Материал будет полезен тем, кто осваивает язык R в качестве инструмента анализа табличных данных и хочет увидеть сквозной пример реализации основных шагов обработки.
Ниже демонстрируется загрузка данных из csv-файлов, разбор текстовых строк с элементами очистки данных, агрегация данных по аналитическим измерениям и построение диаграмм.
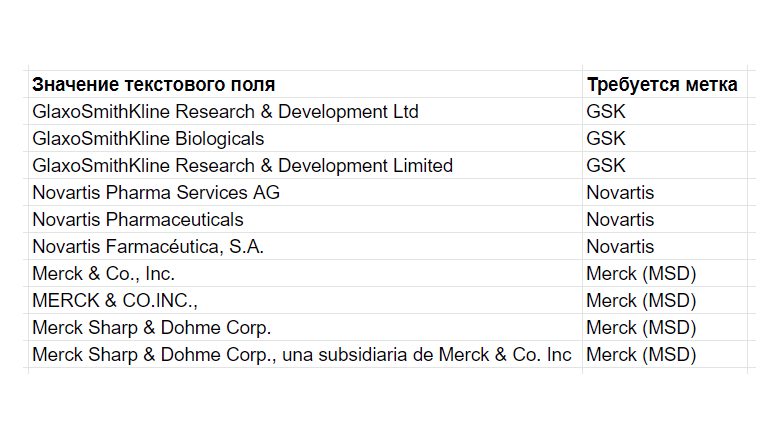
В примере активно используется функциональность пакетов data.table, reshape2, stringdist и ggplot2.
В качестве «реальных данных» взята информация о выданных разрешениях на осуществление деятельности по перевозке пассажиров и багажа легковым такси в Москве. Данные предоставлены в общее пользование Департаментом транспорта и развития дорожно-транспортной инфраструктуры города Москвы. Страница набора данных
data.mos.ru/datasets/655
Исходные данные имеют следующий формат:
ROWNUM;VEHICLE_NUM;FULL_NAME;BLANK_NUM;VEHICLE_BRAND_MODEL;INN;OGRN
1;"А248УЕ197";"ООО «ТАКСИ-АВТОЛАЙН»";"017263";"FORD FOCUS";"7734653292";"1117746207578"
2;"А249УЕ197";"ООО «ТАКСИ-АВТОЛАЙН»";"017264";"FORD FOCUS";"7734653292";"1117746207578"
3;"А245УЕ197";"ООО «ТАКСИ-АВТОЛАЙН»";"017265";"FORD FOCUS";"7734653292";"1117746207578"
```
1. Загрузка первичных данных
Данные можно загружать непосредственно с сайта. В процессе загрузки сразу переименуем колонки удобным образом.
url <- "http://data.mos.ru/datasets/download/655"
colnames = c("RowNumber", "RegPlate", "LegalName", "DocNum", "Car", "INN", "OGRN", "Void")
rawdata <- read.table(url, header = TRUE, sep = ";",
colClasses = c("numeric", rep("character",6), NA),
col.names = colnames,
strip.white = TRUE,
blank.lines.skip = TRUE,
stringsAsFactors = FALSE,
encoding = "UTF-8")
Теперь можно приступать к анализу и визуализации…