В конце зимы этого года прошло соревнование IEEE's Signal Processing Society — Camera Model Identification. Я участвовал в этом командном соревновании в качестве ментора. Об альтернативном способе формирования команды, решении и втором этапе под катом.

tldr.py
Постановка задачи
По фотографии необходимо определить устройство, на которое эта фотография была получена. Датасет состоял из картинок десяти классов: два айфона, семь андроид смартфонов и одна камера. В тренировочную выборку входили по 275 полноразмерных изображений каждого класса. В тестовой выборке были представлены только центральные кропы 512x512. Причем к 50 процентам из них была применена одна из трех аугментаций: jpg сжатие, ресайз с кубической интерполяцией или гамма коррекция. Можно было использовать внешние данные.

Суть (тм)
Если попытаться объяснить задачу простым языком, то идея представлена на картинке ниже. Как правило, современные нейросети учат отличать объекты на фотографии. т.е. нужно научиться отличать котиков от собачек, порнографию от купальников или танки от дорог. При этом, всегда должно быть безразлично каким образом и на какое устройство сделан снимок котика и танка.

В этом же конкурсе все было совсем наоборот. Вне зависимости от того, что показано на фото, нужно определить тип устройства. То есть использовать такие вещи как шумы матрицы, артефакты обработки снимков, дефекты оптики и т.д. В этом и состоял ключевой челлендж — разработать алгоритм цепляющий низкоуровневые фичи снимков.
Особенности командного взаимодействия
Подавляющая часть команд на kaggle формируется так: участники с близким скором по лидерборду объединяются в команду, при этом, каждый пилит свою версию решения от начала и до конца. Про типичный пример такого выступления я написал ранее пост. Однако в этот раз мы пошли другим путем, а именно: разделили части решения по людям. Кроме того, по правилам соревнования топ-3 студенческих команд получали путевку в Канаду на второй этап. Поэтому, когда собрался костяк, мы доукомплектовали команду, чтобы соответствовать правилам.
Решение
Чтобы показать хороший результат на этой задаче необходимо было собрать следующий пазл по приоритетам:
Сбор данных
Этой частью занимался Артур Фаттахов. Для данной задачи внешние данные добыть было довольно легко, это просто снимки с определенных моделей телефонов. Артур написал python-скрипт, использующий библиотеку для удобного парсинга html-страниц, которая называется BeautifulSoup. Но, например, на странице альбома flickr блоки фотографий подгружаются динамически, и чтобы это обойти пришлось использовать selenium, который эмулировал действие браузера. Суммарно было скачано 500+ Гб фотографий с yandex.fotki, flickr, wiki commons.
Фильтрация данных
Это был мой единственный вклад в решение в виде кода. Я просто посмотрел как выглядят необработанные фотографии и сделал кучу правил: 1) размер, типичный для определенной модели 2) jpg качество выше порога 3) наличие нужных meta-тегов моделей 4) правильный софт, которым производилась обработка.

На рисунке показано распределение фотографий по источникам и мобилам до и после фильтрации. Как видно, например, Moto-X значительно меньше, чем других телефонов. При этом до фильтрации их было довольно много, но большая часть отсеялась из-за того, что есть множество вариантов этого телефона и обладатели не всегда верно указывали модель.
Валидация
Реализацией части с обучением и валидацией занимался Илья Кибардин. Валидация на куске kaggle-трейна вообще не работало — сетка выбивала практически 1.0 accuracy, а на лидерборде было около 0.96.
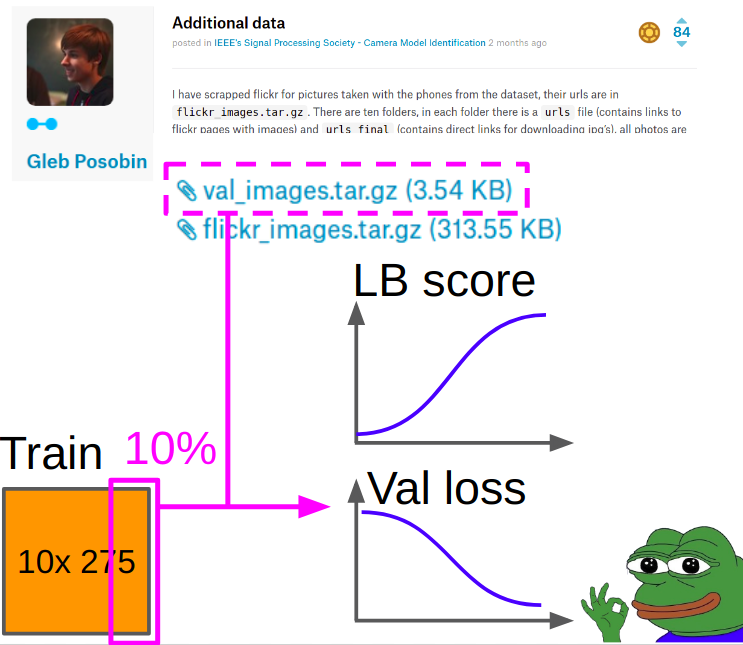
Поэтому под валидацию были взяты картинки Глеба Пособина, которые он взял со всяких сайтов с обзорами телефонов. В ней была ошибка: вместо айфона 6 там был айфон 6+. Мы заменили его на настоящий айфон 6 и докинули 10% картинок из трейна кагла, чтобы отбалансировать классы.
При обучении метрику считали так:
Лучшие чекпоинты отбирали по полученной в п.3 взвешенной кросс энтропии.
Обучение моделей
Где-то в середине соревнования Андрес Торрубиа выложил весь код своего решения. Он был настолько хорош в плане точности финальных моделей, что куча команд полетели с ним вверх по лидерборду. Однако он был написал на keras’e и уровень кода желал лучшего.
Ситуация второй раз сильно поменялась, когда Иван Романов выложил pytorch версию этого кода. Она была быстрее и к тому же легко паралеллилась на несколько видеокарт. Уровень кода, впрочем все равно был не очень, но это не так важно.

Грусть заключается в том, что эти парни закончили на 30м и 45м месте соответственно, но в наших сердцах навсегда остались в топе.
Илья в нашей команде взял код Миши и произвел следующие изменения.
Препроцессинг:

Обучение
Обучение происходило finetune’ом сети целиком, не замораживая сверточные слои классификатор (у нас было много данных + интуитивно, веса, которые извлекают высокоуровневые объекты в виде кошек/собачек можно и подрасшатать, потому что нам нужны низкоуровневые фичи).

Шедулинг:
Adam с lr = 1e-4. Когда лосс на валидации перестает улучшаться в ходе 2-3 эпох, уменьшаем lr в два раза. Так до сходимости. Заменяем Adam на SGD и учим с циклическим lr от 1e-3 до 1e-6 три цикла.
Финальный ансамбль:
Я попросил Илью реализовать свой подход из предыдущего соревнования. Для фильного ансамбля мы обучили 9 моделей, от каждый выбрали 3 лучших чекпоинта, каждый чекпоинт предсказали с ТТА и в финале все предсказания усреднили геометрическим средним.

Послесловие первого этапа
В итоге мы заняли 2е место на лидерборде и 1е место среди студенческих команд. А это значит, что мы попали на 2й этап этого соревнования в рамках 2018 IEEE International Conference on Acoustics, Speech and Signal Processing в Канаде. Из примечательного, команда, которая заняла 3е место, тоже была формально студенческая. Если посчитать скор, то выходило, что мы обошли ее на одну правильно предсказанную картинку.
Final IEEE Signal Processing Cup 2018
После того как нам пришли все подтверждения, я, Валерий и Андрей решили не ехать в Канаду на второй этап. Илья и Артур Ф. решили ехать, начали все оформлять и им не дали визу. Чтобы избежать международного скандала по притеснению сильнейших дата саентистов из России, орги разрешили участвовать удаленно.
Таймлайн был такой:
30.03 — выдали данные трейна
04.09 — выдали данные теста
12.04 — нам разрешили участвовать удаленно
13.04 — мы начали смотреть чего там с данными
16.04 — финал
Особенности второго этапа
На втором этапе не было лидерборда: нужно было отправить только один сабмит в самом конце. То есть даже формат предсказаний не проверить. Также не были известны модели камер. А это значит сразу два фейла: не выйдет использовать внешние данные и локальная валидация может быть очень не репрезентативной.
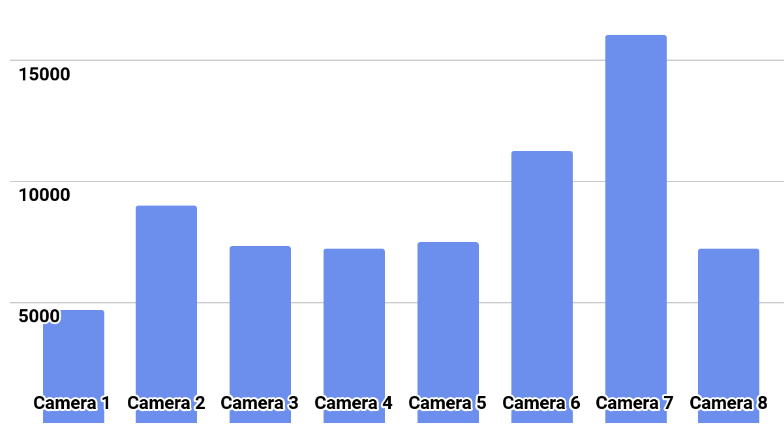
Распределение классов показано на картинке.
Решение
Мы попытались обучить модели пайпланом с первого этапа с весов лучших моделей. Все модели бодро обучались до 0.97+ accuracy на своих фолдах, но на тесте давали пересечение предсказаний в районе 0.87.
Что я интерпретировал как жесткий оверфит. Поэтому предложил новый план:

Логика здесь следующая. Нейросети уже обучены извлекать низкоуровневые фичи сенсора, оптики, алгоритма демозайки, и при этом не цепляются к контексту. Кроме того, фичи извлеченные перед финальным классификатором (по сути лог.регрессией) являются результатом сильно нелинейного преобразования. Поэтому можно было бы просто обучить что-то простое не склонное к переобучению, типа лог.регрессии. Однако поскольку новые данные могут сильно отличаться от данных первого этапа, то все-таки лучше обучить что-то нелинейное, например градиентный бустинг на решающий деревьях. Такой подход я использовал в нескольких соревнованиях, где выложил код.
Поскольку здесь был один сабмит, у меня нет надежных способов проверить свой подход. Однако, в качестве экстрактора фичей лучше всего показали себя DenseNet’ы. Resnext и SE-Resnext сети показывали более низкий перфоманс на локальной валидации. Поэтому финальное решение выглядело так.

Для части с манипуляциями количество всех обучающих сэмплов нужно умножить на 7, поскольку я извлек фичи с каждой манипуляции отдельно.
Послесловие
В итоге на финальном этапе мы заняли второе место, но тут есть много оговорок. Для начала, место присуждалось не по точности алгоритма, а по оценкам презентации жюри. Команда, которой присудили первое место, сделали не просто презу, но еще и лайв-демо с работой своего алгоритма. Ну и финальную скор каждой команды мы до сих пор не знаем, а орги не раскрывают их в переписке даже после прямых вопросов.
Из забавных вещей: на первом этапе все команды нашего комьюнити указали в названии команды [ods.ai] и довольно мощно окупировали лидерборд. После чего такие легенды кэггла как inversion и Giba решили присоединиться к нам, чтобы посмотреть чем же мы тут занимаемся.
Мне очень понравилось участвовать в качестве ментора. На основе опыта участия в предыдущих соревнованиях, мне удалось дать ряд ценных советов по улучшению бейзлайна, а также построению локальной валидации. В будущем такой формат более чем имеет место быть: Kaggle Master/Grandmaster как архитектор решения + 2-3 Kaggle Expert’a для написания кода и проверки гипотез. На мой взгляд, это чистый win-win, поскольку опытным участникам уже лень писать код и, возможно, нет столько времени, а начинающие получают более высокий результат, не совершают банальных ошибок по неопытности и набираются опыта еще быстрее.
→ Код нашего решения
→ Запись выступления с ML тренировки
tldr.py
from internet import yandex_fotki, flickr, wiki commons
from Andres_Torrubia import Ivan_Romanov as pytorch_baseline
import kaggle
dataset = kaggle.data()
for source in [yandex_fotki, flickr, wiki_commons]:
dataset[train].append(source.download())
predicts = []
for model in [densenet201, resnext101, se_resnext50, dpn98,
densenet161, resnext101 d4, se resnet50, dpn92]:
with pytorch_baseline():
model.fit(dataset[train])
predicts.append(model.predict_tta(dataset[test]))
kaggle.submit(gmean(predicts))
Постановка задачи
По фотографии необходимо определить устройство, на которое эта фотография была получена. Датасет состоял из картинок десяти классов: два айфона, семь андроид смартфонов и одна камера. В тренировочную выборку входили по 275 полноразмерных изображений каждого класса. В тестовой выборке были представлены только центральные кропы 512x512. Причем к 50 процентам из них была применена одна из трех аугментаций: jpg сжатие, ресайз с кубической интерполяцией или гамма коррекция. Можно было использовать внешние данные.
Суть (тм)
Если попытаться объяснить задачу простым языком, то идея представлена на картинке ниже. Как правило, современные нейросети учат отличать объекты на фотографии. т.е. нужно научиться отличать котиков от собачек, порнографию от купальников или танки от дорог. При этом, всегда должно быть безразлично каким образом и на какое устройство сделан снимок котика и танка.
В этом же конкурсе все было совсем наоборот. Вне зависимости от того, что показано на фото, нужно определить тип устройства. То есть использовать такие вещи как шумы матрицы, артефакты обработки снимков, дефекты оптики и т.д. В этом и состоял ключевой челлендж — разработать алгоритм цепляющий низкоуровневые фичи снимков.
Особенности командного взаимодействия
Подавляющая часть команд на kaggle формируется так: участники с близким скором по лидерборду объединяются в команду, при этом, каждый пилит свою версию решения от начала и до конца. Про типичный пример такого выступления я написал ранее пост. Однако в этот раз мы пошли другим путем, а именно: разделили части решения по людям. Кроме того, по правилам соревнования топ-3 студенческих команд получали путевку в Канаду на второй этап. Поэтому, когда собрался костяк, мы доукомплектовали команду, чтобы соответствовать правилам.
Решение
Чтобы показать хороший результат на этой задаче необходимо было собрать следующий пазл по приоритетам:
- Найти и скачать внешние данные. В этом соревновании было разрешено использовать неограниченное число внешних данных. И довольно быстро стало понятно, что большой внешний датасет тащит.
- Отфильтровать внешние данные. Люди иногда выкладывают обработанные снимки, что убивает все фичи устройства.
- Использовать надежную локальную схему валидации. Поскольку даже одна модель выдавала точность в районе 0.98+, а в тесте было всего 2к снимков, выбор чекпоинта модели был отдельной задачей
- Обучить модели. На форуме выложили очень мощный бейзлайн. Однако без щепотки магии он позволял получить только серебро.
Сбор данных
Этой частью занимался Артур Фаттахов. Для данной задачи внешние данные добыть было довольно легко, это просто снимки с определенных моделей телефонов. Артур написал python-скрипт, использующий библиотеку для удобного парсинга html-страниц, которая называется BeautifulSoup. Но, например, на странице альбома flickr блоки фотографий подгружаются динамически, и чтобы это обойти пришлось использовать selenium, который эмулировал действие браузера. Суммарно было скачано 500+ Гб фотографий с yandex.fotki, flickr, wiki commons.
Фильтрация данных
Это был мой единственный вклад в решение в виде кода. Я просто посмотрел как выглядят необработанные фотографии и сделал кучу правил: 1) размер, типичный для определенной модели 2) jpg качество выше порога 3) наличие нужных meta-тегов моделей 4) правильный софт, которым производилась обработка.
На рисунке показано распределение фотографий по источникам и мобилам до и после фильтрации. Как видно, например, Moto-X значительно меньше, чем других телефонов. При этом до фильтрации их было довольно много, но большая часть отсеялась из-за того, что есть множество вариантов этого телефона и обладатели не всегда верно указывали модель.
Валидация
Реализацией части с обучением и валидацией занимался Илья Кибардин. Валидация на куске kaggle-трейна вообще не работало — сетка выбивала практически 1.0 accuracy, а на лидерборде было около 0.96.
Поэтому под валидацию были взяты картинки Глеба Пособина, которые он взял со всяких сайтов с обзорами телефонов. В ней была ошибка: вместо айфона 6 там был айфон 6+. Мы заменили его на настоящий айфон 6 и докинули 10% картинок из трейна кагла, чтобы отбалансировать классы.
При обучении метрику считали так:
- Считаем кросс энтропию и акураси на центр кропах из валидации.
- Считаем кросс энтропию и акураси на (манипуляция + центр кроп) для каждой манипуляции из этих 8. Усредняя их по восьми манипуляциям арифметическим средним.
- Складываем скоры из п.1 и п.2 с весами 0.7 и 0.3.
Лучшие чекпоинты отбирали по полученной в п.3 взвешенной кросс энтропии.
Обучение моделей
Где-то в середине соревнования Андрес Торрубиа выложил весь код своего решения. Он был настолько хорош в плане точности финальных моделей, что куча команд полетели с ним вверх по лидерборду. Однако он был написал на keras’e и уровень кода желал лучшего.
Ситуация второй раз сильно поменялась, когда Иван Романов выложил pytorch версию этого кода. Она была быстрее и к тому же легко паралеллилась на несколько видеокарт. Уровень кода, впрочем все равно был не очень, но это не так важно.
Грусть заключается в том, что эти парни закончили на 30м и 45м месте соответственно, но в наших сердцах навсегда остались в топе.
Илья в нашей команде взял код Миши и произвел следующие изменения.
Препроцессинг:
- Из оригинальной картинки делается рандом кроп 960х960.
- С вероятностью 0.5 применяется одна случайная манипуляция. (В зависимости от того, применялась ли, ставится is_manip = 1 или 0)
- Делается случайный кроп 480х480
- Было два варианта обучения: либо делается случайный поворот на 90 градусов в конкретную сторону (имитация горизонтальной/вертикальной съемки для мобилы), либо случайное преобразование D4 группы.
Обучение
Обучение происходило finetune’ом сети целиком, не замораживая сверточные слои классификатор (у нас было много данных + интуитивно, веса, которые извлекают высокоуровневые объекты в виде кошек/собачек можно и подрасшатать, потому что нам нужны низкоуровневые фичи).
Шедулинг:
Adam с lr = 1e-4. Когда лосс на валидации перестает улучшаться в ходе 2-3 эпох, уменьшаем lr в два раза. Так до сходимости. Заменяем Adam на SGD и учим с циклическим lr от 1e-3 до 1e-6 три цикла.
Финальный ансамбль:
Я попросил Илью реализовать свой подход из предыдущего соревнования. Для фильного ансамбля мы обучили 9 моделей, от каждый выбрали 3 лучших чекпоинта, каждый чекпоинт предсказали с ТТА и в финале все предсказания усреднили геометрическим средним.
Послесловие первого этапа
В итоге мы заняли 2е место на лидерборде и 1е место среди студенческих команд. А это значит, что мы попали на 2й этап этого соревнования в рамках 2018 IEEE International Conference on Acoustics, Speech and Signal Processing в Канаде. Из примечательного, команда, которая заняла 3е место, тоже была формально студенческая. Если посчитать скор, то выходило, что мы обошли ее на одну правильно предсказанную картинку.
Final IEEE Signal Processing Cup 2018
После того как нам пришли все подтверждения, я, Валерий и Андрей решили не ехать в Канаду на второй этап. Илья и Артур Ф. решили ехать, начали все оформлять и им не дали визу. Чтобы избежать международного скандала по притеснению сильнейших дата саентистов из России, орги разрешили участвовать удаленно.
Таймлайн был такой:
30.03 — выдали данные трейна
04.09 — выдали данные теста
12.04 — нам разрешили участвовать удаленно
13.04 — мы начали смотреть чего там с данными
16.04 — финал
Особенности второго этапа
На втором этапе не было лидерборда: нужно было отправить только один сабмит в самом конце. То есть даже формат предсказаний не проверить. Также не были известны модели камер. А это значит сразу два фейла: не выйдет использовать внешние данные и локальная валидация может быть очень не репрезентативной.
Распределение классов показано на картинке.
Решение
Мы попытались обучить модели пайпланом с первого этапа с весов лучших моделей. Все модели бодро обучались до 0.97+ accuracy на своих фолдах, но на тесте давали пересечение предсказаний в районе 0.87.
Что я интерпретировал как жесткий оверфит. Поэтому предложил новый план:
- Берем наши лучшие модели первого этапа как фича экстракторы.
- От извлеченных фичей берем PCA, чтобы все обучалось за ночь.
- Обучаем LightGBM.
Логика здесь следующая. Нейросети уже обучены извлекать низкоуровневые фичи сенсора, оптики, алгоритма демозайки, и при этом не цепляются к контексту. Кроме того, фичи извлеченные перед финальным классификатором (по сути лог.регрессией) являются результатом сильно нелинейного преобразования. Поэтому можно было бы просто обучить что-то простое не склонное к переобучению, типа лог.регрессии. Однако поскольку новые данные могут сильно отличаться от данных первого этапа, то все-таки лучше обучить что-то нелинейное, например градиентный бустинг на решающий деревьях. Такой подход я использовал в нескольких соревнованиях, где выложил код.
Поскольку здесь был один сабмит, у меня нет надежных способов проверить свой подход. Однако, в качестве экстрактора фичей лучше всего показали себя DenseNet’ы. Resnext и SE-Resnext сети показывали более низкий перфоманс на локальной валидации. Поэтому финальное решение выглядело так.
Для части с манипуляциями количество всех обучающих сэмплов нужно умножить на 7, поскольку я извлек фичи с каждой манипуляции отдельно.
Послесловие
В итоге на финальном этапе мы заняли второе место, но тут есть много оговорок. Для начала, место присуждалось не по точности алгоритма, а по оценкам презентации жюри. Команда, которой присудили первое место, сделали не просто презу, но еще и лайв-демо с работой своего алгоритма. Ну и финальную скор каждой команды мы до сих пор не знаем, а орги не раскрывают их в переписке даже после прямых вопросов.
Из забавных вещей: на первом этапе все команды нашего комьюнити указали в названии команды [ods.ai] и довольно мощно окупировали лидерборд. После чего такие легенды кэггла как inversion и Giba решили присоединиться к нам, чтобы посмотреть чем же мы тут занимаемся.
Мне очень понравилось участвовать в качестве ментора. На основе опыта участия в предыдущих соревнованиях, мне удалось дать ряд ценных советов по улучшению бейзлайна, а также построению локальной валидации. В будущем такой формат более чем имеет место быть: Kaggle Master/Grandmaster как архитектор решения + 2-3 Kaggle Expert’a для написания кода и проверки гипотез. На мой взгляд, это чистый win-win, поскольку опытным участникам уже лень писать код и, возможно, нет столько времени, а начинающие получают более высокий результат, не совершают банальных ошибок по неопытности и набираются опыта еще быстрее.
→ Код нашего решения
→ Запись выступления с ML тренировки
