Программа на Python для статистического анализа текста
3 min
Recovery Mode
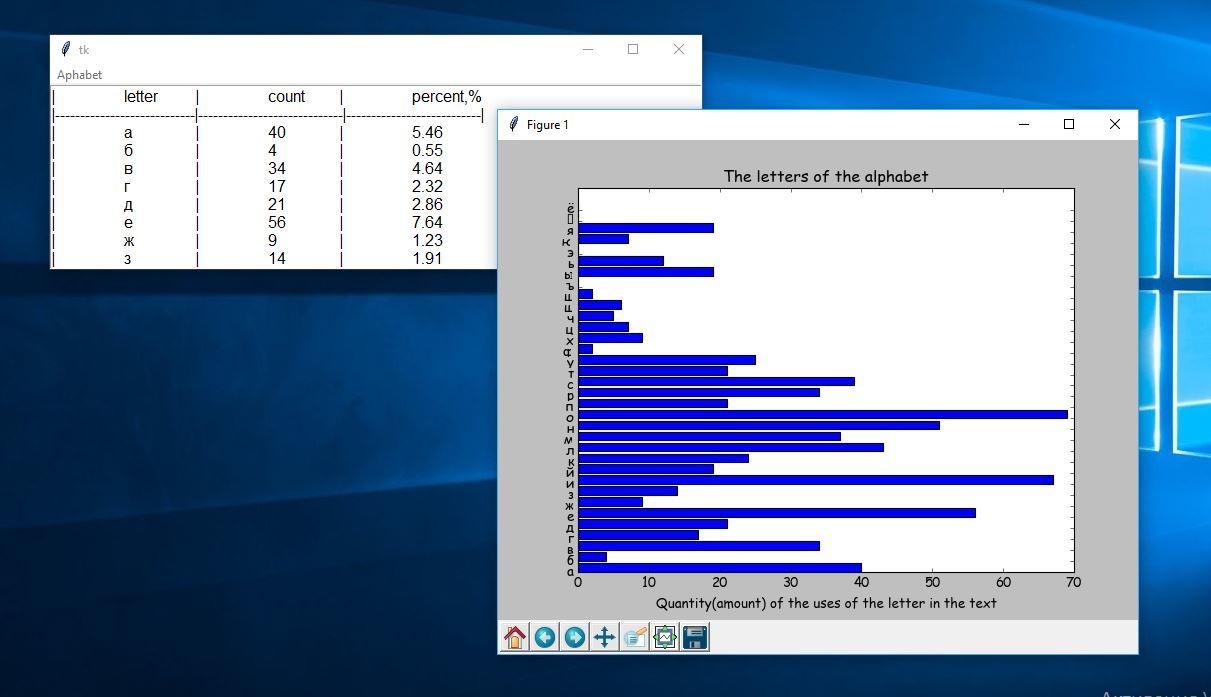
Задача подсчета частоты употребления определенных букв в английских и русских текстах является одним из этапов лингво-статистического анализа. В каталоге Каталог лингвистических программ и ресурсов в Cети отсутствует программа на Python для решения указанной задачи.
На форумах по Python встречаются отдельные части такой программы, однако они ориентированы на один язык, главным образом английский. Учитывая это обстоятельство мной разработана программа для статистической обработки, как для русских, так и для английских текстов.