Judy-массивы в PHP
4 min
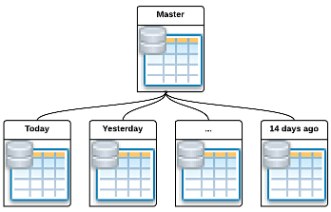
 В Badoo используется много сервисов на C и C++, большинство из которых работают с огромными объёмами данных. Как правило, сервисы выступают в роли «быстрого кэша» или «быстрой базы данных», т.е. совершают различные операции с массивами однотипных данных. Для быстрого доступа к данным мы давно и успешно используем Judy-массивы (англ. Judy arrays). Но однажды нам захотелось странного: обрабатывать большие массивы целых чисел на PHP, и мы сразу вспомнили про Judy.
В Badoo используется много сервисов на C и C++, большинство из которых работают с огромными объёмами данных. Как правило, сервисы выступают в роли «быстрого кэша» или «быстрой базы данных», т.е. совершают различные операции с массивами однотипных данных. Для быстрого доступа к данным мы давно и успешно используем Judy-массивы (англ. Judy arrays). Но однажды нам захотелось странного: обрабатывать большие массивы целых чисел на PHP, и мы сразу вспомнили про Judy.Немного истории
Judy-массивы были изобретены Дугласом Баскинсом (англ. Douglas Baskins) в начале 2000-го года. Проект их разработки финансировался компанией HP, но примерно через два года был закрыт. За это время было выпущено четыре версии, причём разработка последней заняла больше года, и в ней разработчики смогли в два раза ускорить Judy, в два раза уменьшить потребление памяти, хоть и далось это нелёгкой ценой: объём кода вырос в 5 раз, а его сложность ― на порядок.

 «Что? Стивен Кинг „Как писать программный код“ ?! Нет такой книги! Да он вообще не программист ни разу!».
«Что? Стивен Кинг „Как писать программный код“ ?! Нет такой книги! Да он вообще не программист ни разу!».