Диаграммы помогают визуализировать как простые, так и самые сложные наборы данных. При этом диаграмм — множество видов, у каждого есть свои достоинства и недостатки. О наиболее эффектных и эффективных, реализуемых с Python, мы решили рассказать в сегодняшней подборке. Если вам интересна эта тема – просим под кат. А если у вас есть собственные предпочтения среди графиков (или вы используете что-то ещё), то пишите в комментариях, обсудим. Что же – поехали!

Чтобы построить график, нужны данные!
И они у нас есть. Для статьи можно взять практически любые данные, главное, чтобы их можно было визуализировать. Наборы данных по самым разным темам есть на Википедии. Возьмем информацию из статьи "Список стран по выбросам углекислого газа".
Сначала парсим данные. Это можно сделать при помощи вот такого кода:
import requests
from bs4 import BeautifulSoup
wikiurl='https://en.wikipedia.org/wiki/List_of_countries_by_carbon_dioxide_emissions'
table_class='wikitable sortable jquery-tablesorter'
response=requests.get(wikiurl)
#status 200: Сервер успешно ответил на запрос http
print(response.status_code) Затем применяем BeautifulSoup для сортировки и ранжирования данных:
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table',{'class':"wikitable"})
df2018 = pd.read_html(str(table))[0]
df2018Воспользуемся столбцом «Выбросы углекислого газа в 2018 / Общие» и возьмем только страны с объемом выбросов от 200 до 1000 MT CO2e.
# Получаем списки данных
emi_ = df2018[('2018 CO2 emissions[21]', 'Total excluding LUCF[23]')]
country_ = list(df2018[('Country[20]', 'Country[20]')])
country_mod = [i.replace('\xa0',' ') for i in country_]
# Создаём DataFrame
df = pd.DataFrame(zip(country_mod,emi_), columns = ['countries', 'emission_2018'])
# Убираем строку о стране, которую нельзя конвертировать
df = df[df['countries']!='Serbia & Montenegro']
df.iloc[:,1] = df.iloc[:,1].astype('float')
df = df[(df['emission_2018']>200) & (df['emission_2018']<1000)]
df['percentage'] = [i*100/sum(df['emission_2018']) for i in df['emission_2018']]
df.head(9)Получаем вот такой результат:

Визуализируй это
Диаграмм и гистограмм существует великое множество. Если описывать все – получится не статья, а сочинение из многих томов. Поэтому отберем пять, которые привлекают внимание сильнее всего (всё это, конечно, субъективно, поэтому если у вас есть собственные предпочтения по визуализации данных в Python, расскажите о них в комментариях):
Круговая диаграмма
Древовидная диаграмма
Интерактивная гистограмма
Лепестковая диаграмма
Секторная диаграмма
Круговая диаграмма
Круговой она называется потому, что (вот сюрприз) представляет собой круг с отдельными дорожками на ней. Есть у этой диаграммы особенность — длина столбцов-«дорожек». Те, что находятся ближе к центру круга, короче столбцов, которые находятся подальше. Нечто вроде стадиона с беговыми дорожками, по которым бегут атлеты.
Вот код, который позволяет нарисовать круговую диаграмму для спарсенных ранее данных:
import math
plt.gcf().set_size_inches(12, 12)
sns.set_style('darkgrid')
# Установка максимального значения
max_val = max(df['emission_2018'])*1.01
ax = plt.subplot(projection='polar')
# Зададим внутренний график
ax.set_theta_zero_location('N')
ax.set_theta_direction(1)
ax.set_rlabel_position(0)
ax.set_thetagrids([], labels=[])
ax.set_rgrids(range(len(df)), labels= df['countries'])

Визуализация, которая даёт наглядное представление о ситуации с углекислым газом (или любой другой проблемой, вопросом, данные которых требуется отобразить графически).
Древовидная диаграмма
Она демонстрирует иерархические данные в виде площадей прямоугольников. Стандартная древовидная диаграмма сортирует данные по убыванию. Древовидную диаграмму несложно сделать посредством Plotly.
import plotly.express as px
fig = px.treemap(df, path=[px.Constant('Countries'), 'countries'],
values=df['emission_2018'],
color=df['emission_2018'],
color_continuous_scale='Spectral_r',
color_continuous_midpoint=np.average(df['emission_2018'])
)
fig.update_layout(margin = dict(t=50, l=25, r=25, b=25))
fig.show()
Интерактивная гистограмма
Для создания такой диаграммы также рекомендуем использовать библиотеку Plotly. Она очень сильно упрощает процесс добавления интерактивности. Вот код:
import plotly.express as px
fig = px.bar(df, x='countries', y='emission_2018', text='emission_2018',
color ='countries', color_discrete_sequence=pal_vi)
fig.update_traces(texttemplate='%{text:.3s}', textposition='outside')
fig.update_layout({'plot_bgcolor': 'white',
'paper_bgcolor': 'white'})
fig.update_layout(width=1100, height=500,
margin = dict(t=15, l=15, r=15, b=15))
fig.show()А вот результат:

Лепестковая диаграмма
Этот вид диаграмм используется для случаев, когда нужно визуализировать многовариантные данные. Таким образом можно сравнивать данные, которые не расположены рядом друг с другом. Чтобы создать лепестковую диаграмму, будем считать каждую категорию переменной в многовариантных данных.
Вот код, который отвечает за создание этого типа диаграмм.
import plotly.express as px
fig = px.line_polar(df, r='emission_2018',
theta='countries', line_close=True)
fig.update_traces(fill='toself', line = dict(color=pal_spec[5]))
fig.show()Результат, который получается в итоге.

Если потребуется визуализировать уже отсортированный DataFrame, то вот код, который позволяет это сделать.
import plotly.express as px
fig = px.line_polar(df_s, r='emission_2018',
theta='countries', line_close=True)
fig.update_traces(fill='toself', line = dict(color=pal_spec[-5]))
fig.show()И результат:

Пузырьковая диаграмма
Хороший вариант, чтобы наглядно показать данные в виде окружностей с определённым размером. Располагать окружности можно в любом виде — вертикально, горизонтально, кружком, треугольником и т.п. Ниже пример вертикальной пузырьковой диаграммы.
Сначала — пример кода, который отвечает за построение списка значений X, значений Y и меток.
# Столбцы по осям X и Y
df_s['X'] = [1]*len(df_s)
list_y = list(range(0,len(df_s)))
list_y.reverse()
df_s['Y'] = list_y
# Столбец меток
df_s['labels'] = ['<b>'+i+'<br>'+format(j, ",") for i,j in zip(df_s['countries'], df_s['emission_2018'])]
df_s

А теперь приступаем к построению самой диаграммы. Вот пример кода:
import plotly.express as px
fig = px.scatter(df_s, x='X', y='Y',
color='countries', color_discrete_sequence=pal_vi,
size='emission_2018', text='labels', size_max=30)
fig.update_layout(width=500, height=1100,
margin = dict(t=0, l=0, r=0, b=0),
showlegend=False
)
fig.update_traces(textposition='middle right')
fig.update_xaxes(showgrid=False, zeroline=False, visible=False)
fig.update_yaxes(showgrid=False, zeroline=False, visible=False)
fig.update_layout({'plot_bgcolor': 'white',
'paper_bgcolor': 'white'})
fig.show()И сама пузырьковая диаграмма.

Бонус. А что насчёт анимированных диаграмм?
Для этого в Python есть пакет, который даёт возможность анимировать визуализацию данных. Этот метод расширения FuncAnimation и часть класса Animation библиотеки Matplotlib в Python. Анимация начинается вот с такого кода:
import matplotlib.animation as ani
animator = ani.FuncAnimation(fig, chartfunc, interval = 100)Здесь:
fig — объект рисунка, где и будет происходить создание диаграммы.
chartfunc — функция, которая позволяет показывать время измерения во временном ряду.
Interval — задержка между кадрами в мс (по дефолту — до 200).
Если нужна более подробная документация по входным данным, то вот она.
Для демонстрации возможностей анимации диаграмм давайте воспользуемся данными по пандемии COVID-19 по разным странам.
import matplotlib.animation as ani
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
url = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series
/time_series_covid19_deaths_global.csv'
df = pd.read_csv(url, delimiter=',', header='infer')
df_interest = df.loc[
df['Country/Region'].isin(['United Kingdom', 'US', 'Italy', 'Germany'])
& df['Province/State'].isna()]
df_interest.rename(
index=lambda x: df_interest.at[x, 'Country/Region'], inplace=True)
df1 = df_interest.transpose()
df1 = df1.drop(['Province/State', 'Country/Region', 'Lat', 'Long'])
df1 = df1.loc[(df1 != 0).any(1)]
df1.index = pd.to_datetime(df1.index)
Чтобы построить диаграмму, нужно определить параметры, которые остаются постоянными. Соответственно, создаём объект рисунка, координаты x и y, а также устанавливаем цвета линий и поля.
import numpy as np
import matplotlib.pyplot as plt
color = ['red', 'green', 'blue', 'orange']
fig = plt.figure()
plt.xticks(rotation=45, ha="right", rotation_mode="anchor") #циклическое перемещение значений по оси x
plt.subplots_adjust(bottom = 0.2, top = 0.9) #убеждаемся, что даты (по оси x) умещаются на экране
plt.ylabel('No of Deaths')
plt.xlabel('Dates')Далее - настраиваем функцию кривой и анимируем ее.
def buildmebarchart(i=int):
plt.legend(df1.columns)
p = plt.plot(df1[:i].index, df1[:i].values) #обращаем внимание, что происходит возврат набора данных вплоть до точки i
for i in range(0,4):
p[i].set_color(color[i]) #устанавливаем цвет для каждой кривой
importmatplotlib.animation as ani
animator = ani.FuncAnimation(fig, buildmebarchart, interval = 100)
plt.show()Вот, что получается на выходе:
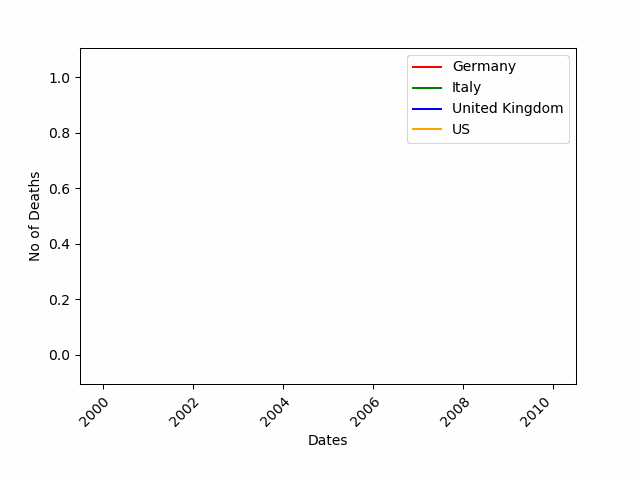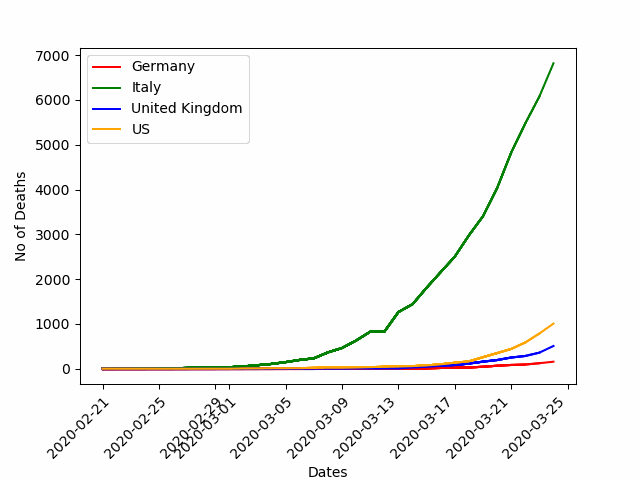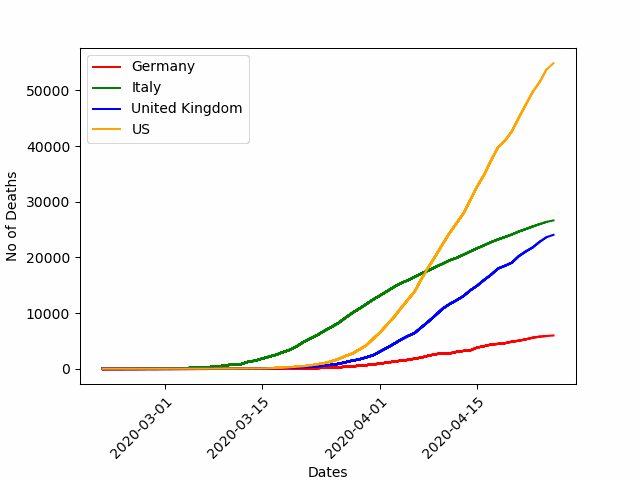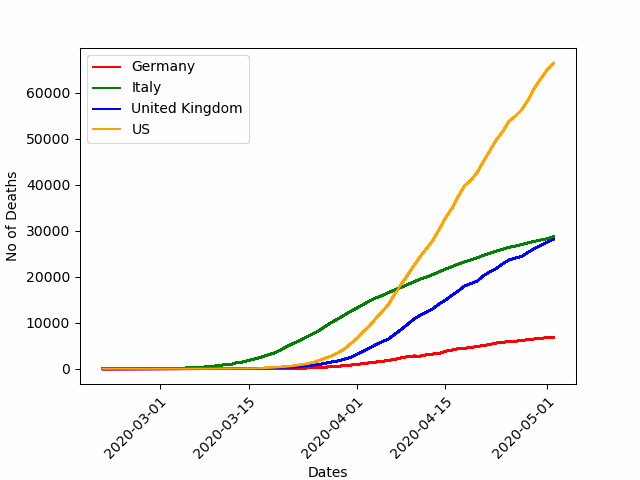
Стоит отметить, что возможностей визуализации данных просто огромное количество. Их можно комбинировать, получая нечто совершенно новое и эффектное. Здесь предела совершенству просто нет, можно проводить часы за выбором интересных методов визуализации.
