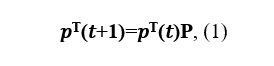Использование статистических методов для анализа временных рядов

Очень часто в нашей работе встречается такое понятие как «временной ряд». Это определение было придумано очень давно. Тогда, когда люди только стали записывать данные о чем-то двумя значениями: явлением и временем. Наиболее классическим описанием временного ряда является запись температуры на протяжении года или нескольких лет.
Но сам ряд — это лишь набор информации, который не несет ничего нужного. При этом, если построить график этого ряда, используя, к примеру, для оси Y значения времени, а для оси X — показания, которые были нами изначально записаны или форматизированы в цифровом виде, то мы сможем найти некоторые последовательности.
В случае графика температур — день теплее, чем ночь, а зима холоднее лета. И чем больше данных мы сможем проанализировать подобным образом, выделяя какие-то закономерности, тем с большей точностью мы сможем предугадать — что нас ждет в будущем.
Таким же образом думали люди в прошлом, разделяя процесс работы с временными графиками на три этапа: сбор данных, анализ временного ряда, предсказание следующих значений.
Но для чего может использоваться временной ряд в аудите? Для всего!
Операции клиента на протяжении квартала – временной ряд. Расход топлива служебного автомобиля – временной ряд. Даже чтение этой статьи – тоже временной ряд! (мы можем записать — сколько слов в минуту вы читаете, с указанием порядкового времени минуты)
Поэтому, анализ временных рядов мы с вами проводим достаточно часто. И, к сожалению, очень часто можем ошибаться.
Основным методом работы с любым простым временным рядом – это построение графика и его визуальная оценка.
Возьмем простой пример: рассмотрим покупки подарков к праздничному мероприятию для десяти коллег.