Знакомство с Fugue — уменьшаем шероховатости при работе с PySpark
15 min
Tutorial
Translation

Автор оригинальной статьи: Kevin Kho
Повышение производительности разработчиков и снижение затрат на проекты Big Data

User
Автор оригинальной статьи: Kevin Kho
Повышение производительности разработчиков и снижение затрат на проекты Big Data
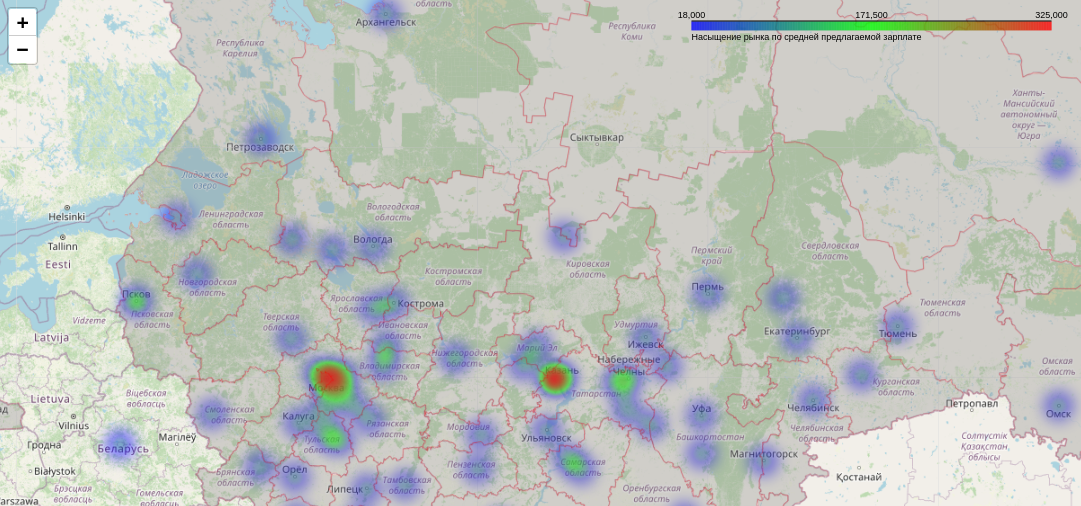
Возникла необходимость изобразить на интерактивной карте актуальное предложение вакансий в сфере Data Science с агрегацией по городам.
Действовать будем в 3 этапа:

Pandas - одна из наиболее используемых библиотек Python с открытым исходным кодом для работы со структурированными табличными данными для анализа. Однако он не поддерживает распределенную обработку, поэтому вам всегда придется увеличивать ресурсы, когда вам понадобится дополнительная мощность для поддержки растущих данных. И всегда наступит момент, когда ресурсов станет недостаточно. В данной статье мы рассмотрим, как PySpark выручает в условиях нехватки мощностей для обработки данных.
Ну что же, приступим...