
Давайте немного поговорим о том, как наблюдать за тем, какой объём ресурсов процессора потребляет JavaScript-код приложений. При этом предлагаю построить наш разговор вокруг компонентов — базовых строительных блоков приложения. При таком подходе любые усилия по улучшению производительности (или усилия по поиску причин замедления программ) можно сосредоточить на (хочется надеяться) маленьких самодостаточных фрагментах проекта. Я предполагаю при этом, что ваше фронтенд-приложение, как и многие другие современные проекты, создано путём сборки небольших фрагментов интерфейса, подходящих для многократного использования. Если это не так, то наши рассуждения можно будет применить и к другому приложению, но вам придётся найти собственный способ разделения своего крупномасштабного кода на фрагменты и надо будет подумать над тем, как анализировать эти фрагменты.

Зачем измерять потребление ресурсов процессора JavaScript-кодом? Дело в том, что в наши дни производительность приложений чаще всего привязана к возможностям процессора. Позвольте мне вольно процитировать слова Стива Содерса и Пэта Минана из интервью, которое я брал для Planet Performance Podcast. Оба они говорили о том, что производительность приложений больше не ограничивается возможностями сетей или сетевыми задержками. Сети становятся всё быстрее и быстрее. Разработчики, кроме того, научились сжимать текстовые ответы серверов с помощью GZIP (или, скорее, с применением brotli) и разобрались с оптимизацией изображений. Это всё очень просто.
Узким местом производительности современных приложений стали процессоры. Особенно это актуально в мобильной среде. И, в то же время, выросли наши ожидания относительно интерактивных возможностей современных веб-приложений. Мы ожидаем, что интерфейсы таких приложений будут работать очень быстро и плавно. А для всего этого требуется всё больше и больше JavaScript-кода. Кроме того, нам нужно помнить о том, что 1 Мб изображений — это не то же самое, что 1 Мб JavaScript. Изображения загружаются прогрессивно, а приложение в это время решает другие задачи. А вот JavaScript-код — это часто такой ресурс, без которого приложение оказывается неработоспособным. Для обеспечения функционирования современного приложения требуются большие объёмы JS-кода, которые, прежде чем они начинают реально работать, нужно распарсить и выполнить. А это — задачи, которые сильно зависят от возможностей процессора.
Мы будем использовать такой показатель скорости работы фрагментов кода, как количество инструкций процессора, необходимое на их обработку. Это позволит нам отделить измерения от свойств конкретного компьютера и от того, в каком состоянии он находится в момент измерений. В метриках, основанных на измерении времени (вроде TTI) слишком много «шума». Они зависят от состояния сетевого соединения, а так же от чего угодно другого, происходящего на компьютере в момент измерений. Например, на временные показатели производительности могут повлиять некие скрипты, выполняемые во время загрузки исследуемой страницы, или вирусы, которые чем-то заняты в фоновых процессах. То же самое можно сказать и о браузерных расширениях, которые могут потреблять немало системных ресурсов и замедлять страницу. При подсчёте же количества инструкций процессора, с другой стороны, время неважно. Подобные показатели могут быть, как вы скоро увидите, по-настоящему стабильными.
Вот идея, положенная в основу нашей работы: нужно создать «лабораторию», в которой код будет запускаться и исследоваться при внесении в него изменений. Под «лабораторией» я понимаю обычный компьютер, возможно, тот, которым вы постоянно пользуетесь. Системы контроля версий дают в наше распоряжении хуки, с помощью которых можно перехватывать определённые события и выполнять некие проверки. Конечно, измерения в «лаборатории» можно выполнять после выполнения коммитов. Но вы, наверняка, знаете о том, что изменения в код, достигший стадии коммита, будут вноситься медленнее, чем в код, находящийся в процессе написания (если вообще будут вноситься). То же самое касается и исправления кода бета-версии продукта, и исправления кода, который попал в продакшн.
Нам нужно, чтобы при каждом изменении кода проводилось бы сравнение его производительности до и после внесения изменений. При этом мы стремимся к тому, чтобы исследовать компоненты в изоляции. В результате мы сможем ясно видеть проблемы и сможем точно знать о том, где они возникают.
Хорошо то, что подобные исследования можно проводить в настоящем браузере, используя, например, Puppeteer. Это — инструмент, который позволяет управлять браузером без пользовательского интерфейса из среды Node.js.
Для того чтобы найти код для исследования, мы можем обратиться к любому руководству по стилям, или к любой дизайн-системе. В целом — нас устроит что угодно, предоставляющее краткие, изолированные примеры использования компонентов.
Что такое «руководство по стилям»? Обычно это — веб-приложение, демонстрирующее все компоненты или «строительные блоки» элементов пользовательского интерфейса, доступные разработчику. Это может быть как некая библиотека компонентов стороннего разработчика, так и что-то, созданное вашими силами.
Занимаясь поиском подобных проектов в интернете, я наткнулся на недавнюю ветку обсуждения в Твиттере, речь в которой шла об относительно новых библиотеках React-компонентов. Я взглянул на несколько упомянутых там библиотек.
Неудивительно то, что современные качественные библиотеки снабжены документацией, включающей в себя рабочие примеры кода. Здесь представлена пара библиотек и реализованные их средствами компоненты

Документация Chakra, посвящённая компоненту Button

Документация Semantic UI React, посвящённая компоненту Button
Это — именно то, что нам нужно. Это — те примеры, код которых мы можем исследовать на предмет потребления ими ресурсов процессора. Подобные примеры могут находиться в недрах документации, или в комментариях к коду, написанных в стиле JSDoc. Возможно, если вам повезёт, вы обнаружите такие примеры, оформленные в виде отдельных файлов, скажем — в виде файлов модульных тестов. Наверняка будет именно так. Ведь все мы пишем модульные тесты. Правда?
Представим, ради демонстрации описываемого метода анализа производительности, что в исследуемой нами библиотеке есть компонент
Вот простой компонент
А вот — пример использования компонента
Вот страница
Для того чтобы загрузить тестовую страницу в Chrome, мы можем воспользоваться Node.js-библиотекой Puppeteer, которая даёт нам доступ к API для управления браузером. Пользоваться этой библиотекой можно в любой операционной системе. В ней имеется собственная копия Chrome, но её можно применять и для работы с уже существующим на компьютере разработчика экземпляром Chrome или Chromium различных версий. Chrome можно запустить так, что его окно будет невидимым. Тесты выполняются автоматически, разработчику при этом видеть окно браузера необязательно. Chrome можно запустить и в обычном режиме. Это полезно для целей отладки.
Вот пример Node.js-скрипта, запускаемого из командной строки, который загружает тестовую страницу и пишет данные в файл журнала производительности. Всё, что происходит в браузере между командами
Разработчик может управлять «детальностью» данных о производительности, указывая «категории» трассировки. Список доступных категорий можно увидеть, если перейти в Chrome по адресу
Настройка состава данных, записываемых в журнал производительности
После того, как тестовая страница исследована с помощью Puppeteer, можно проанализировать результаты измерений производительности, перейдя в браузере по адресу

Визуализация trace.json
Здесь можно видеть результаты вызова метода
Вот фрагмент

Фрагмент файла trace.json
Для того чтобы выяснить то, что нам нужно, достаточно вычесть показатель количества инструкций процессора (
Сейчас мы измерили лишь показатели, характеризующие первый вывод на страницу единственного компонента. И ничего больше. Настоятельно необходимо измерять показатели, относящиеся к как можно меньшему объёму выполняемого кода. Это позволяет уменьшить уровень «шума». Дьявол кроется в деталях. Чем меньше то, производительность чего измеряется, тем лучше. После измерений нужно убрать из полученных результатов то, что находится за пределами влияния разработчика. Например — данные, относящиеся к операциям сборки мусора. Компонент не контролирует такие операции. Если они выполняются, то это значит, что браузер, в процессе рендеринга компонента, сам решил их запустить. В результате из итоговых результатов нужно убрать те процессорные ресурсы, которые ушли на сборку мусора.
Блок данных, относящийся к сборке мусора (этот «блок данных» правильнее называть «событием»), носит имя
Нужно очень внимательно относиться к тому, что именно мы измеряем. Браузеры — весьма интеллектуальные сущности. Они оптимизируют код, который выполняется более одного раза. На следующем графике можно видеть количество инструкций процессора, необходимое для вывода некоего компонента. Первая операция рендеринга требует больше всего ресурсов. Последующие операции создают гораздо меньшую нагрузку на процессор. Это стоит иметь в виду, анализируя производительность кода.

10 операций рендеринга одного и того же компонента
Вот ещё одна деталь: если компонент выполняет некие асинхронные операции (например, пользуется
Если ответственно подойти к решению вопроса о том, что именно измеряется, то можно получить по-настоящему стабильный сигнал, отражающий влияние на производительность любых изменений. Мне нравится то, насколько гладкими получились линии на следующем графике.
Стабильные результаты измерений
На нижнем графике показаны результаты измерений 10 операций рендеринга простого элемента
То, как именно представлять измерения такой точности — дело разработчика. Если подобная точность ему не нужна, он всегда может измерять производительность рендеринга более крупных фрагментов.
Теперь, когда в распоряжении разработчика имеется система нахождения численных показателей, очень точно характеризующих производительность мельчайших фрагментов кода, разработчик может воспользоваться этой системой для решения различных задач. Так, с помощью
Можно ли всем, о чём шла тут речь, пользоваться уже сегодня? Да, можно. Для этого понадобится Chrome версии 78 или выше. Если в
К сожалению, сведения о количестве инструкций процессора нельзя получить на платформе Mac. Windows я пока не пробовал, поэтому ничего определённого об этой ОС сказать не могу. В общем — наши друзья — это Unix и Linux.
Надо отметить, что для того, чтобы браузер мог бы выдавать сведения об инструкциях процессора, понадобится использовать пару флагов — это
Надеюсь, теперь вы сможете вывести анализ производительности своих веб-приложений на новый уровень.
Уважаемые читатели! Планируете ли вы использовать представленную здесь методику анализа производительности веб-проектов?


Зачем это нужно?
Зачем измерять потребление ресурсов процессора JavaScript-кодом? Дело в том, что в наши дни производительность приложений чаще всего привязана к возможностям процессора. Позвольте мне вольно процитировать слова Стива Содерса и Пэта Минана из интервью, которое я брал для Planet Performance Podcast. Оба они говорили о том, что производительность приложений больше не ограничивается возможностями сетей или сетевыми задержками. Сети становятся всё быстрее и быстрее. Разработчики, кроме того, научились сжимать текстовые ответы серверов с помощью GZIP (или, скорее, с применением brotli) и разобрались с оптимизацией изображений. Это всё очень просто.
Узким местом производительности современных приложений стали процессоры. Особенно это актуально в мобильной среде. И, в то же время, выросли наши ожидания относительно интерактивных возможностей современных веб-приложений. Мы ожидаем, что интерфейсы таких приложений будут работать очень быстро и плавно. А для всего этого требуется всё больше и больше JavaScript-кода. Кроме того, нам нужно помнить о том, что 1 Мб изображений — это не то же самое, что 1 Мб JavaScript. Изображения загружаются прогрессивно, а приложение в это время решает другие задачи. А вот JavaScript-код — это часто такой ресурс, без которого приложение оказывается неработоспособным. Для обеспечения функционирования современного приложения требуются большие объёмы JS-кода, которые, прежде чем они начинают реально работать, нужно распарсить и выполнить. А это — задачи, которые сильно зависят от возможностей процессора.
Показатель производительности
Мы будем использовать такой показатель скорости работы фрагментов кода, как количество инструкций процессора, необходимое на их обработку. Это позволит нам отделить измерения от свойств конкретного компьютера и от того, в каком состоянии он находится в момент измерений. В метриках, основанных на измерении времени (вроде TTI) слишком много «шума». Они зависят от состояния сетевого соединения, а так же от чего угодно другого, происходящего на компьютере в момент измерений. Например, на временные показатели производительности могут повлиять некие скрипты, выполняемые во время загрузки исследуемой страницы, или вирусы, которые чем-то заняты в фоновых процессах. То же самое можно сказать и о браузерных расширениях, которые могут потреблять немало системных ресурсов и замедлять страницу. При подсчёте же количества инструкций процессора, с другой стороны, время неважно. Подобные показатели могут быть, как вы скоро увидите, по-настоящему стабильными.
Идея
Вот идея, положенная в основу нашей работы: нужно создать «лабораторию», в которой код будет запускаться и исследоваться при внесении в него изменений. Под «лабораторией» я понимаю обычный компьютер, возможно, тот, которым вы постоянно пользуетесь. Системы контроля версий дают в наше распоряжении хуки, с помощью которых можно перехватывать определённые события и выполнять некие проверки. Конечно, измерения в «лаборатории» можно выполнять после выполнения коммитов. Но вы, наверняка, знаете о том, что изменения в код, достигший стадии коммита, будут вноситься медленнее, чем в код, находящийся в процессе написания (если вообще будут вноситься). То же самое касается и исправления кода бета-версии продукта, и исправления кода, который попал в продакшн.
Нам нужно, чтобы при каждом изменении кода проводилось бы сравнение его производительности до и после внесения изменений. При этом мы стремимся к тому, чтобы исследовать компоненты в изоляции. В результате мы сможем ясно видеть проблемы и сможем точно знать о том, где они возникают.
Хорошо то, что подобные исследования можно проводить в настоящем браузере, используя, например, Puppeteer. Это — инструмент, который позволяет управлять браузером без пользовательского интерфейса из среды Node.js.
Поиск кода для исследования
Для того чтобы найти код для исследования, мы можем обратиться к любому руководству по стилям, или к любой дизайн-системе. В целом — нас устроит что угодно, предоставляющее краткие, изолированные примеры использования компонентов.
Что такое «руководство по стилям»? Обычно это — веб-приложение, демонстрирующее все компоненты или «строительные блоки» элементов пользовательского интерфейса, доступные разработчику. Это может быть как некая библиотека компонентов стороннего разработчика, так и что-то, созданное вашими силами.
Занимаясь поиском подобных проектов в интернете, я наткнулся на недавнюю ветку обсуждения в Твиттере, речь в которой шла об относительно новых библиотеках React-компонентов. Я взглянул на несколько упомянутых там библиотек.
Неудивительно то, что современные качественные библиотеки снабжены документацией, включающей в себя рабочие примеры кода. Здесь представлена пара библиотек и реализованные их средствами компоненты
Button. В документации к данным библиотекам есть примеры использования этих компонентов. Речь идёт о библиотеке Chakra и о библиотеке Semantic UI React.Документация Chakra, посвящённая компоненту Button
Документация Semantic UI React, посвящённая компоненту Button
Это — именно то, что нам нужно. Это — те примеры, код которых мы можем исследовать на предмет потребления ими ресурсов процессора. Подобные примеры могут находиться в недрах документации, или в комментариях к коду, написанных в стиле JSDoc. Возможно, если вам повезёт, вы обнаружите такие примеры, оформленные в виде отдельных файлов, скажем — в виде файлов модульных тестов. Наверняка будет именно так. Ведь все мы пишем модульные тесты. Правда?
Файлы
Представим, ради демонстрации описываемого метода анализа производительности, что в исследуемой нами библиотеке есть компонент
Button, код которого находится в файле Button.js.К этому файлу прилагается файл с модульным тестом Button-test.js, а также — файл с примером использования компонента — Button-example.js. Нам нужно создать некую тестовую страницу, в окружении которой может быть запущен тестовый код. Нечто вроде test.html.Компонент
Вот простой компонент
Button. Я тут использую React, но ваши компоненты могут быть написаны с использованием любых удобных вам технологий.import React from 'react';
const Button = (props) =>
props.href
? <a {...props} className="Button"/>
: <button {...props} className="Button"/>
export default Button;Пример
А вот — пример использования компонента
Button. Как видите, в данном случае имеются два варианта компонента, в которых используются разные свойства.import React from 'react';
import Button from 'Button';
export default [
<Button onClick={() => alert('ouch')}>
Click me
</Button>,
<Button href="https://reactjs.com">
Follow me
</Button>,
]Тест
Вот страница
test.html, которая может загружать любые компоненты. Обратите внимание на вызовы методов объекта performance. Именно с их помощью мы, по своему желанию, делаем записи в файл журнала производительности Chrome. Совсем скоро мы этими записями воспользуемся.const examples =
await import(location.hash + '-example.js');
examples.forEach(example =>
performance.mark('my mark start');
ReactDOM.render(<div>{example}</div>, where);
performance.mark('my mark end');
performance.measure(
'my mark', 'my mark start', 'my mark end');
);Средство для запуска тестов
Для того чтобы загрузить тестовую страницу в Chrome, мы можем воспользоваться Node.js-библиотекой Puppeteer, которая даёт нам доступ к API для управления браузером. Пользоваться этой библиотекой можно в любой операционной системе. В ней имеется собственная копия Chrome, но её можно применять и для работы с уже существующим на компьютере разработчика экземпляром Chrome или Chromium различных версий. Chrome можно запустить так, что его окно будет невидимым. Тесты выполняются автоматически, разработчику при этом видеть окно браузера необязательно. Chrome можно запустить и в обычном режиме. Это полезно для целей отладки.
Вот пример Node.js-скрипта, запускаемого из командной строки, который загружает тестовую страницу и пишет данные в файл журнала производительности. Всё, что происходит в браузере между командами
tracing.start() и end(), записывается (хочется отметить, весьма подробно) в файл trace.json.import pup from 'puppeteer';
const browser = await pup.launch();
const page = await browser.newPage();
await page.tracing.start({path: 'trace.json'});
await page.goto('test.html#Button');
await page.tracing.stop();
await browser.close();Разработчик может управлять «детальностью» данных о производительности, указывая «категории» трассировки. Список доступных категорий можно увидеть, если перейти в Chrome по адресу
chrome://tracing, нажать Record и открыть в появившемся окне раздел Edit categories.Настройка состава данных, записываемых в журнал производительности
Результаты
После того, как тестовая страница исследована с помощью Puppeteer, можно проанализировать результаты измерений производительности, перейдя в браузере по адресу
chrome://tracing и загрузив только что записанный файл trace.json.Визуализация trace.json
Здесь можно видеть результаты вызова метода
performance.measure('my mark'). Вызов measure() нужен исключительно для отладочных целей, на тот случай, если разработчику захочется открыть файл trace.json и посмотреть его. Всё, что произошло со страницей, заключено в блок my mark.Вот фрагмент
trace.json:Фрагмент файла trace.json
Для того чтобы выяснить то, что нам нужно, достаточно вычесть показатель количества инструкций процессора (
ticount) маркера Start из такого же показателя маркера End. Это позволяет узнать о том, сколько инструкций процессора нужно для вывода компонента в браузере. Это — то самое число, которое можно использовать для того, чтобы выяснить, стал ли компонент быстрее или медленнее.Дьявол кроется в деталях
Сейчас мы измерили лишь показатели, характеризующие первый вывод на страницу единственного компонента. И ничего больше. Настоятельно необходимо измерять показатели, относящиеся к как можно меньшему объёму выполняемого кода. Это позволяет уменьшить уровень «шума». Дьявол кроется в деталях. Чем меньше то, производительность чего измеряется, тем лучше. После измерений нужно убрать из полученных результатов то, что находится за пределами влияния разработчика. Например — данные, относящиеся к операциям сборки мусора. Компонент не контролирует такие операции. Если они выполняются, то это значит, что браузер, в процессе рендеринга компонента, сам решил их запустить. В результате из итоговых результатов нужно убрать те процессорные ресурсы, которые ушли на сборку мусора.
Блок данных, относящийся к сборке мусора (этот «блок данных» правильнее называть «событием»), носит имя
V8.GCScavenger. Его показатель tidelta нужно вычесть из количества инструкций процессора, уходящих на рендеринг компонента. Вот документация по событиям трассировки. Она, правда, устарела, и не содержит сведений о нужных нам показателях:tidelta— количество инструкций процессора, потребовавшихся на обработку некоего события.ticount— количество инструкций на начало события.
Нужно очень внимательно относиться к тому, что именно мы измеряем. Браузеры — весьма интеллектуальные сущности. Они оптимизируют код, который выполняется более одного раза. На следующем графике можно видеть количество инструкций процессора, необходимое для вывода некоего компонента. Первая операция рендеринга требует больше всего ресурсов. Последующие операции создают гораздо меньшую нагрузку на процессор. Это стоит иметь в виду, анализируя производительность кода.
10 операций рендеринга одного и того же компонента
Вот ещё одна деталь: если компонент выполняет некие асинхронные операции (например, пользуется
setTimeout() или fetch()), то нагрузка на систему, создаваемая асинхронным кодом, не учитывается. Может — это хорошо. Может — плохо. Если вы исследуете производительность подобных компонентов — подумайте об отдельном изучении асинхронного кода.Сильный сигнал
Если ответственно подойти к решению вопроса о том, что именно измеряется, то можно получить по-настоящему стабильный сигнал, отражающий влияние на производительность любых изменений. Мне нравится то, насколько гладкими получились линии на следующем графике.
Стабильные результаты измерений
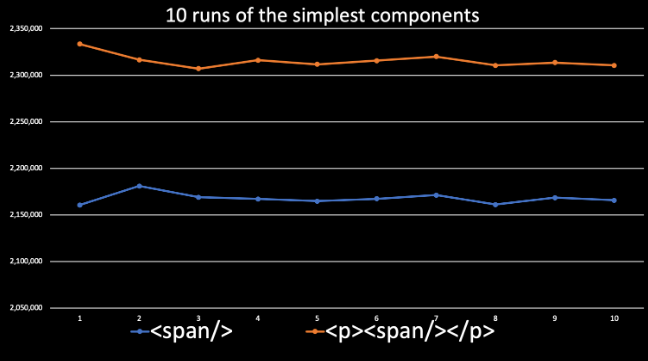
На нижнем графике показаны результаты измерений 10 операций рендеринга простого элемента
<span> в React. Ничего больше в эти результаты не входит. Оказывается, что на выполнение этой операции нужно от 2.15 до 2.2 миллиона инструкций процессора. Если же <span> обернуть в тег <p>, то для вывода такой конструкции надо уже около 2.3 миллиона инструкций. Меня поражает такой уровень точности. Если разработчик может увидеть разницу в производительности, появляющуюся при добавлении на страницу единственного элемента <p>, это значит, что в руках разработчика находится по-настоящему мощный инструмент.То, как именно представлять измерения такой точности — дело разработчика. Если подобная точность ему не нужна, он всегда может измерять производительность рендеринга более крупных фрагментов.
Дополнительные сведения о производительности
Теперь, когда в распоряжении разработчика имеется система нахождения численных показателей, очень точно характеризующих производительность мельчайших фрагментов кода, разработчик может воспользоваться этой системой для решения различных задач. Так, с помощью
performance.mark() можно записывать в trace.json дополнительные полезные сведения. Можно сообщать членам команды разработчиков о том, что, происходит, и что вызывает рост количества инструкций процессора, необходимых для выполнения некоего кода. Можно включать в отчёты о производительности сведения о количестве узлов DOM, или о количестве операций записи в DOM, выполняемых React. На самом деле, тут можно выводить сведения об очень многом. Можно подсчитывать число пересчётов макета страницы. Средствами Puppeteer можно делать скриншоты страниц и сравнивать то, как выглядит интерфейс до и после внесения изменений. Иногда рост количества инструкций процессора, необходимых для вывода некоей страницы, выглядит совершенно неудивительно. Например — в том случае, если в новую версию страницы добавлено 10 кнопок и 12 полей для редактирования и форматирования текста.Итоги
Можно ли всем, о чём шла тут речь, пользоваться уже сегодня? Да, можно. Для этого понадобится Chrome версии 78 или выше. Если в
trace.json имеются показатели ticount и tidelta, то вам вышеописанное доступно. В более ранних версиях Chrome таких показателей нет.К сожалению, сведения о количестве инструкций процессора нельзя получить на платформе Mac. Windows я пока не пробовал, поэтому ничего определённого об этой ОС сказать не могу. В общем — наши друзья — это Unix и Linux.
Надо отметить, что для того, чтобы браузер мог бы выдавать сведения об инструкциях процессора, понадобится использовать пару флагов — это
--no-sandbox и --enable-thread-instruction-count. Вот как передать их браузеру, запускаемому средствами Puppeteer:await puppeteer.launch({
args: [
'--no-sandbox',
'--enable-thread-instruction-count',
]});Надеюсь, теперь вы сможете вывести анализ производительности своих веб-приложений на новый уровень.
Уважаемые читатели! Планируете ли вы использовать представленную здесь методику анализа производительности веб-проектов?
