Apache Airflow – простой и удобный batch-ориентированный инструмент для построения, планирования и мониторинга дата-пайплайнов. Ключевой его особенностью является то, что, используя Python-код и встроенные функциональные блоки, можно соединить множество различных технологий, использующихся в современном мире. Основная рабочая сущность Airflow – DAG – направленный ацикличный граф, в котором узлами являются задачи, а зависимости между задачами представлены направленными ребрами.
Те, кто использует Apache Airflow для оркестрации задач загрузки данных в хранилище, наверняка оценили гибкость, которую он предоставляет для решения шаблонных задач. Когда весь процесс разработки сводится к заполнению конфигурационного файла с описанием параметров DAGа и списком задач, которые должны выполняться. У нас в Леруа Мерлен такой подход успешно используется для создания задач по перекладыванию данных из raw-слоя в ods-слой хранилища. Поэтому было решено распространить его на задачи по заполнению витрин данных.
Основная сложность состояла в том, что единой методологии разработки витрин данных и процедур по их заполнению у нас пока нет. И каждый разработчик решал задачу, основываясь на своих личных предпочтениях и опыте. Это укладывается в один из основных корпоративных IT принципов - ”You build it – you run it”, который означает, что разработчик несет ответственность за свое решение и сам его поддерживает. Данный принцип хорош для быстрой проработки гипотез, но для однотипных вещей больше подходит стандартное решение.
Как было
Тут стоит рассказать, как велась до этог�� разработка для загрузки витрин данных. Разработчик пишет процедуры загрузки в GreenPlum, разрабатывает DAGи для их запуска, после чего создает по шаблону новый репозиторий на GitHub, загружает код своих DAGов и добавляет свой репозиторий в основной проект Airflow в качестве сабмодуля. При таком подходе возникали следующие трудности:
Нужно погружение в Python и Apache Airflow;
На момент начала разработки релиз основного проекта происходил раз в неделю, поэтому, чтоб увидеть свои DAGи на проде Airflow, нужно было подождать;
Основной проект постепенно разрастался и начал притормаживать при деплое;
Разбросанным по разным репозиториям кодом DAGов, выполняющих однотипные задачи, сложно управлять;
Отсутствие единого подхода также влияло и на качество SQL-кода процедур. Часто можно было встретить сложную логику по управлению параметрами загрузки, которую легко можно было «перевесить» на Airflow.
Все вышеперечисленное привело нас к мысли, что пора брать ситуацию под свой контроль и заняться разработкой стандартного решения. Анализ существующих DAG-ов показал, что большинство из них очень простые, не содержат сложных зависимостей и состоят, в основном, из DummyOperator-ов и PostgresOperator-ов. Это и послужило отправной точкой для разработки нового инструмента, который, в свою очередь, должен был:
Уметь создавать DAG-и на основе конфигурационного файла в формате YAML, в которым бы были указаны основные параметры, как-то: дата старта, расписание, параметры подключения к БД, названия запускаемых процедур, их параметры и т. д. YAML файлы должны храниться внутри корпоративного сервиса по управлению метаданными, получить их содержимое можно через API;
Быть максимально простым, иметь понятную документацию, чтобы погружение не занимало много времени;
В то же время быть максимально гибким, уметь работать с максимально возможным количеством параметров настройки DAG-а в Airflow.
Что есть
Получился примерно вот следующий шаблон для конфигурационного файла:

Из которого создается вот такой DAG:

Описание параметров
Общие параметры:
module_name – нужен для формирование DAG_ID;
pool – пул, в котором будут запущены задачи;
queue – очередь для задач;
owner – владелец DAGа;
postgres_conn_id – строка подключения к БД;
email – список емейлов для рассылки алертов;
tags – список тэгов для поиска DAGа в UI;
access_control: роль для управление DAGом;
schedule_interval – расписание для запуска DAGа;
start_date и catchup – параметры, управляющие глубиной истории загрузки. Airflow использует интервальный подход. Это означает, что временной период от start_date и до опциональной end_date (мы не используем) разбивается на интервалы, указанные в schedule_interval. Если catchup True, то запуск DAGА начнется от start_date, если False, то с текущего интервала;
schema_name – схема БД, в которой находится витрина;
task_list – список задач в DAGе.
Основные параметры задач:
task_name – соответствует task_id Airflow
task_type – тип задачи
task_schema_name - схема БД, в которой находится витрина, если схема отличается от общей
task_conn_id – строка подключения, если отличается от общей
procedure_name – процедура загрузки витрины
params – список параметров процедуры и их значений
task_depends_on – список задач, от которых зависит запуск данной задачи
priority_weight – приоритет данной задачи по отношению к другим задачам
task_concurrency - количество одновременно запущенных экземпляров задачи во всех запущенных экземплярах DAGа
Сейчас существует три типа задач(task_type):
1) Dummy – соответствует DummyOperator. Задача, которая ничего не выполняет и обычно служит начальной и конечной задачей, а также для разделения задач на блоки.

2) Обычная загрузка – соответствует PostgresOperator в Airflow
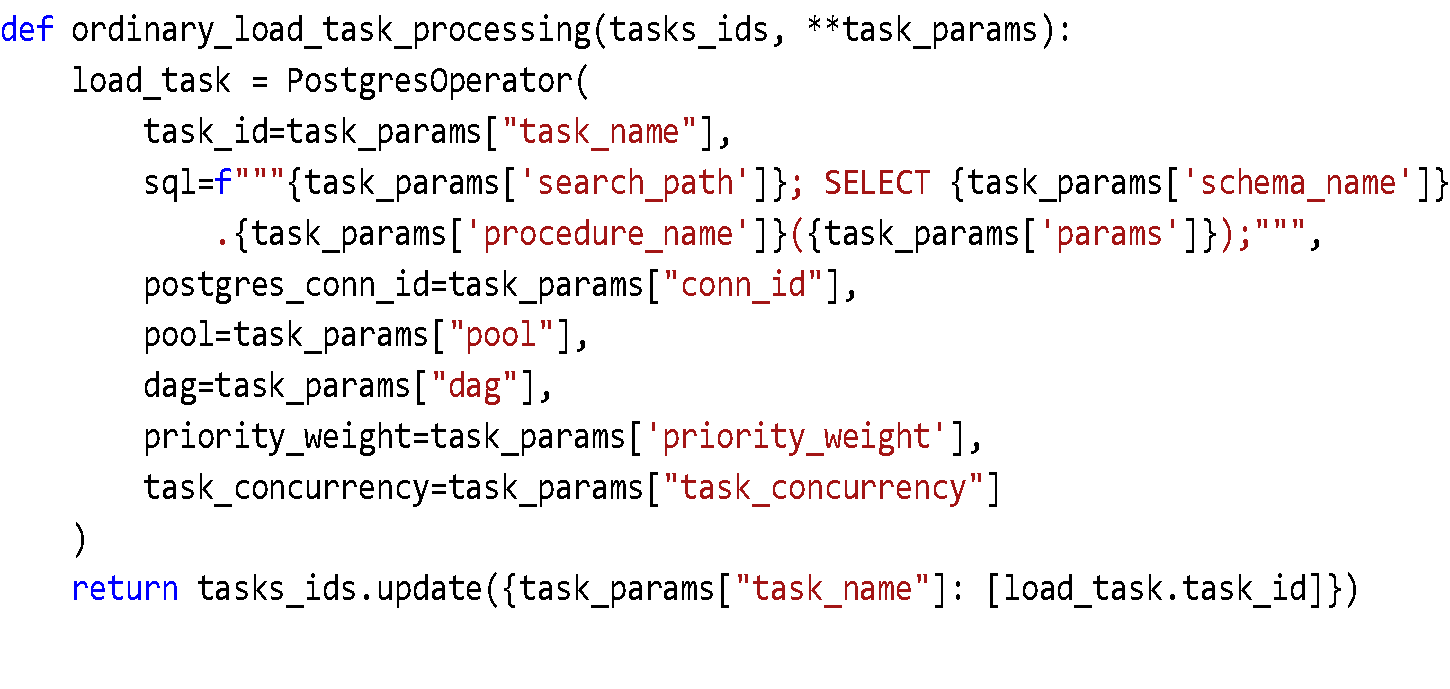
Вот так выглядит SQL-код, который генерит эта задача:

3) Множественная загрузка – много PostgresOperator(если нужно создать кучу однотипных задач, различающихся по одному параметру)

У этого типа есть свои специфические параметры:
task_multiply - может иметь 2 значения: "schema" или "params". Если указано schema", то значения из task_multiply_list добавляются в выражение SEARCH_PATH. Если "params", то значения из task_multiply_list добавляются в список параметров процедуры для параметра из списка params, у которого в значении указано 'task_multiply_list’
task_multiply_list - список значений для параметра, по которому будут создаваться однотипные задачи
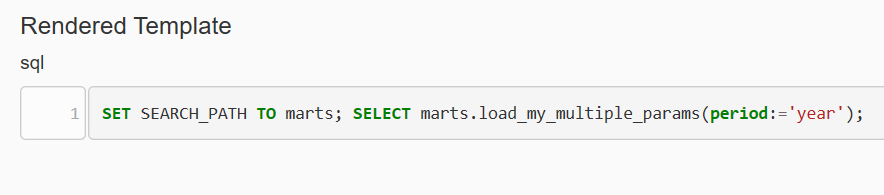
В результате получается такой SQL-код.
Для “schema”:

Для “params”:
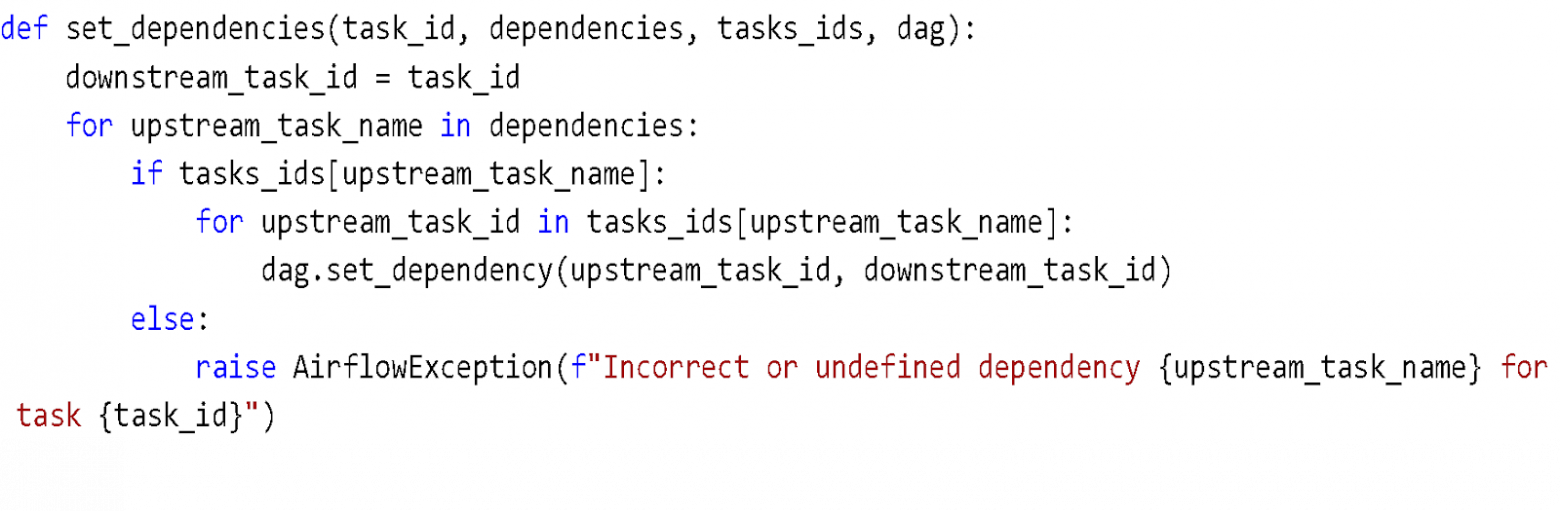
А вот так проставляются зависимости между задачами:
Куда пойдем
Внедрение инструмента позволило существенно сократить время на разработку DAGов. Глубокое погружение в Apache Airflow больше не нужно, хотя почитать про макросы и расписание все-таки придется. Шаблон конфигурационного файла заполняется минут за 10-15. Время, затрачиваемое на ревью и деплой на прод, тоже сильно сократились. Однако здесь же и кроется основная зона для развития: сейчас ревью и деплой происходят в ручном режиме. Хочется обложить все это тестами и предоставить разработчику возможность самому отправлять свои DAGи на прод.
