
Перед вами обновляемый список самых замечательных «вкусностей» Юникода, а также пакетов и ресурсов
Юникод — это потрясающе! До его появления международная коммуникация была изнурительной: каждый определял свой отдельный расширенный набор символов в верхней половине ASCII (так называемые кодовые страницы). Это порождало конфликты. Просто подумайте, что немцам приходилось договариваться с корейцами, где чья кодовая страница. К счастью, появился Юникод и ввёл общий стандарт. Юникод 8.0 охватывает более 120 000 символов из более 129 письменностей. И современные, и древние, и до сих пор не расшифрованные. Юникод поддерживает текст слева направо и справа налево, наложение символов и включает самые разные культурные, политические, религиозные символы и эмодзи. Юникод потрясающе человечен, а его возможности сильно недооцениваются.
Содержание
- Краткое введение
- Список удивительных символов
- Причуды и устранение неполадок
- Отличные пакеты и библиотеки
- Эмодзи
- Переменные и методы с креативными названиями
- Шрифты Юникода
- Дополнительные ресурсы
- Более глубокое исследование самого Юникода
- Общая карта
- Принципы Стандарта Юникод
- Версии Юникода
Краткое введение
Какие символы входят в Стандарт Юникод?
Стандарт Юникод определяет коды для символов основных современных языков. Это европейские алфавитные письменности, ближневосточные письменности справа налево и многие письменности Азии.
Стандарт также содержит знаки пунктуации, диакритические знаки, математические символы, технические символы, стрелки, дингбаты, эмодзи и т. д. Он предоставляет коды для диакритических знаков, изменяющих знаки символов, такие как тильда (~). Они используются в сочетании с основными для представления акцентированных символов (например, ñ). В целом, Юникод версии 9.0 предоставляет коды для 128 172 символов из мировых алфавитов, наборов идеограмм и коллекций символов.
Большинство символов общего пользования помещаются в первые 64K кодовых точек, область кодового пространства, которая называется основной многоязычной плоскостью, или BMP для краткости. Есть ещё шестнадцать других дополнительных плоскостей, доступных для кодирования других символов, с более чем 850 000 неиспользуемых кодовых точек. Они могут пригодиться для добавления новых символов в будущие версии стандарта.
Стандарт Юникод также резервирует кодовые точки для частного использования. Вендоры или конечные пользователи могут назначать их в своих собственных системах для своих символов или использовать со специализированными шрифтами. На BMP находится 6400 кодовых точек для частного использования и ещё 131 068 дополнительных кодовых точек частного использования, если 6400 недостаточно для конкретных приложений.
Кодировки символов Юникода
Стандарты кодирования символов определяют не только идентичность каждого символа и его числовое значение или кодовую точку, но и то, как это значение представлено в битах.
Стандарт Юникод определяет три формы кодирования, которые позволяют передавать одни и те же данные: это байт, слово и двойное слово (то есть 8, 16 или 32 бит на единицу кода). Все три формы кодируют один и тот же общий набор символов и могут быть эффективно преобразованы друг в друга без потери данных. Консорциум Юникод полностью одобряет использование любой из этих форм кодирования в качестве согласованного способа реализации Стандарта Юникод.
UTF-8 популярен для HTML и подобных протоколов. UTF-8 — это способ преобразования всех символов Юникода в кодировку переменной байтовой длины. Его преимущество в том, что символы Юникода, соответствующие знакомому набору ASCII, имеют те же байтовые значения, что и ASCII, а символы Юникода, преобразованные в UTF-8, могут использоваться с большим количеством существующего программного обеспечения без серьёзной доработки ПО.
UTF-16 популярен во многих средах, где необходимо сбалансировать эффективный доступ к символам с экономичным хранением. Он достаточно компактен, и все часто используемые символы помещаются в один 16-битный кодовый блок, в то время как все остальные символы доступны через пары 16-битных кодовых блоков.
UTF-32 полезен там, где объём памяти не вызывает беспокойства, но требуется доступ к символам по единому коду фиксированной ширины. Здесь каждый символ Юникода кодируется в одном 32-разрядном кодовом блоке.
Все три формы кодирования требуют для каждого символа не более 4 байт (или 32 бит).
Поговорим о цифрах
Набор символов Юникода разделён на 17 основных сегментов (плоскостей), которые далее делятся на блоки. В каждой плоскости есть место для 65 536 (216) кодовых точек, что создаёт в сумме 1 114 112 кодовых точек. Есть две «плоскости частного использования» (№ 16 и № 17), которые выделяются для использования на усмотрение компаний/пользователей. В них 131 072 кодовые точки.
| № | Название | Диапазон |
|---|---|---|
| 1. | Основная многоязычная плоскость | (от U+0000 до U+FFFF) |
| 2. | Дополнительная многоязычная плоскость | (от U+10000 до U+1FFFF) |
| 3. | Дополнительная идеографическая плоскость | (от U+20000 до U+2FFFF) |
| 4. | Третичная идеографическая плоскость | (от U+30000 до U+3FFFF) |
| 5. | Плоскость 5 (не используется) | (от U+40000 до U+4FFFF) |
| 6. | Плоскость 6 (не используется) | (от U+50000 до U+5FFFF) |
| 7. | Плоскость 7 (не используется) | (от U+60000 до U+6FFFF) |
| 8. | Плоскость 8 (не используется) | (от U+70000 до U+7FFFF) |
| 9. | Плоскость 9 (не используется) | (от U+80000 до U+8FFFF) |
| 10. | Плоскость 10 (не используется) | (от U+90000 до U+9FFFF) |
| 11. | Плоскость 11 (не используется) | (от U+A0000 до U+AFFFF) |
| 12. | Плоскость 12 (не используется) | (от U+B0000 до U+BFFFF) |
| 13. | Плоскость 13 (не используется) | (от U+C0000 до U+CFFFF) |
| 14. | Плоскость 14 (не используется) | (от U+D0000 до U+DFFFF) |
| 15. | Специализированная дополнительная плоскость | (от U+E0000 до U+EFFFF) |
| 16. | Дополнительная область для частного использования — A | (от U+F0000 до U+FFFFF) |
| 17. | Дополнительная область для частного использования — B | (от U+100000 до U+10FFFF) |
Первая плоскость называется основной многоязычной плоскостью или BMP. Она содержит кодовые точки от U+0000 до U+FFFF, то есть наиболее часто используемые символы. Остальные шестнадцать плоскостей (U+010000 → U+10FFFF) называются дополнительными или астральными.
Суррогатные пары UTF-16
Символы вне основной плоскости, как тетраграмматон, означающий центр (U+1D306), можно закодировать в UTF-16 только двумя 16-битными кодовыми единицами: 0xD834 0xDF06. Это называется суррогатной парой. Обратите внимание, что суррогатная пара представляет только один символ.
Первая кодовая единица суррогатной пары всегда находится в диапазоне от 0xD800 до 0xDBFF и называется верхней частью пары.
Вторая кодовая единица суррогатной пары всегда находится в диапазоне от 0xDC00 до 0xDFFF и называется нижней частью пары.
Матиас Байненс
Суррогатная пара: представление одного абстрактного символа, состоящего из последовательности двух 16-разрядных кодовых единиц, где первое значение пары является верхней суррогатной кодовой единицей, а второе — нижней суррогатной кодовой единицей. Суррогатные пары используются только в UTF-16.
Unicode 8.0 Глава 3.8 − Суррогаты
Вычисление суррогатных пар
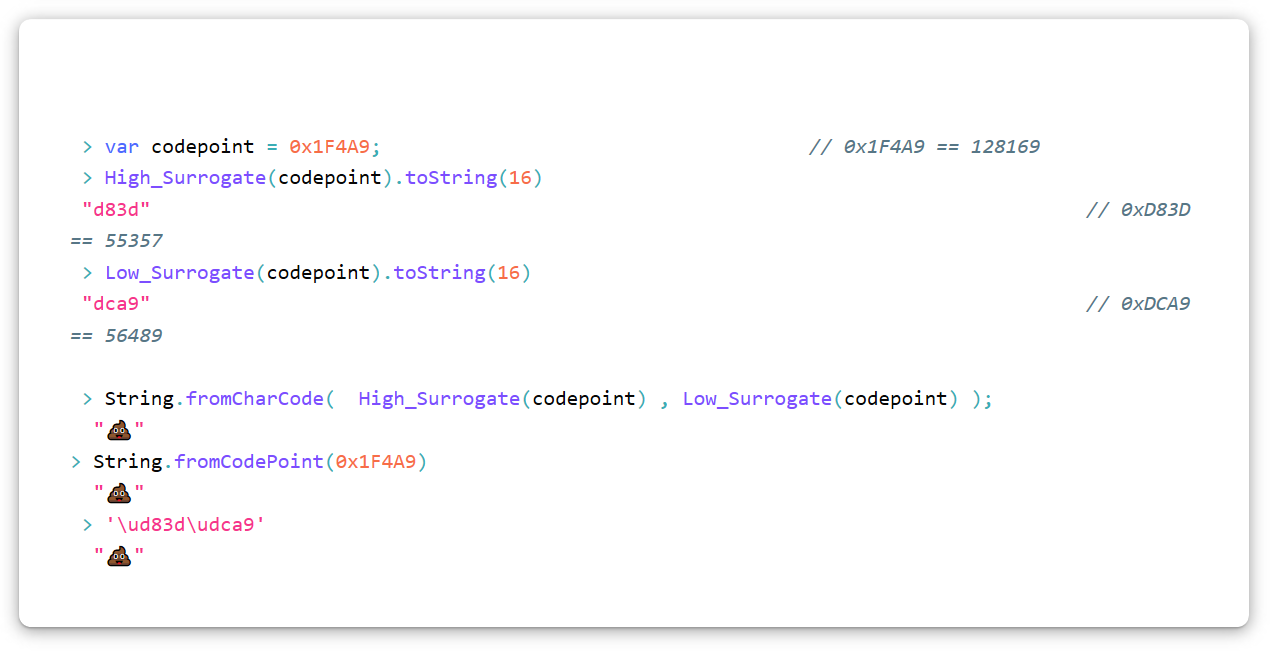
Юникодовский символ «Куча дерьма» (U+1F4A9) в UTF-16 придётся кодировать как суррогатную пару, т. е. два суррогата. Чтобы преобразовать любую кодовую точку в суррогатную пару, используйте такой алгоритм (на JavaScript). Имейте в виду, что мы используем шестнадцатеричную нотацию.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 };
var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
// Reverses The Conversion
var Code_Point = function(High_Surrogate, Low_Surrogate){
return (High_Surrogate - 0xD800) * 0x400 + Low_Surrogate - 0xDC00 + 0x10000;
};
Композиция и декомпозиция
Юникод включает в себя механизм для изменения формы символа, который значительно расширяет поддерживаемый набор глифов. Это касается комбинируемых диакритических знаков. Они вставляются после главного знака. На один и тот же знак можно наложить несколько комбинируемых диакритических знаков. Юникод также содержит предварительно составленные версии большинства таких комбинаций для нормального использования.
Некоторые последовательности символов также можно представить в виде одного символа, который называется предварительно составленным символом (precomposed character), он же составной символ (composite character). Например, символ [ü] можно закодировать как единственную кодовую точку U+00FC или как базовый символ U+0075 (u), за которым следует несамостоятельный знак U+0308 (¨). Стандарт Юникод кодирует составные символы для совместимости с установленными стандартами, такими как Latin 1, который включает в себя множество составных символов, таких как [ü] и [ñ].
Составные символы можно разложить для согласованности или анализа. Например, при сортировке имён по алфавиту символ [ü] можно разложить на [u], за которым следует несамостоятельный знак [¨]. После такой декомпозиции алгоритму проще работать с последовательностью символов. Это позволяет упростить сортировку в языках, где модификаторы символов не влияют на алфавитный порядок. Стандарт Юникод устанавливает порядок декомпозиции для всех составных символов. Он также определяет формы нормализации для обеспечения уникальных представлений символов.
Мифы о Юникоде
Из слайдов презентации Марка Дэвиса «Мифы Юникода».
- Юникод — это просто 16-битный код. — Некоторые ошибочно полагают, что Юникод — это просто 16-битный код, в котором каждый символ занимает 16 бит, и поэтому существует 65 536 возможных символов. На самом деле это не совсем так. Это самый распространённый миф о Юникоде, так что если вы тоже так думали раньше, не расстраивайтесь.
- Можно взять для своих нужд любую кодовую точку, которая не используется. — Нет. Когда-нибудь это место займёт другой символ. Вместо этого используйте плоскости для частного использования или области без символов в каждой плоскости, где по стандарту не будет никаких символов.
- Каждая кодовая точка Юникода представляет символ. — Нет. Есть много точек без символов (FFFE, FFFF, 1FFFE и др.) Кроме того, суррогатные кодовые точки, приватные и неиспользуемые кодовые точки, а также управляющие/форматирующие «символы» (RLM, ZWNJ и др.)
- В Юникоде заканчивается место. — Если бы оно заполнялось линейно, то закончилось бы в 2140 году. Но место не заполняется линейно. Планы на будущее см. здесь.
- Все знаки сопоставляются один к одному. — Нет. Возможны варианты:
- Один ко многим: (β → SS)
- С учётом контекста: (…Σ ←→ …ς и в то же время …ΣΤ… ←→ …στ…)
- С учётом локали: (I ←→ ı и в то же время İ ←→ i)
- Один ко многим: (β → SS)
Прикладные кодировки Юникода
| Тип кодирования | Пример |
|---|---|
| Объект HTML (десятичный) |  |
| Объект HTML (hex) | |
| Управляющий код URL | %F0%9F%96%96 |
| UTF-8 (hex) | 0xF0 0x9F 0x96 0x96 (f09f9696) |
| UTF-8 (бинарный) | 11110000:10011111:10010110:10010110 |
| UTF-16/UTF-16BE (hex) | 0xD83D 0xDD96 (d83ddd96) |
| UTF-16LE (hex) | 0x3DD8 0x96DD (3dd896dd) |
| UTF-32/UTF-32BE (hex) | 0x0001F596 (0001f596) |
| UTF-32LE (hex) | 0x96F50100 (96f50100) |
| Восьмеричная управляющая последовательность | \360\237\226\226 |
Исходный код
| Тип кодирования | Пример |
|---|---|
| JavaScript | \u1F596 |
| JSON | \u1F596 |
| C | \u1F596 |
| C++ | \u1F596 |
| Java | \u1F596 |
| Python | \u1F596 |
| Perl | \x{1F596} |
| Ruby | \u{1F596} |
| CSS | \01F596 |
Список удивительных символов

Совместный доступ к документу может быстро превратить редактирование в письменную рэп-битву, ведущуюся все более запутанной расстановкой управляющих от U+202a до U+202e
Специальные символы
Консорциум Unicode опубликовал диаграмму общей пунктуации, где можете найти более подробную информацию.
| Символ | Название | Описание |
|---|---|---|
'' |
U+FEFF Неразрывный пробел нулевой ширины (Byte Order Mark — BOM) | Обладает важным свойством однозначности при изменении порядка байтов. У него также нулевая ширина и невидимость. В неподходщем программном обеспечении (например, интерпретаторе PHP) это приводит к всевозможным примерам забавного поведения. |
'' |
'\uFFEF' Обратный BOM | Не приравнивается к символу, кроме начала текста. |
'' |
'\u200B' Неразрывное пространство нулевой ширины | Символ без внешнего вида и без эффекта, кроме предотвращения образования лигатур. |
' ' |
U+00A0 Неразрывный пробел | Заставляет соседние символы держаться вместе. Хорошо известен как в HTML. |
'' |
U+00AD Мягкий дефис | В HTML работает как пространство нулевой ширины, но при встрече с концом строки (и только в этом случае) показывает дефис. |
'' |
U+200D Знак нулевой ширины (с объединением) | Заставляет соединяться соседние символы (например, арабские символы или поддерживаемые эмодзи). Можно использовать для последовательно скомбинированных эмодзи. |
'' |
U+2060 Соединитель слов | То же самое, что и U+00A0, но совершенно невидимый. Хорошо подходит для @font-face в Twitter. |
' ' |
U+1680 Огам знак пробела | Отмечает пробел, который выглядит как тире. Отлично подходит, чтобы приблизить программистов к безумию: 1 + 2 === 3. |
';' |
U+037E Греческий знак вопроса | Похож на точку с запятой. Также забавный способ троллить разработчиков. |
'' |
U+202D | Изменяет направление текста слева-направо. |
'' |
U+202E | Изменяет направление текста справа-налево. |
'ꓸ' |
U+A4F8 Лису буква tone mya ti | Двойник для точки. |
'ꓹ' |
U+A4F9 Лису буква tone na po | Двойник для запятой. |
'ꓼ' |
U+A4FC Лису буква tone mya na | Двойник для точки с запятой. |
'ꓽ' |
U+A4FD Лису буква tone mya jeu | Двойник для двоеточия. |
'︀' |
Вариантные селекторы (от U+FE00 до U+FE0F и от U+E0100 до U+E01EF) | Блок из 256 символов нулевой ширины, которые обладают свойством ID_Continue, то есть могут использоваться в именах переменных (не первая буква). Что делает их особенными, так это то, что над ними проходит курсор мыши, поскольку они объединяют символы, в отличие от большинства других символов нулевой ширины. |
'ᅟ' |
U+115F Заполнитель хангыль чхосон | По сути, заполняет пространство. Визуализируется как символ нулевой ширины (невидимый), если явно не поддерживается при визуализации. Обозначен как ID_Start |
'ᅠ' |
U+1160 Заполнитель чунсон | Возможно, заполняет пространство? Визуализируется как символ нулевой ширины (невидимый), если явно не поддерживается при визуализации. Обозначен как ID_Start |
'ㅤ' |
U+3164 Заполнитель хангыль | В целом, заполняет пространство. Визуализируется как символ нулевой ширины (невидимый), если явно не поддерживается при визуализации. Обозначен как ID_Start |
Подожди… что я только что прочитал?
Идентификаторы переменных могут включать пробелы!
U+3164 Заполнитель хангыль отображается в виде широкого пробела. Если символ явно не поддерживается в рендеринге, то отображается как полностью невидимый (и не занимает место, т. е. «нулевой ширины»). Это означает, что вы никогда не увидите уродливый символ замены символов (�).
Я пока не уверен, почему U+3164 указано вести себя таким образом. Интересно, что U+3164 был добавлен в Юникод в версии 1.1 (1993) — так что у специалистов Консорциума было много времени, чтобы его продумать. Во всяком случае, вот несколько примеров.
> var ᅟ = 'foo';
undefined
> ᅟ
'foo'
> var ㅤ= alert;
undefined
> var foo = 'bar'
undefined
> if ( foo ===ㅤ`baz` ){} // alert
undefined
> var varㅤfooㅤ\u{A60C}ㅤπ = 'bar';
undefined
> varㅤfooㅤꘌㅤπ
'bar'**Примечание:** я тестировал рендеринг U+3164 на Ubuntu и OS X со следующими параметрами: `node`, `php`, `ruby`, `python3.5`, `scala`, `vim`, `cat`, `chrome`+`github gist'. Atom — единственная система, которая терпит неудачу, (некорректно) отображая пустые поля. Мне ещё предстоит проверить код в Emacs и Sublime. Насколько я понимаю, Консорциум Юникод не будет переназначать или переименовывать символы или кодовые точки, но его можно убедить изменить свойства символов, таких как ID_Start и ID_Continue.
Модификаторы
Объединитель нулевой ширины (ZWJ) является непечатным символом в компьютерном наборе некоторых сложных шрифтов, таких как арабский или любой индийский шрифт. При помещении между двумя символами, которые в противном случае не были бы связаны, ZWJ заставляет их печататься в объединённой форме.
Разъединитель нулевой ширины (ZWNJ) — это непечатный символ в компьютерных наборах письменностей с лигатурами. При размещении между двумя символами, которые в противном случае были бы соединены в лигатуру, ZWNJ заставляет их печататься в их окончательной и первоначальной формах, соответственно. Действует как пробел, но используется в том случае, когда желательно удерживать слова рядом друг с другом или соединить слово с его морфемой.
> 'a'
"a"
> 'a\u{0308}'
"ä"
> 'a\u{20DE}\u{0308}'
"a⃞̈"
> 'a\u{20DE}\u{0308}\u{20DD}'
"a⃞̈⃝"
// Modifying Invisible Characters
> '\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}'
""
> '\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}'.length
10Коллизии преобразований в верхнем регистре
| Символ | Кодовая точка | Результат |
|---|---|---|
| ß | 0x00DF | SS |
| ı | 0x0131 | I |
| ſ | 0x017F | S |
| ff | 0xFB00 | FF |
| fi | 0xFB01 | FI |
| fl | 0xFB02 | FL |
| ffi | 0xFB03 | FFI |
| ffl | 0xFB04 | FFL |
| ſt | 0xFB05 | ST |
| st | 0xFB06 | ST |
Коллизии преобразований в нижнем регистре
| Символ | Кодовая точка | Результат |
|---|---|---|
| K | 0x212A | k |
Причуды и устранение неполадок
- Длина строки обычно определяется по количеству кодовых точек. Это означает, что суррогатные пары будут считаться двумя символами. На символ может быть наложено нескольких диакритических знаков:
a + ̈ == ̈a. Это увеличивает длину строки, производя только один символ.
- Аналогично, обращение строки часто становится нетривиальной задачей. Опять же, суррогатные пары и диакритические знаки следует обращать вместе. ES Reverser предлагает довольно хорошее решение.
- Сопоставления верхнего и нижнего регистра не всегда совпадают. Они могут выражаться и такими отношениями:
- Один ко многим: (ß → SS )
- С учётом контекста: (…Σ ←→ …ς и …ΣΤ… ←→ …στ… )
- С учётом локали: ( I ←→ ı и İ ←→ i )
Сопоставления одного ко многим
Большинство нижеприведенных символов выражают свои сопоставления «один ко многим» в верхнем регистре, а другие в нижнем. В принципе, список можно разделить на две части.
Кодовая точка Символ Название Сопоставленный символ Сопоставленные кодовые точки U+00DF ßЛатинская строчная буква эсцет (S острое) s,sU+0073, U+0073 U+0130 İЛатинская заглавная буква «I» с точкой сверху i,̇U+0069, U+0307 U+0149 ʼnЛатинская строчная буква «n» предшествующим апострофом ʼ,nU+02BC, U+006E U+01F0 ǰЛатинская строчная буква «j» с гачеком j,̌U+006A, U+030C U+0390 ΐГреческая строчная буква йота с диалитика и тонос ι,̈,́U+03B9, U+0308, U+0301 U+03B0 ΰГреческая строчная буква ипсилон с диалитика и тонос υ,̈,́U+03C5, U+0308, U+0301 U+0587 ևАрмянская строчная лигатура ech yiwn ե,ւU+0565, U+0582 U+1E96 ẖЛатинская строчная буква h с линией снизу h,̱U+0068, U+0331 U+1E97 ẗЛатинская строчная буква t с диэрезисом t,̈U+0074, U+0308 U+1E98 ẘЛатинская строчная буква w с кольцом выше w,̊U+0077, U+030A U+1E99 ẙЛатинская строчная буква y с кольцом выше y,̊U+0079, U+030A U+1E9A ẚЛатинская строчная буква a с правой половинкой кольца a,ʾU+0061, U+02BE U+1E9E ẞЛатинская заглавная буква острая s s,sU+0073, U+0073 U+1F50 ὐГреческая строчная буква ипсилон с псили υ,̓U+03C5, U+0313 U+1F52 ὒГреческая строчная буква ипсилон с псили и вария υ,̓,̀U+03C5, U+0313, U+0300 U+1F54 ὔГреческая строчная буква ипсилон с псили и оксия υ,̓,́U+03C5, U+0313, U+0301 U+1F56 ὖГреческая строчная буква ипсилон с псили и периспоменти υ,̓,͂U+03C5, U+0313, U+0342 U+1F80 ᾀГреческая строчная буква альфа с псили и ипогеграммены ἀ,ιU+1F00, U+03B9 U+1F81 ᾁГреческая строчная буква альфа с дасия и ипогеграммены ἁ,ιU+1F01, U+03B9 U+1F82 ᾂГреческая строчная буква альфа с псили и вария и ипогеграммены ἂ,ιU+1F02, U+03B9 U+1F83 ᾃГреческая строчная буква альфа с дасия и вария и ипогеграммены ἃ,ιU+1F03, U+03B9 U+1F84 ᾄГреческая строчная буква альфа с псили и оксия и ипогеграммены ἄ,ιU+1F04, U+03B9 U+1F85 ᾅГреческая строчная буква альфа с дасия и оксия и ипогеграммены ἅ,ιU+1F05, U+03B9 U+1F86 ᾆГреческая строчная буква альфа с псили и периспоменти и ипогеграммены ἆ,ιU+1F06, U+03B9 U+1F87 ᾇГреческая строчная буква альфа с дасия и периспоменти и ипогеграммены ἇ,ιU+1F07, U+03B9 U+1F88 ᾈГреческая заглавная буква альфа с псили и просгеграммены ἀ,ιU+1F00, U+03B9 U+1F89 ᾉГреческая заглавная буква альфа с дасия и просгеграммены ἁ,ιU+1F01, U+03B9 U+1F8A ᾊГреческая заглавная буква альфа с псили и вария и просгеграммены ἂ,ιU+1F02, U+03B9 U+1F8B ᾋГреческая заглавная буква альфа с дасия и вария и просгеграммены ἃ,ιU+1F03, U+03B9 U+1F8C ᾌГреческая заглавная буква альфа с псили и оксия и просгеграммены ἄ,ιU+1F04, U+03B9 U+1F8D ᾍГреческая заглавная буква альфа с дасия и оксия и просгеграммены ἅ,ιU+1F05, U+03B9 U+1F8E ᾎГреческая заглавная буква альфа с псили и периспоменти и просгеграммены ἆ,ιU+1F06, U+03B9 U+1F8F ᾏГреческая заглавная буква альфа с дасия и периспоменти и просгеграммены ἇ,ιU+1F07, U+03B9 U+1F90 ᾐГреческая строчная буква эта с псили и ипогеграммены ἠ,ιU+1F20, U+03B9 U+1F91 ᾑГреческая строчная буква эта с дасия и ипогеграммены ἡ,ιU+1F21, U+03B9 U+1F92 ᾒГреческая строчная буква эта с псили и вария и ипогеграммены ἢ,ιU+1F22, U+03B9 U+1F93 ᾓГреческая строчная буква эта с дасия и вария и ипогеграммены ἣ,ιU+1F23, U+03B9 U+1F94 ᾔГреческая строчная буква эта с псили и оксия и ипогеграммены ἤ,ιU+1F24, U+03B9 U+1F95 ᾕГреческая строчная буква эта с дасия и оксия и ипогеграммены ἥ,ιU+1F25, U+03B9 U+1F96 ᾖГреческая строчная буква эта с псили и периспоменти и ипогеграммены ἦ,ιU+1F26, U+03B9 U+1F97 ᾗГреческая строчная буква эта с дасия и периспоменти и ипогеграммены ἧ,ιU+1F27, U+03B9 U+1F98 ᾘГреческая заглавная буква эта с псили и просгеграммены ἠ,ιU+1F20, U+03B9 U+1F99 ᾙГреческая заглавная буква эта с дасия и просгеграммены ἡ,ιU+1F21, U+03B9 U+1F9A ᾚГреческая заглавная буква эта с псили и вария и просгеграммены ἢ,ιU+1F22, U+03B9 U+1F9B ᾛГреческая заглавная буква эта с дасия и вария и просгеграммены ἣ,ιU+1F23, U+03B9 U+1F9C ᾜГреческая заглавная буква эта с псили и оксия и просгеграммены ἤ,ιU+1F24, U+03B9 U+1F9D ᾝГреческая заглавная буква эта с дасия и оксия и просгеграммены ἥ,ιU+1F25, U+03B9 U+1F9E ᾞГреческая заглавная буква эта с псили и периспоменти и просгеграммены ἦ,ιU+1F26, U+03B9 U+1F9F ᾟГреческая заглавная буква эта с дасия и периспоменти и просгеграммены ἧ,ιU+1F27, U+03B9 U+1FA0 ᾠГреческая строчная буква омега с псили и ипогеграммены ὠ,ιU+1F60, U+03B9 U+1FA1 ᾡГреческая строчная буква омега с дасия и ипогеграммены ὡ,ιU+1F61, U+03B9 U+1FA2 ᾢГреческая строчная буква омега с псили и вария и ипогеграммены ὢ,ιU+1F62, U+03B9 U+1FA3 ᾣГреческая строчная буква омега с дасия и вария и ипогеграммены ὣ,ιU+1F63, U+03B9 U+1FA4 ᾤГреческая строчная буква омега с псили и оксия и ипогеграммены ὤ,ιU+1F64, U+03B9 U+1FA5 ᾥГреческая строчная буква омега с дасия и оксия и ипогеграммены ὥ,ιU+1F65, U+03B9 U+1FA6 ᾦГреческая строчная буква омега с псили и периспоменти и ипогеграммены ὦ,ιU+1F66, U+03B9 U+1FA7 ᾧГреческая строчная буква омега с дасия и периспоменти и ипогеграммены ὧ,ιU+1F67, U+03B9 U+1FA8 ᾨГреческая заглавная буква омега с псили и просгеграммены ὠ,ιU+1F60, U+03B9 U+1FA9 ᾩГреческая заглавная буква омега с дасия и просгеграммены ὡ,ιU+1F61, U+03B9 U+1FAA ᾪГреческая заглавная буква омега с псили и вария и просгеграммены ὢ,ιU+1F62, U+03B9 U+1FAB ᾫГреческая заглавная буква омега с дасия и вария и просгеграммены ὣ,ιU+1F63, U+03B9 U+1FAC ᾬГреческая заглавная буква омега с псили и оксия и просгеграммены ὤ,ιU+1F64, U+03B9 U+1FAD ᾭГреческая заглавная буква омега с дасия и оксия и просгеграммены ὥ,ιU+1F65, U+03B9 U+1FAE ᾮГреческая заглавная буква омега с псили и периспоменти и просгеграммены ὦ,ιU+1F66, U+03B9 U+1FAF ᾯГреческая заглавная буква омега с дасия и периспоменти и просгеграммены ὧ,ιU+1F67, U+03B9 U+1FB2 ᾲГреческая строчная буква альфа с вария и ипогеграммены ὰ,ιU+1F70, U+03B9 U+1FB3 ᾳГреческая строчная буква альфа с ипогеграммены α,ιU+03B1, U+03B9 U+1FB4 ᾴГреческая строчная буква альфа с оксия и ипогеграммены ά,ιU+03AC, U+03B9 U+1FB6 ᾶГреческая строчная буква альфа с периспоменти α,͂U+03B1, U+0342 U+1FB7 ᾷГреческая строчная буква альфа с периспоменти и ипогеграммены α,͂,ιU+03B1, U+0342, U+03B9 U+1FBC ᾼГреческая заглавная буква альфа с просгеграммены α,ιU+03B1, U+03B9 U+1FC2 ῂГреческая строчная буква эта с вария и ипогеграммены ὴ,ιU+1F74, U+03B9 U+1FC3 ῃГреческая строчная буква эта с ипогеграммены η,ιU+03B7, U+03B9 U+1FC4 ῄГреческая строчная буква эта с оксия и ипогеграммены ή,ιU+03AE, U+03B9 U+1FC6 ῆГреческая строчная буква эта с периспоменти η,͂U+03B7, U+0342 U+1FC7 ῇГреческая строчная буква эта с периспоменти и ипогеграммены η,͂,ιU+03B7, U+0342, U+03B9 U+1FCC ῌГреческая заглавная буква эта с просгеграммены η,ιU+03B7, U+03B9 U+1FD2 ῒГреческая строчная буква йота с диалитика и вария ι,̈,̀U+03B9, U+0308, U+0300 U+1FD3 ΐГреческая строчная буква йота с диалитика и оксия ι,̈,́U+03B9, U+0308, U+0301 U+1FD6 ῖГреческая строчная буква йота с периспоменти ι,͂U+03B9, U+0342 U+1FD7 ῗГреческая строчная буква йота с диалитика и периспоменти ι,̈,͂U+03B9, U+0308, U+0342 U+1FE2 ῢГреческая строчная буква ипсилон с диалитика и вария υ,̈,̀U+03C5, U+0308, U+0300 U+1FE3 ΰГреческая строчная буква ипсилон с диалитика и оксия υ,̈,́U+03C5, U+0308, U+0301 U+1FE4 ῤГреческая строчная буква rho с псили ρ,̓U+03C1, U+0313 U+1FE6 ῦГреческая строчная буква ипсилон с периспоменти υ,͂U+03C5, U+0342 U+1FE7 ῧГреческая строчная буква ипсилон с диалитика и периспоменти υ,̈,͂U+03C5, U+0308, U+0342 U+1FF2 ῲГреческая строчная буква омега с вария и ипогеграммены ὼ,ιU+1F7C, U+03B9 U+1FF3 ῳГреческая строчная буква омега с ипогеграммены ω,ιU+03C9, U+03B9 U+1FF4 ῴГреческая строчная буква омега с оксия и ипогеграммены ώ,ιU+03CE, U+03B9 U+1FF6 ῶГреческая строчная буква омега с периспоменти ω,͂U+03C9, U+0342 U+1FF7 ῷГреческая строчная буква омега с периспоменти и ипогеграммены ω,͂,ιU+03C9, U+0342, U+03B9 U+1FFC ῼГреческая заглавная буква омега с просгеграммены ω,ιU+03C9, U+03B9 U+FB00 ffЛатинская строчная лигатура Ff f,fU+0066, U+0066 U+FB01 fiЛатинская строчная лигатура Fi f,iU+0066, U+0069 U+FB02 flЛатинская строчная лигатура Fl f,lU+0066, U+006C U+FB03 ffiЛатинская строчная лигатура Ffi f,f,iU+0066, U+0066, U+0069 U+FB04 fflЛатинская строчная лигатура Ffl f,f,lU+0066, U+0066, U+006C U+FB05 ſtЛатинская строчная лигатура длинная S T s,tU+0073, U+0074 U+FB06 stЛатинская строчная лигатура St s,tU+0073, U+0074 U+FB13 ﬓАрмянская строчная лигатура Men Now մ,նU+0574, U+0576 U+FB14 ﬔАрмянская строчная лигатура Men Ech մ,եU+0574, U+0565 U+FB15 ﬕАрмянская строчная лигатура Men Ini մ,իU+0574, U+056B U+FB16 ﬖАрмянская строчная лигатура Vew Now վ,նU+057E, U+0576 U+FB17 ﬗАрмянская строчная лигатура Men Xeh մ,խU+0574, U+056D
Отличные пакеты и библиотеки
- PhantomScript — :ghost: :flashlight: Выполнение невидимого JavaScript и социальная инженерия
- ESReverser — Обращение строк на JavaScript с учётом Юникода.
- mimic — Некорректное использование Юникода
- python-ftfy — Пытается создать максимальную корректное и цельное представление текста, поступившего в Юникоде.
- vim-troll-stopper — Защита вашего кода от юникод-троллей.
Эмодзи
- Диаграмма эмодзи от Консорциума Юникод
- Emojipedia — Информация о конкретном эмодзи, новостной блог.
- emojitracker — Использование эмодзи в реальном времени в Twitter.
- World Translation Foundation — Исследование, продвижение, а также словарь эмодзи.
- Can I Emoji? — Отображает текущее состояние нативной поддержки эмодзи в iOS, Android и Windows.
- Как зарегистрировать доменное имя с эмодзи
Многообразие
Консорциум Unicode приложил огромные усилия для лучшего отражения человеческого многообразия (diversity), включая культурные практики. Вот отчёт Консорциума о многообразии.
Теперь доступны эмодзи для разных гендерных ситуаций, включая однополые семьи, держащиеся руки и поцелуи. Последний функционал — это составные последовательности эмодзи. Основные примеры:
Кодовые точки Рецепт Сочетание U+1F469 U+200D U+2764 U+FE0F U+200D U+1F469 


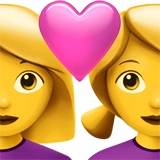
U+1F468 U+200D U+1F468 U+200D U+1F467 U+200D U+1F466 

Кроме того, эмодзи теперь поддерживают модификаторы цвета кожи.
В Юникоде версии 8.0 (середина 2015 года) появилось пять символов-модификаторов символов для оттенков человеческой кожи. Эти символы основаны на шести оттенках по шкале Фицпатрика, признанного стандарта в дерматологии (в интернете много примеров этой шкалы, таких как FitzpatrickSkinType.pdf). Точные оттенки зависят от реализации.
Отчёт Консорциума Unicode о многообразии
Код Название Примеры U+1F3FB Модификатор эмодзи для шкалы Фицпатрика типы-1-2 

U+1F3FC Модификатор эмодзи для шкалы Фицпатрика тип-3 

U+1F3FD Модификатор эмодзи для шкалы Фицпатрика тип-4 

U+1F3FE Модификатор эмодзи для шкалы Фицпатрика тип-5 

U+1F3FF Модификатор эмодзи для шкалы Фицпатрика тип-6 

Просто выбирайте нужный эмодзи, указав один из модификаторов цвета кожи\u{1F466}\u{1F3FE}.

+
→


Переменные и методы с креативными названиями
Примеры на JavaScript (ES6)
Обычно символы, обозначенные свойством ID_START, можно ставить в начале названия переменной. Символы, обозначенные свойством ID_CONTINUE, можно ставить после первого символа в имени переменной.
// How convenient! var π = Math.PI; // Sometimes, you just have to use the Bad Parts of JavaScript: var ಠ_ಠ = eval; // Code, Y U NO WORK?! var ლ_ಠ益ಠ_ლ = 42; // How about a JavaScript library for functional programming? var λ = function() {}; // Obfuscate boring variable names for great justice var \u006C\u006F\u006C\u0077\u0061\u0074 = 'heh'; // …or just make up random ones var Ꙭൽↈⴱ = 'huh'; // While perfectly valid, this doesn’t work in most browsers: var foo\u200Cbar = 42; // This is *not* a bitwise left shift (`<<`): var 〱〱 = 2; // This is, though: 〱〱 << 〱〱; // 8 // Give yourself a discount: var price_9̶9̶_89 = 'cheap'; // Fun with Roman numerals var Ⅳ = 4; var Ⅴ = 5; Ⅳ + Ⅴ; // 9 // Cthulhu was here var Hͫ̆̒̐ͣ̊̄ͯ͗͏̵̗̻̰̠̬͝ͅE̴̷̬͎̱̘͇͍̾ͦ͊͒͊̓̓̐_̫̠̱̩̭̤͈̑̎̋ͮͩ̒͑̾͋͘Ç̳͕̯̭̱̲̣̠̜͋̍O̴̦̗̯̹̼ͭ̐ͨ̊̈͘͠M̶̝̠̭̭̤̻͓͑̓̊ͣͤ̎͟͠E̢̞̮̹͍̞̳̣ͣͪ͐̈T̡̯̳̭̜̠͕͌̈́̽̿ͤ̿̅̑Ḧ̱̱̺̰̳̹̘̰́̏ͪ̂̽͂̀͠ = 'Zalgo';
А вот некоторые юникодовские классы CSS от Дэвида Уолша.
<!-- place this within the document head --> <meta charset="UTF-8" /> <!-- error message --> <div class="ಠ_ಠ">You do not have access to this page.</div> <!-- success message --> <div class="">Your changes have been saved successfully!</div>
.ಠ_ಠ { border: 1px solid #f00; } . { background: lightgreen; }
Скрипт рекурсивного переименования тегов HTML
Если вы хотите переименовать все свои HTML-теги в нечто невидимое, вот скрипт, который вам нужен.
Только обратите внимание, что HTML поддерживает не все символы Юникода.
// U+1160 HANGUL JUNGSEONG FILLER transformAllTags('ᅠ'); // An actual HTML element node designed to look like a comment node, using the U+01C3 LATIN LETTER RETROFLEX CLICK // <ǃ-- name="viewport" content="width=device-width"></ǃ--> transformAllTags('ǃ--'); // or even <ᅠ⃝ transformAllTags('\u{1160}\u{20dd}'); // and for a bonus, all existing tag names will have each character ensquared. h⃞t⃞m⃞l⃞ transformAllTags(); function transformAllTags (newName){ // querySelectorAll doesn't actually return an array. Array.from(document.querySelectorAll('*')) .forEach(function(x){ transformTag(x, newName); }); } function wonky(str){ return str.split('').join('\u{20de}') + '\u{20de}'; } function transformTag(tagIdOrElem, tagType){ var elem = (tagIdOrElem instanceof HTMLElement) ? tagIdOrElem : document.getElementById(tagIdOrElem); if(!elem || !(elem instanceof HTMLElement))return; var children = elem.childNodes; var parent = elem.parentNode; var newNode = document.createElement(tagType||wonky(elem.tagName)); for(var a=0;a<elem.attributes.length;a++){ newNode.setAttribute(elem.attributes[a].nodeName, elem.attributes[a].value); } for(var i= 0,clen=children.length;i<clen;i++){ newNode.appendChild(children[0]); //0...always point to the first non-moved element } newNode.style.cssText = elem.style.cssText; parent.replaceChild(newNode,elem); }
Вот что он поддерживает:
function testBegin(str){ try{ eval(`document.createElement( '${str}' );`) return true; } catch(e){ return false; } } function testContinue(str){ try{ eval(`document.createElement( 'a${str}' );`) return true; } catch(e){ return false; } }
А вот некоторые результаты:
// Test if dashes can start an HTML Tag > testBegin('-') < false > testContinue('-') < true > testBegin('ᅠ-') // Prepend dash with U+1160 HANGUL JUNGSEONG FILLER < true
Шрифты Юникода
Ни один шрифт TrueType или OpenType не способен охватить все символы UTF-8, поскольку есть жёсткое ограничение на 65 535 символов в шрифте. Если у нас более 1,1 миллиона глифов UTF-8, то для полного покрытия придётся делать семейство шрифтов.
Дополнительные ресурсы
- «Абсолютный минимум, который каждый разработчик должен обязательно, совершенно точно знать о Юникоде и наборах символов» — Джоэл Спольски
- «Что каждый программист обязательно, совершенно точно должен знать о кодировках и наборах символов для работы с текстом»
- Список рекомендованной литературы от Консорциума Юникод
- Space Yourself — руководство по интервалам от Smashing Magazine
- «У JavaScript проблема Юникода»
- Креативные юзернеймы и захват учётной записи Spotify
Более глубокое исследование самого Юникода
- Shapecatcher — нарисуйте символ, который вы ищете.
- Похожие символы Юникода
- База данных символов Юникода
- Дампы базы Codepoints.net
- Список блоков в пространстве Юникода
- Таблицы символов Юникода
- Таблицы регистров в Юникоде
- Таблица нормализации для Юникода
- FAQ по Юникоду
Общая карта
Карта основной многоязычной плоскости
Каждое нумерованное поле представляет собой 256 кодовых точек.
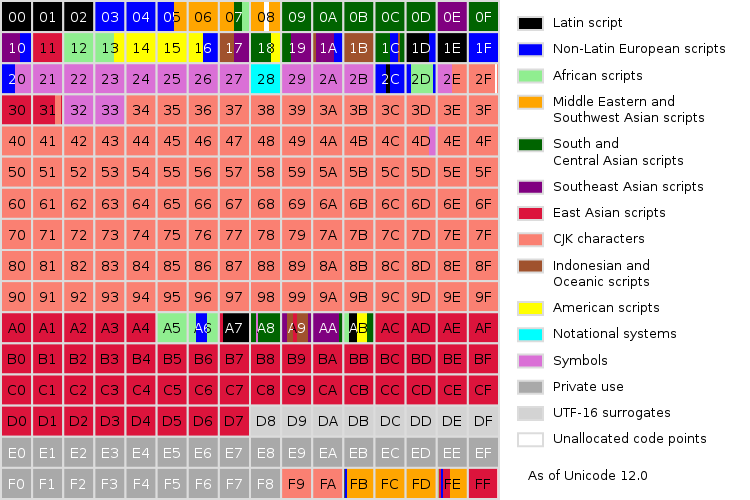
Китайские, японские и корейские (ККЯ) письменности объединены одним цветом как символы ККЯ (CJK). В процессе, который называется унификацией Хань, распознаются общие символы и составляется список «унифицированных идеограмм ККЯ».
Блоки Юникода
Стандарт Юникод объединяет группы символов в блоки. Вот полный список блоков по всем 17-ти плоскостям.
Принципы Стандарта Юникод
Стандарт Юникод устанавливает следующие фундаментальные принципы:
- Универсальность — каждую когда-либо используемую письменную систему следует уважать и представить в стандарте.
- Логический порядок — в двунаправленном тексте символы хранятся в логическом порядке, а не в соответствии с представлением.
- Эффективность — документация должна быть эффективной и полной.
- Унификация — если разные культуры или языки используют один и тот же символ, он должен быть включен только один раз. Это ведёт к следующему пункту.
- Символы, а не глифы — кодируются только символы, а не глифы. В двух словах, глифы являются фактической графической репрезентацией.
- Динамическая композиция — новые символы могут быть составлены из других, уже стандартизированных символов. Например, символ [Ä] может состоять из символа [A] и символа диерезиса [¨].
- Семантика — включённые символы должны быть чётко определены и отличаться от других.
- Стабильность — однажды определённые, символы никогда не будут удалены, а их кодовые точки никогда не будут переназначены. В случае ошибки кодовая точка считается устаревшей.
- Обычный текст — символы в стандарте являются текстом, они никогда не могут быть разметкой или метасимволами.
- Конвертируемость — любая другая используемая кодировка должна иметь возможность быть представленной в терминах кодировки Юникода.
Источник: описание принципов c codepoints.net.
Версии Юникода
- Версия 11.0 (черновик)
- Версия 10.0 (последняя версия, опубликована 20.06.2017 г.)
- Версия 9.0
- Версия 8.0
- Версия 7.0
- Версия 6.3
- Версия 6.2
- Версия 6.1
- Версия 6.0
- Версия 5.2
- Версия 5.1
- Версия 5.0 (недоступна)
- Версия 4.0.1
- Версия 4.0
