Занимаясь программированием рендеринга графики, мы живём в мире, в котором обязательны низкоуровневые оптимизации, чтобы добиться GPU-фреймов длиной 30 мс. Для этого мы используем различные методики и разработанные с нуля новые проходы рендеринга с повышенной производительностью (атрибуты геометрии, текстурный кеш, экспорт и так далее), GPR-сжатие, скрывание задержки (latency hiding), ROP…
В сфере повышения производительности CPU в своё время применялись разные трюки, и примечательно то, что сегодня они используются для современных видеокарт ради ускорения вычислений
ALU (
Низкоуровневая оптимизация для AMD GCN,
Быстрый обратный квадратный корень в Quake).
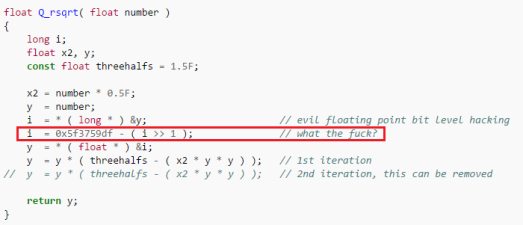 Быстрый обратный квадратный корень в Quake
Быстрый обратный квадратный корень в Quake
Но в последнее время, особенно в свете перехода на 64 бита, я заметил рост количества неоптимизированного кода, словно в индустрии стремительно теряются все накопленные ранее знания. Да, старые трюки вроде быстрого обратного квадратного корня на современных процессорах контрпродуктивны. Но программисты не должны забывать о низкоуровневых оптимизациях и надеяться, что компиляторы решат все их проблемы.
Не решат.
Эта статья — не исчерпывающее хардкорное руководство по железу. Это всего лишь введение, напоминание, свод базовых принципов написания эффективного кода для CPU. Я хочу «
показать, что низкоуровневое мышление сегодня всё ещё полезно»,
даже если речь пойдёт о процессорах, которые я мог бы добавить.
В статье мы рассмотрим кеширование, векторное программирование, чтение и понимание ассемблерного кода, а также написание кода, удобного для компилятора.