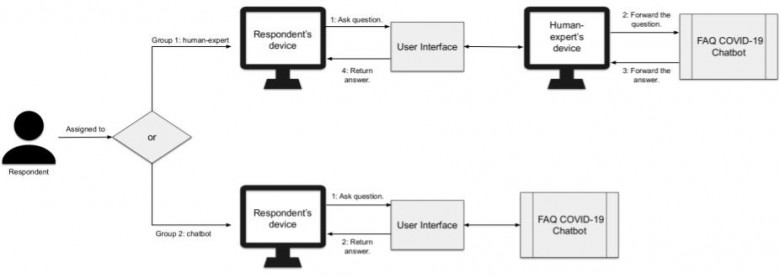
Для разнородных групп пользователей (прим. язык, возраст), возможность одинаково эффективно взаимодействовать с веб-приложениями является одним из важнейших факторов такого понятия как "доступность" (англ. Accessibility). Это относится и к системам автоматического ответа на вопросы с использованием графов знаний (англ. Knowledge Graph Question Answering, KGQA), которые обеспечивают доступ к данным Семантической паутины (англ. The Semantic Web) через интерфейс на естественном языке. В ходе работы над такой темой, как многоязычная доступность KGQA-систем, мы с коллегами выявили несколько наиболее острых проблем. Одной из которых является отсутствие многоязычных бенчмарков для KGQA.
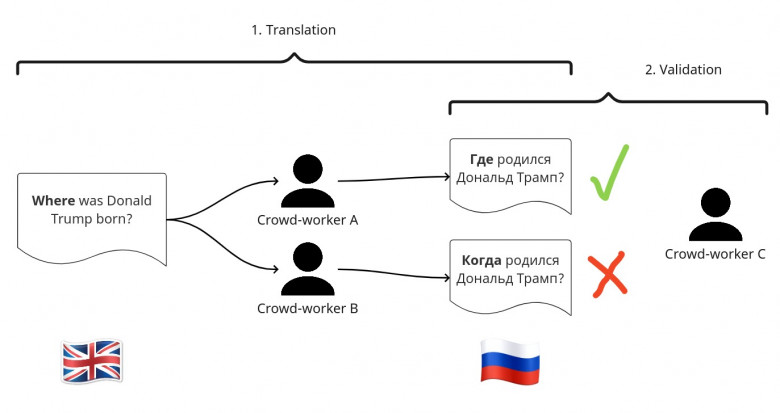
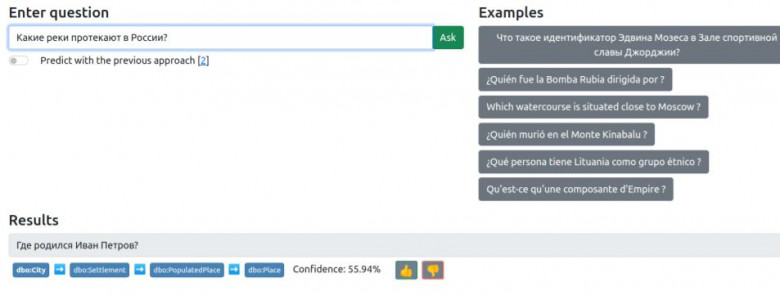
В этой статье мы улучшаем один из самых популярных бенчмарков для KGQA -- QALD-9, путем создания эталонных переводов вопросов из исходного датасета на 8 различных языков (немецкий, французский, русский, украинский, белорусский, армянский, башкирский, литовский). Одним из самых важных аспектов является то, что переводы были предоставленны и провалидированы носителями соответствующего языка. Пять из этих языков - армянский, украинский, литовский, башкирский и белорусский - насколько нам известно, никогда ранее не рассматривались в рамках KGQA-систем. А два языка (башкирский и белорусский) рассматриваются ЮНЕСКО как "находящиеся под угрозой исчезновения". Мы назвали новый расширенный датасет "QALD-9-plus". Датасет доступен онлайн.