Выше уже упоминали D, а если вспомнить, что все эти ranges в C++ попали оттуда (именно в виде шаблонных конструкций этапа компиляции), то и for надо смотреть там же.
foreach (i; 0..100) {}
В C++ это переносится примерно так же, как у вас в статье
for (auto i : iota(100)) {}
Я считаю, что синтаксический сахар в виде range-based for вместе с хорошей библиотекой ranges (ranges-v3, которая фактически в стандарте C++20), и есть идеальный for.
Ну и стоит упомянуть, что функциональщина в виде map, filter или cartesianProduct часто лучше читается. Можете посмотреть на ndslice и увидеть, как хорошо решается задача многомерного прохода на тех же абстракциях.
Это гораздо лучше чем перевод очередной графомании зарубежного автора, новости про телеграмм, потому что это АйТи и многого другого на хабра.
Космос не зауряден, тем более, что сейчас кое-что меняется и движется в этой сфере. Такие новости про запуски создают хороший и правдоподобный фон происходящего.
Вот это выкидывание на рынок мне, да и не только мне, тоже не нравится. А точнее разработка под такой рынок. Но боюсь, это примерно того же порядка, что и «мне не нравится вода, потому что она сырая». Это же не заговор злых менеджеров по продажам, это объективные рыночные условия, так что приходится расслабляться и получать удовольствие.
А вот должен ли разработчик сам следить за памятью — это уже интересный технический вопрос. Тот же rust отлично показывает, что даже под жёстким контролем и гарантиями языка, человек не может точно управлять временем жизни объектов. Иначе там бы не появился счётчик ссылок. То есть есть ситуации, когда время жизни не очевидно и зависит от разных условий. И тогда это становится выбором между счётчиком и сборщиком. И оба не идеальны. Так что я бы не называл это ошибкой, скорее рекомендацией обойтись без автоматического управления, когда хватает ручного. В терминах C++ это использование uniq_ptr вместо shared_ptr, в D — @nogc, в C# struct, где это возможно.
Особенно ярко проблема заметна не на памяти, а файловых дескрипторах и прочих ресурсах, которые сборщик не трогает. Они должны управляться предельно просто и детерменировано. Но там и циклических ссылок нет.
Спору нет, hard realtime это точно не про GC. Но согласитесь, это очень маленькая ниша и там себя неплохо чувствует C. Там есть средства и время на разработку.
А вот с тем, что GC из D может приводить к требованию 256 ядер процессора для простой игры, я не соглашусь. Люди пишут говнокод независимо от языка и фреймвёрка. Если бы не было js или C# с Unity, в такой же среде даже на чистом C написали бы то же самое, такое же медленное, но дороже. Более того, я уверен, что при равных трудозатратах код на C будет медленнее кода на D и, возможно, C#. C быстр тогда, когда на него тратят силы, а когда тяп-ляп и в прод, будет ад.
И нет, это не разработчики обленились и не хотят «включать мозг». Это запрос рынка на тяп-ляп, js, electron… ой, у нас анимация мигания курсора проц съела. Если качество кода не ценится, то язык не поможет. Административные проблемы техническими средствами не решаются.
Я писал на D физический симулятор реального времени для применения в играх. В нём не понадобилось отключать или как-либо особо задумываться над GC, всё просто работало. Предыдущая версия на C++ содержала свои коллекции и аллокаторы, была заметно сложнее в этом аспекте, но работала медленнее. Удобство написания кода позволяет больше времени уделять алгоритмам.
Это я к тому, что GC удобен, а ситуаций, где с ним надо что-то делать не так много. Обычный программист на C++ не пишет свои аллокаторы (разве что использует готовые простые решения), так же и обычно на D не надо вспоминать про особенности сборки мусора.
Весь цикл статей как раз про то, что не надо бояться GC, потому что вам его хватит, а если нет, то даже за его пределами есть жизнь.
Я рассматривал все сочетания лесенок высотой 3 и 4, их не много, можно разбить на классы и все рассмотреть на бумаге. Сейчас точно не воспроизведу, доказательство не сохранял, уже уверен, что в нём есть дыры, раз уж никто до сих пор полноценно задачу не решил.
Вы имеете в виду врехнюю границу промежуточного результата? А зачем? Отсекать количество вариантов тут не надо, вариантов не так много, чтобы не перебрать все. Можно ли доказать, что среди экстремально больших промежуточных результатов не может быть искомого? Мне кажется, что можно, не так много действий могут приводить к чему-то большому.
Полный перебор (забив на все переполнения и неточности, поэтому и не полностью корректный как доказательство) в даблах на домашнем компе у меня занял 40 секунд. Длинная арифметика сразу увеличивает время в разы (что ерунда для глобальной задачи), но от точности и непредставимости результатов деления не спасает. 1/3 и в длинной арифметике непредставима, а sqrt(2) и в виде рациональных дробей. Я вижу проблему только с резким ростом вычислительной погрешности в операциях вроде 100500 ^ sqrt(3). Но для одного конкретного числа 10958 таких ситуаций мало, их можно и по одной (или классами) руками рассмотреть.
По крайней мере у меня получалось рассмотреть все лесенки из степеней, чтобы показать, что там 10958 точно нет. Чего я не рассмотрел, так это проблемы вычислительной погрешности, которые описал выше.
И да, я считаю (и это было в оригинале) что задача поставлена в действительных числах, не выходя в комплексную плоскость.
Забавно, а я давал задачку на поиск разложения 10958 студентам в качестве практики по программированию. Понятно, что не фундаментальное исследование, а просто перебор всех возможных вариантов, забив на сверхбольшие числа и всевозможные неточности double. А тут из этой задачи современную проблему математики создают.
Мне казалось, что отсутствие разложения уже доказано, ведь несложно показать, что среди лесенок из степеней этого числа нет, а всё остальное перебирается в лоб.
Хотел было возразить, что нет, C++ нормальный первый язык. Я с него начал и продолжаю работать на нём. Но потом понял, что на брейнфаке я тоже писал немало и даже никнейм на хабре к нему отсылает. А я считал себя нормальным человеком :(((
Пулинг, то есть объединение проб нескольких человек в один тест вполне себе используется. Ссылок под рукой нет, но должно гуглиться. Если хоть один человек в группе болен, то тест будет положительный и всех надо отправлять не подтверждение индивидуальным тестом.
Более сложные схемы, типа той, что в статье слишком ненадёжны. Сам по себе тест не 100% точный + ошибки лаборантов и неверный тест уже не у одного человека, а у всей группы, причём как ложноположительный (что терпимо), так и ложноотрицательный, что опасно.
Я сам думал про такую схему ещё в начале эпидемии, думаю, что не только я. Но в реальности малоприменимо.
Я видел, но это не совсем то же самое. Без поддержки языка статический анализ так и останется рекомендательным инструментом. В том же D понадобился live, а ещё были scope и return scope(hello DIP1000). Пока что это выглядит так себе, но я верю, что можно найти такое решение, которое будет понятнее и проще, и которое можно внедрить в C++.
Несмотря на то, как плохо выглядит вклинивание системы владения указателей в D, мне это очень нравится. Да, в расте всё выглядит органичнее и консистентнее, зато практика внедрения владения в язык, где это изначально не задумано, очень полезна для остальных. Rust всё же инопланетныйспецифичный язык, а тут есть шанс принести все его плюсы в более привычное окружение. И я сейчас даже не про D — всё это потенциально переносимо в другие языки, в первую очередь в C++.
С посылом статьи в целом согласен. Я учился программировать на BASIC на спектруме во времена выхода пентиумов 3 и 4, то есть это было не актуально совсем. Ни разу на практике не пригодились те знания, но навык программирования от языка зависит мало, и он спокойно был перенесён сначала на Паскаль, C, а потом и C++.
К списку полезного в вузе я бы добавил теоретическую информатику: алгоритмы, конечные автоматы, машина Тьюринга, методы оптимизации и всякие P = NP. Не то чтобы оно было нужно постоянно, детали все давно забыты, но знание о принципиальной возможности или невозможности решения задачи весьма полезны. Помогает не биться линий раз в стену невозможного и не сдаваться перед преодолимыми сложностями.
Каким образом теряется RAII или раскрутка стека? Если раскрутка как-то и страдает из-за использования map и then, то деструкторы не перестают вызываться. Гарантии те же и даже больше, потому что больше никто не может вклиниться в неудобные места вроде вычисления аргументов функций. Писать expected safe код проще, чем exception safe.
Что же вы все так набросились на статью! Да, не идеал, ради рекламы Expected много написано, но озвучить эту сторону тоже надо было.
Не надо забывать, что исключения совсем не zero cost даже, когда не бросаются, иначе бы noexcept в стандарт не тащили. Кроме затрат непосредственно на секцию try, которая в реализации SJLJ может быть очень недешёвой, есть ещё и косвенные на сломанные оптимизации. Сейчас с ходу не найду доклад, но точно был про внутренности llvm, где демонстрировалось, какие именно оптимизации ломаются.
Кроме того есть ещё разбухание бинаря (привет dwarf), -fno-exceptions и прочие интересные случаи.
Возможно, я чего-то о нём не знаю, но как без возможности воспроизвести проблему тестом, воспользоватся valgrind'ом? Когда есть, что запустить, чтобы воспроизвести утечку, valgrind гораздо лучше, но что делать, когда она никак не воспроизводится? Что он может сделать с одним лишь дампом?
Понятно, что посыл не в том, но всё же никто бы не стал в первый же год добавлять новый день. В реальности остались бы на старом календаре, а потом бы уже постепенно перешли, когда подготовили и софт и людей. Церковь вон живёт с юлианским календарём и никаких проблем не имеет.
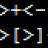
Выше уже упоминали D, а если вспомнить, что все эти ranges в C++ попали оттуда (именно в виде шаблонных конструкций этапа компиляции), то и for надо смотреть там же.
В C++ это переносится примерно так же, как у вас в статье
Я считаю, что синтаксический сахар в виде range-based for вместе с хорошей библиотекой ranges (ranges-v3, которая фактически в стандарте C++20), и есть идеальный for.
Ну и стоит упомянуть, что функциональщина в виде map, filter или cartesianProduct часто лучше читается. Можете посмотреть на ndslice и увидеть, как хорошо решается задача многомерного прохода на тех же абстракциях.
В данном случае дело не только в jpeg, но суть вы поняли
Космос не зауряден, тем более, что сейчас кое-что меняется и движется в этой сфере. Такие новости про запуски создают хороший и правдоподобный фон происходящего.
А вот должен ли разработчик сам следить за памятью — это уже интересный технический вопрос. Тот же rust отлично показывает, что даже под жёстким контролем и гарантиями языка, человек не может точно управлять временем жизни объектов. Иначе там бы не появился счётчик ссылок. То есть есть ситуации, когда время жизни не очевидно и зависит от разных условий. И тогда это становится выбором между счётчиком и сборщиком. И оба не идеальны. Так что я бы не называл это ошибкой, скорее рекомендацией обойтись без автоматического управления, когда хватает ручного. В терминах C++ это использование uniq_ptr вместо shared_ptr, в D — @nogc, в C# struct, где это возможно.
Особенно ярко проблема заметна не на памяти, а файловых дескрипторах и прочих ресурсах, которые сборщик не трогает. Они должны управляться предельно просто и детерменировано. Но там и циклических ссылок нет.
А вот с тем, что GC из D может приводить к требованию 256 ядер процессора для простой игры, я не соглашусь. Люди пишут говнокод независимо от языка и фреймвёрка. Если бы не было js или C# с Unity, в такой же среде даже на чистом C написали бы то же самое, такое же медленное, но дороже. Более того, я уверен, что при равных трудозатратах код на C будет медленнее кода на D и, возможно, C#. C быстр тогда, когда на него тратят силы, а когда тяп-ляп и в прод, будет ад.
И нет, это не разработчики обленились и не хотят «включать мозг». Это запрос рынка на тяп-ляп, js, electron… ой, у нас анимация мигания курсора проц съела. Если качество кода не ценится, то язык не поможет. Административные проблемы техническими средствами не решаются.
Это я к тому, что GC удобен, а ситуаций, где с ним надо что-то делать не так много. Обычный программист на C++ не пишет свои аллокаторы (разве что использует готовые простые решения), так же и обычно на D не надо вспоминать про особенности сборки мусора.
Весь цикл статей как раз про то, что не надо бояться GC, потому что вам его хватит, а если нет, то даже за его пределами есть жизнь.
Полный перебор (забив на все переполнения и неточности, поэтому и не полностью корректный как доказательство) в даблах на домашнем компе у меня занял 40 секунд. Длинная арифметика сразу увеличивает время в разы (что ерунда для глобальной задачи), но от точности и непредставимости результатов деления не спасает. 1/3 и в длинной арифметике непредставима, а sqrt(2) и в виде рациональных дробей. Я вижу проблему только с резким ростом вычислительной погрешности в операциях вроде 100500 ^ sqrt(3). Но для одного конкретного числа 10958 таких ситуаций мало, их можно и по одной (или классами) руками рассмотреть.
По крайней мере у меня получалось рассмотреть все лесенки из степеней, чтобы показать, что там 10958 точно нет. Чего я не рассмотрел, так это проблемы вычислительной погрешности, которые описал выше.
И да, я считаю (и это было в оригинале) что задача поставлена в действительных числах, не выходя в комплексную плоскость.
Мне казалось, что отсутствие разложения уже доказано, ведь несложно показать, что среди лесенок из степеней этого числа нет, а всё остальное перебирается в лоб.
Более сложные схемы, типа той, что в статье слишком ненадёжны. Сам по себе тест не 100% точный + ошибки лаборантов и неверный тест уже не у одного человека, а у всей группы, причём как ложноположительный (что терпимо), так и ложноотрицательный, что опасно.
Я сам думал про такую схему ещё в начале эпидемии, думаю, что не только я. Но в реальности малоприменимо.
инопланетныйспецифичный язык, а тут есть шанс принести все его плюсы в более привычное окружение. И я сейчас даже не про D — всё это потенциально переносимо в другие языки, в первую очередь в C++.К списку полезного в вузе я бы добавил теоретическую информатику: алгоритмы, конечные автоматы, машина Тьюринга, методы оптимизации и всякие P = NP. Не то чтобы оно было нужно постоянно, детали все давно забыты, но знание о принципиальной возможности или невозможности решения задачи весьма полезны. Помогает не биться линий раз в стену невозможного и не сдаваться перед преодолимыми сложностями.
Не надо забывать, что исключения совсем не zero cost даже, когда не бросаются, иначе бы noexcept в стандарт не тащили. Кроме затрат непосредственно на секцию try, которая в реализации SJLJ может быть очень недешёвой, есть ещё и косвенные на сломанные оптимизации. Сейчас с ходу не найду доклад, но точно был про внутренности llvm, где демонстрировалось, какие именно оптимизации ломаются.
Кроме того есть ещё разбухание бинаря (привет dwarf), -fno-exceptions и прочие интересные случаи.