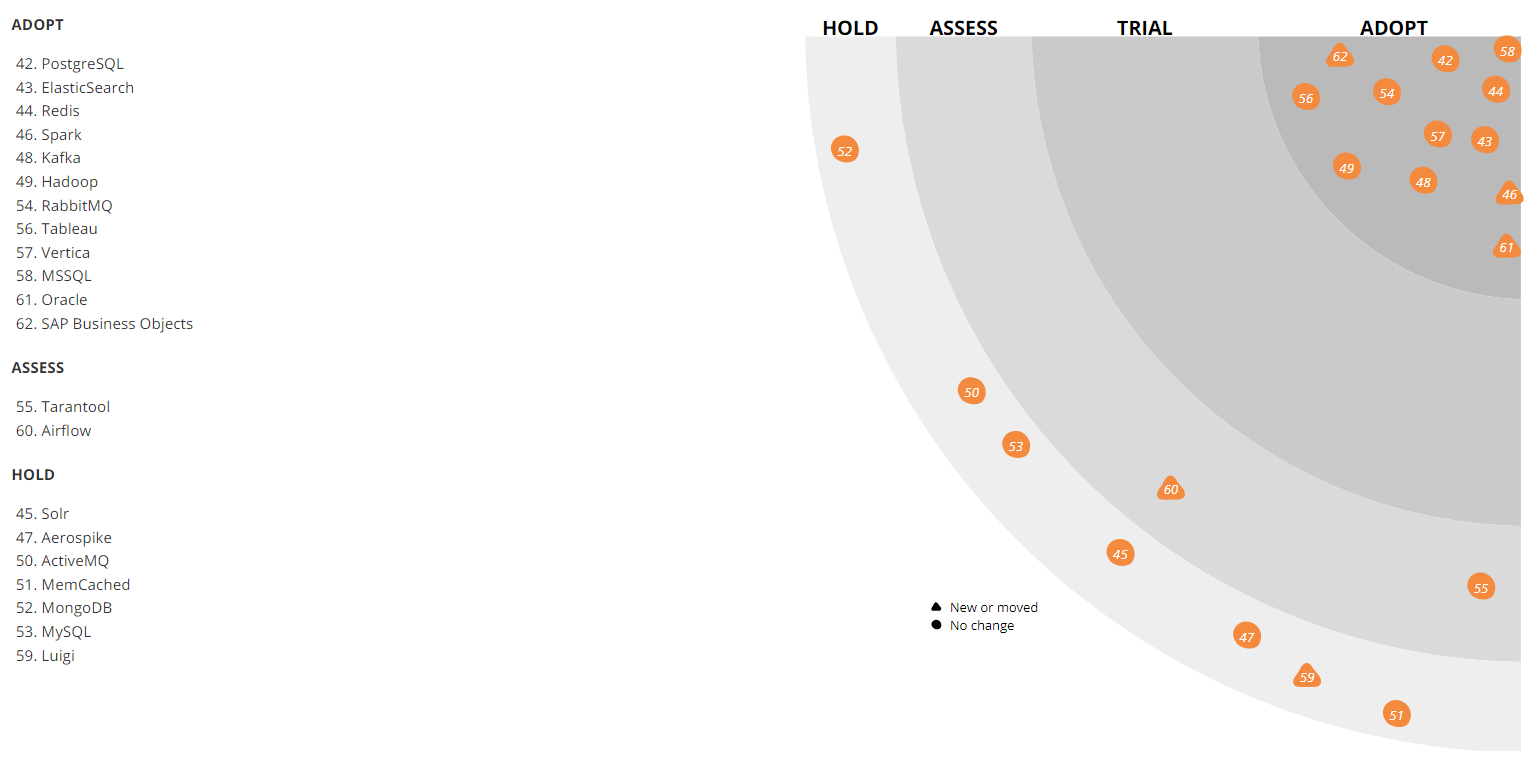
Как и у многих, самые разные БД у нас реализованы на PostgreSQL — он используется везде, где нужны реляционные базы, например, для хранения каталога. Специалистов по этой технологии найти довольно легко, кроме того, доступно множество разных сервисов.
Конечно, PostgreSQL — не единственная СУБД, которую можно найти в нашей ИТ-инфраструктуре. На отдельных старых системах, например, используется MySQL, а в WMS есть немного MongoDB. Однако для высоких нагрузок и масштабирования (с учетом остального нашего стека технологий) мы не используем их для новых проектов. В целом PostgreSQL — наше все.
Также на радаре виден Aerospike. Мы использовали его довольно активно, но потом у продукта поменялось лицензионное соглашение, так что «наша» версия оказалась немного урезанной. Однако сейчас мы на него посмотрели снова. Возможно, мы пересмотрим свое отношение к инструменту и будем использовать его активнее. Сейчас Aerospike используется в сервисе агрегации событий просмотра страниц и работы пользователя с корзиной а также в сервисе social-proof («на этой неделе 5 человек добавили этот товар в избранное»). Сейчас мы делаем на нем еще более крутые рекомендации.
Для поиска данных на продакшене используется Apache Solr. Параллельно мы также применяем ElasticSearch. Оба решения — open source, однако если раньше, когда мы только внедряли поиск, Apache Solr имел уже третью или четвертую версию и активно развивался, а у ElasticSearch еще не было даже первого стабильного релиза — использовать его на продакшне было рано. Сейчас же роли поменялись — найти решения для ElasticSearch гораздо проще, и к нам как раз пришли новые люди, которые хорошо умеют его готовить. Однако в проде у нас Solr, и мы не будем переезжать на другое решение как минимум до Black Friday 2018.
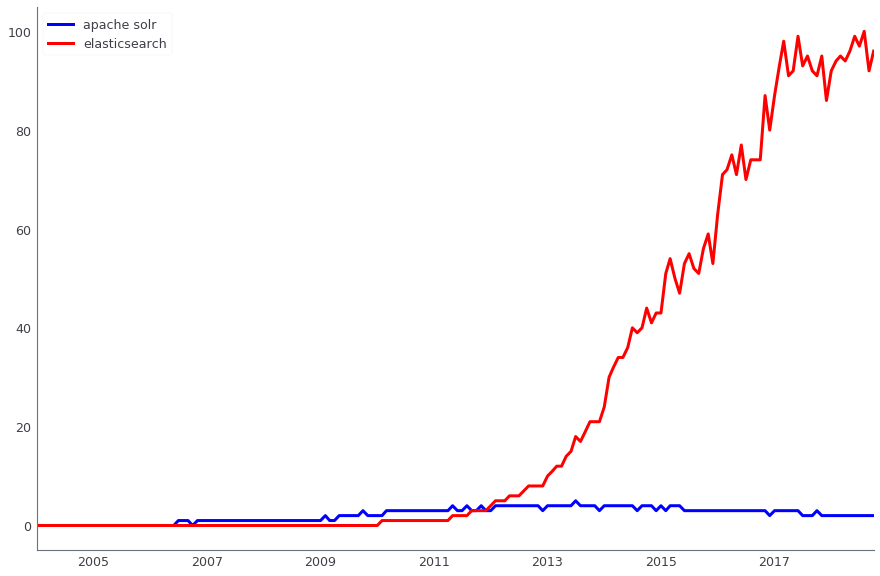
Сравнение динамики поисковых запросов Apache Solr (синий) и ElasticSearch (красный), по данным Google Trends
Анализ данных происходит в нескольких системах, в частности мы активно используем Apache Hadoop. Параллельно для хранения витрин данных (суммарным объемом порядка 4 Тб) используется колоночная СУБД Vertica. Над этими Витринами строится финансовая, операционная и коммерческая отчетность. Для многих наших ETL-задач мы ранее использовали Luigi, но сейчас переходим на Apache Airflow. Также для реляционного хранилища у нас используется Pentaho, в котором порядка тысячи регулярных ETL задач.
Часть анализа и подготовка данных для других систем осуществляется в Spark. В некоторых местах это не только инструмент аналитики, но и часть нашей лямбда-архитектуры.
Большую роль в IT инфраструктуре играют ERP системы: Microsoft Dynamics AX и 1C. В качестве СУБД используется Microsoft SQL Server. А для создания отчетности — его компоненты, такие как Analysis services и Reporting services.
Для кеширования мы используем Redis. Ранее эту задачу выполнял MemCached, он не мог быть использован как key value хранилище с периодическим дампом на диск, поэтому мы от него отказались.
В качестве брокера событий у нас используется сразу два инструмента — Apache Kafka и RabbitMQ.
Apache Kafka — инструмент, который позволяет нам обрабатывать десятки тысяч сообщений в различных системах, где нужен обмен сообщениями. Отдельные кластеры Kafka у нас развернуты под некоторые высоконагруженные части системы — например, под события пользователя или логирование (про логирование у нас был хороший доклад на Highload++ 2017). Kafka позволяет справляться с 6000 тысячами объемных сообщений в секунду при минимальном использовании железа.
Во внутренних системах у нас используется RabbitMQ для отложенных действий.
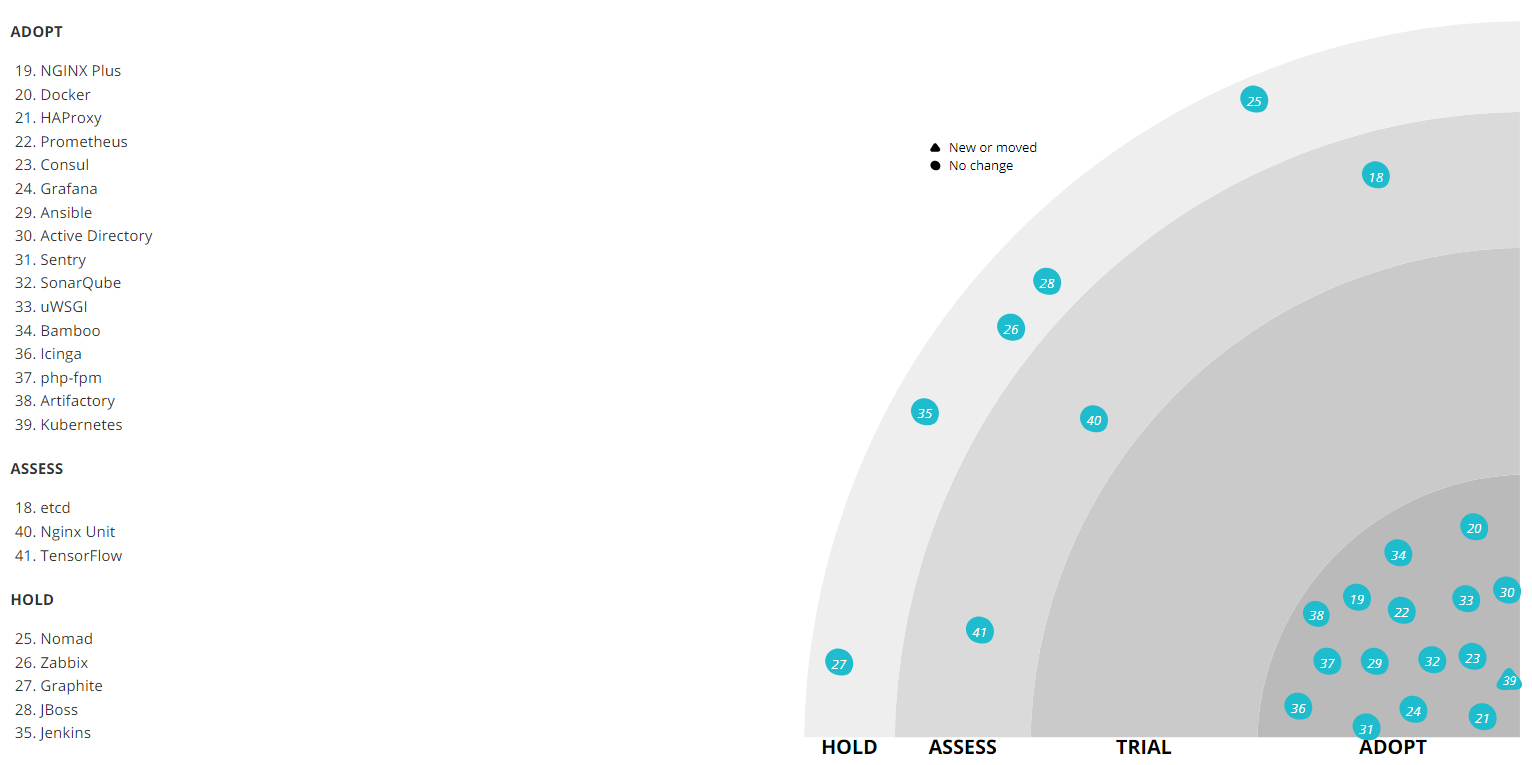
Для деплоя используется Kubernetes, который пришел на смену связке Nomad + Consul от Hashicorp. Предыдущий стек очень плохо работал с апгрейдом оборудования. Когда наша Ops-команда меняла физические серверы, на которых крутились ноды и хранились контейнеры, он периодически ломался и падал, не желая подниматься. Стабильной версии на тот момент так и не вышло. Тем более, у нас на тогда использовалась не самая последняя — 0.5.6, которую все равно необходимо было обновлять. Апгрейд до последней беты требовал определенных трудозатрат. Поэтому от него было решено отказаться и перейти на более популярный Kubernetes.
Сейчас Nomad и Consul все еще используются в QA, но в перспективе и он должен переехать на Kubernetes.
Для реализации continuous delivery используются Docker-контейнеры, на которые мы мигрировали два года назад. Для наших высоконагруженных сервисов (корзины, каталога, сайта, системы управления заказами) важна возможность быстро поднять несколько дополнительных контейнеров какого-то сервиса, поэтому контейнеры у нас везде. А Docker — один из наиболее популярных способов контейнеризации, так что его присутствие на радаре вполне логично.
В качестве сервера сборки и непрерывной интеграции развернут Bamboo, используемый в связке с Jira и Bitbucket (стандартный стек).
В радаре упомянут и Jenkins. Мы с ним экспериментировали, но не потащим его в новые проекты. Это превосходный инструмент, но он просто не вписывается в наш стек из-за того, что у нас уже есть Bamboo.
Собранные при помощи Bamboo docker-контейнеры хранятся в репозитории под управлением Artifactory.
У нас используется NGINX Plus, но не в части балансировки, поскольку его метрик для наших задач недостаточно. Он не может сказать, допустим, какой запрос чаще всего роутится или подвисает. Поэтому для балансировки нагрузки используется HAProxy. Он умеет работать быстро и эффективно в связке с nginx, не загружая процессор и память. Кроме того, нужные нам метрики здесь присутствуют из коробки — HAproxy умеет показывать статистику по нодам, по числу коннектов на данный момент, по тому, насколько занят bandwidth и многое другое.
Для запуска синхронных Python-приложений используется uWSGI. В качестве менеджера процессов на всех PHP-шных сервисах использован php-fpm.
Prometheus мы используем для сбора метрик с наших приложений и host машин (виртуалок), а также как Time series database для приложения. Мы собираем логи, для этого используем ELK стек, в качестве системы алертинга используем Icinga, которая настроена и на ELK, и на Prometheus. Она рассылает алерты в почту и SMS. Такие же алерты получает служба поддержки 6911 и принимает решение о привлечении дежурных инженеров.
Prometheus задействован практически везде, и для этого у нас есть библиотеки для всех языков, которые позволяют при помощи буквально пары строчек кода подключать его метрики к проекту. К примеру, библиотека для PHP выложена в Open Source).
Для наглядного отображения результатов мониторинга в виде красивых дашбордов используется Grafana. В основном все дашборды мы собираем из Prometheus, хотя иногда источниками могут служить и другие системы.
Для отлавливания и автоматической агрегации ошибок мы применяем Sentry, которая интегрирована с Jira и позволяет легко на каждую из проблем продакшена заводить задачу в таск трекер. Он умеет захватывать ошибку с некоторым бэктрейсом и дополнительной информацией, так что потом это удобно дебажить.
Сбор статистики по коду создаваемых пулл-реквестов осуществляется при помощи SonarQube.
За время развития ИТ-инфраструктуры Lamoda мы экспериментировали почти с тремя десятками различных инструментов, поэтому данная категория самая «масштабная» на нашем радаре. На сегодняшний день активно используются:
Про разработку на JavaScript хочется рассказать отдельно. У нас, как и у многих, целое поле экспериментов. На сайте для JavaScript используется самописный фреймворк. На фронтенде в рамках не критичных для бизнеса задач велись эксперименты с разными фреймворками — Angular, ReactJS, vue.js. В этой «гонке вооружений», похоже, лидирует vue.js, который изначально применялся в системе автоматизации контентной студии, а теперь постепенно приходит везде.
Если попытаться описать все это разнообразие в двух словах, то мы пишем на GO, PHP, Java, JavaScript, держим базы на PostgreSQL, а деплоим на Docker и Kubernetes.
Разумеется, описанное состояние технологического стека нельзя назвать итоговым. Мы непрерывно развиваемся, и с ростом нагрузки классы подходящих решений приходится изменять, что само по себе является интересной задачей. Параллельно усложняется бизнес-логика, так что нам постоянно приходится искать новые инструменты. Если вы хотите подискутировать на тему, почему выбрали именно этот инструмент, а не другой, добро пожаловать в комментарии.
Я и мои коллеги готовы подискутировать в комментариях или на стенде компании на HighLoad++ 2018.
Рассмотреть радар крупно и подробно можно здесь.
Как мы уже говорили, в Lamoda задействовано огромное количество различных технологий и инструментов. И это не случайно. Иначе нам не справиться с нагрузкой! У нас большой автоматизированный склад. Наш call-center обслуживают 500 сотрудников, а выстроенные нами процессы позволяют перезвонить клиенту в течение 5 минут после оформления заказа. Наша служба доставки работает по 15-минутным интервалам. А ведь кроме собственных систем, у нас есть B2B интеграция с другими интернет-магазинами. С таким многообразием решаемых задач и требованиями такого динамичного бизнеса, как e-commerce, неизбежно разрастание технического стека, ведь каждую задачу мы хотим решать наиболее подходящими технологиями. Разнообразие неизбежно. Об основных представителях нашего стека мы расскажем далее. Но начнем с механизмов, позволяющих не «заблудиться» в этом многообразии.
Главные по архитектуре
Мы активно движемся в направлении микросервисной архитектуры. Большая часть систем уже построена в соответствии с этой идеологией — два года назад мы прошли переходный этап со своими проблемами и их решениями. Но на деталях этого процесса здесь мы останавливаться не будем — гораздо больше об этом расскажет доклад Андрея Евсюкова "Особенности микросервисов на примере e-Com-платформы".
Чтобы не усугублять технологическое многообразие, у нас введена «диктатура опробованных практик», в соответствии с которой создателям новых фишек рекомендовано использовать те технологии и инструменты, которые уже задействованы где-то в компании. Большинство сервисов общаются друг с другом через API (мы используем свою модификацию второй версии стандарта JSONRPC), но там, где это позволяет бизнес-логика, мы также используем шину данных для взаимодействия.
Использование иных технологий не запрещено. Однако любая новая идея должна пройти проверку в специально созданном архитектурном комитете, куда входят руководители основных направлений.
Рассматривая очередное предложение, комитет либо дает добро на эксперимент, либо предлагает какую-то замену из уже существующего стека. Кстати, решение это во многом зависит от текущих обстоятельств в бизнесе. Например, если команда придет накануне распродажи Black Friday и объявит, что будет внедрять в продакшн технологию, о которой ранее комитет никогда не слышал, скорее всего, она получит отказ. С другой стороны, тому же эксперименту может быть дан зеленый свет, если новая технология или инструмент будет внедряться в менее критичных для бизнеса обстоятельствах, при этом внедрение начнётся с тестирования вне продакшна.
Архитектурный комитет также отвечает за ведение Technology radar, раз в 2-3 месяца внося необходимые изменения. Одно из назначений этого ресурса — как раз дать командам представление о том, какая экспертиза уже есть в компании.
Но перейдем к самому интересному — к разбору секторов нашего радара.
Стоит отметить, что мы используем немного нестандартную трактовку категорий принятия технологии:
- ADOPT — технологии и инструменты, которые внедрены и активно используются;
- TRIAL — технологии и инструменты, которые уже прошли этап тестирования и готовятся к тому, чтобы работать с продакшн (или даже уже работают там);
- ASSESS — пробные инструменты, которые в данный момент оцениваются и пока не влияют на продакшн. С их участием реализуются только тестовые проекты;
- HOLD — в этой категории у нас есть экспертиза, но упомянутые инструменты используются только при поддержке существующих систем — новые проекты на них не запускаются.
Разработка
PHP — Python — Go
Первый важный для нас язык, на котором хочется остановиться, — это PHP. Сегодня он решает лишь часть задач бэкенда магазина, а изначально на PHP работал весь бэкенд. По мере масштабирования бизнеса на фронтенде стала заметна нехватка скорости и производительности — тогда еще мы использовали PHP 5, поэтому ему на смену пришел Python (сначала 2.x, а затем и 3.x). Однако PHP позволяет писать богатые бизнес-модели, поэтому этот язык остался в бэкофисе для автоматизации различных операционных процессов, в частности, интеграции со сторонними интернет-магазинами или службами доставки, а также автоматизации студии контента, оформляющей карточки товаров. Сейчас мы уже используем PHP 7. На PHP мы написали множество библиотек для внутреннего использования: интеграция и обёртки над нашей инфраструктурой, слой интеграции между сервисами, различные переиспользуемые хелперы. Первую партию библиотек уже стали выносить в open source на наш github.com, в скором времени доедут и остальные, наиболее «созревшие». Одной из первых была стейт-машина, которая, присутствуя почти во всех приложениях, следит за тем, чтобы с заказом перед отправкой произвели все необходимые действия.
Со временем Python для бэкенда магазина также стало недостаточно. Теперь мы отдаем предпочтение более производительному и легковесному Go.
Пожалуй, переход на Go стал важным изменением, поскольку позволил экономить много аппаратных и человеческих ресурсов — эффективность повысилась в разы. Первыми, кто сделал первые проекты на Go, были RnD, они не хотели бороться с техническими ограничениями Python. Затем в команде мобильной разработки появились люди, которые были хорошо с ним знакомы и продвигали его на продакшн. С их подачи мы провели тесты и были более чем удовлетворены результатом. В отдельных кейсах после того, как часть проекта переписывали с Python на Go, загрузка нод кластера существенно падала. К примеру, переписывание движка расчета скидок для корзины с питона на Go позволило обрабатывать в 8 раз больше запросов на тех же аппаратных мощностях, а среднее время ответа API уменьшилось в 25 раз. Т.е. Go оказался эффективнее Python (если на нем правильно писать), пусть даже и не таким удобным для разработчика.
Поскольку мобильной разработке приходилось взаимодействовать с десятками внутренних API, был создан кодогенератор, который по описанию API сервиса (по спецификации Swagger) может генерировать клиент на Go. Так на Go постепенно стали переписываться существующие сервисы и инструменты, особенно те, что создавали «бутылочное горлышко» для нагрузки. Помимо упрощения жизни разработчику мобильного бэкенда, мы упростили следование внутренним соглашениям о том, как разрабатывать API, как называть методы, как передавать параметры и тому подобное. Такая стандартизация сделала разработку и внедрение новых сервисов проще для всех команд.
На сегодняшний день Go уже используется почти везде — во всех real-time взаимодействиях с пользователями — в бэкенде сайта и мобильных приложений, а также сервисов, с которыми они связаны. А там, где нет потребности в быстрой обработке и ответе, например, в задачах взаимодействия с data warehouse, остался Python, так как для задач обработки данных ему нет равных (хотя и здесь есть проникновение Go).
Как видно на радаре, у нас в активе есть Java. Она используется в системе автоматизации работы со складом (WMS — Warehouse Management System), помогая быстрее собирать заказы. Пока что у нас там достаточно старый стек и старая модель архитектуры — монолит, крутящийся на Wildfly 10 и 8 Java Hotspot, а ещё там есть remoting и Rich client на Netbeans Application Platform (сейчас эта функциональность переносится в web). Здесь же у нас в арсенале стандартные для компании хранилища и даже свой собственный мониторинг. К сожалению, мы не нашли инструмента, который может хорошо визуализировать работу склада и важных процессов на нём (когда какой-то участок перегружен, например), и сделали такой инструмент сами.
В качестве основного языка для машинного обучения мы используем Python: строим рекомендательные системы и ранжируем каталог, исправляем опечатки в поисковых запросах, а также решаем другие задачи в связке со Spark на Hadoop кластере (PySpark). Python помогает нам автоматизировать расчет внутренних метрик и проведение AB тестирования.
Фронтенд и мобильная разработка
Фронтенд десктопного интернет-магазина, а также мобильных сайтов написан на JavaScript. Сейчас фронтенд постепенно переходит на спецификацию ES6, создавая в соответствии с ней новые проекты. В качестве основного фреймворка мы используем vue.js, но на нем остановимся подробнее в разделе инструментов.
Разработка приложений под мобильные платформы — отдельный юнит в компании, куда входят группы бэкенда, а также Android и iOS-приложений со своими стеками технологий и инструментами, которые из-за различий платформ далеко не всегда удается унифицировать в масштабах всего юнита.
Уже два года вся новая Android-разработка ведется на Kotlin-е, позволяющем писать более краткий и понятный код. Среди наиболее часто используемых фич наши разработчики называют: smartcast, sealed-классы, extension-функции, typesafe-билдеры (DSL), функционал stdlib.
iOS-разработка ведется на Swift, который пришел на смену Objective-C.
Специальные языки
Спектр задач Lamoda не ограничивается разработкой «витрины» под разные платформы, соответственно, у нас есть некоторое количество языков, которые используются только в рамках своих систем, работают там хорошо, но не будут внедряться в других частях инфраструктуры:
- R — применяется для скриптов обработки данных и построения отчетов в рамках business intelligence (BI). Его нет в продакшене и на новых задачах он уже не применяется, но у нас все еще работает некоторое количество таких скриптов. Решая задачи с помощью R, мы поняли, что это язык не для высоконагруженных приложений. В новых задачах мы используем Python и другие технологии, которые с R несовместимы.
- Scala — используется офисом разработки в Вильнюсе для развития системы автоматизации call-центра. Изначально эта система была написана на PHP, но при переходе к микросервисной архитектуре ряд компонентов переписали на Scala. Также на нем команда Data Engineering пишет Spark job'ы.
- к TypeScript мы присматриваемся. Уже сейчас с его помощью реализована доставка, а в будущем мы задействуем TypeScript + vue.js на фронтенде.
- Lua применяется для конфигурации nginx (через API nginx), в других проектах его нет и не будет.
- Мы модная компания и следим за модой на функциональное программирование. Например, эмулятор сортировочного устройства одного из наших складов написан на Haskell.
Управление данными
СУБД, поиск и анализ данных
Как и у многих, самые разные БД у нас реализованы на PostgreSQL — он используется везде, где нужны реляционные базы, например, для хранения каталога. Специалистов по этой технологии найти довольно легко, кроме того, доступно множество разных сервисов.
Конечно, PostgreSQL — не единственная СУБД, которую можно найти в нашей ИТ-инфраструктуре. На отдельных старых системах, например, используется MySQL, а в WMS есть немного MongoDB. Однако для высоких нагрузок и масштабирования (с учетом остального нашего стека технологий) мы не используем их для новых проектов. В целом PostgreSQL — наше все.
Также на радаре виден Aerospike. Мы использовали его довольно активно, но потом у продукта поменялось лицензионное соглашение, так что «наша» версия оказалась немного урезанной. Однако сейчас мы на него посмотрели снова. Возможно, мы пересмотрим свое отношение к инструменту и будем использовать его активнее. Сейчас Aerospike используется в сервисе агрегации событий просмотра страниц и работы пользователя с корзиной а также в сервисе social-proof («на этой неделе 5 человек добавили этот товар в избранное»). Сейчас мы делаем на нем еще более крутые рекомендации.
Для поиска данных на продакшене используется Apache Solr. Параллельно мы также применяем ElasticSearch. Оба решения — open source, однако если раньше, когда мы только внедряли поиск, Apache Solr имел уже третью или четвертую версию и активно развивался, а у ElasticSearch еще не было даже первого стабильного релиза — использовать его на продакшне было рано. Сейчас же роли поменялись — найти решения для ElasticSearch гораздо проще, и к нам как раз пришли новые люди, которые хорошо умеют его готовить. Однако в проде у нас Solr, и мы не будем переезжать на другое решение как минимум до Black Friday 2018.
Сравнение динамики поисковых запросов Apache Solr (синий) и ElasticSearch (красный), по данным Google Trends
Анализ данных происходит в нескольких системах, в частности мы активно используем Apache Hadoop. Параллельно для хранения витрин данных (суммарным объемом порядка 4 Тб) используется колоночная СУБД Vertica. Над этими Витринами строится финансовая, операционная и коммерческая отчетность. Для многих наших ETL-задач мы ранее использовали Luigi, но сейчас переходим на Apache Airflow. Также для реляционного хранилища у нас используется Pentaho, в котором порядка тысячи регулярных ETL задач.
Часть анализа и подготовка данных для других систем осуществляется в Spark. В некоторых местах это не только инструмент аналитики, но и часть нашей лямбда-архитектуры.
Большую роль в IT инфраструктуре играют ERP системы: Microsoft Dynamics AX и 1C. В качестве СУБД используется Microsoft SQL Server. А для создания отчетности — его компоненты, такие как Analysis services и Reporting services.
Кеширование
Для кеширования мы используем Redis. Ранее эту задачу выполнял MemCached, он не мог быть использован как key value хранилище с периодическим дампом на диск, поэтому мы от него отказались.
Очереди сообщений
В качестве брокера событий у нас используется сразу два инструмента — Apache Kafka и RabbitMQ.
Apache Kafka — инструмент, который позволяет нам обрабатывать десятки тысяч сообщений в различных системах, где нужен обмен сообщениями. Отдельные кластеры Kafka у нас развернуты под некоторые высоконагруженные части системы — например, под события пользователя или логирование (про логирование у нас был хороший доклад на Highload++ 2017). Kafka позволяет справляться с 6000 тысячами объемных сообщений в секунду при минимальном использовании железа.
Во внутренних системах у нас используется RabbitMQ для отложенных действий.
Платформы и инфраструктура
Continuous delivery
Для деплоя используется Kubernetes, который пришел на смену связке Nomad + Consul от Hashicorp. Предыдущий стек очень плохо работал с апгрейдом оборудования. Когда наша Ops-команда меняла физические серверы, на которых крутились ноды и хранились контейнеры, он периодически ломался и падал, не желая подниматься. Стабильной версии на тот момент так и не вышло. Тем более, у нас на тогда использовалась не самая последняя — 0.5.6, которую все равно необходимо было обновлять. Апгрейд до последней беты требовал определенных трудозатрат. Поэтому от него было решено отказаться и перейти на более популярный Kubernetes.
Сейчас Nomad и Consul все еще используются в QA, но в перспективе и он должен переехать на Kubernetes.
Для реализации continuous delivery используются Docker-контейнеры, на которые мы мигрировали два года назад. Для наших высоконагруженных сервисов (корзины, каталога, сайта, системы управления заказами) важна возможность быстро поднять несколько дополнительных контейнеров какого-то сервиса, поэтому контейнеры у нас везде. А Docker — один из наиболее популярных способов контейнеризации, так что его присутствие на радаре вполне логично.
В качестве сервера сборки и непрерывной интеграции развернут Bamboo, используемый в связке с Jira и Bitbucket (стандартный стек).
В радаре упомянут и Jenkins. Мы с ним экспериментировали, но не потащим его в новые проекты. Это превосходный инструмент, но он просто не вписывается в наш стек из-за того, что у нас уже есть Bamboo.
Собранные при помощи Bamboo docker-контейнеры хранятся в репозитории под управлением Artifactory.
Управление процессами и балансировка
У нас используется NGINX Plus, но не в части балансировки, поскольку его метрик для наших задач недостаточно. Он не может сказать, допустим, какой запрос чаще всего роутится или подвисает. Поэтому для балансировки нагрузки используется HAProxy. Он умеет работать быстро и эффективно в связке с nginx, не загружая процессор и память. Кроме того, нужные нам метрики здесь присутствуют из коробки — HAproxy умеет показывать статистику по нодам, по числу коннектов на данный момент, по тому, насколько занят bandwidth и многое другое.
Для запуска синхронных Python-приложений используется uWSGI. В качестве менеджера процессов на всех PHP-шных сервисах использован php-fpm.
Мониторинг
Prometheus мы используем для сбора метрик с наших приложений и host машин (виртуалок), а также как Time series database для приложения. Мы собираем логи, для этого используем ELK стек, в качестве системы алертинга используем Icinga, которая настроена и на ELK, и на Prometheus. Она рассылает алерты в почту и SMS. Такие же алерты получает служба поддержки 6911 и принимает решение о привлечении дежурных инженеров.
Prometheus задействован практически везде, и для этого у нас есть библиотеки для всех языков, которые позволяют при помощи буквально пары строчек кода подключать его метрики к проекту. К примеру, библиотека для PHP выложена в Open Source).
Для наглядного отображения результатов мониторинга в виде красивых дашбордов используется Grafana. В основном все дашборды мы собираем из Prometheus, хотя иногда источниками могут служить и другие системы.
Для отлавливания и автоматической агрегации ошибок мы применяем Sentry, которая интегрирована с Jira и позволяет легко на каждую из проблем продакшена заводить задачу в таск трекер. Он умеет захватывать ошибку с некоторым бэктрейсом и дополнительной информацией, так что потом это удобно дебажить.
Сбор статистики по коду создаваемых пулл-реквестов осуществляется при помощи SonarQube.
Фреймворки и инструменты
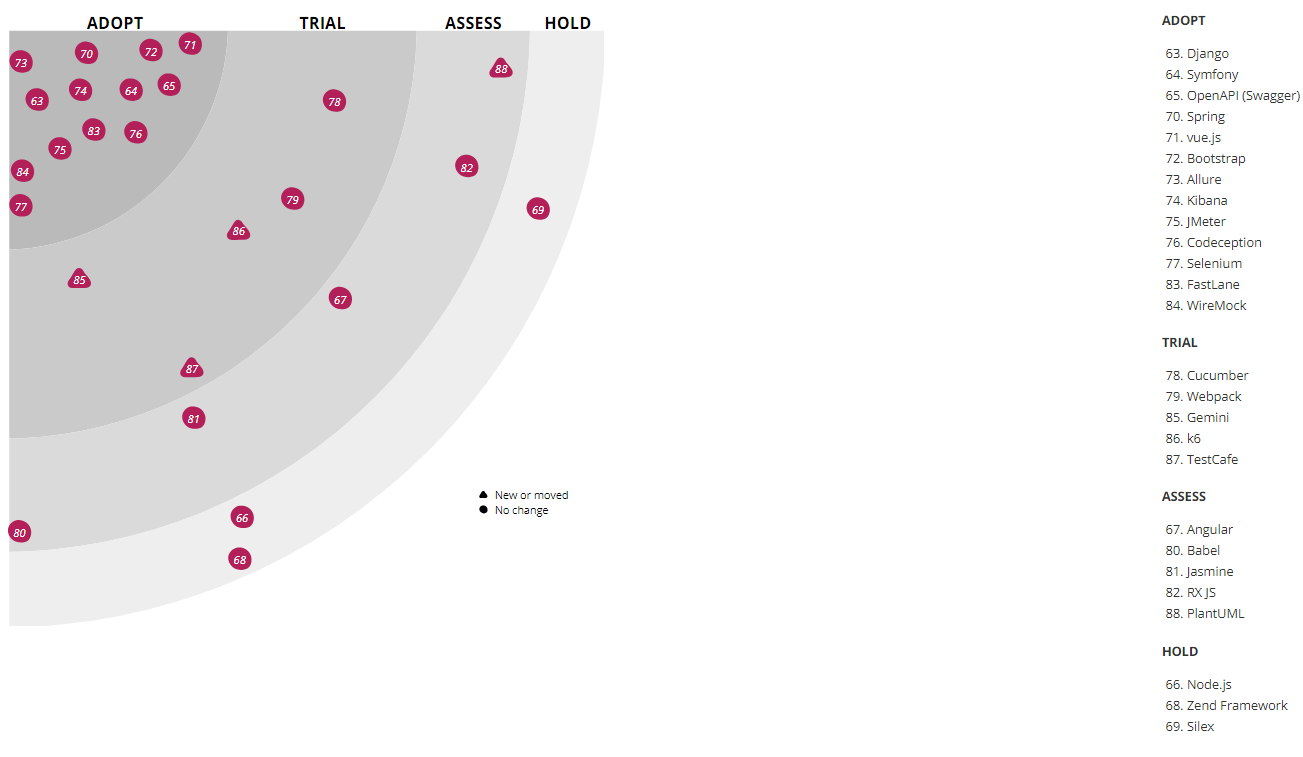
За время развития ИТ-инфраструктуры Lamoda мы экспериментировали почти с тремя десятками различных инструментов, поэтому данная категория самая «масштабная» на нашем радаре. На сегодняшний день активно используются:
- Symfony 3.x, а с недавнего времени — Symfony 4.x — для разработки на PHP;
- Django и шаблонизатор Jinja для Python-разработки. Кстати, Jinja используется, в том числе, для конфигурации в Ansible;
- Flask — для внутренних сервисов (наравне с Django), но в продакшн мы его не тащим;
- Spring — в Java-разработке;
- Bootstrap — для самых разных внутренних инструментов в веб-разработке (админки, самодельные дашборды и т.п.);
- jQuery — для js-разработки;
- OpenAPI (Swagger) — для документации всех API-сервисов, в т.ч. которые используются для упомянутой выше кодогенерации на Go;
- Webpack — для упаковки JS и минимизации CSS;
- Selenium — для тестирования фронтенда;
- также на тестировании применяются WireMock, JMeter, Allure и другие;
- Ansible — для управления конфигурациями;
- Kibana — для визуализации результатов поиска в ElasticSearch.
Про разработку на JavaScript хочется рассказать отдельно. У нас, как и у многих, целое поле экспериментов. На сайте для JavaScript используется самописный фреймворк. На фронтенде в рамках не критичных для бизнеса задач велись эксперименты с разными фреймворками — Angular, ReactJS, vue.js. В этой «гонке вооружений», похоже, лидирует vue.js, который изначально применялся в системе автоматизации контентной студии, а теперь постепенно приходит везде.
В сухом остатке
Если попытаться описать все это разнообразие в двух словах, то мы пишем на GO, PHP, Java, JavaScript, держим базы на PostgreSQL, а деплоим на Docker и Kubernetes.
Разумеется, описанное состояние технологического стека нельзя назвать итоговым. Мы непрерывно развиваемся, и с ростом нагрузки классы подходящих решений приходится изменять, что само по себе является интересной задачей. Параллельно усложняется бизнес-логика, так что нам постоянно приходится искать новые инструменты. Если вы хотите подискутировать на тему, почему выбрали именно этот инструмент, а не другой, добро пожаловать в комментарии.
