«Живые графы» — выращивание графов на клеточных автоматах с примерами на Silverlight
Простой
15 мин
UPD. 2025. The demo of Graph Unfolding Cellular Automata (GUCA) has been re-implemented in TypeScript: https://github.com/roma-goodok/guca
Пожалуй, ничто так долго, на протяжении многих веков, не интересовало учёных, как вопросы о происхождении жизни и разума. Как природа догадалась сотворить человеческий мозг? Чем определяется структура нейронной сети в нашей голове и как работает автосборка многоклеточного организма из единственной клетки? Почему при развитии зародыша человека на определённой стадии можно наблюдать нечто похожее на рыбьи жабры?
Да и простого любопытствующего обывателя, не отягощённого подробностями органической химии, подобные вопросы не обходят стороной.
Вот была бы игрушка-конструктор, с помощью которой можно собрать простенькие растущие организмы. Тогда построив предельно упрощённую модель, демонстрирующую многие из явлений живого, можно было бы приблизиться к ответам на вопросы устройства жизни, или хотя бы к пониманию, где эти ответы искать.
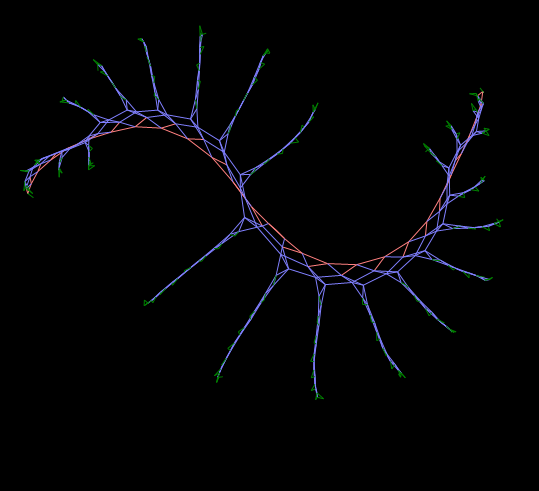
Такой предельно упрощённой и наглядной моделью могут оказаться «Живые графы» — конечные автоматы на графе, каждый узел которого содержит некое исполняющее устройство (автомат) с конечным числом состояний и с набором примитивных правил, управляющих созданием или изменением новых связей между узлами.
Введение
Пожалуй, ничто так долго, на протяжении многих веков, не интересовало учёных, как вопросы о происхождении жизни и разума. Как природа догадалась сотворить человеческий мозг? Чем определяется структура нейронной сети в нашей голове и как работает автосборка многоклеточного организма из единственной клетки? Почему при развитии зародыша человека на определённой стадии можно наблюдать нечто похожее на рыбьи жабры?
Да и простого любопытствующего обывателя, не отягощённого подробностями органической химии, подобные вопросы не обходят стороной.
Вот была бы игрушка-конструктор, с помощью которой можно собрать простенькие растущие организмы. Тогда построив предельно упрощённую модель, демонстрирующую многие из явлений живого, можно было бы приблизиться к ответам на вопросы устройства жизни, или хотя бы к пониманию, где эти ответы искать.
Такой предельно упрощённой и наглядной моделью могут оказаться «Живые графы» — конечные автоматы на графе, каждый узел которого содержит некое исполняющее устройство (автомат) с конечным числом состояний и с набором примитивных правил, управляющих созданием или изменением новых связей между узлами.


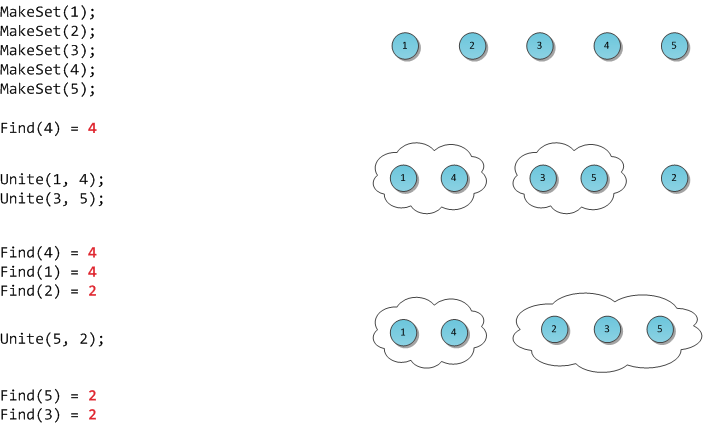
 Алгоритм Флойда — Уоршелла — алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного
Алгоритм Флойда — Уоршелла — алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного