Спасибо за уточнение. В ту же копилку можно добавить и ngx_http_reqstat_module от того же tengine, да. Что я пытался сказать - что есть способы достать из nginx метрики. И чего я не могу понять из статьи - так это мотивации делать то, что описано
Максим, а можете, пожалуйста, немножко развернуть мотивацию такого бутерброда? В предисловии к статье я вижу три пункта:
Коммерческая версия Nginx предлагает решение в виде проверок работоспособности из модуля ngx_http_upstream_hc_module: периодически запрашивается какой-то URL (или просто пытается открыть порт), и, если тот или иной бэкенд не отвечает, его временно исключают из рабочего списка.
ограничение на количество одновременных запросов к бэкенду, а точнее — помещение запросов, превышающих лимиты, в очередь для последующей обработки.
Это решается и в опенсорсной версии в ngx_http_limit_req_module: limit_req zone=... burst=... без ключа nodelay.
Вы знаете его пределы и, например, не хотите пускать больше ста пользователей за раз
Если же подразумевалось, что инстансы nginx должны иметь синхронизированные счетчики - то не проще ли не решать это вовсе, а воспользоваться рейтлимитером на стороне приложения? Тем более, что известны его пределы. Причем в качестве примера приведено вообще единомоментное количество пользователей, а не rps - то есть вообще другой домен, который с ограничением rps связан слабо.
отсутствие встроенного способа получения вменяемой статистики по распределению трафика по бэкендам
Наверняка пошли бы копать в эту сторону, если бы tcpdump не показал, что каждая из сторон считала, что отсылает свою часть работы вовремя. Но это была бы уже другая статья :)
В большинстве случаев, которые я видел и не могу на них влиять, ваша K8S нода работает внутри VM от VMware или т.п. с share физическими ядрами из пула
Я правильно понимаю, что речь про условные 4*50%vCPU-виртуалки? Т.е. четыре виртуальных ядра, но гарантируется только 0.5с процессорного времени на ядро в секунду? Такие виртуалки да, для критичного к задержкам трафика использовать не рекомендуется — и предпочтительнее взять машинку 2*100%vCPU с гарантированными ядрами. Серьёзные cloud-провайдеры не будут запускать на этих ядрах ничего, что не относится к вашей виртуалке. Далее путь уже зависит от сетевого стека конкретного cloud-провайдера.
Да, ровно так дело и обстоит: это могли быть и другие ядра той же NUMA-ноды.
Что до того, что ядра берутся именно HT-парами: это сделано для того, чтобы меньше вымывался кеш инструкций.
Пробежался глазами по ридми — да, утилита может раскидать прерывания лесенкой. Но всё равно нужно будет прокинуть флажки --banirq — номера прерываний для которых до SCM ещё нужно как-то доставить. procfs и статистика с сетевой карты в диагностике не сильно помогут, к сожалению.
Q: I see that workload is distributed fine, but there is a lot of workload. How to go deeper, how to understand what my system doing right now?
A: Try perf top
С этим спорить невозможно — в знании того, когда именно следует воспользоваться одним из этих инструментов, и состоит немалая часть работы SRE / сисадмина
Пардон, мой ответ неполон без контекста, который я не донёс в статье: речь идёт о машинках без swap, на которых крутятся stateless-сервисы. Единственная disk-related активность этих сервисов — логи в stdout контейнера, которые оседают на диске.
А как отлавливали проблемные трейсы? Получается, нужно каждый трейс автоматически проверять на "гепы"? Понятно, что как-то это решается, но интересно вдруг есть элегантное решение, чем просто просто перебирать спаны?
Все трейсы, разумеется, проверять не нужно — тестовое приложение-клиент писало в логи trace_id только аномально длинных запросов. Эти trace_id искались в wireshark с помощью простого совпадения по строке (find packet -> string), а вся сессия находилась через follow -> tcp stream
А с чем связано ограничение в 10 мс?
Только с тем, что приложение было написано так, чтобы отправлять запрос раз в десять миллисекунд. Цифра в 10мс была выбрана достаточно большой, чтобы отделить от штатно отработавших запросов-ответов (1мс), но в то же время не сильно большой, чтобы отловить "микрозатыки".
В приведённом примере машинка с двумя процессорами, по 24 физических / 48 гипертредовых ядер на сокет — итого 96 логических ядер, нумерованных от 0 до 95. Две гипертредовых пары мы вынесли под сетевые прерывания — ядра 1 и 49, 2 и 50. 0,3-48,51-95 — это просто свёрнутое представление всех остальных ядер на этой машинке. На каком-нибудь твоём сервере или виртуалки нужные числа будут другие — нужно смотреть топологию конкретной железки
По наблюдениям, цикл поддержки удлиняется на два года примерно каждые два года.
И это замечательно, в этом сейчас они лидеры рынка.
При этом с новым SDK можно вполне написать приложение, работающее на старых устройствах — просто нужно не дёргать селекторы и классы новых АПИ (или проверять их существование заранее), и выставить Deployment Target соответственно интересующей системе.
Жаль, что с коммерческими приложениями так не выйдет — потому что пользователи заклюют за отсутствие очередной важной новой фичи из последнего апдейта iOS. И у пользователя устройства, объявленного устаревшим, даже нет опции установки старой версии.
Я просто напомню, что 32-битные айфоны и айпады перестали поддерживаться в iOS 11. В 2018 году
Скажите это оригинальному айфону, который превратился в тыкву с выходом iOS4 — apple перестали принимать в app store приложения, скомпилированные со старой версией SDK.
SERVICE TYPE % TRENI SOPPRESSI
Medium- and long-distance trains 0.76
International trains 1.68
Regional trains 0.16
Из тех, что не отменили вовсе, задерживали отправление более чем на пять минут:
SERVICE TYPE % DELAY >5’
Medium- and long-distance trains 10.6
International trains 23.6
Regional trains 5.6
Что до прибытия в пункт назначения, trenitalia мухлюют с цифрами и оглашают "прибытие без опоздания или с опозданием меньше чем на час" в одном бакете. Т.е. не хотят, чтобы публика офигела от количества опозданий на 40 минут:
SERVICE TYPE % DELAY<60’ 60’~120’ >120’
Medium- and long-distance trains 98.4 1.2 0.4
International trains 98.3 1.3 0.4
Regional trains 99.9 0.1 0.0

Спасибо за уточнение. В ту же копилку можно добавить и ngx_http_reqstat_module от того же tengine, да. Что я пытался сказать - что есть способы достать из nginx метрики. И чего я не могу понять из статьи - так это мотивации делать то, что описано
Максим, а можете, пожалуйста, немножко развернуть мотивацию такого бутерброда? В предисловии к статье я вижу три пункта:
tengine предоставляет модуль активных хелсчеков: https://github.com/alibaba/tengine/tree/master/modules/ngx_http_upstream_check_module
Это решается и в опенсорсной версии в ngx_http_limit_req_module:
limit_req zone=... burst=...без ключаnodelay.Если же подразумевалось, что инстансы nginx должны иметь синхронизированные счетчики - то не проще ли не решать это вовсе, а воспользоваться рейтлимитером на стороне приложения? Тем более, что известны его пределы. Причем в качестве примера приведено вообще единомоментное количество пользователей, а не rps - то есть вообще другой домен, который с ограничением rps связан слабо.
Это же решается с https://github.com/vozlt/nginx-module-vts
Т.е. вижу что, но не могу понять зачем
Да. https://habr.com/ru/post/124363/
Это in-house разработка, которую в опенсорсе, увы, не посмотреть. Передал коллегам идею для одной из следующих статей.
Отличный момент!
Нет, не смотрели в силу используемого стека. Да, в Linux алгоритм Нейгла используется по умолчанию и для отключения нужно нужно явно вызывать setsockopt с TCP_NODELAY. В Go, тем не менее, TCP-сокеты по умолчанию создаются с флагом TCP_NODELAY:
https://github.com/golang/go/blob/release-branch.go1.18/src/net/tcpsock.go#L206-L224
https://github.com/golang/go/blob/release-branch.go1.18/src/net/tcpsockopt_posix.go#L15
Каноническая имплементация gRPC на C++ также проставляет TCP_NODELAY:
https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/socket_utils_common_posix.cc#L234-L249
https://github.com/grpc/grpc/blob/136055b043dcf2b15f69f535f659e4090cf25b9f/src/core/lib/iomgr/tcp_server_utils_posix_common.cc#L177
https://github.com/grpc/grpc/blob/136055b043dcf2b15f69f535f659e4090cf25b9f/src/core/lib/iomgr/tcp_client_posix.cc#L79
Наверняка пошли бы копать в эту сторону, если бы tcpdump не показал, что каждая из сторон считала, что отсылает свою часть работы вовремя. Но это была бы уже другая статья :)
Я правильно понимаю, что речь про условные 4*50%vCPU-виртуалки? Т.е. четыре виртуальных ядра, но гарантируется только 0.5с процессорного времени на ядро в секунду? Такие виртуалки да, для критичного к задержкам трафика использовать не рекомендуется — и предпочтительнее взять машинку 2*100%vCPU с гарантированными ядрами. Серьёзные cloud-провайдеры не будут запускать на этих ядрах ничего, что не относится к вашей виртуалке. Далее путь уже зависит от сетевого стека конкретного cloud-провайдера.
Яндекс.Облако, например, может вынести сетевой оверхед на отдельные ядра, которые не видны из гостевой системы: https://cloud.yandex.ru/docs/compute/concepts/software-accelerated-network
AWS может прокинуть виртуальную функцию физической сетевой карты: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/enhanced-networking.html
Словом, облачные провайдеры максимально прозрачны, и в случае необходимости могут сделать вам быструю сеть.
В случае VMWare — начать с обновления ядра гостя. В 2020 году Алексей Махалов и Томер Зельцер добавили поддержку steal time:
https://lore.kernel.org/all/202003211432.57Hu5M7W%25lkp@intel.com/T/
NBS в Яндекс-Облаке реализован поверх YDB, в 2018 рассказывали про это:
https://www.youtube.com/watch?v=Kr6WIYPts8I&t=12861s
https://cloud.yandex.ru/docs/ydb/public_talks#about-cloud
Да, ровно так дело и обстоит: это могли быть и другие ядра той же NUMA-ноды.
Что до того, что ядра берутся именно HT-парами: это сделано для того, чтобы меньше вымывался кеш инструкций.
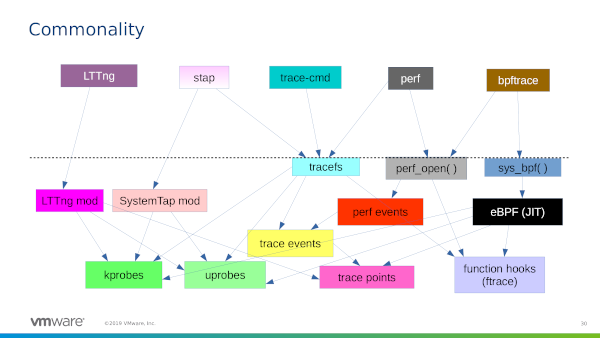
Пробежался глазами по ридми — да, утилита может раскидать прерывания лесенкой. Но всё равно нужно будет прокинуть флажки
--banirq— номера прерываний для которых до SCM ещё нужно как-то доставить. procfs и статистика с сетевой карты в диагностике не сильно помогут, к сожалению.С этим спорить невозможно — в знании того, когда именно следует воспользоваться одним из этих инструментов, и состоит немалая часть работы SRE / сисадмина
Пардон, мой ответ неполон без контекста, который я не донёс в статье: речь идёт о машинках без swap, на которых крутятся stateless-сервисы. Единственная disk-related активность этих сервисов — логи в stdout контейнера, которые оседают на диске.
Это, разумеется, была одна из гипотез — но проблема наблюдалась даже у stateless-сервисов, которые не пишут логов.
Все трейсы, разумеется, проверять не нужно — тестовое приложение-клиент писало в логи trace_id только аномально длинных запросов. Эти trace_id искались в wireshark с помощью простого совпадения по строке (find packet -> string), а вся сессия находилась через follow -> tcp stream
Только с тем, что приложение было написано так, чтобы отправлять запрос раз в десять миллисекунд. Цифра в 10мс была выбрана достаточно большой, чтобы отделить от штатно отработавших запросов-ответов (1мс), но в то же время не сильно большой, чтобы отловить "микрозатыки".
В приведённом примере машинка с двумя процессорами, по 24 физических / 48 гипертредовых ядер на сокет — итого 96 логических ядер, нумерованных от 0 до 95. Две гипертредовых пары мы вынесли под сетевые прерывания — ядра 1 и 49, 2 и 50.

0,3-48,51-95— это просто свёрнутое представление всех остальных ядер на этой машинке. На каком-нибудь твоём сервере или виртуалки нужные числа будут другие — нужно смотреть топологию конкретной железкиВы слишком серьёзны в своём анализе первоапрельского видео из 2013 года :)
Но почему нельзя заблаговременно заполнить анкеты силами экскурсионной компании, раз турист уже и так дал им свои персональные данные?
И это замечательно, в этом сейчас они лидеры рынка.
Жаль, что с коммерческими приложениями так не выйдет — потому что пользователи заклюют за отсутствие очередной важной новой фичи из последнего апдейта iOS. И у пользователя устройства, объявленного устаревшим, даже нет опции установки старой версии.
Скажите это оригинальному айфону, который превратился в тыкву с выходом iOS4 — apple перестали принимать в app store приложения, скомпилированные со старой версией SDK.
Спасибо, буду иметь в виду. Рим-Милан и Милан-Флоренция на нужные мне даты стоили как frecciarossa.
Статистика от Italo не согласна с вашим экспириенсом :)
https://habr.com/ru/company/tuturu/blog/474976/#comment_20864560
Несмотря на то, что впечатления говорят об обратном, простые электрички (treni regionali) в Италии расписание соблюдают лучше, чем все эти frecciaross-ы.
Вот данные за прошлый год:
https://www.trenitalia.com/content/dam/tcom/en/info-and-contacts/Quality_Report_2018.pdf
За 2018 было полностью отменено:
Из тех, что не отменили вовсе, задерживали отправление более чем на пять минут:
Что до прибытия в пункт назначения, trenitalia мухлюют с цифрами и оглашают "прибытие без опоздания или с опозданием меньше чем на час" в одном бакете. Т.е. не хотят, чтобы публика офигела от количества опозданий на 40 минут:
У поездов Italo, дорогих и скоростных, всё еще хуже:
https://italospa.italotreno.it/static/upload/qua/quality-report-2017.pdf
Всего в точку назначения опоздало: 62.5%
из них: