
Агрегирующие функции в dplyr
6 min
Translation
summarise() используется с агрегирующими функциями, которые принимают на вход вектор значений, а возвращают одно. Функция summarise_each() предлагает другой подход к summarise() с такими же результатами.Цель этой статьи — сравнить поведение
summarise() и summarise_each(), учитывая два фактора, которыми мы можем управлять:1. Сколькими переменными оперировать
- 1А, одна переменная
- 1В, более одной переменной
2. Сколько функций применять к каждой переменной
- 2А, одна функция
- 2В, более одной функции
Получается четыре варианта:
- Вариант 1: применить одну функцию к одной переменной
- Вариант 2: применить много функций к одной переменной
- Вариант 3: применить одну функцию к многим переменным
- Вариант 4: применить много функций к многим переменным
Также проверим эти четыре случая с и без опции
group_by().
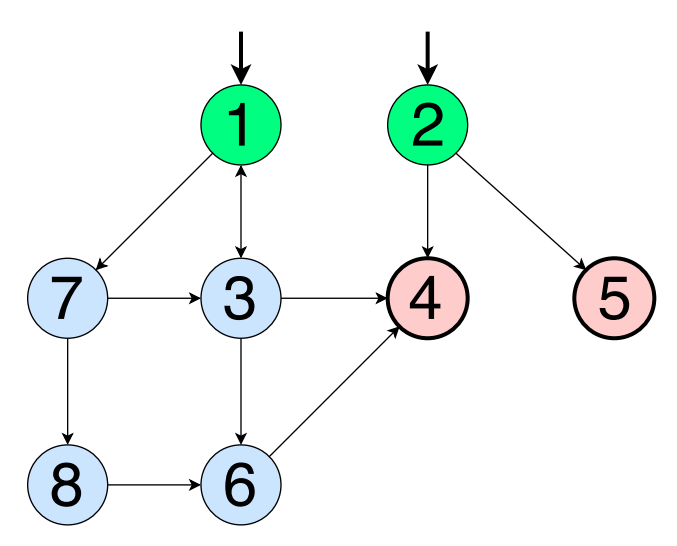 Большинство программ и алгоритмов можно представить в виде графа, состоящего из набора вершин (N) и ребер (Е). Покрытие графов в тестировании полезно тем, что можно проектировать тесты, используя разные критерии покрытия, и выявить ошибки. Что касается тестирования черного ящика, то покрытие графов здесь тоже может иметь большое значение, если приходится работать с состояниями и переходами, графами состояний сущности и т.д. Если граф достаточно сложен, разные критерии покрытия позволят оценить достаточность тестового набора.
Большинство программ и алгоритмов можно представить в виде графа, состоящего из набора вершин (N) и ребер (Е). Покрытие графов в тестировании полезно тем, что можно проектировать тесты, используя разные критерии покрытия, и выявить ошибки. Что касается тестирования черного ящика, то покрытие графов здесь тоже может иметь большое значение, если приходится работать с состояниями и переходами, графами состояний сущности и т.д. Если граф достаточно сложен, разные критерии покрытия позволят оценить достаточность тестового набора.
 Хотя популярность buzzword «pairwise» уже не та, на собеседованиях до сих пор задают вопрос о том, что представляет собой эта техника тест-дизайна. Однако, далеко не все тестировщики (как те, кто приходят на собеседование, так и те, кто его проводят) могут четко сформулировать ответ на вопрос, зачем нужны комбинаторные техники в общем и pairwise в частности (подавляющее большинство ошибок, все же, находятся на атомарных значениях параметров и не зависят от других). Простой ответ на этот вопрос, на мой взгляд — для нахождения багов, возникающих вследствие явных и неявных зависимостей между параметрами. Для простых случаев техника вряд ли принесет серьезную пользу, поскольку их можно проверить вручную, а для большого числа параметров и сложных зависимостей между ними количество тестов, скорее всего, будет слишком велико для ручного тестирования. Потому основное применение комбинаторных техник (и соответственно, инструментов, осуществляющих генерацию комбинаций параметров) — автоматизированное составление наборов тестовых данных по определенным законам.
Хотя популярность buzzword «pairwise» уже не та, на собеседованиях до сих пор задают вопрос о том, что представляет собой эта техника тест-дизайна. Однако, далеко не все тестировщики (как те, кто приходят на собеседование, так и те, кто его проводят) могут четко сформулировать ответ на вопрос, зачем нужны комбинаторные техники в общем и pairwise в частности (подавляющее большинство ошибок, все же, находятся на атомарных значениях параметров и не зависят от других). Простой ответ на этот вопрос, на мой взгляд — для нахождения багов, возникающих вследствие явных и неявных зависимостей между параметрами. Для простых случаев техника вряд ли принесет серьезную пользу, поскольку их можно проверить вручную, а для большого числа параметров и сложных зависимостей между ними количество тестов, скорее всего, будет слишком велико для ручного тестирования. Потому основное применение комбинаторных техник (и соответственно, инструментов, осуществляющих генерацию комбинаций параметров) — автоматизированное составление наборов тестовых данных по определенным законам.