Last time we talked about data consistency, looked at the difference between levels of transaction isolation from the point of view of the user and figured out why this is important to know. Now we are starting to explore how PostgreSQL implements snapshot isolation and multiversion concurrency.
In this article, we will look at how data is physically laid out in files and pages. This takes us away from discussing isolation, but such a digression is necessary to understand what follows. We will need to figure out how the data storage is organized at a low level.
If you look inside tables and indexes, it turns out that they are organized in a similar way. Both are database objects that contain some data consisting of rows.
There is no doubt that a table consists of rows, but this is less obvious for an index. However, imagine a B-tree: it consists of nodes that contain indexed values and references to other nodes or table rows. It's these nodes that can be considered index rows, and in fact, they are.
Actually, a few more objects are organized in a similar way: sequences (essentially single-row tables) and materialized views (essentially, tables that remember the query). And there are also regular views, which do not store data themselves, but are in all other senses similar to tables.
All these objects in PostgreSQL are called the common word relation. This word is extremely improper because it is a term from the relational theory. You can draw a parallel between a relation and a table (view), but certainly not between a relation and an index. But it just so happened: the academic origin of PostgreSQL manifests itself. It seems to me that it's tables and views that were called so first, and the rest swelled over time.
To be simpler, we will further discuss tables and indexes, but the other relations are organized exactly the same way.
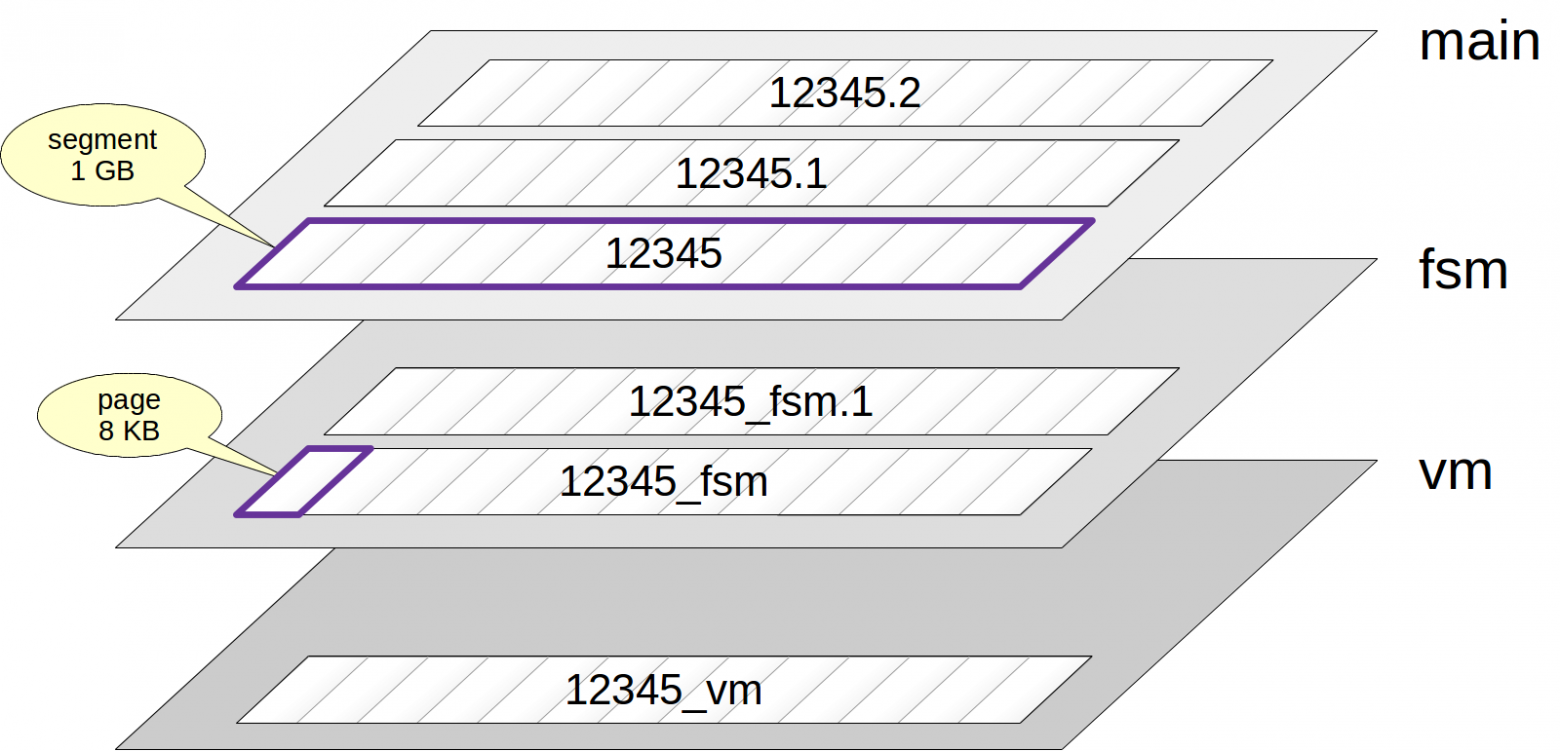
Usually several forks correspond to each relation. Forks can have several types, and each of them contains a certain kind of data.
If there is a fork, it is first represented by the only file. The filename is a numeric identifier, which can be appended by an ending that corresponds to the fork name.
The file gradually grows and when its size reaches 1 GB, a new file of the same fork is created (files like these are sometimes called segments). The ordinal number of the segment is appended at the end of the filename.
The 1 GB limitation of the file size arose historically to support different file systems, some of which cannot deal with files of a larger size. You can change this limitation when building PostgreSQL (
So, several files on disk can correspond to one relation. For example, for a small table there will be three of them.
All files of objects that belong to one tablespace and one database will be stored in one directory. You need to have this in mind since filesystems usually fail to work fine with a large number of files in a directory.
Note here that files, in turn, are divided into pages (or blocks), usually by 8 KB. We will discuss the internal structure of pages a bit further.
Now let's look at fork types.
The main fork is the data itself: the very table and index rows. The main fork is available for any relations (except views that do not contain data).
The names of files of the main fork consist of the only numeric identifier. For example, this is the path to the table that we created last time:
Where do these identifiers arise from? The «base» directory corresponds to the «pg_default» tablespace. Next subdirectory, corresponding to the database, is where the file of interest is located:
The path is relative, it is specified starting from the data directory (PGDATA). Moreover, virtually all paths in PostgreSQL are specified starting from PGDATA. Thanks to this, you can safely move PGDATA to a different location — nothing confines it (except for it might be required to set the path to libraries in LD_LIBRARY_PATH).
Further, looking into the filesystem:
The initialization fork is only available for unlogged tables (created with UNLOGGED specified) and their indexes. Objects like these are no way different from regular objects except that operations with them are not logged in the write-ahead log (WAL). Because of this, it is faster to work with them, but it is impossible to recover the data in the consistent state in case of a failure. Therefore, during a recovery PostgreSQL just removes all the forks of such objects and writes the initialization fork in place of the main fork. This results in an empty object. We will discuss logging in detail, but in another series.
The «accounts» table is logged, and therefore, it does not have an initialization fork. But to experiment, we can turn logging off:
The example clarifies that a possibility to turn logging on and off on the fly is associated with rewriting the data to files with different names.
An initialization fork has the same name as the main fork, but with the "_init" suffix:
The free space map is a fork that keeps track of the availability of free space inside pages. This space is constantly changing: it decreases when new versions of rows are added and increases during vacuuming. The free space map is used during insertion of new row versions in order to quickly find a suitable page, where the data to be added will fit.
The name of the free space map has the "_fsm" suffix. But this file appears not immediately, but only as the need arises. The easiest way to achieve this is to vacuum a table (we will explain why when the time comes):
The visibility map is a fork where pages that only contain up-to-date row versions are marked by one bit. Roughly, it means that when a transaction tries to read a row from such a page, the row can be shown without checking its visibility. In next articles, we will discuss in detail how this happens.
As already mentioned, files are logically divided into pages.
A page usually has the size of 8 KB. The size can be changed within certain limits (16 KB or 32 KB), but only during the build (
Regardless of the fork where files belong, the server uses them in a pretty similar way. Pages are first read into the buffer cache, where the processes can read and change them; then as the need arises, they are evicted back to disk.
Each page has internal partitioning and in general contains the following partitions:
You can easily get to know the sizes of these partitions using the «research» extension pageinspect:
Here we are looking at the header of the very first (zero) page of the table. In addition to the sizes of other areas, the header has different information about the page, which we are not interested in yet.
At the bottom of the page there is the special space, which is empty in this case. It is only used for indexes, and even not for all of them. «At the bottom» here reflects what is in the picture; it may be more accurate to say «in high addresses».
After the special space, row versions are located, that is, that very data that we store in the table plus some internal information.
At the top of a page, right after the header, there is the table of contents: the array of pointers to row versions available in the page.
Free space can be left between row versions and pointers (this free space is kept track of in the free space map). Note that there is no memory fragmentation inside a page — all the free space is represented by one contiguous area.
Why are the pointers to row versions needed? The thing is that index rows must somehow reference row versions in the table. It's clear that the reference must contain the file number, the number of the page in the file and some indication of the row version. We could use the offset from the beginning of the page as the indicator, but it is inconvenient. We would be unable to move a row version inside the page since it would break available references. And this would result in the fragmentation of the space inside pages and other troublesome consequences. Therefore, the index references the pointer number, and the pointer references the current location of the row version in the page. And this is indirect addressing.
Each pointer occupies exactly four bytes and contains:
The data format on disk is exactly the same as the data representation in RAM. The page is read into the buffer cache «as is», without whatever conversions. Therefore, data files from one platform turn out incompatible with other platforms.
For example, in the X86 architecture, the byte ordering is from least significant to most significant bytes (little-endian), z/Architecture uses the inverse order (big-endian), and in ARM the order can be swapped.
Many architectures provide for data alignment on boundaries of machine words. For example, on a 32-bit x86 system, integer numbers (type «integer», which occupies 4 bytes) will be aligned on a boundary of 4-byte words, the same way as double-precision numbers (type «double precision», which occupies 8 bytes). And on a 64-bit system, double-precision numbers will be aligned on a boundary of 8-byte words. This is one more incompatibility reason.
Because of the alignment, the size of the table row depends on the field order. Usually this effect is not very noticeable, but sometimes, it may result in a considerable growth of the size. For example, if fields of types «char(1)» and «integer» are interleaved, usually 3 bytes between them go to waste. For more details of this, you can look into Nikolay Shaplov's presentation "Tuple internals".
We will discuss details of the internal structure of row versions next time. At this point, it is only important for us to know that each version must entirely fit one page: PostgreSQL has no way to «extend» the row to the next page. The Oversized Attributes Storage Technique (TOAST) is used instead. The name itself hints that a row can be sliced into toasts.
Joking apart, TOAST implies several strategies. We can transmit long attribute values to a separate internal table after breaking them up into small toast chunks. Another option is to compress a value so that the row version does fit a regular page. And we can do both: first compress and then break up and transmit.
For each primary table, a separate TOAST table can be created if needed, one for all attributes (along with an index on it). The availability of potentially long attributes determines this need. For example, if a table has a column of type «numeric» or «text», the TOAST table will be immediately created even if long values won't be used.
Since a TOAST table is essentially a regular table, it has the same set of forks. And this doubles the number of files that correspond to a table.
The initial strategies are defined by the column data types. You can look at them using the
The names of the strategies mean:
In general, the algorithm is as follows. PostgreSQL aims to have at least four rows fit one page. Therefore, if the row size exceeds one forth of the page, the header taken into account (2040 bytes for a regular 8K-page), TOAST must be applied to a part of the values. We follow the order described below and stop as soon as the row no longer exceeds the threshold:
Sometimes it may be useful to change the strategy for certain columns. For example, if it is known in advance that the data in a column cannot be compressed, we can set the «external» strategy for it, which enables us to save time by avoiding useless compression attempts. This is done as follows:
Re-running the query, we get:
TOAST tables and indexes are located in the separate pg_toast schema and are, therefore, usually not visible. For temporary tables, the «pg_toast_temp_N» schema is used similarly to the usual «pg_temp_N».
Of course, if you like nobody will hinder your spying upon the internal mechanics of the process. Say, in the «accounts» table there are three potentially long attributes, and therefore, there must be a TOAST table. Here it is:
It's reasonable that the «plain» strategy is applied to the toasts into which the row is sliced: there is no second-level TOAST.
PostgreSQL hides the index better, but it is not difficult to find either:
The «client» column uses the «extended» strategy: its values will be compressed. Let's check:
There is nothing in the TOAST table: repeating characters are compressed fine and after compression the value fits a usual table page.
And now let the client name consist of random characters:
Such a sequence cannot be compressed, and it gets into the TOAST table:
We can see that the data are broken up into 2000-byte chunks.
When a long value is accessed, PostgreSQL automatically and transparently for the application restores the original value and returns it to the client.
Certainly, it is pretty resource-intensive to compress and break up and then to restore. Therefore, to store massive data in PostgreSQL is not the best idea, especially if they are frequently used and the usage does not require transactional logic (for example: scans of original accounting documents). A more beneficial alternative is to store such data on a file system with the filenames stored in the DBMS.
The TOAST table is only used to access a long value. Besides, its own mutiversion concurrency is supported for a TOAST table: unless a data update touches a long value, a new row version will reference the same value in the TOAST table, and this saves space.
Note that TOAST only works for tables, but not for indexes. This imposes a limitation on the size of keys to be indexed.
Read on.
In this article, we will look at how data is physically laid out in files and pages. This takes us away from discussing isolation, but such a digression is necessary to understand what follows. We will need to figure out how the data storage is organized at a low level.
Relations
If you look inside tables and indexes, it turns out that they are organized in a similar way. Both are database objects that contain some data consisting of rows.
There is no doubt that a table consists of rows, but this is less obvious for an index. However, imagine a B-tree: it consists of nodes that contain indexed values and references to other nodes or table rows. It's these nodes that can be considered index rows, and in fact, they are.
Actually, a few more objects are organized in a similar way: sequences (essentially single-row tables) and materialized views (essentially, tables that remember the query). And there are also regular views, which do not store data themselves, but are in all other senses similar to tables.
All these objects in PostgreSQL are called the common word relation. This word is extremely improper because it is a term from the relational theory. You can draw a parallel between a relation and a table (view), but certainly not between a relation and an index. But it just so happened: the academic origin of PostgreSQL manifests itself. It seems to me that it's tables and views that were called so first, and the rest swelled over time.
To be simpler, we will further discuss tables and indexes, but the other relations are organized exactly the same way.
Forks and files
Usually several forks correspond to each relation. Forks can have several types, and each of them contains a certain kind of data.
If there is a fork, it is first represented by the only file. The filename is a numeric identifier, which can be appended by an ending that corresponds to the fork name.
The file gradually grows and when its size reaches 1 GB, a new file of the same fork is created (files like these are sometimes called segments). The ordinal number of the segment is appended at the end of the filename.
The 1 GB limitation of the file size arose historically to support different file systems, some of which cannot deal with files of a larger size. You can change this limitation when building PostgreSQL (
./configure --with-segsize). So, several files on disk can correspond to one relation. For example, for a small table there will be three of them.
All files of objects that belong to one tablespace and one database will be stored in one directory. You need to have this in mind since filesystems usually fail to work fine with a large number of files in a directory.
Note here that files, in turn, are divided into pages (or blocks), usually by 8 KB. We will discuss the internal structure of pages a bit further.
Now let's look at fork types.
The main fork is the data itself: the very table and index rows. The main fork is available for any relations (except views that do not contain data).
The names of files of the main fork consist of the only numeric identifier. For example, this is the path to the table that we created last time:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
Where do these identifiers arise from? The «base» directory corresponds to the «pg_default» tablespace. Next subdirectory, corresponding to the database, is where the file of interest is located:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
The path is relative, it is specified starting from the data directory (PGDATA). Moreover, virtually all paths in PostgreSQL are specified starting from PGDATA. Thanks to this, you can safely move PGDATA to a different location — nothing confines it (except for it might be required to set the path to libraries in LD_LIBRARY_PATH).
Further, looking into the filesystem:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
The initialization fork is only available for unlogged tables (created with UNLOGGED specified) and their indexes. Objects like these are no way different from regular objects except that operations with them are not logged in the write-ahead log (WAL). Because of this, it is faster to work with them, but it is impossible to recover the data in the consistent state in case of a failure. Therefore, during a recovery PostgreSQL just removes all the forks of such objects and writes the initialization fork in place of the main fork. This results in an empty object. We will discuss logging in detail, but in another series.
The «accounts» table is logged, and therefore, it does not have an initialization fork. But to experiment, we can turn logging off:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
The example clarifies that a possibility to turn logging on and off on the fly is associated with rewriting the data to files with different names.
An initialization fork has the same name as the main fork, but with the "_init" suffix:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
The free space map is a fork that keeps track of the availability of free space inside pages. This space is constantly changing: it decreases when new versions of rows are added and increases during vacuuming. The free space map is used during insertion of new row versions in order to quickly find a suitable page, where the data to be added will fit.
The name of the free space map has the "_fsm" suffix. But this file appears not immediately, but only as the need arises. The easiest way to achieve this is to vacuum a table (we will explain why when the time comes):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
The visibility map is a fork where pages that only contain up-to-date row versions are marked by one bit. Roughly, it means that when a transaction tries to read a row from such a page, the row can be shown without checking its visibility. In next articles, we will discuss in detail how this happens.
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
Pages
As already mentioned, files are logically divided into pages.
A page usually has the size of 8 KB. The size can be changed within certain limits (16 KB or 32 KB), but only during the build (
./configure --with-blocksize). A built and run instance can only work with pages of the same size.Regardless of the fork where files belong, the server uses them in a pretty similar way. Pages are first read into the buffer cache, where the processes can read and change them; then as the need arises, they are evicted back to disk.
Each page has internal partitioning and in general contains the following partitions:
0 +-----------------------------------+
| header |
24 +-----------------------------------+
| array of pointers to row versions |
lower +-----------------------------------+
| free space |
upper +-----------------------------------+
| row versions |
special +-----------------------------------+
| special space |
pagesize +-----------------------------------+
You can easily get to know the sizes of these partitions using the «research» extension pageinspect:
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
Here we are looking at the header of the very first (zero) page of the table. In addition to the sizes of other areas, the header has different information about the page, which we are not interested in yet.
At the bottom of the page there is the special space, which is empty in this case. It is only used for indexes, and even not for all of them. «At the bottom» here reflects what is in the picture; it may be more accurate to say «in high addresses».
After the special space, row versions are located, that is, that very data that we store in the table plus some internal information.
At the top of a page, right after the header, there is the table of contents: the array of pointers to row versions available in the page.
Free space can be left between row versions and pointers (this free space is kept track of in the free space map). Note that there is no memory fragmentation inside a page — all the free space is represented by one contiguous area.
Pointers
Why are the pointers to row versions needed? The thing is that index rows must somehow reference row versions in the table. It's clear that the reference must contain the file number, the number of the page in the file and some indication of the row version. We could use the offset from the beginning of the page as the indicator, but it is inconvenient. We would be unable to move a row version inside the page since it would break available references. And this would result in the fragmentation of the space inside pages and other troublesome consequences. Therefore, the index references the pointer number, and the pointer references the current location of the row version in the page. And this is indirect addressing.
Each pointer occupies exactly four bytes and contains:
- a reference to the row version
- the size of this row version
- several bytes to determine the status of the row version
Data format
The data format on disk is exactly the same as the data representation in RAM. The page is read into the buffer cache «as is», without whatever conversions. Therefore, data files from one platform turn out incompatible with other platforms.
For example, in the X86 architecture, the byte ordering is from least significant to most significant bytes (little-endian), z/Architecture uses the inverse order (big-endian), and in ARM the order can be swapped.
Many architectures provide for data alignment on boundaries of machine words. For example, on a 32-bit x86 system, integer numbers (type «integer», which occupies 4 bytes) will be aligned on a boundary of 4-byte words, the same way as double-precision numbers (type «double precision», which occupies 8 bytes). And on a 64-bit system, double-precision numbers will be aligned on a boundary of 8-byte words. This is one more incompatibility reason.
Because of the alignment, the size of the table row depends on the field order. Usually this effect is not very noticeable, but sometimes, it may result in a considerable growth of the size. For example, if fields of types «char(1)» and «integer» are interleaved, usually 3 bytes between them go to waste. For more details of this, you can look into Nikolay Shaplov's presentation "Tuple internals".
Row versions and TOAST
We will discuss details of the internal structure of row versions next time. At this point, it is only important for us to know that each version must entirely fit one page: PostgreSQL has no way to «extend» the row to the next page. The Oversized Attributes Storage Technique (TOAST) is used instead. The name itself hints that a row can be sliced into toasts.
Joking apart, TOAST implies several strategies. We can transmit long attribute values to a separate internal table after breaking them up into small toast chunks. Another option is to compress a value so that the row version does fit a regular page. And we can do both: first compress and then break up and transmit.
For each primary table, a separate TOAST table can be created if needed, one for all attributes (along with an index on it). The availability of potentially long attributes determines this need. For example, if a table has a column of type «numeric» or «text», the TOAST table will be immediately created even if long values won't be used.
Since a TOAST table is essentially a regular table, it has the same set of forks. And this doubles the number of files that correspond to a table.
The initial strategies are defined by the column data types. You can look at them using the
\d+ command in psql, but since it additionally outputs a lot of other information, we will query the system catalog:=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
The names of the strategies mean:
- plain — TOAST is unused (used for data types known to be short, such as «integer»).
- extended — both compression and storage in a separate TOAST table are allowed
- external — long values are stored in the TOAST table without compression.
- main — long values are first compressed and only get into the TOAST table if the compression did not help.
In general, the algorithm is as follows. PostgreSQL aims to have at least four rows fit one page. Therefore, if the row size exceeds one forth of the page, the header taken into account (2040 bytes for a regular 8K-page), TOAST must be applied to a part of the values. We follow the order described below and stop as soon as the row no longer exceeds the threshold:
- First we go through the attributes with the «external» and «extended» strategies from the longest attribute to the shortest. «Extended» attributes are compressed (if it is effective) and if the value itself exceeds one forth of the page, it immediately gets into the TOAST table. «External» attributes are processed the same way, but aren't compressed.
- If after the first pass, the row version does not fit the page yet, we transmit the remaining attributes with the «external» and «extended» strategies to the TOAST table.
- If this did not help either, we try to compress the attributes with the «main» strategy, but leave them in the table page.
- And only if after that, the row is not short enough, «main» attributes get into the TOAST table.
Sometimes it may be useful to change the strategy for certain columns. For example, if it is known in advance that the data in a column cannot be compressed, we can set the «external» strategy for it, which enables us to save time by avoiding useless compression attempts. This is done as follows:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
Re-running the query, we get:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
TOAST tables and indexes are located in the separate pg_toast schema and are, therefore, usually not visible. For temporary tables, the «pg_toast_temp_N» schema is used similarly to the usual «pg_temp_N».
Of course, if you like nobody will hinder your spying upon the internal mechanics of the process. Say, in the «accounts» table there are three potentially long attributes, and therefore, there must be a TOAST table. Here it is:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
It's reasonable that the «plain» strategy is applied to the toasts into which the row is sliced: there is no second-level TOAST.
PostgreSQL hides the index better, but it is not difficult to find either:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
The «client» column uses the «extended» strategy: its values will be compressed. Let's check:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
There is nothing in the TOAST table: repeating characters are compressed fine and after compression the value fits a usual table page.
And now let the client name consist of random characters:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
Such a sequence cannot be compressed, and it gets into the TOAST table:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
We can see that the data are broken up into 2000-byte chunks.
When a long value is accessed, PostgreSQL automatically and transparently for the application restores the original value and returns it to the client.
Certainly, it is pretty resource-intensive to compress and break up and then to restore. Therefore, to store massive data in PostgreSQL is not the best idea, especially if they are frequently used and the usage does not require transactional logic (for example: scans of original accounting documents). A more beneficial alternative is to store such data on a file system with the filenames stored in the DBMS.
The TOAST table is only used to access a long value. Besides, its own mutiversion concurrency is supported for a TOAST table: unless a data update touches a long value, a new row version will reference the same value in the TOAST table, and this saves space.
Note that TOAST only works for tables, but not for indexes. This imposes a limitation on the size of keys to be indexed.
For more details of the internal data structure, you can read the documentation.
Read on.
