
Для того чтобы подготовить видео к стримингу на большое количество типов устройств, нужно сделать несколько шагов — от подготовки метаданных до упаковки в разные контейнеры (MP4, DASH, HLS) с разным битрейтом. В Ivi.ru построили гибкую систему с приоритетами, которая учитывает потребности бизнеса в скорости подготовки видео и умеет работать с пятью DRM-системами. Архитектурное решение основывается на жонглировании Docker-контейнерами и включает в себя как аппаратные средства для кодирования видео, так и софтверные. Подробно весь процесс и все тонкости работы с видео объяснил эксперт и технический директор ivi Евгений Россинский. Под катом — расшифровка его доклада с Backend Conf 2017.

О спикере
Евгений Россинский - с 2012 года по сей день работает CTO ivi. Руководил компанией по разработке высоконагруженных проектов Netstream, плодами которой были проекты, связанные с online-вещанием и видео (smotri.com, ivi). С 2012 года Netstream вместе со всей командой был поглощен ivi.
C 2006 г. преподает в МГТУ им. Баумана авторский курс «Технологии командной разработки ПО»
Сегодня расскажу, как мы погрызли кактус и поплакали с мышами на тему того, как сделать систему кодирования с последующей выгрузкой для OnDemand-видео.
Сначала я коротко познакомлю вас с нашим сервисом, чтобы вы понимали контекст, а потом уже перейдем к животно-сортирному юмору и различным подробностям.
Теперь перейдем непосредственно к тому, о чем хотелось бы поговорить, – как видео от правообладателя доходит до конечного пользователя.

1. Правообладатель отправляет нам либо ссылку, либо (в 10 % случаев эта система автоматизирована) по специальному протоколу мы забираем с их FTP ссылки на файлы оригиналов.
2. Специальный отдел Ingest (термин взят из телевидения) занимается подготовкой видео к передаче в Систему кодирования.
В чем заключается эта работа? Нужно проверить, что прислал правообладатель, если это вообще пригодно к просмотру, в том числе: посмотреть битрейт, в каких кодеках, возможно, где-то отрезать начало или конец, вывести уровень звука, сделать цветокоррекцию и прочие разные интересные вещи.
Отдел Ingest был реорганизован два года назад, когда мы всю это затеяли и выделили два типа специалистов:
Нашей задачей было сделать так, чтобы с ростом компании количество профессионалов, которые разбираются в видео, росло не сильно. Нужно было увеличивать число тех, кто «закидывает барана и получает две палки колбасы».
3. Из волшебного отдела Ingest видео попадает в Систему кодирования. Это уже наша вотчина, о которой я и расскажу.
4. После кодирования видео уходит на сервера Оriginals.
5. Дальше стандартная схема – видео раскладывается (с помощью магии или самостоятельно) на CDN и отправляется конечному пользователю.
Это простая классическая схема дистрибуции контента, начиная с серверов оригиналов и заканчивая CDN.
Но интересна нам будет сама система кодирования, о которой я вам расскажу дальше, а вы будете задавать гнусные вопросы.
Или почему два года назад мы пришли к выводу, что надо что-то менять и сделать мир лучше, а не хуже.
Мы любим ffmpeg, mp4box и прочее. Разработчик: «О, вышла новая версия, класс! Сейчас я быстренько ее соберу у себя! Блин, битрейт упал на 5%! Вообще огонь! Надо задеплоить!».
И тут начинается самое веселое – классическая проблема DevOps: у разработчика одна инфраструктура, на продакшн-серверах – другая. Начинается боль, содомия, кидание какашками, ненависть между отделами разработки и эксплуатации.
На самом деле попробуйте – поищите на рынке людей, которые прекрасно разбираются в кодировании видео, и чтобы их было еще много, поскольку приходит примерно 10 тысяч единиц контента.
Например, год назад мы взяли на пробу индийский сериал – надо было вывалить быстро 10 000 тайпов. Все они в разном битрейте, какие-то самим правообладателем скачаны с торрента – полная содомия. И это все нужно было как-то обработать.
Когда у вас система, которая требует очень умного и понимающего человека, 10 тысяч тайпов не обработать так, чтобы качество было нормальным. Поэтому мы предприняли ряд шагов.
Систему массового обслуживания нужно привести в чувство и эту самую задачу либо перезапустить, либо исправить и перезапустить, либо сказать: «ОК, это в принципе кодировать не можем».
Это вообще веселые ребята, которые просыпаются в районе ночи и начинают креативить.
На TechCrunch вышла какая-нибудь статейка типа «Израильский стартап выпустил новый кодек, который позволяет снизить битрейт видоса на 10%» Конечно же, надо попробовать! И внезапно получается: «Так, ОК, контактуем сейчас с израильским стартапом, из г*вна и палок лепим концепт, а теперь надо это все запустить в продакшн!».
И тут возвращаемся к первой проблеме, когда в пищевой цепочке появляется еще один потребитель, и это очень неприятно.
На самом деле, кодеков не очень большой зоопарк, а вот с контейнерами и DRM действительно огромный. Поскольку мы – легальный сервис, нам нельзя просто так взять и отдать прекрасный Dash или HLS, потому что нам просто этого не разрешают. Правообладатель говорит, например: «Ребята, фильм «Звездные войны» вы можете отдавать только на такой-то платформе и только в таком DRM».
DRM – это Digital rights management – штука, которая вроде бы защищает от скачивания и от возможности украсть аудио- и видеоконтент. Этих систем на самом деле несколько. Мы практически все популярные внедрили. Это, правда, боль и страдания.
Почему? Потому что по-хорошему ты не должен знать, как работает DRM – ведь это система защиты. Ты не имеешь права заниматься реверс-инжинирингом, но если этого не делать, эта ерунда не работает. Поэтому как тестировать и отлаживать работу DRM – это вообще отдельная песня.
Как результат, у нас появилось 52 различных конфигурации кодирования и пакетирования видеопотоков.
Например, есть старый телевизор LG, у которого представление об HLS очень специфическое. Если ты дашь ему честный, хороший, классный HLS, который проходит по всем стандартам, он играть его не сможет, хотя в доке у него написано, что может. Вообще у него ничего, кроме MP4, играть не получается – с соответствующими минусами для пользователя: время старта, буферизация и пр.
Поэтому для того чтобы играть на максимально большом количестве устройств, нам пришлось научиться либо генерировать эти форматы заранее, либо делать это на лету. Тут решают деньги – где нам это выгодно, а где нет. Об этом я чуть позже расскажу.
Например, нужно найти все видосы с keyframe в две сек. Зачем это может быть нужно, могу рассказать.
Например, нужно провести тест, насколько изменение длины чанка влияет на нагрузку на CDN и как это связано с алгоритмами кэширования. Эта информация нужна. Это – не жизненно важная история, без которой нельзя существовать, но очень полезная, если ты хочешь сделать эксплуатацию своего сервиса несколько более экономически эффективной.
Чтобы вы понимали: наша стоимость в шесть-семь раз дешевле, чем коммерческие предложения любого CDN. Там такие конские ценники закладывают. Но это бизнес, и он должен закладывать нормальную маржу. Поэтому система кодирования для нас – не пустой звук.
Первый, кто смотрит любые фичи перед тем, как мы катим это на prod, это QA-инженер. Он должен сначала прочитать многокилометровую инструкцию и затем у себя в кластере это поднять.
Вообще таски (фичи) по кодированию – самые сложные, потому что требуют большого времени. Тестировщик – тоже человек: он запустил что-то кодироваться и пошел бодренько пить чай. На этом у него контекст потерялся. Он вернулся – все упало – надо разбираться, что. Таких итераций много.
При том что на том же самом Web или на бэкенде мы гоним по 15-20 релизов в день. Это нормально.
В случае системы кодирования очень много времени уходит на то, чтобы дождаться, когда видео закодируется. Обработка тестового файлика, даже если он весь черный, нет никаких смен сцен, все равно требует определенного времени.
У нас несколько департаментов пользуются системой кодирования. Это отдел контента, который забирает от правообладателя, и есть еще веселые ребята под названием «Реклама».
Поскольку мы – гордые и независимые – чтобы не садиться на чужие пилюли и иголки, запустили свою рекламную крутилку. Рекламщикам нужно уметь быстро выкатить тот или иной рекламный материал нашему пользователю.
В таком интенсивном режиме мы просто не могли набирать людей в нужном количестве, которые разбираются в кодировании.
Что хотел бизнес? Бизнес хотел дешевых специалистов, которые все умеют и в восторге от рутинной, однотипной работы – просто прутся от нее!
Чего ждал технический департамент от специалиста по кодированию? Умения: «Ну, пожалуйста, сделай так, как на картинке!».
К чему мы шли?
При поступлении видео к нам в систему в первую очередь проверяется сам оригинал — поскольку даже классные ребята, которые разбираются в том, как правильно закодировать видео, могут ошибаться.
По статистике предыдущей версии системы очень часты были случаи, когда, например, оригинал пришел в битрейте 1 Мбит, а оператор кодирования бодренько просит от системы: «Сделай мне, пожалуйста, из этого Full HD».
Это возможно – upscale никто не отменял. Система берет и делает эту штуку. На выходе получается: 1 большой квадрат бежит за другим большим квадратом, и на все это смотрит третий большой квадрат. Инженеры контроля качества видео смотрят на это и говорят: «Ребята, это г*вно!».
После n-го количества обращений специалистов контроля качества видеоотоков мы добавили проверку битрейта.
В нашей практике было два смешных случая, когда правообладатель прислал видео размером 2 х 480, и эти две полоски случайно выложились на prod. Собственно, после этих двух полосок у нас и появился человеческий отдел контроля качества, и мы еще на первом этапе смотрим пропорции, чтобы видеопоток хоть как-то мог поместиться в 9:16 или хотя бы 3:4. В крайнем случае, 1:20 — но не 1:480.
Проверку FPS (Frame per second – количество кадров в секунду в видеопотоке) мы ввели около полугода назад, когда стали экспериментировать с генерацией HLS на лету.
Контроль FPS нужен для того, чтобы в начале каждого чанка всегда находился опорный кадр. Если чанк четыре или две секунды, а FPS дробный, так или иначе опорный кадр от начала чанка куда-нибудь уедет.
Конечно, можно подгонять, делать неравнозначные чанки и прочее. Но когда вы делаете адаптивный стриминг, нужно это как-то синхронизировать. Поэтому более простые правила порождают более простую эксплуатацию и понимание, как это все работает.
7-10% нашего контента живут с дробным FPS, и это видео нельзя стримить в произвольные контейнеры. Сейчас у нас есть система, которая позволяет на лету нарезать MP4 в HLS, в Dash, еще и кодировать все это.
Часто видео приходит вообще без звука, или звук помечен другим языком, или еще что-то.
Стандартный набор проверок, в том числе проверка размера файликов.
После того, как мы решили, что оригинал годен для последующей обработки, происходит его кодирование в нужный битрейт из одного файла в другой. Результирующий файл – MP4.
Дальше производится упаковка и, возможно, шифрование — если мы по каким-либо причинам хотим заранее упаковать видеопоток в тот или иной контейнер, чтобы потом отдавать с серверов original-статику. Статику всегда дешевле отдавать по нагрузке, но дороже хранить дополнительную копию битрейта.
Потом происходит отправка на сервера оригиналов, куда уже приходят специально обученные люди, которые занимаются контролем качества того, что получилось.
Контроль качества состоит из двух частей:
На самом деле тупо проверяем MD5 от потока, что нормально все скопировалось. Примерно раз в год вижу в логах историю о том, что донесли хреново – то есть это не придуманный случай.
После этого, поскольку мы все-таки сервис изымания денег из людей, мы размечаем места, где нужно показать рекламу, если это видео будет работать по модели с демонстрацией рекламы.
И то, что хорошо для пользователя, – устанавливается метка титров с нотификацией следующей серии и прочими вещами.
Наконец, специально обученный человек дергает рубильник и контент уходит к конечному потребителю: сервера Backend начинают раздавать ссылки именно на этот видеопоток.
Самый большой кластер у нас – это ffmpeg плюс разный софт. Можно выделить два типа: Hardware и Software.
Мы берем ffmpeg и MP4, HLS и прочие боксы, и это закрывает 95% всех задач кодирования, которые мы выполняем. Однако для экономии времени и проведения экспериментов год-полтора назад мы купили пару сервачков от компании Elemental.
Это не реклама, они и вправду неплохие ребята. Эти серверы дороже, чем все наши железки, вместе взятые, но у них есть один плюс. Если тебе сложно что-то сварить с помощью ffmpeg или опенсорсного софта, ты можешь всегда обратиться в саппорт и сказать: «Ребята, у меня Smooth Streaming не работает, сделайте, чтобы работало!».
Они тебе это отправляют, а потом, если ты хочешь это масштабировать, просто тупо копируешь то, что они выслали и, либо вставляешь в софтверное решение, либо говоришь: «ОК, пусть это крутится на Elemental».
Сейчас у нас в продакшн Elemental используется только для одной штуки. Мы делаем контент с DRM PlayReady, который отдаем в HSS. HSS – это как раз Smooth Streaming – Майкрософтовская хрень, которая сейчас поддерживается не таким большим количеством устройств. Но, например, телевизоры Филипс, как и старые Самсунги и LG, очень любят его.
Все остальные платформы несколько быстрее догоняют. На Smart TV вообще проблема с обновлением прошивок. Они очень часто забрасывают старые телики и по железу, и по всему. Там с саппортом беда.
Но есть люди, которые хотят смотреть кино на старых моделях, и наша задача – как-то подружить ужа с ежом.
В итоге примерно 95% у нас уходит на софтверное кодирование и 5% – на кодирование и упаковку с помощью Elemental. И очень большой кусок связан с R&D, который тоже проводим на Elemental. Там все-таки скорости несколько выше, потому что напиханы GPU.
Например, истории с 4К и с HDR мы сначала запилили на хардварном решении.
Вспоминая о первой проблеме, когда разработчики мочили эксплуатацию, а эксплуатация мочила разработчиков, мы сделали довольно простую штуку: взяли докер-контейнер и запихнули туда все, что связано с кодированием, убрав этим все сложности с настройкой инфраструктуры, сборкой ffmpeg, версиями и так далее.
Мы сделали:
Дальше я чуть-чуть расскажу, какие из систем оркестрации мы пробовали и почему решили остановиться на тривиальных и примитивных решениях именно для этой истории.
Предположим, мы хотим запустить новый сервер и сделать его частью облачка, которое занимается кодированием видео.
Работает бронебойно.
Каждый контейнер последовательно запрашивает задачи нескольких типов:
Попробовав выполнить по одной задаче каждого типа, контейнер, благополучно сложив результаты своей работы, отмирает.
Внутри контейнера:
Запуск этих волшебных вещей обернут Django, потому что так было проще на тот момент – можно было написать Shell-скрипты или обернуть это все в Джанговские команды.
Дальше встал вопрос – а как к этому всему добру подключить внешние сервисы?
Тоже довольно просто. На самом деле контейнер имеет еще один отдельный тип – отправить задачку куда-то еще. Он по SSH тупо лезет на Elemental и смотрит, есть ли у него там ресурс, чтобы:
Если есть – прекрасно, он выкачивает файлик, ставит задачку на кодирование и асинхронно уходит ждать.
Дальше он в цикле периодически спрашивает у Elemental: «Есть что там, готово?». Если готово, опять wget’ом выкачивает уже обратно и кладет в общую папочку результаты кодирования.
Таким образом мы подключали несколько разных, очень простых RPC-сервисов (или не очень простых), чтобы интегрировать это в систему кодирования.
Что дальше? А дальше это все выкатили в эксплуатацию и начали получать первые веселые отзывы.
Таким образом появилась такая интересная система приоритетов. Это все взято с реальных запросов, которые отправляли нам различные департаменты. Самым высшим назван приоритет «Внезапно».

Автор этой классификации – Володя Прохода – методично это все выписал и сейчас у нас действительно такая система приоритезации. И они в этом прекрасно разбираются! Они знают, что «Мне надо вчера» – это намного более важно, чем «Суперсрочно», «Суперсрочно» почему-то важнее, чем «Мегасрочно».
Собственно, какие пользователи, такие и запросы.
С приоритетами более-менее понятно, но их оказалось недостаточно. Почему? Потому что все, естественно, начали мочить «Внезапно» – ведь моя задача самая важная! А если еще бизнес пытается навесить KPI типа «Ты должен откодировать 20 видосов в час!», и ты думаешь: «Да, конечно, мне же надо! Внезапно! Давай! Горшочек, вари!».
У всех однозначно появилось «Внезапно»!
К чему это привело? К тому, что действительно важные задачи стали тупо ждать ресурсов. На самом деле можно было совершенно спокойно видео, которое нужно только через 4 месяца на продакшн, поставить с обычным приоритетом. Оно бы все равно за ночь откодировалось. Но пока люди сидят в офисе, им же нужно шампуры переворачивать и говорить, что у тебя подгорело.
Поэтому у нас появились маршруты.
Что это такое? По сути мы отгородили в своих вычислительных мощностях пространства, куда может ходить только определенный департамент.
Действительно срочных задач немного:
В этом году мы довольно часто выкладываем сериалы до эфира (catch-forward). Народ дрючит наш саппорт – когда же следующая серия «Отеля Эллион!? Я уже не могу ждать!» Там действительно время идет! Вы будете смеяться, но это правда. Я уже не говорю про популярность сериала «Сваты-6».
Поэтому горячие премьеры, особенно catch-forward или catch-up (сразу после телеэфира), надо выгружать быстро.
С рекламщиками еще хуже, потому что можно посчитать, сколько стоит получасовая или часовая задержка при таком большом количестве пользователей. Эти деньги – упущенная выгода компании.
Как только в спор между разными подразделениями встает бабло, люди перестают быть людьми и достают топор войны – кровь, слезы и сопли.
Поэтому мы сделали резервации, куда можно ходить, а куда ходить нельзя, и назвали их маршрутами.
На самом деле срочных задач действительно не очень много. Если в день приходит несколько супергорячих премьер и 20 рекламных роликов, то одна железка справляется с этим. Они, в принципе, друг с дпугом не конфликтуют. А все основные вещи совершенно спокойно могут решаться приоритетами.
Выделив отделу контента для премьер и трейлеров отдельный загончик, а рекламщикам – отдельную историю, мы достигли того, что они смогли более-менее неплохо договариваться и вести диалог. Мне так кажется, но они, может быть, считают по-другому.

Служба эксплуатации, когда к ней приходят с чем-то новым, всегда встречает это в штыки, потому что ее девиз «Не тронь технику, и она тебя не подведет!».
Как только приходит что-то новое, это значит, что тебе нужно меняться. Изменения всегда происходят через боль – человечество другого пока не придумало.
Поэтому мы хотели истории с виртуализацией, с докерами запустить несколько шире, чем только систему кодирования. Пошли двумя путями:
Это было два года назад. Полгода мы люто бились головой о стену, пытаясь решить те проблемы, которые «…вот-вот, через три месяца, сейчас мы зарелизим и все будет хорошо!». Это я про инженеров Kubernetes.
Готовясь к докладу, я посмотрел, какие изменения произошли там за два года. Да, действительно порядка 70% наших проблем закрыты. Сейчас можно этим всем уже, наверное, пользоваться, но мы уже убили полгода, и следующий виток, я думаю, будет через полгода-год.
У нас есть специальные DevOps-инженеры, которые помогают людям скрещивать ужа с ежом. Хотя в принципе заюзать Docker-контейнер получается довольно просто.
Но Kubernetes нас доканал. Человек, который его внедрял, приуныл, и через полгода уволился потому, что делаешь, делаешь, вроде бы, по документации все хорошо, и мысли у тебя правильные, и направление тоже, но горшочек не варит!
А через месяц после того, как мы решили, что не будем делать Kubernetes, один из наших разработчиков написал очень простую систему оркестрации, как раз для решения локальной проблемы поднятия тестового кластера для тестировщиков.
Kubernetes решает все-таки более глобальные проблемы – как на продакшене все это делать, а не только на тестовом кластере. Да, у меня была мечта ломануться с этим на продакшн, но сначала была идея первого шага – сделать тестовую инфраструктуру.
Оказалось, что тестовую инфраструктуру намного проще сделать без помощи сложной системы оркестрации, хотя я ни в коем разе не критикую путь Kubernetes. Он правильный, просто на тот момент, когда мы начали, было еще очень сыро.
Docker-контейнеры собираются довольно быстро – за несколько секунд.
Есть вычислительные мощности – поднимаешь туда все, что тебе нужно, с помощью Puppet, и все работает быстро.
Снизилось количество обращений от отдела Ingest в отдел разработки. Мне важно, чтобы разработчики занимались разработкой, а не саппортом. Сейчас, наверное, максимум раза два в месяц кто-то из программистов смотрит, что произошло с той или иной задачкой, что идет не так. При этом, как правило, они не лезут в код, а используют специальную админку.
Мне, как техническому директору, стало несколько спокойнее жить, потому что люди не перекладывают бумажки из одного ящика в другой, а делают доброе, светлое, вечное… или нет.
Попробовали на примере Elemental и, например, яблочного упаковщика в HLS подключать внешние сервисы.
Это нужно как раз для оптимизации работы CDN, чтобы адаптивный стриминг лучше шурупил. До создания этой системы вопрос перекодирования всего каталога мог занимать от полугода до года. У нас действительно много видео!
Сейчас, я думаю, на тех мощностях, которые есть, можно справиться за полтора-два месяца. Вопрос только: зачем?
При этом совершенно спокойно можно арендовать облачко, главное, чтобы это облачко было где-то недалеко от тебя, потому что как-то к нам пришел Амазон и сказал:
— Смотрите, классическая задача – давайте, поднимете у нас…
— А у вас в России что-то есть?
— Так, чтобы к вам близко, нет.
— Смотрите, у нас два Pb оригиналов. Нам нужно, условно говоря, перегнать их туда, а потом забрать. Сколько мы вам за трафон заплатим?
— Ну, да… В России поднимемся, придем.
По времени, если гонять куда-то далеко, расстояние имеет очень существенное воздействие на выбор партнера, где можно, например, поднять внешние вычислительные мощности.
Действительно, две недели на тестирование и проверку качества любой новой фичи в системе кодирования, которые я описывал раньше, – это адо-содомия. Просто на корню зарубает все желание получать какие-то фичи от этой системы.
А сейчас день-два, если совсем геморрой – три-четыре. Плюс – понятно, как это делать. Тестировщик не занимается инфраструктурными проблемами. Он не ходит вокруг девопсера, не говорит: «Блин, у меня вот то же самое не работает, почему?». Сейчас (по крайней мере, я на это надеюсь) тестировщики перестали бояться брать на себя задачки по контролю качества системы кодирования.
В ответах на вопросы после доклада зачастую содержатся самые интересные фишки и любопытные детали, поэтому мы собрали их тут
Также мы открыли доступ ко всем видеозаписям выступлений с Backend Conf 2017 и HighLoad++ Junior.
Экспертов и профессионалов мы приглашаем стать спикерами на майском фестивале конференций РИТ++. Если у вас есть интересный опыт разработки и вы готовы им поделиться, оставьте заявку для нашего программного комитета.
О спикере
Евгений Россинский - с 2012 года по сей день работает CTO ivi. Руководил компанией по разработке высоконагруженных проектов Netstream, плодами которой были проекты, связанные с online-вещанием и видео (smotri.com, ivi). С 2012 года Netstream вместе со всей командой был поглощен ivi.
C 2006 г. преподает в МГТУ им. Баумана авторский курс «Технологии командной разработки ПО»
Сегодня расскажу, как мы погрызли кактус и поплакали с мышами на тему того, как сделать систему кодирования с последующей выгрузкой для OnDemand-видео.
Сначала я коротко познакомлю вас с нашим сервисом, чтобы вы понимали контекст, а потом уже перейдем к животно-сортирному юмору и различным подробностям.
Немного об IVI
- «Ivi» показывает легальное видео.
- У нас очень много различных клиентских приложений: играем на Web, iOS, кофеварках, телевизорах. Недавно запустили приложение XBOX.
- Это highload-проект с многомиллионной аудиторией – 33 млн!
- Уже несколько лет назад построили свой CDN: 30 городов в России и 3 ДЦ в Москве с кольцом 150 Гбит.
- Развлекаемся такой нагрузкой как 70 тысяч запросов в секунду.
Теперь перейдем непосредственно к тому, о чем хотелось бы поговорить, – как видео от правообладателя доходит до конечного пользователя.
1. Правообладатель отправляет нам либо ссылку, либо (в 10 % случаев эта система автоматизирована) по специальному протоколу мы забираем с их FTP ссылки на файлы оригиналов.
2. Специальный отдел Ingest (термин взят из телевидения) занимается подготовкой видео к передаче в Систему кодирования.
В чем заключается эта работа? Нужно проверить, что прислал правообладатель, если это вообще пригодно к просмотру, в том числе: посмотреть битрейт, в каких кодеках, возможно, где-то отрезать начало или конец, вывести уровень звука, сделать цветокоррекцию и прочие разные интересные вещи.
Отдел Ingest был реорганизован два года назад, когда мы всю это затеяли и выделили два типа специалистов:
- люди, которые действительно разбираются в кодировании видео, — и для них слова GOP и keyframe не являются пустым набором символов.
- операторы системы массового обслуживания под названием Система кодирования. У них есть баран, они кидают его в систему массового обслуживания, с другой стороны получают две палки колбасы. Нюхают колбасу – нормальная? – лей на prod.
Нашей задачей было сделать так, чтобы с ростом компании количество профессионалов, которые разбираются в видео, росло не сильно. Нужно было увеличивать число тех, кто «закидывает барана и получает две палки колбасы».
3. Из волшебного отдела Ingest видео попадает в Систему кодирования. Это уже наша вотчина, о которой я и расскажу.
4. После кодирования видео уходит на сервера Оriginals.
5. Дальше стандартная схема – видео раскладывается (с помощью магии или самостоятельно) на CDN и отправляется конечному пользователю.
Это простая классическая схема дистрибуции контента, начиная с серверов оригиналов и заканчивая CDN.
Но интересна нам будет сама система кодирования, о которой я вам расскажу дальше, а вы будете задавать гнусные вопросы.
Какие у нас были проблемы
Или почему два года назад мы пришли к выводу, что надо что-то менять и сделать мир лучше, а не хуже.
- У нас были просто многокилометровые инструкции о том, как создать продакшн-среду для кодирования.
Мы любим ffmpeg, mp4box и прочее. Разработчик: «О, вышла новая версия, класс! Сейчас я быстренько ее соберу у себя! Блин, битрейт упал на 5%! Вообще огонь! Надо задеплоить!».
И тут начинается самое веселое – классическая проблема DevOps: у разработчика одна инфраструктура, на продакшн-серверах – другая. Начинается боль, содомия, кидание какашками, ненависть между отделами разработки и эксплуатации.
Можно много говорить – да, нужен DevOps и пр. Но на самом деле нет – люди всегда есть люди, они ненавидят друг друга. Поэтому надо дать сначала технологическую платформу, которая уберет противостояние.
- Вторая большая проблема – нам нужно было действительно сильно снизить требования к уровню вхождения операторов системы кодирования.
На самом деле попробуйте – поищите на рынке людей, которые прекрасно разбираются в кодировании видео, и чтобы их было еще много, поскольку приходит примерно 10 тысяч единиц контента.
Например, год назад мы взяли на пробу индийский сериал – надо было вывалить быстро 10 000 тайпов. Все они в разном битрейте, какие-то самим правообладателем скачаны с торрента – полная содомия. И это все нужно было как-то обработать.
Когда у вас система, которая требует очень умного и понимающего человека, 10 тысяч тайпов не обработать так, чтобы качество было нормальным. Поэтому мы предприняли ряд шагов.
- Следующая проблема – для того, чтобы подготовить видео к стримингу, нужно пройти большое количество этапов, а значит, на каждом этапе вы можете облажаться – совершить ошибку.
Систему массового обслуживания нужно привести в чувство и эту самую задачу либо перезапустить, либо исправить и перезапустить, либо сказать: «ОК, это в принципе кодировать не можем».
- Следующая история – R&D.
Это вообще веселые ребята, которые просыпаются в районе ночи и начинают креативить.
На TechCrunch вышла какая-нибудь статейка типа «Израильский стартап выпустил новый кодек, который позволяет снизить битрейт видоса на 10%» Конечно же, надо попробовать! И внезапно получается: «Так, ОК, контактуем сейчас с израильским стартапом, из г*вна и палок лепим концепт, а теперь надо это все запустить в продакшн!».
И тут возвращаемся к первой проблеме, когда в пищевой цепочке появляется еще один потребитель, и это очень неприятно.
- Дальше – зоопарк контейнеров, кодеков и DRM.
На самом деле, кодеков не очень большой зоопарк, а вот с контейнерами и DRM действительно огромный. Поскольку мы – легальный сервис, нам нельзя просто так взять и отдать прекрасный Dash или HLS, потому что нам просто этого не разрешают. Правообладатель говорит, например: «Ребята, фильм «Звездные войны» вы можете отдавать только на такой-то платформе и только в таком DRM».
DRM – это Digital rights management – штука, которая вроде бы защищает от скачивания и от возможности украсть аудио- и видеоконтент. Этих систем на самом деле несколько. Мы практически все популярные внедрили. Это, правда, боль и страдания.
Почему? Потому что по-хорошему ты не должен знать, как работает DRM – ведь это система защиты. Ты не имеешь права заниматься реверс-инжинирингом, но если этого не делать, эта ерунда не работает. Поэтому как тестировать и отлаживать работу DRM – это вообще отдельная песня.
Как результат, у нас появилось 52 различных конфигурации кодирования и пакетирования видеопотоков.
Например, есть старый телевизор LG, у которого представление об HLS очень специфическое. Если ты дашь ему честный, хороший, классный HLS, который проходит по всем стандартам, он играть его не сможет, хотя в доке у него написано, что может. Вообще у него ничего, кроме MP4, играть не получается – с соответствующими минусами для пользователя: время старта, буферизация и пр.
Поэтому для того чтобы играть на максимально большом количестве устройств, нам пришлось научиться либо генерировать эти форматы заранее, либо делать это на лету. Тут решают деньги – где нам это выгодно, а где нет. Об этом я чуть позже расскажу.
- Следующая боль – нам нужно было уметь сохранять истории параметров кодирования, чтобы в дальнейшем понимать, что можно делать с этими видеофайлами, а что нельзя.
Например, нужно найти все видосы с keyframe в две сек. Зачем это может быть нужно, могу рассказать.
Например, нужно провести тест, насколько изменение длины чанка влияет на нагрузку на CDN и как это связано с алгоритмами кэширования. Эта информация нужна. Это – не жизненно важная история, без которой нельзя существовать, но очень полезная, если ты хочешь сделать эксплуатацию своего сервиса несколько более экономически эффективной.
Чтобы вы понимали: наша стоимость в шесть-семь раз дешевле, чем коммерческие предложения любого CDN. Там такие конские ценники закладывают. Но это бизнес, и он должен закладывать нормальную маржу. Поэтому система кодирования для нас – не пустой звук.
- Как и в случае с DevOps, есть большие проблемы с тестированием систем.
Первый, кто смотрит любые фичи перед тем, как мы катим это на prod, это QA-инженер. Он должен сначала прочитать многокилометровую инструкцию и затем у себя в кластере это поднять.
Вообще таски (фичи) по кодированию – самые сложные, потому что требуют большого времени. Тестировщик – тоже человек: он запустил что-то кодироваться и пошел бодренько пить чай. На этом у него контекст потерялся. Он вернулся – все упало – надо разбираться, что. Таких итераций много.
Два года назад время тестирования одной новой фичи в среднем занимало у нас две недели. Это было прям очень больно.
При том что на том же самом Web или на бэкенде мы гоним по 15-20 релизов в день. Это нормально.
В случае системы кодирования очень много времени уходит на то, чтобы дождаться, когда видео закодируется. Обработка тестового файлика, даже если он весь черный, нет никаких смен сцен, все равно требует определенного времени.
- Стандартные проблемы с системой массового обслуживания большого количества потребителей.
У нас несколько департаментов пользуются системой кодирования. Это отдел контента, который забирает от правообладателя, и есть еще веселые ребята под названием «Реклама».
Поскольку мы – гордые и независимые – чтобы не садиться на чужие пилюли и иголки, запустили свою рекламную крутилку. Рекламщикам нужно уметь быстро выкатить тот или иной рекламный материал нашему пользователю.
Кто такой оператор кодирования
В таком интенсивном режиме мы просто не могли набирать людей в нужном количестве, которые разбираются в кодировании.
Что хотел бизнес? Бизнес хотел дешевых специалистов, которые все умеют и в восторге от рутинной, однотипной работы – просто прутся от нее!
Чего ждал технический департамент от специалиста по кодированию? Умения: «Ну, пожалуйста, сделай так, как на картинке!».
К чему мы шли?
- Хотели создать систему с низким уровнем вхождения для операторов.
- Для того, чтобы была возможность использования дешевых низкоквалифицированных сотрудников, которых по требованию можно подключать и отключать.
- Чтобы не увеличивать число дорогостоящих профессионалов – не настолько оправдано использование такого количества людей высокой квалификации.
Этапы подготовки видео
Этап #1
При поступлении видео к нам в систему в первую очередь проверяется сам оригинал — поскольку даже классные ребята, которые разбираются в том, как правильно закодировать видео, могут ошибаться.
- Битрейт.
По статистике предыдущей версии системы очень часты были случаи, когда, например, оригинал пришел в битрейте 1 Мбит, а оператор кодирования бодренько просит от системы: «Сделай мне, пожалуйста, из этого Full HD».
Это возможно – upscale никто не отменял. Система берет и делает эту штуку. На выходе получается: 1 большой квадрат бежит за другим большим квадратом, и на все это смотрит третий большой квадрат. Инженеры контроля качества видео смотрят на это и говорят: «Ребята, это г*вно!».
После n-го количества обращений специалистов контроля качества видеоотоков мы добавили проверку битрейта.
- Пропорции.
В нашей практике было два смешных случая, когда правообладатель прислал видео размером 2 х 480, и эти две полоски случайно выложились на prod. Собственно, после этих двух полосок у нас и появился человеческий отдел контроля качества, и мы еще на первом этапе смотрим пропорции, чтобы видеопоток хоть как-то мог поместиться в 9:16 или хотя бы 3:4. В крайнем случае, 1:20 — но не 1:480.
- FPS.
Проверку FPS (Frame per second – количество кадров в секунду в видеопотоке) мы ввели около полугода назад, когда стали экспериментировать с генерацией HLS на лету.
Контроль FPS нужен для того, чтобы в начале каждого чанка всегда находился опорный кадр. Если чанк четыре или две секунды, а FPS дробный, так или иначе опорный кадр от начала чанка куда-нибудь уедет.
Конечно, можно подгонять, делать неравнозначные чанки и прочее. Но когда вы делаете адаптивный стриминг, нужно это как-то синхронизировать. Поэтому более простые правила порождают более простую эксплуатацию и понимание, как это все работает.
7-10% нашего контента живут с дробным FPS, и это видео нельзя стримить в произвольные контейнеры. Сейчас у нас есть система, которая позволяет на лету нарезать MP4 в HLS, в Dash, еще и кодировать все это.
С дробным FPS получается плохо. Почему? Потому что в момент переключения на другой стрим начинает работать адаптивный стриминг. У пользователя затупил канал, надо быстренько переключиться на другой чанк. Он переключается на другой чанк, а там нет опорного кадра. Тогда на какое-то время у пользователя может развалиться картинка и появиться черный экран. Все зависит от того, как реализован кодек на клиентской стороне.
- Звуковые дорожки.
Часто видео приходит вообще без звука, или звук помечен другим языком, или еще что-то.
- Прочее.
Стандартный набор проверок, в том числе проверка размера файликов.
Этап #2
После того, как мы решили, что оригинал годен для последующей обработки, происходит его кодирование в нужный битрейт из одного файла в другой. Результирующий файл – MP4.
Этап #3
Дальше производится упаковка и, возможно, шифрование — если мы по каким-либо причинам хотим заранее упаковать видеопоток в тот или иной контейнер, чтобы потом отдавать с серверов original-статику. Статику всегда дешевле отдавать по нагрузке, но дороже хранить дополнительную копию битрейта.
Этапы #4-5
Потом происходит отправка на сервера оригиналов, куда уже приходят специально обученные люди, которые занимаются контролем качества того, что получилось.
Контроль качества состоит из двух частей:
- Тривиальная проверка, нормально ли мы вообще донесли файлик с контентом до сервера оригиналов.
На самом деле тупо проверяем MD5 от потока, что нормально все скопировалось. Примерно раз в год вижу в логах историю о том, что донесли хреново – то есть это не придуманный случай.
- Дальше специально обученный человек смотрит во встроенном плеере (сначала в админке), как это все смотрится, соответствует ли текущему качеству то, что мы накодировали.
Этап #6
После этого, поскольку мы все-таки сервис изымания денег из людей, мы размечаем места, где нужно показать рекламу, если это видео будет работать по модели с демонстрацией рекламы.
И то, что хорошо для пользователя, – устанавливается метка титров с нотификацией следующей серии и прочими вещами.
Этап #7
Наконец, специально обученный человек дергает рубильник и контент уходит к конечному потребителю: сервера Backend начинают раздавать ссылки именно на этот видеопоток.
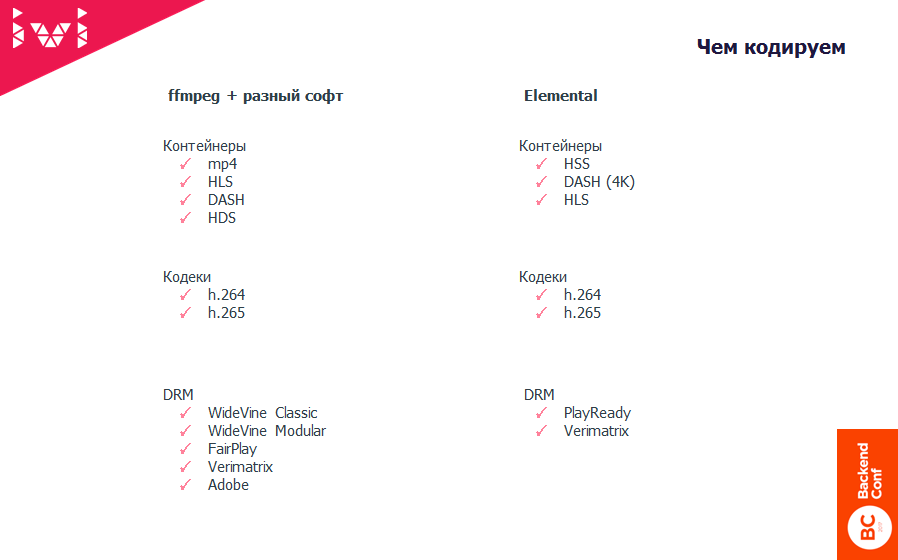
Чем мы кодируем?
Самый большой кластер у нас – это ffmpeg плюс разный софт. Можно выделить два типа: Hardware и Software.
Мы берем ffmpeg и MP4, HLS и прочие боксы, и это закрывает 95% всех задач кодирования, которые мы выполняем. Однако для экономии времени и проведения экспериментов год-полтора назад мы купили пару сервачков от компании Elemental.
Это не реклама, они и вправду неплохие ребята. Эти серверы дороже, чем все наши железки, вместе взятые, но у них есть один плюс. Если тебе сложно что-то сварить с помощью ffmpeg или опенсорсного софта, ты можешь всегда обратиться в саппорт и сказать: «Ребята, у меня Smooth Streaming не работает, сделайте, чтобы работало!».
Они тебе это отправляют, а потом, если ты хочешь это масштабировать, просто тупо копируешь то, что они выслали и, либо вставляешь в софтверное решение, либо говоришь: «ОК, пусть это крутится на Elemental».
Сейчас у нас в продакшн Elemental используется только для одной штуки. Мы делаем контент с DRM PlayReady, который отдаем в HSS. HSS – это как раз Smooth Streaming – Майкрософтовская хрень, которая сейчас поддерживается не таким большим количеством устройств. Но, например, телевизоры Филипс, как и старые Самсунги и LG, очень любят его.
Все остальные платформы несколько быстрее догоняют. На Smart TV вообще проблема с обновлением прошивок. Они очень часто забрасывают старые телики и по железу, и по всему. Там с саппортом беда.
Но есть люди, которые хотят смотреть кино на старых моделях, и наша задача – как-то подружить ужа с ежом.
В итоге примерно 95% у нас уходит на софтверное кодирование и 5% – на кодирование и упаковку с помощью Elemental. И очень большой кусок связан с R&D, который тоже проводим на Elemental. Там все-таки скорости несколько выше, потому что напиханы GPU.
Например, истории с 4К и с HDR мы сначала запилили на хардварном решении.
Как это все работает внутри и как мы к этому пришли
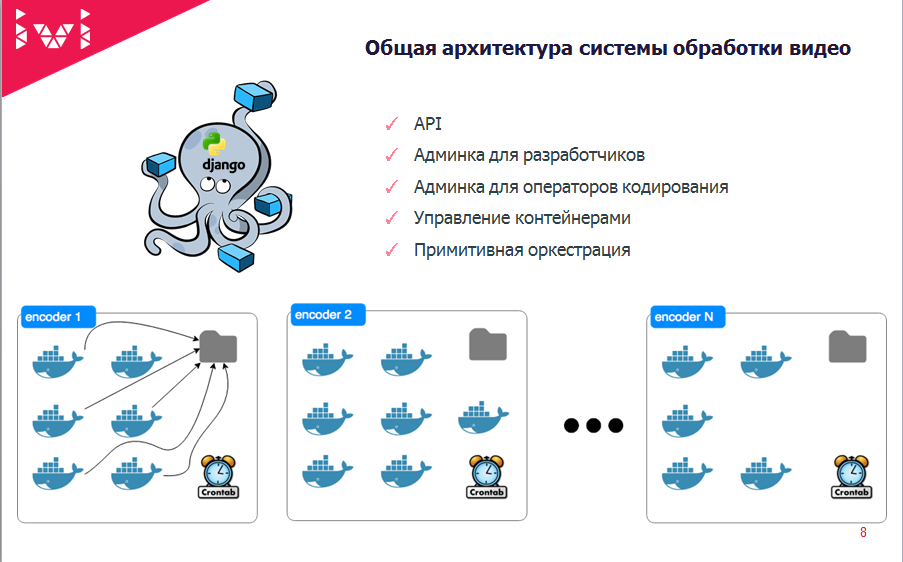
Вспоминая о первой проблеме, когда разработчики мочили эксплуатацию, а эксплуатация мочила разработчиков, мы сделали довольно простую штуку: взяли докер-контейнер и запихнули туда все, что связано с кодированием, убрав этим все сложности с настройкой инфраструктуры, сборкой ffmpeg, версиями и так далее.
Мы сделали:
- API;
- админку для разработчика, с помощью которой они могут разбираться со сложными случаями;
- админку для операторов кодирования;
- управление контейнерами;
- очень примитивную оркестрацию.
Дальше я чуть-чуть расскажу, какие из систем оркестрации мы пробовали и почему решили остановиться на тривиальных и примитивных решениях именно для этой истории.
Как это работает (на пальцах)
Предположим, мы хотим запустить новый сервер и сделать его частью облачка, которое занимается кодированием видео.
- Мы загружаем туда через Puppet всю конфигурацию;
- Устанавливаем Cron, который раз в минуту проверяет, есть ли свободное место для того, чтобы запустить еще один контейнер;
- Дальше этот контейнер поднимается, смотрит, есть ли для него задания на кодирование, и выполняет их. На сервере есть расшаренная папочка, куда он кладет свои результаты, и, благополучно выполнив задачу, умирает, при этом поделившись логами с историей кодирования. Все очень просто.
- Потом по Cron’у просыпается новая штука, смотрит, есть ли что делать. Если есть, то бежит туда.
Работает бронебойно.
Что внутри контейнера?
Каждый контейнер последовательно запрашивает задачи нескольких типов:
- Сначала он говорит: «Друзья, есть ли что сделать именно по самому видео? Нужно ли мне в какой-то другой битрейт его перегнать?» И делает MP4.
- Откодировав MP4, он говорит: «Друзья, я сделал MP4, все хорошо. А может быть нужно упаковать в HLS?» На самом деле, это не обязательно тот самый MP4 — это может быть абсолютно любой другой MP4 с другим битрейтом.
- Дальше происходит аналогичная история с DASH и затем – с HDS.
Попробовав выполнить по одной задаче каждого типа, контейнер, благополучно сложив результаты своей работы, отмирает.
Внутри контейнера:
- Ubuntu,
- ffmpeg,
- ffprobe,
- mp4box.
Запуск этих волшебных вещей обернут Django, потому что так было проще на тот момент – можно было написать Shell-скрипты или обернуть это все в Джанговские команды.
Интеграция с внешними сервисами
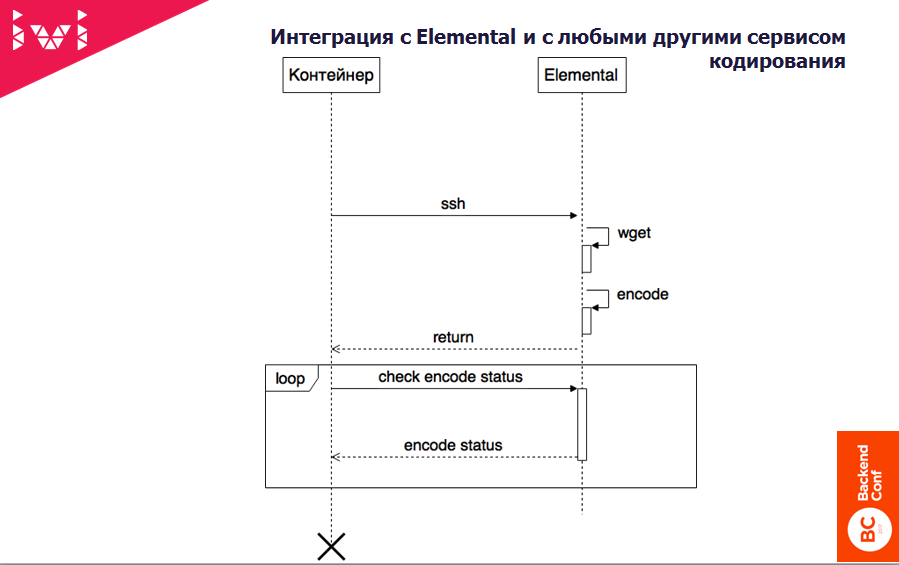
Дальше встал вопрос – а как к этому всему добру подключить внешние сервисы?
Тоже довольно просто. На самом деле контейнер имеет еще один отдельный тип – отправить задачку куда-то еще. Он по SSH тупо лезет на Elemental и смотрит, есть ли у него там ресурс, чтобы:
- выкачать файл;
- запустить задачку.
Если есть – прекрасно, он выкачивает файлик, ставит задачку на кодирование и асинхронно уходит ждать.
Дальше он в цикле периодически спрашивает у Elemental: «Есть что там, готово?». Если готово, опять wget’ом выкачивает уже обратно и кладет в общую папочку результаты кодирования.
Таким образом мы подключали несколько разных, очень простых RPC-сервисов (или не очень простых), чтобы интегрировать это в систему кодирования.
Приоритеты
Что дальше? А дальше это все выкатили в эксплуатацию и начали получать первые веселые отзывы.
Таким образом появилась такая интересная система приоритетов. Это все взято с реальных запросов, которые отправляли нам различные департаменты. Самым высшим назван приоритет «Внезапно».
Автор этой классификации – Володя Прохода – методично это все выписал и сейчас у нас действительно такая система приоритезации. И они в этом прекрасно разбираются! Они знают, что «Мне надо вчера» – это намного более важно, чем «Суперсрочно», «Суперсрочно» почему-то важнее, чем «Мегасрочно».
Собственно, какие пользователи, такие и запросы.
С приоритетами более-менее понятно, но их оказалось недостаточно. Почему? Потому что все, естественно, начали мочить «Внезапно» – ведь моя задача самая важная! А если еще бизнес пытается навесить KPI типа «Ты должен откодировать 20 видосов в час!», и ты думаешь: «Да, конечно, мне же надо! Внезапно! Давай! Горшочек, вари!».
У всех однозначно появилось «Внезапно»!
К чему это привело? К тому, что действительно важные задачи стали тупо ждать ресурсов. На самом деле можно было совершенно спокойно видео, которое нужно только через 4 месяца на продакшн, поставить с обычным приоритетом. Оно бы все равно за ночь откодировалось. Но пока люди сидят в офисе, им же нужно шампуры переворачивать и говорить, что у тебя подгорело.
Поэтому у нас появились маршруты.
Маршруты
Что это такое? По сути мы отгородили в своих вычислительных мощностях пространства, куда может ходить только определенный департамент.
Действительно срочных задач немного:
- трейлеры,
- реклама,
- горячие премьеры.
В этом году мы довольно часто выкладываем сериалы до эфира (catch-forward). Народ дрючит наш саппорт – когда же следующая серия «Отеля Эллион!? Я уже не могу ждать!» Там действительно время идет! Вы будете смеяться, но это правда. Я уже не говорю про популярность сериала «Сваты-6».
Поэтому горячие премьеры, особенно catch-forward или catch-up (сразу после телеэфира), надо выгружать быстро.
С рекламщиками еще хуже, потому что можно посчитать, сколько стоит получасовая или часовая задержка при таком большом количестве пользователей. Эти деньги – упущенная выгода компании.
Как только в спор между разными подразделениями встает бабло, люди перестают быть людьми и достают топор войны – кровь, слезы и сопли.
Поэтому мы сделали резервации, куда можно ходить, а куда ходить нельзя, и назвали их маршрутами.
На самом деле срочных задач действительно не очень много. Если в день приходит несколько супергорячих премьер и 20 рекламных роликов, то одна железка справляется с этим. Они, в принципе, друг с дпугом не конфликтуют. А все основные вещи совершенно спокойно могут решаться приоритетами.
Выделив отделу контента для премьер и трейлеров отдельный загончик, а рекламщикам – отдельную историю, мы достигли того, что они смогли более-менее неплохо договариваться и вести диалог. Мне так кажется, но они, может быть, считают по-другому.
Служба эксплуатации, когда к ней приходят с чем-то новым, всегда встречает это в штыки, потому что ее девиз «Не тронь технику, и она тебя не подведет!».
Как только приходит что-то новое, это значит, что тебе нужно меняться. Изменения всегда происходят через боль – человечество другого пока не придумало.
Поэтому мы хотели истории с виртуализацией, с докерами запустить несколько шире, чем только систему кодирования. Пошли двумя путями:
- Мы попытались внедрить Kubernetes для того, чтобы тестовые кластеры для наших QA-инженеров работали на нем.
- Нам нужна была оркестрация.
Это было два года назад. Полгода мы люто бились головой о стену, пытаясь решить те проблемы, которые «…вот-вот, через три месяца, сейчас мы зарелизим и все будет хорошо!». Это я про инженеров Kubernetes.
Готовясь к докладу, я посмотрел, какие изменения произошли там за два года. Да, действительно порядка 70% наших проблем закрыты. Сейчас можно этим всем уже, наверное, пользоваться, но мы уже убили полгода, и следующий виток, я думаю, будет через полгода-год.
Но при этом нам очень понравилась история как раз с Docker-контейнерами – простота, с которой можно завернуть нужную тебе конфигурацию, причем абсолютно без конфликта между отделом эксплуатации и отделом разработки.
У нас есть специальные DevOps-инженеры, которые помогают людям скрещивать ужа с ежом. Хотя в принципе заюзать Docker-контейнер получается довольно просто.
Но Kubernetes нас доканал. Человек, который его внедрял, приуныл, и через полгода уволился потому, что делаешь, делаешь, вроде бы, по документации все хорошо, и мысли у тебя правильные, и направление тоже, но горшочек не варит!
А через месяц после того, как мы решили, что не будем делать Kubernetes, один из наших разработчиков написал очень простую систему оркестрации, как раз для решения локальной проблемы поднятия тестового кластера для тестировщиков.
Kubernetes решает все-таки более глобальные проблемы – как на продакшене все это делать, а не только на тестовом кластере. Да, у меня была мечта ломануться с этим на продакшн, но сначала была идея первого шага – сделать тестовую инфраструктуру.
Оказалось, что тестовую инфраструктуру намного проще сделать без помощи сложной системы оркестрации, хотя я ни в коем разе не критикую путь Kubernetes. Он правильный, просто на тот момент, когда мы начали, было еще очень сыро.
Чего нам удалось добиться?
- Во-первых, действительно простоты в эксплуатации.
Docker-контейнеры собираются довольно быстро – за несколько секунд.
- Мы получили очень хорошие возможности масштабирования.
Есть вычислительные мощности – поднимаешь туда все, что тебе нужно, с помощью Puppet, и все работает быстро.
- Очень важно для нас подробное логирование всех этапов обработки видео.
Снизилось количество обращений от отдела Ingest в отдел разработки. Мне важно, чтобы разработчики занимались разработкой, а не саппортом. Сейчас, наверное, максимум раза два в месяц кто-то из программистов смотрит, что произошло с той или иной задачкой, что идет не так. При этом, как правило, они не лезут в код, а используют специальную админку.
Мне, как техническому директору, стало несколько спокойнее жить, потому что люди не перекладывают бумажки из одного ящика в другой, а делают доброе, светлое, вечное… или нет.
- Возможности подключать внешние сервисы
Попробовали на примере Elemental и, например, яблочного упаковщика в HLS подключать внешние сервисы.
- За 2016 год несколько раз (4, 5, 6 – точно не помню) перекодировали полностью каталог.
Это нужно как раз для оптимизации работы CDN, чтобы адаптивный стриминг лучше шурупил. До создания этой системы вопрос перекодирования всего каталога мог занимать от полугода до года. У нас действительно много видео!
Сейчас, я думаю, на тех мощностях, которые есть, можно справиться за полтора-два месяца. Вопрос только: зачем?
При этом совершенно спокойно можно арендовать облачко, главное, чтобы это облачко было где-то недалеко от тебя, потому что как-то к нам пришел Амазон и сказал:
— Смотрите, классическая задача – давайте, поднимете у нас…
— А у вас в России что-то есть?
— Так, чтобы к вам близко, нет.
— Смотрите, у нас два Pb оригиналов. Нам нужно, условно говоря, перегнать их туда, а потом забрать. Сколько мы вам за трафон заплатим?
— Ну, да… В России поднимемся, придем.
По времени, если гонять куда-то далеко, расстояние имеет очень существенное воздействие на выбор партнера, где можно, например, поднять внешние вычислительные мощности.
- QA теперь в принципе умеет тестировать
Действительно, две недели на тестирование и проверку качества любой новой фичи в системе кодирования, которые я описывал раньше, – это адо-содомия. Просто на корню зарубает все желание получать какие-то фичи от этой системы.
А сейчас день-два, если совсем геморрой – три-четыре. Плюс – понятно, как это делать. Тестировщик не занимается инфраструктурными проблемами. Он не ходит вокруг девопсера, не говорит: «Блин, у меня вот то же самое не работает, почему?». Сейчас (по крайней мере, я на это надеюсь) тестировщики перестали бояться брать на себя задачки по контролю качества системы кодирования.
В ответах на вопросы после доклада зачастую содержатся самые интересные фишки и любопытные детали, поэтому мы собрали их тут
под спойлером
— Видео, которое вы гоняете для кодировщиков, и ваш 2 Pb каталог – как вы вообще построили это хранилище, как эти сервера выкачивают это видео – по какому протоколу это происходит?
— Это все HTTP.
— Вы говорите, ваши контейнеры запускаются и по кругу спрашивают – а кого они спрашивают? Сервер очередей стоит?
— Я не стал акцентировать внимание на этом. Там нет ничего сложного. Есть БД, где хранится инфа обо всех запросах. Собственно, контейнер о статусах тоже пишет все в БД.
— Вы кратко упомянули о GPU. Вы делаете кодирование на GPU?
— Смотрите, у нас есть обычные ЦПУ. 95% кодирования осуществляется на них. Есть два сервачка для экспериментов и нестандартного программирования Elemental – там GPU. Каждый год мы делаем новый тендер и смотрим, имеет ли смысл купить.
Дело в том, что один сервак с GPU стоит как шесть обычных серваков. Когда ты ставишь их рядом и просто проверяешь по скорости – да, там по питанию чуть-чуть меньше, это классно. Каждый раз мы считаем, раз в год думаем – может, случилось чудо, и сейчас для наших целей подойдет вот это.
Казалось бы, да, но пока еще нет. Месяц назад мы снова поговорили с Nvidia, вчера они нам прислали на тесты новую железку для того, чтобы посмотреть, как и что. Посмотрим, если действительно будет экономическая целесообразность… То, что GPU классные, – я не спорю. Но мы можем построить примерно ту же скорость, просто распараллелив все это на другие железки.
— Собственный Elemental – это не только система кодирования, но еще и система пакетирования. Вы его используете только для кодирования?
— Да. Только для кодирования.
— То есть пакетирование у вас свое и оно полностью за кадром? И там вы запаковываете в HLS, DASH?
— Единственное, во что мы запаковываем на Elemental, – это HSS.
— И шифрование вы делаете не на уровне пакетирования, а прямо на этапе кодирования?
— На этапе пакетирования. Есть пакетайзер, которому ты скармливаешь, условно говоря, то, что тебе нужно упаковать, и говоришь – там сервер лицензий, там ключи – вперед, сделай мне вот это.
— Тут просто непонятно. Вы говорили про энкодинг, а потом начали говорить про DRM…
— Они связаны между собой.
— Понятно. Вы рассказываете, что вы сэкономили кучу денег на эксплуатации и прочем, но это вам стоило, очевидно, каких-то совершенно безумных сроков разработки. Есть какие-то примерные оценки, сколько стоило разработать саму систему энкодинга и пакетирования?
— Четыре или пять месяцев командой из двух человек.
— Вы говорили, что вы внедрили Kubernetes …
— Мы не внедрили Kubernetes, мы попробовали, и два года назад у нас не получилось.
— Вопрос в том, смотрели ли вы на Mesos + Marathon, который непосредственно про ваш кейс?
— Смотрели. По поводу этого можно отдельно долго говорить. Там были чудовищные проблемы по поводу сетевой связанности, адресации. На Mesos с Marathon мы потратили около двух месяцев и пришли к выводу – да, это классно и замечательно, но можно сделать гораздо проще.
Если говорить про те преимущества, которые дает система оркестрации, для именно продакшн-использования – это классно. Там заявлено, что ты можешь поднять любое количество инстансов и прочее. Но для задач, которые скрыты от пользователей – для внутренней системы бэкофиса – мне кажется, это из пушки по воробьям. Пойдите еще, найдите людей, которые нормально вам сварят Kubernetes.
Поэтому это скорее административное решение.
— В общем, вы сеть не одолели?
— Не полетело у нас, да, были проблемы с сетью — именно с тем, как там сделать сетевую связанность, потому что там все настолько через ж*, что больно.
— Пара админских вопросов. На чем храните два Pb? Как-то бэкапите?
— У нас отдельные большие хранилища, где мы храним именно оригиналы, которые приходят от правообладателей. Их мы используем для последующего перекодирования, если нужно будет перекодировать заново.
А так каждый файл хранится в двух местах, на двух сервачках в разных дата-центрах, они же и являются бэкапами. Здесь аналогия с гитом – там есть бэкапы на CDN, просто резервирование хранения. Если все там забэкапить, ты из нормальных, адекватных по деньгам бэкапов быстро это все не вынешь. Иногда быстрее просто перекодировать.
— И второй вопрос, касающийся логирования. Чем парсите, чем пользуетесь? Логи где храните?
— Kibana.
— Понимаю, что вы держите видео для разных платформ. Вопрос – сколько в итоге копий одного и того же вы храните под разные девайсы?
— В начале презентации была история про 52 формата. Храним из этого меньше потому, что 52 – это самый плохой вариант, когда нужно для всех DRM, на всех платформах. Сейчас мы как раз экспериментируем с генерацией на лету. У нас это уже даже работает на проде. У нас приходит исходник – шесть битрейтов, в идеале мы хотим хранить только эти шесть. Сейчас мы умеем из них на лету нарезать HLS – с кодированием Verimatrix, PlayReady, который никому не нужен. Можем делать из этого DASH.
Но при этом, например, для того же самого WDW мы храним еще и копии, заранее откодированные, потому что тут нужно несколько больше времени на проведение тестов. Не всегда понятно – ты облажался потому, что ты облажался с кэшированием на одном из CDN-узлов, или у тебя просто заглючил DRM.
Поэтому сейчас, наверное, 18.
— Вы несколько раз упоминали, что с сетью были достаточно большие проблемы. А у вас есть отдельные ребята, которые занимаются сетью?
— У нас нет проблем с сетью. У нас прекрасный отдел, который занимается исключительно сетевыми вопросами, сетевой связанностью, подключением различных операторов и прочим. Проблема была в том, чтобы совместить сетевые потребности каждого микросервиса внутри себя, и чтобы еще это все было под управлением какой-то системы оркестрации.
То есть проблема не с тем, как мы настраиваем сеть. Тут наши ребята – боги. Пришла новая технология, незнакомая – Kubernetes, мы начали в ней разбираться и решили попробовать – насколько она для нас применима? Потому что очень хочется минимизировать касты. На тот момент времени пришли к выводу, что не очень применима. Может быть, будем пробовать еще.
— Тогда уточните – есть ребята-админы, программисты, сетевики. А между собой они на каких уровнях взаимодействуют и как это происходит?
— Есть админы, которые любят программистов, есть админы, которые любят админов. В отделе эксплуатации есть несколько человек, которые занимаются исключительно задачами разработки. Они помогают разработчикам, тестировщикам сделать так, чтобы у них там было что-то хорошее.
Например, мы пробуем запустить новую систему генерации проблем сети. По-хорошему, надо оттестить, как работает адаптивный стриминг. Для этого нужна эмуляция проблем в сети. Можно купить железку за несколько тысяч долларов. А можно взять софтверную штуку, пропустить это все через нее и сказать: «ОК, тут у нас будут такие-то дропы пакетов, тут то, тут се». Для этого есть DevOps-инженеры.
Все ребята сидят вместе. Они меняются – кто дежурный, кто нет. Когда приходит новый человек к нам в команду, он сначала ближе к программистам. Чем опытнее он становится, тем ближе подбирается к продакшн.
— У меня вопрос более концептуальный. Ты говорил, что 4К, видео увеличивается и т.д. На QUIK вы смотрели уже, оттестировали, может быть, обсуждали, думали?
— Мы смотрели, но пока еще нет.
Я немножко лукавлю, когда говорю, что мы сильно дешевле, чем классические CDN. Это достигается одной простой штукой. Мы не решаем те задачи, которые нам решать не нужно. Во-первых, у нас нет живого потока, а значит, нам не нужно его на ходу… Мы умышленно в свой CDN пока не делаем именно живой поток. Это другие правила кэширования, другая архитектура.
Умышленно исключая эту задачу, можно использовать более дешевое железо и решать ровно ту задачу, которая тебе нужна, дешевле и эффективнее, чем универсальная машинка, которая умеет все.
— Это все HTTP.
— Вы говорите, ваши контейнеры запускаются и по кругу спрашивают – а кого они спрашивают? Сервер очередей стоит?
— Я не стал акцентировать внимание на этом. Там нет ничего сложного. Есть БД, где хранится инфа обо всех запросах. Собственно, контейнер о статусах тоже пишет все в БД.
— Вы кратко упомянули о GPU. Вы делаете кодирование на GPU?
— Смотрите, у нас есть обычные ЦПУ. 95% кодирования осуществляется на них. Есть два сервачка для экспериментов и нестандартного программирования Elemental – там GPU. Каждый год мы делаем новый тендер и смотрим, имеет ли смысл купить.
Дело в том, что один сервак с GPU стоит как шесть обычных серваков. Когда ты ставишь их рядом и просто проверяешь по скорости – да, там по питанию чуть-чуть меньше, это классно. Каждый раз мы считаем, раз в год думаем – может, случилось чудо, и сейчас для наших целей подойдет вот это.
Казалось бы, да, но пока еще нет. Месяц назад мы снова поговорили с Nvidia, вчера они нам прислали на тесты новую железку для того, чтобы посмотреть, как и что. Посмотрим, если действительно будет экономическая целесообразность… То, что GPU классные, – я не спорю. Но мы можем построить примерно ту же скорость, просто распараллелив все это на другие железки.
— Собственный Elemental – это не только система кодирования, но еще и система пакетирования. Вы его используете только для кодирования?
— Да. Только для кодирования.
— То есть пакетирование у вас свое и оно полностью за кадром? И там вы запаковываете в HLS, DASH?
— Единственное, во что мы запаковываем на Elemental, – это HSS.
— И шифрование вы делаете не на уровне пакетирования, а прямо на этапе кодирования?
— На этапе пакетирования. Есть пакетайзер, которому ты скармливаешь, условно говоря, то, что тебе нужно упаковать, и говоришь – там сервер лицензий, там ключи – вперед, сделай мне вот это.
— Тут просто непонятно. Вы говорили про энкодинг, а потом начали говорить про DRM…
— Они связаны между собой.
— Понятно. Вы рассказываете, что вы сэкономили кучу денег на эксплуатации и прочем, но это вам стоило, очевидно, каких-то совершенно безумных сроков разработки. Есть какие-то примерные оценки, сколько стоило разработать саму систему энкодинга и пакетирования?
— Четыре или пять месяцев командой из двух человек.
— Вы говорили, что вы внедрили Kubernetes …
— Мы не внедрили Kubernetes, мы попробовали, и два года назад у нас не получилось.
— Вопрос в том, смотрели ли вы на Mesos + Marathon, который непосредственно про ваш кейс?
— Смотрели. По поводу этого можно отдельно долго говорить. Там были чудовищные проблемы по поводу сетевой связанности, адресации. На Mesos с Marathon мы потратили около двух месяцев и пришли к выводу – да, это классно и замечательно, но можно сделать гораздо проще.
Если говорить про те преимущества, которые дает система оркестрации, для именно продакшн-использования – это классно. Там заявлено, что ты можешь поднять любое количество инстансов и прочее. Но для задач, которые скрыты от пользователей – для внутренней системы бэкофиса – мне кажется, это из пушки по воробьям. Пойдите еще, найдите людей, которые нормально вам сварят Kubernetes.
Поэтому это скорее административное решение.
— В общем, вы сеть не одолели?
— Не полетело у нас, да, были проблемы с сетью — именно с тем, как там сделать сетевую связанность, потому что там все настолько через ж*, что больно.
— Пара админских вопросов. На чем храните два Pb? Как-то бэкапите?
— У нас отдельные большие хранилища, где мы храним именно оригиналы, которые приходят от правообладателей. Их мы используем для последующего перекодирования, если нужно будет перекодировать заново.
А так каждый файл хранится в двух местах, на двух сервачках в разных дата-центрах, они же и являются бэкапами. Здесь аналогия с гитом – там есть бэкапы на CDN, просто резервирование хранения. Если все там забэкапить, ты из нормальных, адекватных по деньгам бэкапов быстро это все не вынешь. Иногда быстрее просто перекодировать.
— И второй вопрос, касающийся логирования. Чем парсите, чем пользуетесь? Логи где храните?
— Kibana.
— Понимаю, что вы держите видео для разных платформ. Вопрос – сколько в итоге копий одного и того же вы храните под разные девайсы?
— В начале презентации была история про 52 формата. Храним из этого меньше потому, что 52 – это самый плохой вариант, когда нужно для всех DRM, на всех платформах. Сейчас мы как раз экспериментируем с генерацией на лету. У нас это уже даже работает на проде. У нас приходит исходник – шесть битрейтов, в идеале мы хотим хранить только эти шесть. Сейчас мы умеем из них на лету нарезать HLS – с кодированием Verimatrix, PlayReady, который никому не нужен. Можем делать из этого DASH.
Но при этом, например, для того же самого WDW мы храним еще и копии, заранее откодированные, потому что тут нужно несколько больше времени на проведение тестов. Не всегда понятно – ты облажался потому, что ты облажался с кэшированием на одном из CDN-узлов, или у тебя просто заглючил DRM.
Поэтому сейчас, наверное, 18.
— Вы несколько раз упоминали, что с сетью были достаточно большие проблемы. А у вас есть отдельные ребята, которые занимаются сетью?
— У нас нет проблем с сетью. У нас прекрасный отдел, который занимается исключительно сетевыми вопросами, сетевой связанностью, подключением различных операторов и прочим. Проблема была в том, чтобы совместить сетевые потребности каждого микросервиса внутри себя, и чтобы еще это все было под управлением какой-то системы оркестрации.
То есть проблема не с тем, как мы настраиваем сеть. Тут наши ребята – боги. Пришла новая технология, незнакомая – Kubernetes, мы начали в ней разбираться и решили попробовать – насколько она для нас применима? Потому что очень хочется минимизировать касты. На тот момент времени пришли к выводу, что не очень применима. Может быть, будем пробовать еще.
— Тогда уточните – есть ребята-админы, программисты, сетевики. А между собой они на каких уровнях взаимодействуют и как это происходит?
— Есть админы, которые любят программистов, есть админы, которые любят админов. В отделе эксплуатации есть несколько человек, которые занимаются исключительно задачами разработки. Они помогают разработчикам, тестировщикам сделать так, чтобы у них там было что-то хорошее.
Например, мы пробуем запустить новую систему генерации проблем сети. По-хорошему, надо оттестить, как работает адаптивный стриминг. Для этого нужна эмуляция проблем в сети. Можно купить железку за несколько тысяч долларов. А можно взять софтверную штуку, пропустить это все через нее и сказать: «ОК, тут у нас будут такие-то дропы пакетов, тут то, тут се». Для этого есть DevOps-инженеры.
Все ребята сидят вместе. Они меняются – кто дежурный, кто нет. Когда приходит новый человек к нам в команду, он сначала ближе к программистам. Чем опытнее он становится, тем ближе подбирается к продакшн.
— У меня вопрос более концептуальный. Ты говорил, что 4К, видео увеличивается и т.д. На QUIK вы смотрели уже, оттестировали, может быть, обсуждали, думали?
— Мы смотрели, но пока еще нет.
Я немножко лукавлю, когда говорю, что мы сильно дешевле, чем классические CDN. Это достигается одной простой штукой. Мы не решаем те задачи, которые нам решать не нужно. Во-первых, у нас нет живого потока, а значит, нам не нужно его на ходу… Мы умышленно в свой CDN пока не делаем именно живой поток. Это другие правила кэширования, другая архитектура.
Умышленно исключая эту задачу, можно использовать более дешевое железо и решать ровно ту задачу, которая тебе нужна, дешевле и эффективнее, чем универсальная машинка, которая умеет все.
Также мы открыли доступ ко всем видеозаписям выступлений с Backend Conf 2017 и HighLoad++ Junior.
Экспертов и профессионалов мы приглашаем стать спикерами на майском фестивале конференций РИТ++. Если у вас есть интересный опыт разработки и вы готовы им поделиться, оставьте заявку для нашего программного комитета.
