
Зачем нужен алгоритм Хо-Кашьяпа?
4 min
Недавно на Хабре появилась публикация про алгоритм Хо-Кашьяпа (Ho-Kashyap procedure, он же — алгоритм НСКО, наименьшей среднеквадратичной ошибки). Мне она показалась не очень понятной и я решил разобраться в теме сам. Выяснилось, что в русскоязычном интернете тема не очень хорошо разобрана, поэтому я решил оформить статью по итогам поисков.
Несмотря на бум нейросетей в машинном обучении, алгоритмы линейной классификации остаются гораздо более простыми в использовании и интерпретации. Но при этом иногда вовсе не хочется пользоваться сколько-нибудь продвинутыми методами, вроде метода опорных векторов или логистической регрессии и возникает искушение загнать все данные в одну большую линейную МНК-регрессию, тем более её прекрасно умеет строить даже MS Excel.
Проблема такого подхода в том, что даже если входные данные линейно разделимы, то получившийся классификатор может их не разделять. Например, для набора точек![X = [(6, 9), (5, 7), (5, 9), (10, 1)]](https://tex.s2cms.ru/svg/%20X%20%3D%20%5B(6%2C%209)%2C%20(5%2C%207)%2C%20(5%2C%209)%2C%20(10%2C%201)%5D%20) ,
, ![y = [1, 1, -1, -1]](https://tex.s2cms.ru/svg/%20y%20%3D%20%5B1%2C%201%2C%20-1%2C%20-1%5D%20) получим разделяющую прямую
получим разделяющую прямую %20%3D%200%20) (пример позаимствован из (1)):
(пример позаимствован из (1)):
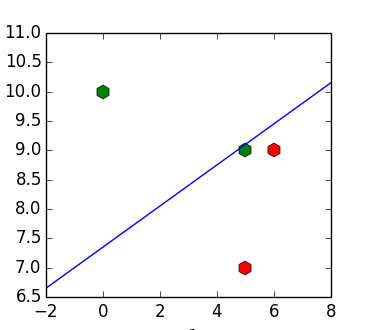
Встаёт вопрос — можно ли как-то избавиться от этой особенности поведения?
Несмотря на бум нейросетей в машинном обучении, алгоритмы линейной классификации остаются гораздо более простыми в использовании и интерпретации. Но при этом иногда вовсе не хочется пользоваться сколько-нибудь продвинутыми методами, вроде метода опорных векторов или логистической регрессии и возникает искушение загнать все данные в одну большую линейную МНК-регрессию, тем более её прекрасно умеет строить даже MS Excel.
Проблема такого подхода в том, что даже если входные данные линейно разделимы, то получившийся классификатор может их не разделять. Например, для набора точек
Встаёт вопрос — можно ли как-то избавиться от этой особенности поведения?