
Конкурс VK Сup. Трек ML. 4 место. Как?
11 min

В данном конкурсе, проводимом в рамках отборочного тура VK Сup 2020, трек ML, необходимо было предсказать долю потенциальной аудитории, которая просмотрит рекламные объявления, показываемые на нескольких рекламных площадках конкретное число раз: 1,2,3 еще и в будущем.
Это было не классическое соревнование по отправке итоговых предсказаний на известные тестовые данные, а предсказание на полностью неизвестных данных, подаваемых на модель в docker, запущенном на площадке конкурса.
В целом, такое решение уравнивает шансы участников и не позволяет тем, кто любит подглядывать в тест, обогащать им тренировочный набор данных, подгонять модель под распределение тестовых данных. Здесь все были в равных условиях, так как не понятно, что может быть в данных: “мусорные” данные, спорадические выбросы, неверные разделители и прочее. Но все эти нюансы одновременно заставляют думать и об обработке исключений.
В этом конкурсе я занял непочетное 4 место и хочу рассказать, как же это удалось.
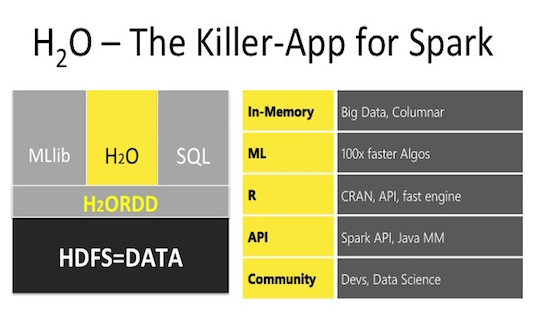 H2O – библиотека машинного обучения, предназначенная как для локальных вычислений, так и с использованием кластеров, создаваемых непосредственно средствами H2O или же работая на кластере Spark. Интеграция H2O в кластеры Spark, создаваемые в Azure HDInsight, была добавлена недавно и в этой публикации (являющейся дополнением моей прошлой статьи:
H2O – библиотека машинного обучения, предназначенная как для локальных вычислений, так и с использованием кластеров, создаваемых непосредственно средствами H2O или же работая на кластере Spark. Интеграция H2O в кластеры Spark, создаваемые в Azure HDInsight, была добавлена недавно и в этой публикации (являющейся дополнением моей прошлой статьи:  Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.
Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight. Как многим известно из прессы, международный консорциум журналистов-расследователей (ICIJ) выложил в свободный доступ, так называемый «Панамский архив»: сведения о лицах, связанных с офшорными компаниями по всему миру, полученные неизвестными лицами из панамской юридической фирмы Mossack Fonseca.
Как многим известно из прессы, международный консорциум журналистов-расследователей (ICIJ) выложил в свободный доступ, так называемый «Панамский архив»: сведения о лицах, связанных с офшорными компаниями по всему миру, полученные неизвестными лицами из панамской юридической фирмы Mossack Fonseca.  В то время как за окном температура на пути к очередным рекордам, интересно посмотреть, а какие вообще бывали температуры в произвольный интервал времени, за любые года за последние несколько десятилетий в 30 000 точках по всему миру. А может не прогадать с днями отпуска, и взять их в те дни, когда есть какое-то «статистическое преимущество» в выбранном местоположении по теплой погоде, а может быть по холодной, оценив его визуально на любой из трех типов диаграмм. Ну или можно просто повращать глобус, визуально оценить разнообразие температур и «как прекрасен этот мир».
В то время как за окном температура на пути к очередным рекордам, интересно посмотреть, а какие вообще бывали температуры в произвольный интервал времени, за любые года за последние несколько десятилетий в 30 000 точках по всему миру. А может не прогадать с днями отпуска, и взять их в те дни, когда есть какое-то «статистическое преимущество» в выбранном местоположении по теплой погоде, а может быть по холодной, оценив его визуально на любой из трех типов диаграмм. Ну или можно просто повращать глобус, визуально оценить разнообразие температур и «как прекрасен этот мир». 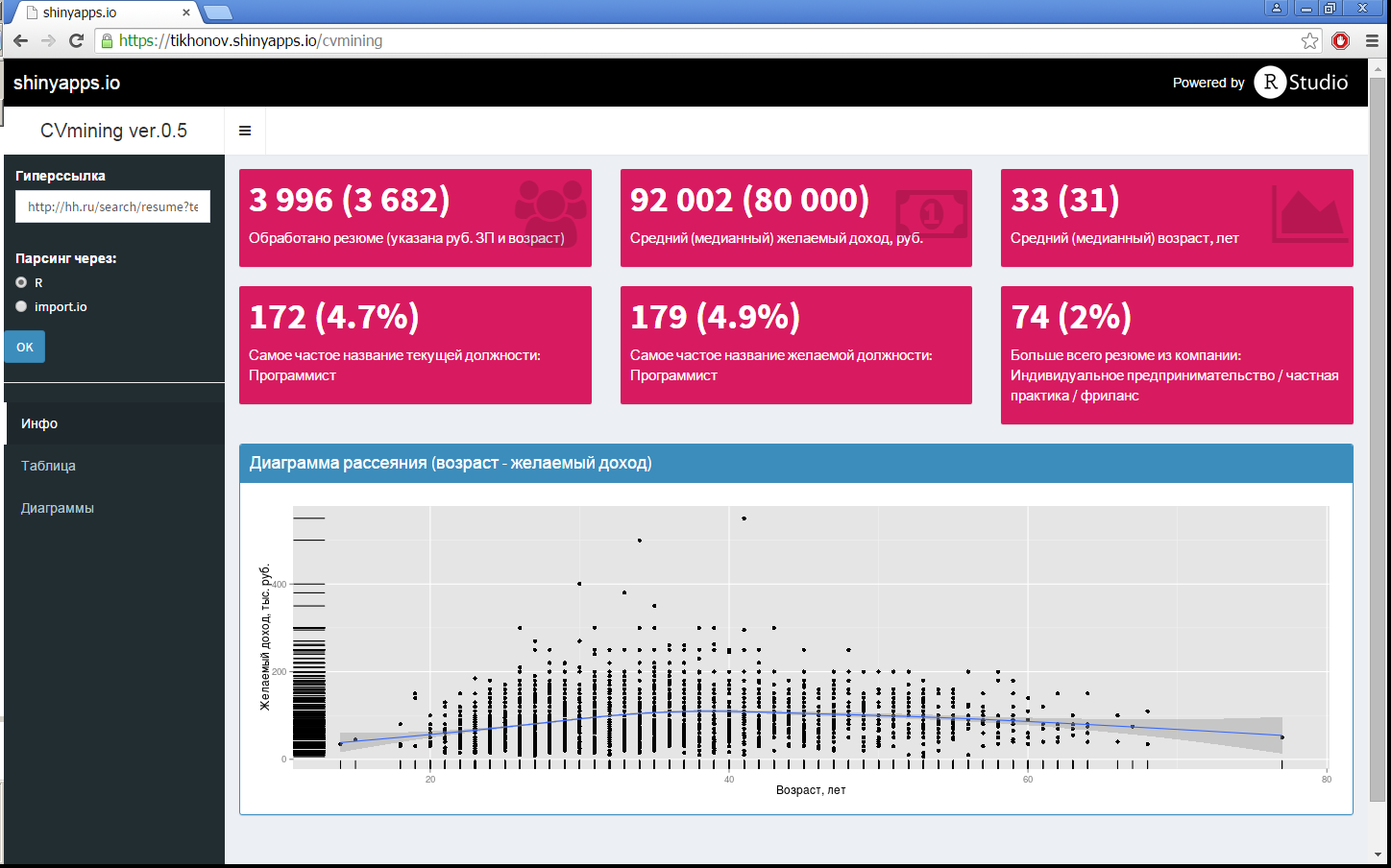
 Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.