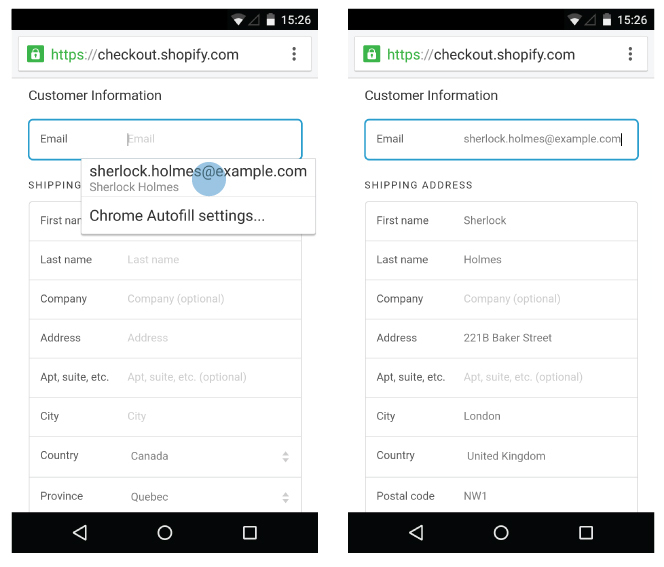
Профилирование JS-кода из функций. Опыт Яндекса
Последние полгода всем знакомый интерфейс поисковой выдачи Яндекса (Search Engine Result Page — SERP) переезжает на новую архитектуру, с которой разработка неспецифичных фич становится очень быстрой, а разработка специфичных фич — прогнозируемой. Для большой распределенной команды из 40 фронтендеров это большой успех. Когда все было почти готово и новый код начали обкатывать в production экспериментах, оказалось, что серверная JS-шаблонизация в новой архитектуре ощутимо замедлилась.

Новый код был проще и логичнее скомпонован, поэтому замедление было не только нежелательным, но и неожиданным. Чтобы получить «зеленый свет» для новой архитектуры, нужно было ускорить код, чтобы он работал как минимум не медленнее старого.
Простым «разглядыванием» проблему решить не удалось, нужно было разбираться, нужно было профилировать. Читайте дальше, чтобы узнать, как это было сделано.
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг. Некоторое время назад я сказал: "
Некоторое время назад я сказал: "