
Всем привет! В предыдущих двух статьях мы подробно рассмотрели технические и методологические аспекты A/B-тестирования в Ozon. А сейчас время перейти к не менее интересным темам. Так как наша команда занимается не только A/B-тестами, но и в целом развитием методов принятия решений с помощью causal inference, стоит уделить внимание многоруким бандитам.
В этой статье мы рассмотрим методологию и границы применимости классических многоруких и контекстуальных бандитов, а также реализуем контекстного бандита, в основе которого будут сэмплирование Томпсона и нейронная сеть. Ну и, конечно, мы постараемся ответить на главный вопрос: могут ли многорукие бандиты заменить A/B-тесты?

Для более четкого понимания предлагаем читателям предварительно ознакомится с глоссарием, где описаны ключевые термины, связанные с бандитами.
Глоссарий
Вариант (стратегия, action, arm) - аналог группы в A/B-тесте. Какое-то изменение, которое вы хотите сравнить с текущей реализацией или чем-либо еще.
Награда (целевая метрика, reward) - значение метрики, которое получено от использования того или иного варианта.
Убыток (regret) - потери в награде от использования того или иного варианта.
Среда - совокупность некоторых условий и отношений, которая формирует определенные закономерности поведения субъектов среды (например: рынок маркетплейсов).
Контекст (факторы) - определенные параметры, характеризующие субъекта среды (пол, возраст, страна).
Код к статье можете посмотреть тут.
Прежде чем перейти к описанию сути многоруких бандитов, давайте вспомним, как проводится A/B-тест. Для определения лучшего варианта мы формируем несколько статичных групп и оцениваем статистическую значимость наблюдаемых изменений через определённый промежуток времени. Из этого краткого описания процесса уже можно понять ключевой недостаток A/B-тестов: часть трафика значительное время может идти на исследование неэффективных вариантов решения, что приводит к росту убытков. Таким образом, возникает дилемма: A/B-тестирование, с одной стороны, позволяет за счёт методологии держаться в рамках заданных уровней ошибок I и II рода, тем самым обеспечивая среднестатистическое принятие верных решений, а с другой стороны, требует больших затрат, связанных с исследованием неэффективных решений, которые могут негативно повлиять на пользователей.
Здесь и выходят на сцену многорукие бандиты — алгоритмы, позволяющие ускорить выбор стратегий с наибольшим потенциальным приростом целевой метрики. Данные алгоритмы направлены на решение вышеупомянутой дилеммы: exploration / exploitation tradeoff. В процессе эксперимента мы не только исследуем наши варианты, но и стараемся как можно раньше начать использовать лучшие из них.

Многорукий бандит — это алгоритм принятия решений, суть которого заключается в обеспечении баланса между исследованием и использованием какого-то из рассматриваемых вариантов решения с целью максимизации целевой метрики и минимизации убытков.
Многоруких бандитов можно разделить на два типа — в зависимости от того, какую задачу они призваны решить:
Классические многорукие бандиты (MAB). Это алгоритмы для выбора одного самого эффективного варианта с максимальной потенциальной наградой. Это самый распространённый тип многоруких бандитов, к нему относятся широко известные классические реализации MAB: epsilon-greedy, UCB, Thompson sampling. Алгоритмы MAB не способны улавливать контекстные особенности среды, в которой работают, — они лишь перераспределяют трафик на варианты, где среднестатистически наблюдается наибольшее среднее значение целевой метрики.
Контекстные бандиты (CMAB). Это алгоритмы, направленные на оптимизацию награды в зависимости от контекста среды, в которой они работают. Суть их работы можно описать так: существует некоторая среда, в которой есть определённые закономерности; перед CMAB стоит задача подобрать для субъектов среды такие варианты, которые бы максимизировали награду исходя из этих закономерностей. Наиболее известные алгоритмы CMAB являются по своей сути комбинацией epsilon-greedy, UCB, Thompson sampling и линейной регрессии: linear epsilon-greedy, UCB, TS. В этой статье мы подробно рассмотрим два алгоритма CMAB: linear TS и neural linear TS.
У алгоритмов MAB и CMAB есть границы применимости. Сразу обозначу: они не являются полноценной заменой A/B-тестирования, у них есть определённая ниша, в которой их применение считается наиболее подходящим. Для CMAB — это задачи, связанные с персонализацией: рекомендательные системы, оптимизация промо, динамическое ценообразование, контекстная реклама и т. д. Для MAB это задачи, где необходимо выбрать одно решение, но проведение A/B-теста затруднено. Например, запускается новый продукт, для которого нельзя на историческом периоде сделать дизайн для запуска полноценного A/B-теста, или необходимо протестировать разные варианты рекламных баннеров, но выборка для принятия решения с помощью эксперимента крайне мала. В остальных случаях лучше придерживаться процесса тестирования новых фич с использованием A/B-тестирования.
Ниже представлена таблица сравнения MAB и CMAB по ряду признаков, однако часть из них следует раскрыть.
Оба типа многоруких бандитов могут оптимизировать лишь одну метрику, поэтому она должна полноценно отражать суть решаемой задачи. Например, если вы хотите повысить маржинальность продаж, нужно выбрать маржу в качестве метрики, а если цель — увеличить CTR, то очевидно, что следует выбрать в качестве метрики конверсию в клик.
CMAB и MAB могут приспосабливаться (меняя выигрышный вариант) к изменениям условий среды, которую они исследуют, однако делают они это по-разному. Если для CMAB это вообще основа работы, то с MAB дело обстоит сложнее: часть алгоритма, ответственная за исследование, может заметить изменение лучшего варианта в определённый момент времени либо проигнорировать этот факт вследствие полного перехода в использование уже выбранного варианта. Последнее часто происходит, если на раннем этапе работы MAB среди вариантов был явный лидер. Это особенно характерно для UCB. Чтобы предотвратить подобную ситуацию и сделать алгоритм MAB чувствительным к изменениям среды, следует предусмотреть возможность переключения раундов с полным обновлением весов MAB либо использовать реализации алгоритма, в которых предусмотрено ручное включение случайного выбора ручек для обновления знаний о вариантах-аутсайдерах в текущем раунде бандита.
Таблица сравнения MAB и CMAB
Признак | MAB | CMAB |
Может оптимизировать только одну метрику | + | + |
Не требует статистических предпосылок для принятия решений | + | + |
Может выбирать несколько вариантов в зависимости от контекста | - | + |
Способен оптимизировать сложные зависимости | - | + |
Способен приспосабливаться к новым условиям среды | +/- | + |
Выделим преимущества и недостатки MAB и CMAB.
Преимущества:
гибкость исследования и возможность перераспределять трафик между худшими и лучшими вариантами для минимизации убытков;
возможность решить задачу, когда A/B-тест применять нецелесообразно;
возможность персонализированно выбирать лучший вариант (CMAB).
Недостатки:
отсутствие статистических предпосылок для фиксации уровней ошибок I и II рода;
мощность MAB может быть ниже, чем у A/B-теста, особенно если разница между вариантами очень мала.

Теоретическая основа MAB и CMAB
Переходим к описанию алгоритмов MAB и CMAB. Для MAB я дам краткое описание и не буду долго на них останавливаться, так как про многоруких бандитов в их классическом варианте написано слишком много. Большая часть этого раздела будет посвящена устройству CMAB.
Основными алгоритмами классических многоруких бандитов являются:
ε-greedy;
UCB (upper confidence bound);
Thompson sampling.
Суть алгоритма ε-greedy очень проста: выбираем стратегию с максимальной средней наградой (средним значением метрики, которую мы оптимизируем) и иногда с определённой заранее вероятностью выбираем случайную стратегию для исследования.
UCB, в отличие от ε-greedy, проводит своё исследование не случайно, а на основе растущей со временем неопределённости у стратегий. В начале работы алгоритм случайно задействует все стратегии, после чего рассчитывается средняя награда каждой. Далее выбор стратегии происходит следующим образом:
После каждой итерации обновляются средние награды стратегий.
С течением времени чем реже выбиралась та или иная стратегия, тем больше будет у неё неопределённость.
Окончательный выбор стратегии — это максимальная сумма средней награды и неопределённости среди всех стратегий.
Если представить алгоритм в математическом виде, то получится следующее выражение:
![A_{t} = argmax\left[Q_{t}(a)+c\sqrt{\frac{\ln{t}}{N_{t}(a)}}\right]](https://habrastorage.org/getpro/habr/upload_files/82f/699/581/82f699581477b4da4cb41c830b0fb836.svg)
где:
Qt(a) — среднее значение награды стратегии a;
t — общее количество наблюдений;
Nt(a) — количество раз, когда была выбрана стратегия a;
c — коэффициент бустинга исследования. Чем он больше, тем больше алгоритм направлен на исследование. (Вообще этот коэффициент может быть как статичным, так и динамичным. Так как награда может меняться со временем, лучше сделать его зависимым от её значения.)
Thompson sampling — самый сложный алгоритм MAB. Он основан на байесовском подходе, поэтому с ним неразрывно связано два термина:
Априорное распределение - распределение, которое выражает предположения до учета экспериментальных данных.
Апостериорное распределение - распределение, которое получено после учёта экспериментальных данных.
У каждого варианта перед запуском бандита есть априорное распределение его награды, которое по мере поступления новых данных становится апостериорным. Сэмплирование Томпсона берет рандомные значения из этих распределений, сравнивает их и выбирает вариант с максимальным значением.

Давайте рассмотрим реализацию Thompson sampling для биномиальной метрики. В качестве априорного распределения возьмём бета-распределение с параметрами α и β:

где α_k и β_k являются по своей сути кумулятивной суммой количества удачных и неудачных исходов:


Выбор стратегии в данном случае — максимальное значение theta, полученное из апостериорных распределений наших стратегий.
Следует отметить, что все эти классические алгоритмы можно и нужно улучшать и комбинировать по своему усмотрению. Например, можно скомбинировать UCB и ε-greedy для добавления случайного переключения в алгоритм UCB, причём можно это реализовать не просто как единоразовое случайное переключение, а как период, в течение которого алгоритм рандомно распределяет трафик, а после снова возвращается к своему первоначальному функционированию. Также есть возможность добавить в уравнение UCB новый член QBC, который будет отвечать за «несогласие в комитете». Принцип работы UCB + QBC прост: теперь за определение лучшей стратегии отвечают не только среднее значение метрики и неопределённость, но и, например, дисперсия метрики этой стратегии или разность между максимальным и минимальным значением награды. Таким образом, тюнинг классических алгоритмов может улучшить их перформанс на ваших данных и принести больше пользы в эксплуатации.
А теперь — самое интересное: CMAB. Как уже было сказано, контекстный бандит максимизирует награду, основываясь на контексте, на факторах, которые объясняют возможную реакцию субъекта на то или иное воздействие. Чтобы учесть контекст, нужна модель, которая умеет делать предикты награды в зависимости от различных факторов. Идеальным кандидатом на роль такой модели является байесовская линейная регрессия, у которой каждый коэффициент перед фактором X имеет свое априорное распределение; а где есть априорное распределение, есть и сэмплирование Томпсона. Подробнее про байесовскую линейную регрессию можно почитать в этой статье, а мы перейдём к описанию процесса работы алгоритма linear TS:
Определить для каждого фактора модели байесовской линейной регрессии априорное распределение: Prior(mu, std), где mu = 0, std = 1 (или любые другие значения, которые вы посчитаете подходящими).
Определить функцию для сэмплирования Томпсона:

Вариант выбирается следующим образом: для каждого варианта, для каждого параметра модели рандомно сэмплируются значения βk из априорного распределения и умножаются на Xk. Полученные значения предикта далее сравниваются между вариантами — и выбирается максимальное значение.
Запустить первую итерацию контекстного бандита и собрать первый батч данных (в первой итерации выбор из априорного распределения идентичен рандомному сэмплированию):

На данных первого батча обучить байесовскую линейную регрессию для каждого из предоставленных вариантов. Сохранить параметры полученного апостериорного распределения (среднее и стандартное отклонения):

Используя новое апостериорное распределение, сделать предикт для выбора лучшего варианта:

Повторить пункты 5 и 6 для новых батчей данных n раз.
Контекстный бандит linear TS готов! Однако проблема в том, что он линейный, то есть будет довольно плохо оптимизировать нелинейные связи, которых на практике подавляющее большинство. Решение данной проблемы описали в статье Deep Bayesian Bandits Showdown. Для улучшения интерпретации нелинейных связей между таргетом и факторами необходимо реализовать многоуровневый алгоритм neural linear TS, который состоит из двух моделей: нейронной сети и линейной байесовской регрессии.
Вместо того чтобы напрямую передавать наши фичи в линейную регрессию, как мы это делали в случае с линейным бандитом, мы сначала обучим на этих фичах нейронную сеть и потом возьмём аутпуты из её последнего скрытого слоя в качестве новых фич, которые в свою очередь будут использованы для обучения линейной регрессии. Эти новые фичи, по сути, являются репрезентацией наших исходных факторов, которые призваны облегчить линейной модели оптимизацию нелинейных зависимостей. Данный алгоритм действий представлен в виде схемы на рисунке далее.

В качестве нейронной сети можно использовать как простую нейронную сеть с несколькими линейными слоями и с функцией активации, как в оригинальной статье, так и более сложные модели, например трансформеры. Однако не стоит забывать о производительности решения: модель должна обучаться в разумный срок и делать быстрые предикты.
Остаётся открытым вопрос о количестве новых фич, сгенерированных нейронной сетью. Это необходимо будет решить уже на этапе валидации модели.
В общем виде принцип работы алгоритма neural linear TS можно изобразить в виде такой схемы:

Практическое применение и валидация CMAB
Для реализации контекстных бандитов воспользуемся библиотекой для вероятностного программирования PyMC. Так как мы не можем знать, какое априорное распределение у β-параметров нашей модели, возьмём нормальное распределение со средним 0 и стандартным отклонением 1.
Реализуем функцию для определения априорного распределения для параметров модели. В неё нужно передать количество вариантов и количество фич модели:
def get_priors(arms, n_features):
posteriors = {}
for arm in arms:
m = np.zeros(n_features)
s = np.ones(n_features)
posteriors[arm] = [m, s]
return posteriorsРеализуем функцию для сэмплирования Томпсона (функцию BestAction из теоретической части). В неё нужно передать словарь с первоначальным априорным или уже апостериорным распределением, вектор с контекстом, вектор с вариантами и значение α — параметра, который влияет на exploration / exploitation tradeoff. Чем меньше α, тем меньше дисперсия у распределения β и тем больше exploitation.
def select_arm_thompson(posteriors, context, arms, alpha = 1):
samples = {}
context = np.insert(context, 0, 1)
for arm in arms:
m = posteriors[arm][0][:-1]
s = posteriors[arm][1][:-1]* alpha
w = np.random.normal(m, s)
sample_prediction = np.dot(w, context)
samples[arm] = sample_prediction
max_value = max(samples.values());
max_keys = [key for key, value in samples.items() if value == max_value]
return np.random.choice(max_keys)Последнее, что нам нужно, — это сама модель. В PyMC есть хороший API Bambi (BAyesian Model-Building Interface), с помощью которого можно легко построить нужную нам модель и задать априорное распределение для параметров.
В качестве среды симуляции используем toy problem из библиотеки Space Bandits (SB). Toy problem — это симуляция промоакции, где есть несколько групп пользователей, о которых известны их ARPU за какой-то период и возраст. Каждый пользователь по-разному реагирует на возможные варианты промо, соответственно, задачи — максимизировать выручку от промоакции и уменьшить издержки.
В Space Bandits реализованы linear TS и neural linear TS. Сравним наши реализации с реализациями алгоритмов из SB. Также для большей наглядности добавим рандомный выбор и UCB. Код симуляции вы можете найти тут.
Награда в toy problem измеряется в условных единицах прибыли, которые заложены в функции get_rewards. Так как мы всегда можем определить наибольшую награду для пользователя, то в результате симуляции мы можем оценить общую награду и общий убыток для каждого из алгоритмов и сравнить их эффективность. Награда будет нелинейно зависеть от фич пользователя.
Для каждого алгоритма итеративно генерируются 5000 пользователей, через каждые 500 пользователей происходит обучение модели на батче этих пользователей (кроме Random и UCB).
Рассмотрим полученные результаты симуляции. Neural linear TS выбил лучший скор как по награде, так и по убытку, что мы и должны были наблюдать, так как связь между целевой метрикой и факторами ARPU и AGE — нелинейная. Причём наша реализация с помощью PyMC близка по эффективности к реализации с помощью SB. Далее по эффективности идёт linear TS, и мы видим, что SB и PyMC также близки по результатам. Худшие скоры показали UCB и Random, что очевидно.
Эффективность алгоритмов в среде симуляции
Алгоритм | Кумулятивный reward | Кумулятивный regret |
Random | 32 980 | 44 885 |
UCB | 43 855 | 32 815 |
SB linear TS | 65 700 | 13 160 |
SB neural linear TS | 71 355 | 7 850 |
PyMC linear TS | 64 910 | 13 500 |
PyMC neural linear TS | 69 565 | 6 870 |
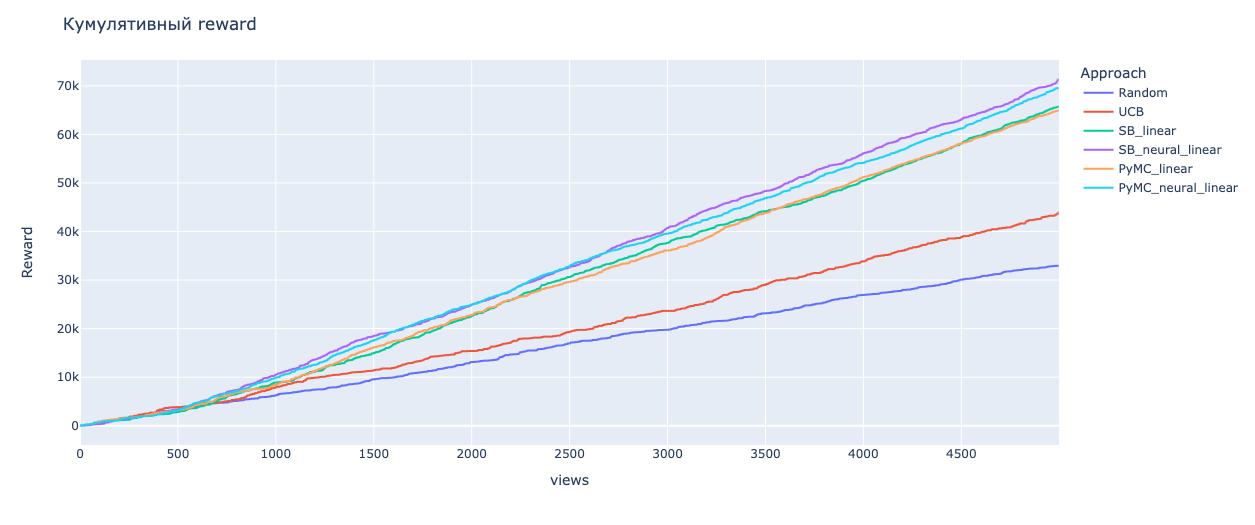

Мы доказали, что алгоритмы CMAB способны максимизировать reward и минимизировать regret. Теперь поговорим немного о выкатке алгоритмов MAB и CMAB в прод. Прежде чем запускать любой из них в продакшен, необходимо сделать две вещи:
Провести симуляцию, как это сделали мы в toy problem, но на реальных данных. С MAB это не вызывает проблем — процесс похож на симуляцию A/B-тестирования, но с CMAB придётся немного напрячься. Необходимо построить функциональную зависимость между целевой метрикой и факторами пользователя, а также разделить пользователей по паттернам поведения. Тогда вы сможете приблизительно оценить, как будет работать CMAB на реальных данных.
Подготовить A/B-тест для контроля за эффективностью работы бандита. Без эксперимента не стоит запускать бандита, так как в таком случае вы просто лишитесь возможности оценить эффективность алгоритма.
Поздравляю, теперь вы можете делать своих контекстуальных бандитов.
Вывод
Мы разобрали работу многоруких бандитов — метода, который призван решать задачи там, где A/B-тесты нецелесообразно или невозможно применять. Теперь вы можете без проблем использовать как классические алгоритмы MAB, так и алгоритмы CMAB для своих данных и делать необходимые выводы. Искренне надеемся, что вам понравилась статья. По всем вопросам пишите в комментарии или в личку автору.
