Финальная статья об инструменте для нагрузочного тестирования Locust. Сегодня поделюсь наблюдениями, которые накопил в процессе работы. Как всегда, видео прилагается.
Часть 1 — тестирование с Locust
Часть 2 — продвинутые сценарии
При написании своих первых тестов с Locust, я столкнулся с необходимостью залогиниться на одном ресурсе, получив авторизационный токен, которой потом уже использовать при нагрузочном тестировании. Тут сразу встал вопрос — как это сделать, ведь инструмент заточен посылать все запросы на один ресурс, который мы указываем в консоли при запуске теста. Есть несколько вариантов решения проблемы:
Я выбрал третий вариант. Ниже предлагаю переделанный пример из первой статьи с разными возможностями получения токена. В качестве сервера авторизации выступит google.com и, так
как токена нет, буду получать самые простые значения
Как видно из примера, перед началом работы пользователь отправляет запрос на сторонний сервер и обрабатывает ответ, помещая данные в заголовки или куки.
При работе с заголовками запроса нужно учитывать несколько важных нюансов.
Для каждого отдельно запроса можно указать собственный набор заголовков следующим образом
При выполнении указанного примера заголовок hello будет добавлен к уже существующим заголовкам клиентской сессии, но только в это запросе — во всех следующих его не будет. Чтобы сделать заголовок постоянным, можно добавить его в сессию:
Еще одно интересное наблюдение — если в запросе мы укажем заголовок, который уже есть в сессии — он будет перезаписан, но только на этот запрос. Так что можно не бояться случайно затереть что-то важное.
Но есть и исключения. Если нам потребуется отправить multipart форму, запрос автоматически сформирует заголовок Content-Type, в котором будет указан разделитель данных формы. Если же мы принудительно перезапишем заголовок с помощью аргумента headers, то запрос провалится, так как форма не сможет быть корректно обработана.
Так же стоит обратить внимание, что все заголовки — обязательно строки. При попытке указать число, например {'aaa': 123}, запрос не будет отправлен и код выдаст исключение InvalidHeader
Для распределенного тестирования locust предоставляет несколько CLI аргументов: --master и --slave, для четкого определения ролей. При этом машина с master не будет симулировать нагрузку, а только собирать статистику и координировать работу. Давайте попробуем запустить наш тестовый сервер и несколько сессий в распределенном режиме, выполнив в разных консолях команды:
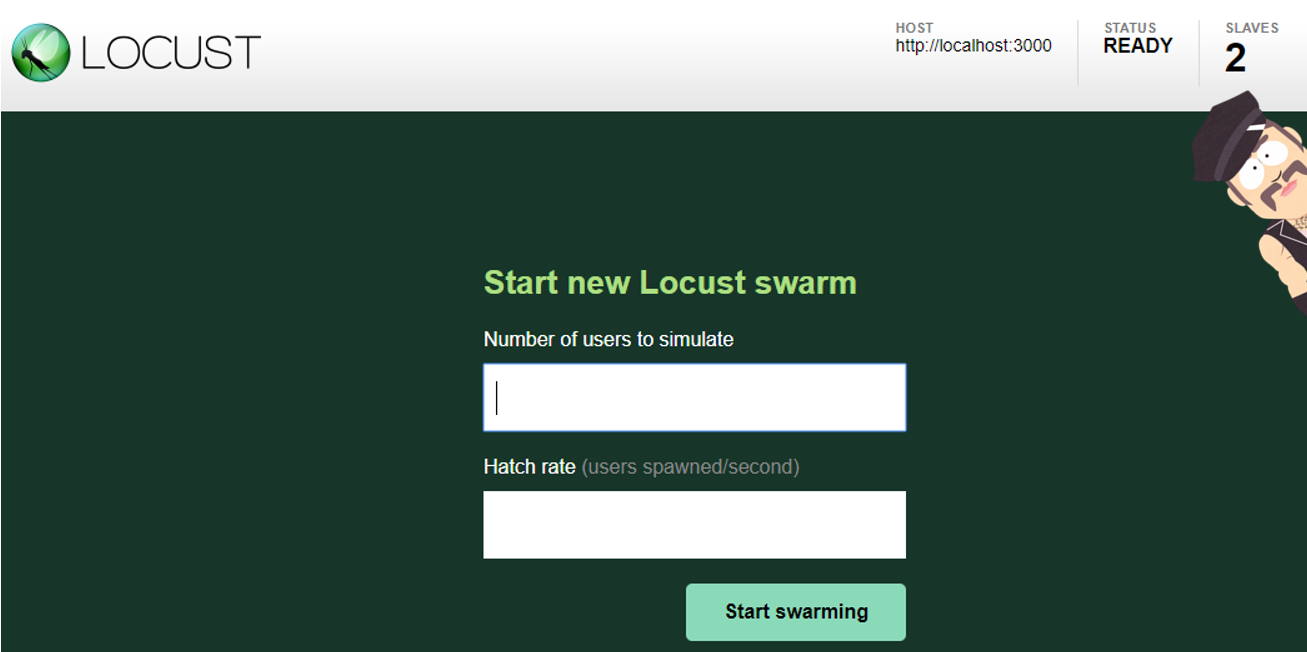
Открыв locust в браузере (localhost:8089), можно обратить внимание, что в правом верхнем углу у нас указано количество машин, которые будут проводить нагрузку
Когда все тесты написаны и отлажены, неплохо бы включить их в регрессионное автоматическое тестирование и просто периодически проверять результаты. С помощью следующей команды можно запустить тест locust без UI:
где
Распределенное тестирование можно комбинировать с регрессионным — для того, чтобы гарантировать, что все узлы для нагрузки стартовали, можно на master’е добавить аргумент --expect-slaves=2, в таком случае тест начнется, только когда будут запущены хотя бы 2 узла.
Пару раз сталкивался с ситуацией — тестируемый ресурс работает только по HTTPS, при этом сертификат сгенерирован заказчиком и операционная система помечает его как подозрительный. Чтобы тесты работали успешно, можно добавить во все запросы аргумент, игнорирующий проверку безопасности, например:
Так как я не всегда могу быть уверен, в какой среде будут запущены тесты, всегда указываю этот аргумент.
Вот и все, чем я хотел поделится. Для себя я открыл простой и удобный инструмент с большими возможностями по тестированию и вариативностью по созданию запросов и обработке ответов сервера. Спасибо, что дочитали до конца.
Часть 1 — тестирование с Locust
Часть 2 — продвинутые сценарии
Авторизация
При написании своих первых тестов с Locust, я столкнулся с необходимостью залогиниться на одном ресурсе, получив авторизационный токен, которой потом уже использовать при нагрузочном тестировании. Тут сразу встал вопрос — как это сделать, ведь инструмент заточен посылать все запросы на один ресурс, который мы указываем в консоли при запуске теста. Есть несколько вариантов решения проблемы:
- отключение авторизации на тестируемом ресурсе — если есть такая возможность
- сгенерировать токен заранее и подложить его в код теста до запуска — самый слабый вариант, требующий ручного труда при каждом запуске, но имеющий право на существование в некоторых редких случаях
- отправить запрос с помощью библиотеки requests и получить токен из ответа — благо, синтаксис тот же
Я выбрал третий вариант. Ниже предлагаю переделанный пример из первой статьи с разными возможностями получения токена. В качестве сервера авторизации выступит google.com и, так
как токена нет, буду получать самые простые значения
from locust import HttpLocust, TaskSet, task import requests class UserBehavior(TaskSet): def on_start(self): response = requests.post("http://mysite.sample.com/login", {"username": "ellen_key", "password": "education"}) # get "token" from response header self.client.headers.update({'Authorization': response.headers.get('Date')}) # get "token" from response cookies self.client.cookies.set('Authorization', response.cookies.get('NID')) # get "token" from response body self.client.headers.update({'Authorization': str(response.content.decode().find('google'))})
Как видно из примера, перед началом работы пользователь отправляет запрос на сторонний сервер и обрабатывает ответ, помещая данные в заголовки или куки.
Headers
При работе с заголовками запроса нужно учитывать несколько важных нюансов.
Для каждого отдельно запроса можно указать собственный набор заголовков следующим образом
self.client.post(url='/posts', data='hello world', headers={'hello': 'world'})
При выполнении указанного примера заголовок hello будет добавлен к уже существующим заголовкам клиентской сессии, но только в это запросе — во всех следующих его не будет. Чтобы сделать заголовок постоянным, можно добавить его в сессию:
self.client.headers.update({'aaa': 'bbb'})
Еще одно интересное наблюдение — если в запросе мы укажем заголовок, который уже есть в сессии — он будет перезаписан, но только на этот запрос. Так что можно не бояться случайно затереть что-то важное.
Но есть и исключения. Если нам потребуется отправить multipart форму, запрос автоматически сформирует заголовок Content-Type, в котором будет указан разделитель данных формы. Если же мы принудительно перезапишем заголовок с помощью аргумента headers, то запрос провалится, так как форма не сможет быть корректно обработана.
Так же стоит обратить внимание, что все заголовки — обязательно строки. При попытке указать число, например {'aaa': 123}, запрос не будет отправлен и код выдаст исключение InvalidHeader
Распределенное тестирование
Для распределенного тестирования locust предоставляет несколько CLI аргументов: --master и --slave, для четкого определения ролей. При этом машина с master не будет симулировать нагрузку, а только собирать статистику и координировать работу. Давайте попробуем запустить наш тестовый сервер и несколько сессий в распределенном режиме, выполнив в разных консолях команды:
json-server --watch sample_server/db.json locust -f locust_files\locust_file.py --master --host=http://localhost:3000 locust -f locust_files\locust_file.py --slave --master-host=localhost locust -f locust_files\locust_file.py --slave --master-host=localhost
Открыв locust в браузере (localhost:8089), можно обратить внимание, что в правом верхнем углу у нас указано количество машин, которые будут проводить нагрузку
Тестирование без UI
Когда все тесты написаны и отлажены, неплохо бы включить их в регрессионное автоматическое тестирование и просто периодически проверять результаты. С помощью следующей команды можно запустить тест locust без UI:
locust -f locust_files\locust_file.py --host=http://localhost:3000 --no-web -c 10 -r 2 --run-time 1m --csv=test_result
где
- --no-web — аргумент, позволяющий запускать тесты без UI
- -c 10 — максимальное количество пользователей
- -r 2 — прирост пользователей в секунду
- --run-time 1m — время выполнения теста (1 минута)
- --csv=test_result — после выполнения теста в текущей папке будет создано 2 csv файла c результатами, их имена начинаются с test_result
Финальные факты, наблюдения и выводы
Распределенное тестирование можно комбинировать с регрессионным — для того, чтобы гарантировать, что все узлы для нагрузки стартовали, можно на master’е добавить аргумент --expect-slaves=2, в таком случае тест начнется, только когда будут запущены хотя бы 2 узла.
Пару раз сталкивался с ситуацией — тестируемый ресурс работает только по HTTPS, при этом сертификат сгенерирован заказчиком и операционная система помечает его как подозрительный. Чтобы тесты работали успешно, можно добавить во все запросы аргумент, игнорирующий проверку безопасности, например:
self.client.get("/posts", verify=False)
Так как я не всегда могу быть уверен, в какой среде будут запущены тесты, всегда указываю этот аргумент.
Вот и все, чем я хотел поделится. Для себя я открыл простой и удобный инструмент с большими возможностями по тестированию и вариативностью по созданию запросов и обработке ответов сервера. Спасибо, что дочитали до конца.
