Завтра искусственный интеллект поработит Землю и станет использовать человеков в качестве смешных батареек, поддерживающих функционирование его систем, а сегодня мы запасаемся попкорном и смотрим, с чего он начинает.
19 октября 2017 года команда Deepmind опубликовала в Nature статью, краткая суть которой сводится к тому, что их новая модель AlphaGo Zero не только разгромно обыгрывает прошлые версии сети, но ещё и не требует никакого человеческого участия в процессе тренировки. Естественно, это заявление произвело в AI-коммьюнити эффект разорвавшейся бомбы, и всем тут же стало интересно, за счёт чего удалось добиться такого успеха.
По мотивам материалов, находящихся в открытом доступе, Семён sim0nsays записал отличный стрим:
А для тех, кому проще два раза прочитать, чем один раз увидеть, я сейчас попробую объяснить всё это буквами.
Сразу хочу отметить, что стрим и статья собирались в значительной степени по мотивам дискуссий на closedcircles.com, отсюда и спектр рассмотренных вопросов, и специфическая манера повествования.
Ну, поехали.
Го — это древняя (по разным оценкам, ей от 2 до 5 тысяч лет) настольная стратегическая игра. Есть поле, расчерченное перпендикулярными линиями. Есть два игрока, у одного в мешочке белые камни, у другого — чёрные. Игроки по очереди выставляют камни на пересечение линий. Камни одного цвета, окружённые по четырём направлениям камнями другого цвета, снимаются с доски:
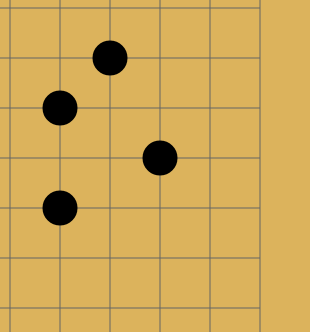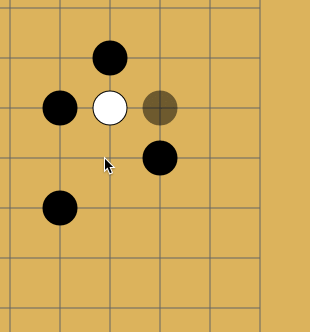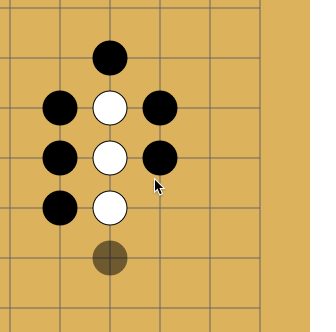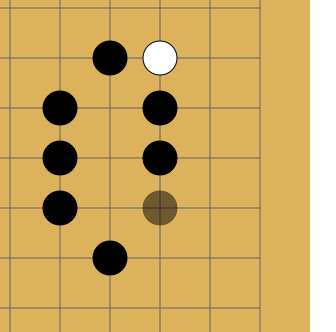
Выигрывает тот, кто к концу партии «окружит» большую по площади территорию. Там есть ещё несколько тонкостей, но базово это всё — человеку, который видит го первый раз в жизни, вполне реально объяснить правила за пять минут.
Окей, давай попробуем сравнить несколько настольных игр.
Начнём с шашек. В шашках у игрока есть примерно 10 вариантов того, какой сделать ход. В 1994 году чемпион мира по шашкам был обыгран программой, написанной исследователями из университета Альберты.
Дальше шахматы. В шахматах игрок выбирает в среднем из 20 допустимых ходов и делает такой выбор приблизительно 50 раз за игру. В 1997 году Deep Blue, созданная командой IBM программа, обыграла чемпиона мира по шахматам Гарри Каспарова.
Теперь го. Профессионалы играют в го на поле размера 19х19, что даёт 361 вариант того, куда можно поставить камень. Отсекая откровенно проигрышные ходы и точки, занятые другими камнями, мы всё равно получаем выбор из более чем 200 опций, который требуется совершить в среднем 50-70 раз за партию. Ситуация осложняется тем, что камни взаимодействуют между собой, образуя построения, и в результате камень, поставленный на 35 ходу, может принести пользу только на 115. А может не принести. А чаще всего вообще трудно понять, помог нам этот ход или помешал. Тем не менее, в 2016 году программа AlphaGo обыграла сильнейшего (по меньшей мере, одного из сильнейших) игрока в мире Ли Седоля в серии из пяти игр со счётом 4:1.
Грубо говоря, да. И в шашках, и в шахматах, и в го общий принцип, по которому работают алгоритмы, один и тот же. Все эти игры попадают в категорию игр с полной информацией, значит, мы можем построить дерево всех возможных состояний игры. Поэтому мы банально строим такое дерево, а дальше просто идём по ветке, которая приводит к победе. Тонкость в том, что для го дерево получается ну очень большим из-за лютого фактора ветвления и впечатляющей глубины, и ни построить, ни обойти его за адекватное время не представлялось возможным. Именно эту проблему смогли решить ребята из DeepMind.
Тут начинается интересное.
Сначала давай поговорим о том, как работали алгоритмы игры в го до AlphaGo. Все они показывали не самые впечатляющие результаты и успешно играли примерно на уровне среднего любителя, и все опирались на метод под названием Monte Carlo Tree Search — MCTS. Идея в чём (с этим важно разобраться).
У тебя есть дерево состояний — ходов. Из данной конкретной ситуации ты идёшь по какой-то из веток этого дерева, пока она не закончится. Когда ветка заканчивается, добавляешь в неё новый узел (ноду), тем самым инкрементально это дерево достраивая. А потом добавленную ноду оцениваешь, чтобы в дальнейшем определять, стоит ходить по данной ветке или не стоит, не раскрывая само дерево.
Чуть детальнее, это работает следующим образом:
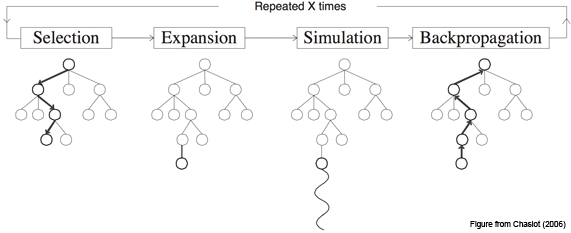
Шаг первый, Selection: у нас есть дерево позиций, и мы каждый раз совершаем ход, выбирая наилучший дочерний узел для текущей позиции.
Шаг второй, Expansion: допустим, мы дошли до конца дерева, но это ещё не конец игры. Просто создаём новую дочернюю ноду и идём в неё.
Шаг третий, Simulation: хорошо, появилась новая нода, фактически, игровая ситуация, в которой мы оказались впервые. Теперь надо её оценить, то есть понять, в хорошей мы оказались ситуации или не очень. Как это сделать? В базовой концепции — используя так называемый rollout: просто сыграть партию (или много партий) из текущей позиции и посмотреть, выиграли мы или проиграли. Получившийся результат и считаем оценкой узла.
Шаг четвёртый, Backpropagation: идём вверх по дереву и увеличиваем или уменьшаем веса всех родительских нод в зависимости от того, хороша новая нода или плоха. Пока важно понять общий принцип, мы ещё успеем рассмотреть данный этап в деталях.
В каждой ноде сохраняем два значения: оценку (value) текущей ноды и количество раз, которое мы по ней пробегали. И повторяем цикл из этих четырёх шагов много-много раз.
В самом простом варианте — берём ноду, у которой будет наивысший показатель Upper Confidence Bounds (UCB):
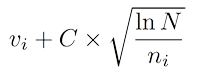
Здесь v — это value нашей ноды, n — сколько раз мы в этой ноде были, N — сколько раз были в родительской ноде, а C — просто некоторый коэффициент.
В не самом простом варианте можно усложнять формулу, чтобы получить более точные результаты, или вообще использовать какую-то другую эвристику, например, нейросеть. Об этом подходе мы тоже ещё поговорим.
Если смотреть чуть шире, перед нами классическая multi-armed bandit problem. Задача — найти такую функцию выбора узла, которая обеспечит оптимальный баланс между использованием лучших из имеющихся вариантов и исследованием новых возможностей.
Потому что с MCTS дерево решений растёт асимметрично: более интересные ноды посещаются чаще, менее интересные — реже, а оценить отдельно взятую ноду становится возможным без раскрытия всего дерева.

В общем и целом, AlphaGo опирается на те же самые принципы. Ключевое отличие — когда на втором этапе мы добавляем новую ноду, для того, чтобы определить, насколько она хорошая, вместо rollout'ов используем нейросеть. Как мы это делаем.
(Я совсем в двух словах расскажу про прошлую версию AlphaGo, хотя на самом деле в ней хватает интересных нюансов; кто хочет подробностей — вэлком в видео в начале, там они хорошо объясняются, или в соответствующий пост на хабре, там они хорошо расписаны).
Во-первых, тренируем две сети, каждая из которых получает на вход состояние доски и говорит, какой бы ход в этой ситуации сделал человек. Почему две? Потому что одна — медленная, но работает хорошо (57% верных предсказаний, и каждый дополнительный процент даёт очень солидный бонус к итоговому результату), а вторая обладает намного меньшей точностью, зато быстрая.
Обе эти сети, медленную и быструю, мы тренируем на человеческих ходах — банально идём на сервер го, забираем партии игроков хорошего уровня, парсим и скармливаем для обучения.
Во-вторых, берём две эти натренированные «на людях» сети и начинаем играть ими сами с собой, чтобы их прокачать.

Примерно так.
В-третьих, тренируем value-сеть, которая получает на вход текущее состояние доски, а в ответ отдаёт число от -1 до 1 — вероятность выиграть, оказавшись в этой позиции в какой-то момент партии.
Таким образом, у нас есть одна медленная и точная функция, которая говорит, куда надо ходить (из шага 2), одна быстрая функция, которая делает то же самое, хоть и не так хорошо (опять же из шага 2), и третья функция, которая, глядя на доску, говорит, проиграешь ты или выиграешь, если окажешься в этой ситуации (из шага 3). Всё, теперь мы играем по MCTS и используем первую, чтобы посмотреть, в какие ноды следует соваться из текущей, вторую — чтобы очень быстро просимулировать rollout из текущей позиции, а третью — чтобы напрямую без rollout'а оценить, насколько хороша нода, в которую мы сунулись. Для итоговой value значения, выданные второй и третьей сетями, просто складываются. В результате мы и очень сильно урезаем фактор ветвления, и можем для оценки узла не лезть вниз по дереву (а если лезем, то быстро-быстро).
Да, внезапно этого оказывается достаточно.
В октябре 2015 AlphaGo играет с трёхкратным чемпионом Европы Fan Hui и обыгрывает его со счётом 5:0. Событие, с одной стороны, большое, потому что впервые компьютер выигрывает у профессионала в равных условиях, а с другой — не очень, потому что в мире го чемпион Европы — это примерно чемпион водокачки, и тот же Fan Hui обладает всего лишь вторым профессиональным даном (из девяти возможных). Версия AlphaGo, которая играла в этом матче, получила внутреннее название AlphaGo Fan.
А вот в марте 2016 новая версия AlphaGo играет пять партий уже с одним из лучших игроков мира Lee Sedol и выигрывает со счётом 4:1. Забавно, но сразу после игр в медиа к Ли Седолю стали относиться как к первому топ-игроку, проигравшему ИИ, хотя время расставило всё по местам и на сегодня Седоль остаётся (и, вероятно, останется навсегда) последним человеком, обыгравшим компьютер. Но я забегаю вперёд. Эта версия AlphaGo в дальнейшем стала обозначаться AlphaGo Lee.

Хорошая попытка, Ли, но нет.
После этого, в конце 2016 и начале 2017, уже следующая версия AlphaGo (AlphaGo Master) играет 60 матчей в онлайне с игроками из топовых позиций мирового рейтинга и выигрывает с общим счётом 60:0. В мае AlphaGo Master играет с топ-1 мирового рейтинга Ke Jie и обыгрывает его со счётом 3:0. Собственно, всё, противостояние человека и компьютера в го завершено.
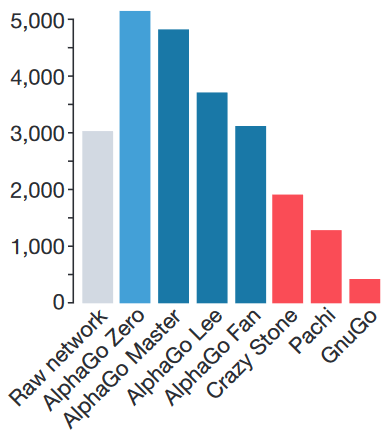
Рейтинг ELO. GnuGo, Pachi и CrazyStone — боты, написанные без использования нейросетей.
Если коротко — для красоты. У сообщества были три относительно большие претензии к AlphaGo:
1) Для стартового обучения используются игры людей. Получается, что без человеческого интеллекта искусственный интеллект не работает.
2) Много заинженеренных фич. Я опустил этот момент в своём пересказе, но в видео и в посте про AlphaGo Lee ему уделяется достаточно внимания, — обе используемые сети получают на вход значительное количество фич, придуманных людьми. Сами по себе эти фичи никакой новой информации не несут и могут быть вычислены, исходя из положения камней на доске, но вот без них сети не справляются. Например, сеть, которая определяет следующий ход, помимо непосредственно стейта получает следующее:
и так далее — в общей сложности 48 слоёв с информацией. А “быстрой” сети, которая предсказывает вероятность победы, и вовсе отдают на вход сто с лишним тысяч заготовленных параметров. Получается, модель учится не играть в го per se, а показывать результаты в некотором заранее очень хорошо подготовленном окружении с большим количеством свойств, о которых ей рассказывает опять же человек.
3) Нужен здоровый кластер, чтобы всё это запустить.
И вот буквально месяц назад Deepmind представили новую версию алгоритма, AlphaGo Zero, в котором все эти проблемы устранены — модель учится с нуля, играя исключительно сама с собой и используя случайные веса нейросети в качестве стартовых; использует только положение камней на доске, чтобы принять решение; и сильно проще по требованиям к железу. Приятным бонусом она обыгрывает AlphaGo Lee в противостоянии из ста партий с общим счётом 100:0.
Две большие штуки.
Во-первых, объединить две сети из прошлых версий AlphaGo в одну. Она получает состояние доски с небольшим количеством фич (я расскажу о них чуть позже), прогоняет всё это добро через свои слои, и в конце два её выхода выдают два результата: policy-выход выдаёт массив 19х19, который показывает, насколько вероятен каждый из ходов из данной позиции, а value выдаёт одно число — вероятность выиграть партию, опять же из данной позиции.
Во-вторых, поменять сам RL-алгоритм. Если раньше непосредственно MCTS использовался только во время игры, то теперь он используется сразу при тренировке. Как это работает.
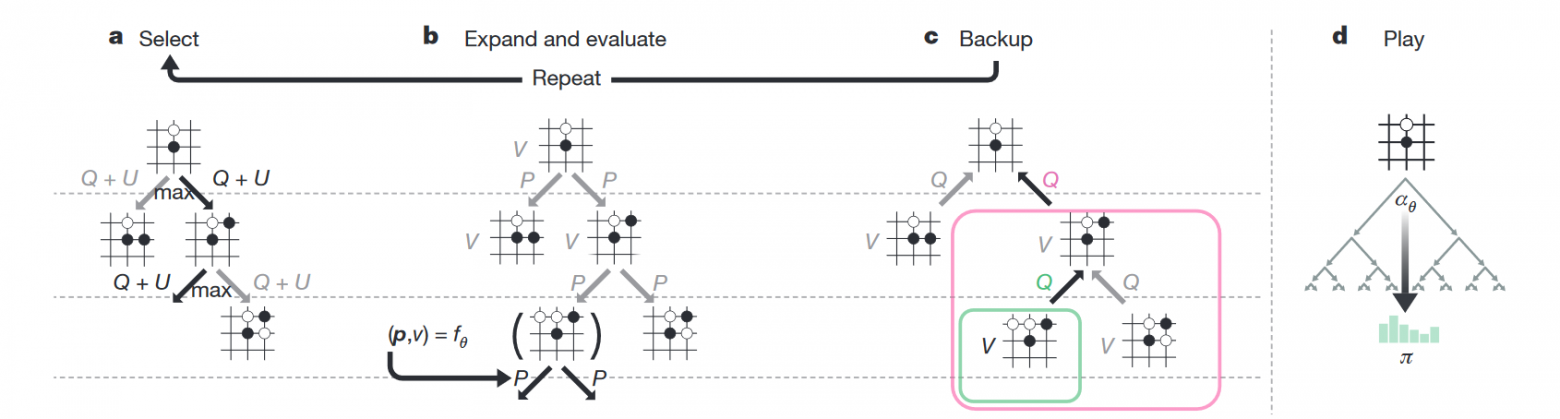
В каждой ноде дерева состояний хранится четыре значения — N (сколько раз мы ходили по этой ноде), V (value этой ноды), Q (усреднённое value всех дочерних нод этой ноды) и P (вероятность, что из всех допустимых на данном ходу нод мы выберем именно эту). Когда сеть играет сама с собой, во время каждого хода она производит следующие симуляции:
Практика показывает, что такая симуляция выдаёт намного более сильные предсказания, нежели базовая нейросеть.
А дальше ход, который сеть действительно сделает, выбирается одним из двух способов:
— Если это реальная игра, идём туда, где больше N (выяснилось, что такая метрика оказывается самой надёжной);
— Если просто тренировка, выбираем ход из распределения Pi ~ N ^ (1/T), где T — просто некоторая температура для контроля баланса между исследованием и эффективностью.
То, что и policy, и value предсказываются одной общей сетью, даёт возможность крайне эффективно всё это запускать. Мы один раз оказались в какой-то ноде, отдали эту ноду в нашу сеть, получили некоторый результат V, все P запомнили, как изначальные веса на дочерних нодах, и всё, больше для этой ноды сеть не задействуем, сколько бы раз через неё ни ходили, а rollout'ов не запускаем вообще, считая, что предсказанный результат и так достаточно точен. Красота.
Тренируется всё это дело, используя вот такой лосс:
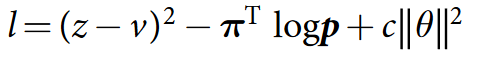
Что это, Бэрримор?
Формула состоит из трёх частей.
В первой части мы говорим, что сеть должна уметь предсказать результат, то есть z (то, с каким результатом закончилась партия) не должно отличаться от v (того value, которое она предсказала).
Во второй части в качестве лейблов для policy используем наши улучшенные вероятности. Это как reward в supervised learning'е — мы хотим как можно точнее предсказать те вероятности, которые получим, пробегаясь по дереву; очень похоже на cross-entropy loss.
Третья часть, c в конце формулы — просто регуляризатор.
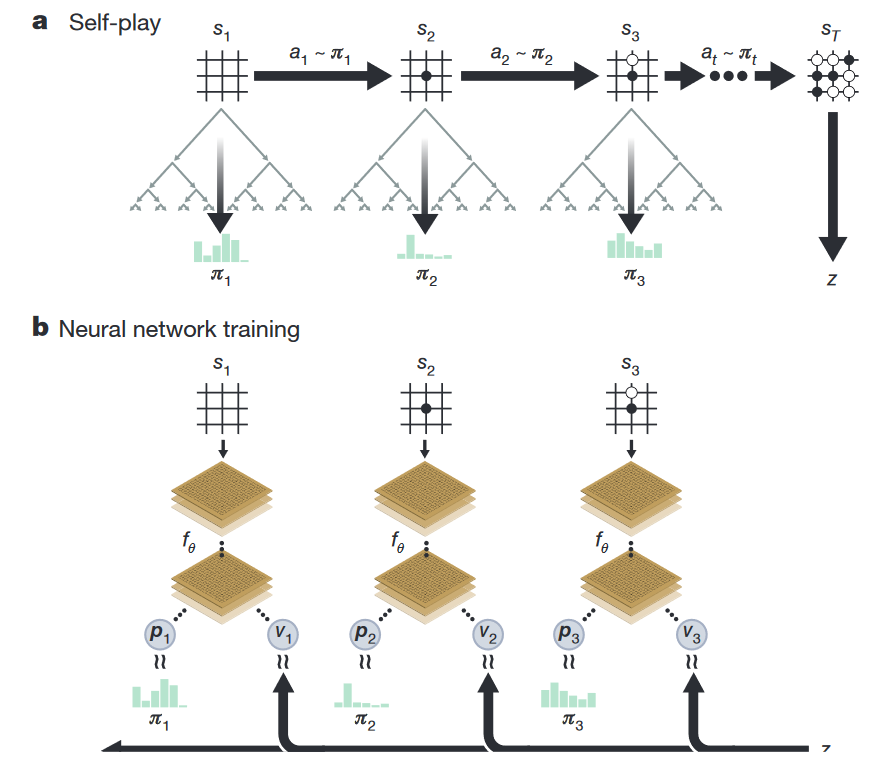
Более глобально, у нас есть некоторая «наилучшая» сеть с весами А. Эта сеть A играет сама с собой 25 000 раз (используя MCTS со своими весами для оценки новых нод), и для каждого хода мы сохраняем сам стейт, распределение Pi и то, чем закончилась игра (+1 за победу и -1 за поражение). Дальше готовим батчи из 2048 случайных позиций из последних 500 000 игр, отдаём 1000 таких батчей на тренировку и получаем некоторую новую сеть с весами B, после чего сеть A играет 400 игр с сетью B — при этом обе сети используют MCTS для выбора хода, только при оценке новой ноды A, очевидно, использует свои веса, а B — свои. Если B побеждает более, чем в 55% случаев, она становится лучшей сетью, если нет — чемпион остаётся прежним. Повторять до готовности.
Ага, было такое. Итак, на вход подаётся поле 19х19, каждый пиксель которого имеет 17 каналов, итого получаем 19х19х17. 17 слоёв нужны для следующего.
Первый говорит, находится ли в данной точке твой камень или нет (1 — стоит, 0 — отсутствует), а дальнейшие семь — находился ли он тут в какой-то из предыдущих семи ходов.
Следующие восемь слоёв — то же самое, но для камней оппонента.
Последний, семнадцатый, слой забит единицами, если ты играешь чёрными, и нулями, если играешь белыми. Это нужно, потому что при финальном подсчёте очков белые получают небольшой бонус за то, что ходят вторыми.
Вот и всё, по факту сеть действительно видит только состояние доски, но с информацией о том, камнями какого цвета она играет, и историей на восемь ходов.
Convolutional layer, потом 40 residual layer'ов, в конце два выхода — value head и policy head. Я не хочу останавливаться на этом подробно, кому важно — посмотрит сам, а всем остальным конкретные слои вряд ли интересны. Если резюмировать, по сравнению с версией Lee сеть стала больше, добавили batch normalization и появились residual connection. Нововведения очень стандартные, очень мейнстримовые, какого-то отдельного rocket science здесь нет.
И всё это привело вот к таким результатам.
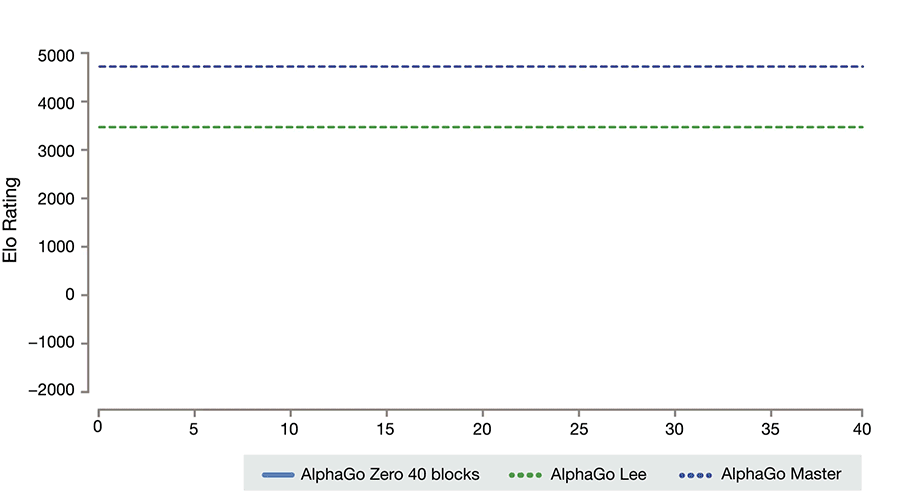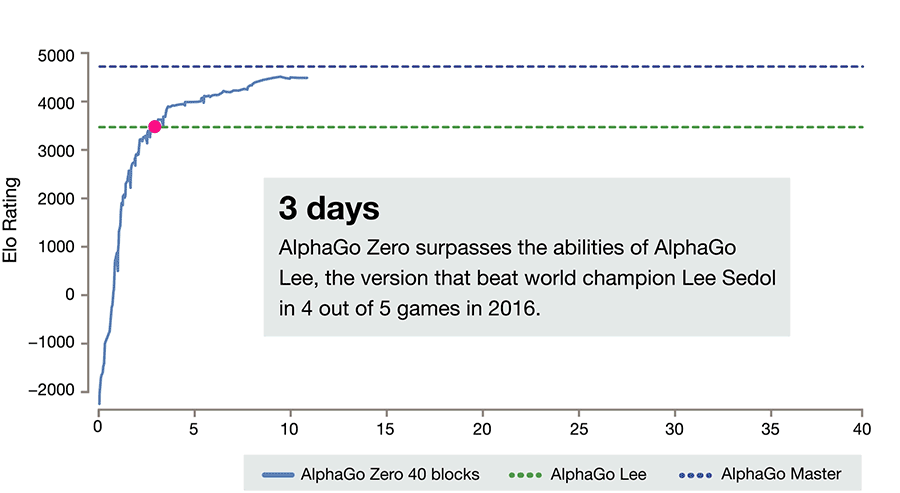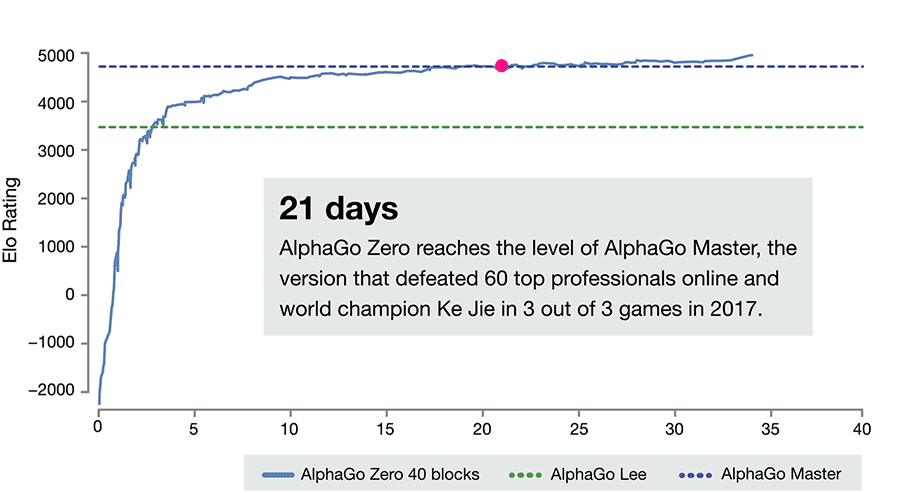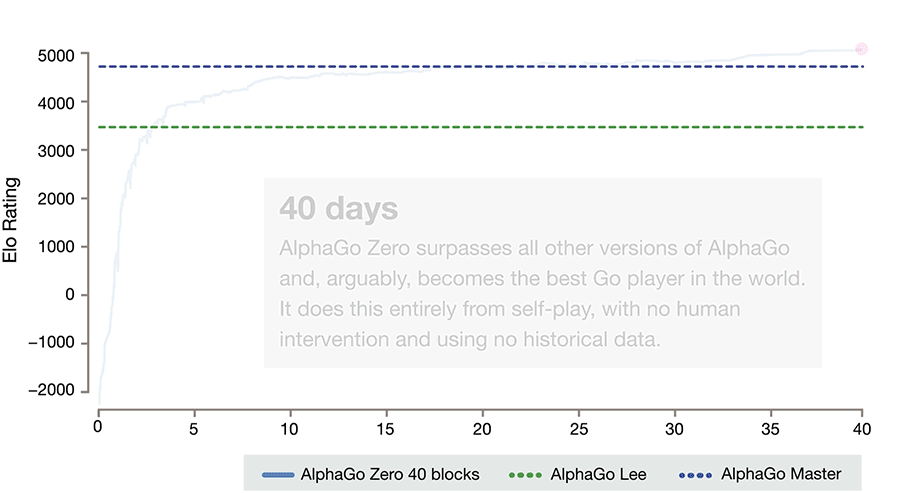
За три дня AlphaGo Zero учится обыгрывать версию Lee, за 21 — Master, а дальше отправляется в космос. После 40 дней тренировки она обыгрывает версию Lee со счётом 100:0 и версию Master со счётом 89:11. В этом свете интересно отметить, что у Master и Zero идентичный алгоритм тренировки, идентичная архитектура, а все отличия заключаются в фичах, подаваемых на вход, и том, что Zero не тренируется на играх людей. И выигрывает.
В го — похоже, что да, мы официально в хурме. В общем случае, нет. У го есть несколько особенностей, крайне важных для текущих методов обучения:
В среде, жёстко ограниченной этими рамками, мы научились строить системы, эффективность которых значительно превышает человеческую. Стоит за рамки немножко выйти, и всё становится сильно сложнее. Поподробнее можно почитать в посте Andrej Karpathy.
В играх — Starcraft и DotA. В обоих направлениях ведётся активная работа, но пока без прорывов сравнимого масштаба. Ждём.
Во-первых, посмотри видео в начале этого поста, оно крутое и охватывает многие вопросы, которые я скипнул.
Во-вторых, почитай пост Семёна про AlphaGo Lee.
В-третьих, приходи в канал #data на closedcircles.com, мы там активно всё это обсуждаем.
В-четвёртых, всё, что я сейчас рассказал про AGZ, есть на одной картинке.
Я закончу этот пост последним параграфом оригинального пейпера:
Humankind has accumulated Go knowledge from millions of games played over thousands of years, collectively distilled into patterns, proverbs and books. In the space of a few days, starting tabula rasa, AlphaGo Zero was able to rediscover much of this Go knowledge, as well as novel strategies that provide new insights into the oldest of games.
Просто подумай об этом.
Спасибо всем, у кого хватило терпения доскроллить до этого места. Отдельная благодарность пользователям sim0nsays за контент и комментарии и buriy за помощь в вычитке.
19 октября 2017 года команда Deepmind опубликовала в Nature статью, краткая суть которой сводится к тому, что их новая модель AlphaGo Zero не только разгромно обыгрывает прошлые версии сети, но ещё и не требует никакого человеческого участия в процессе тренировки. Естественно, это заявление произвело в AI-коммьюнити эффект разорвавшейся бомбы, и всем тут же стало интересно, за счёт чего удалось добиться такого успеха.
По мотивам материалов, находящихся в открытом доступе, Семён sim0nsays записал отличный стрим:
А для тех, кому проще два раза прочитать, чем один раз увидеть, я сейчас попробую объяснить всё это буквами.
Сразу хочу отметить, что стрим и статья собирались в значительной степени по мотивам дискуссий на closedcircles.com, отсюда и спектр рассмотренных вопросов, и специфическая манера повествования.
Ну, поехали.
Что такое го?
Го — это древняя (по разным оценкам, ей от 2 до 5 тысяч лет) настольная стратегическая игра. Есть поле, расчерченное перпендикулярными линиями. Есть два игрока, у одного в мешочке белые камни, у другого — чёрные. Игроки по очереди выставляют камни на пересечение линий. Камни одного цвета, окружённые по четырём направлениям камнями другого цвета, снимаются с доски:
Выигрывает тот, кто к концу партии «окружит» большую по площади территорию. Там есть ещё несколько тонкостей, но базово это всё — человеку, который видит го первый раз в жизни, вполне реально объяснить правила за пять минут.
И почему это считается сложным?
Окей, давай попробуем сравнить несколько настольных игр.
Начнём с шашек. В шашках у игрока есть примерно 10 вариантов того, какой сделать ход. В 1994 году чемпион мира по шашкам был обыгран программой, написанной исследователями из университета Альберты.
Дальше шахматы. В шахматах игрок выбирает в среднем из 20 допустимых ходов и делает такой выбор приблизительно 50 раз за игру. В 1997 году Deep Blue, созданная командой IBM программа, обыграла чемпиона мира по шахматам Гарри Каспарова.
Теперь го. Профессионалы играют в го на поле размера 19х19, что даёт 361 вариант того, куда можно поставить камень. Отсекая откровенно проигрышные ходы и точки, занятые другими камнями, мы всё равно получаем выбор из более чем 200 опций, который требуется совершить в среднем 50-70 раз за партию. Ситуация осложняется тем, что камни взаимодействуют между собой, образуя построения, и в результате камень, поставленный на 35 ходу, может принести пользу только на 115. А может не принести. А чаще всего вообще трудно понять, помог нам этот ход или помешал. Тем не менее, в 2016 году программа AlphaGo обыграла сильнейшего (по меньшей мере, одного из сильнейших) игрока в мире Ли Седоля в серии из пяти игр со счётом 4:1.
Почему на победу в го потребовалось столько времени? Там так много вариантов?
Грубо говоря, да. И в шашках, и в шахматах, и в го общий принцип, по которому работают алгоритмы, один и тот же. Все эти игры попадают в категорию игр с полной информацией, значит, мы можем построить дерево всех возможных состояний игры. Поэтому мы банально строим такое дерево, а дальше просто идём по ветке, которая приводит к победе. Тонкость в том, что для го дерево получается ну очень большим из-за лютого фактора ветвления и впечатляющей глубины, и ни построить, ни обойти его за адекватное время не представлялось возможным. Именно эту проблему смогли решить ребята из DeepMind.
И как они победили?
Тут начинается интересное.
Сначала давай поговорим о том, как работали алгоритмы игры в го до AlphaGo. Все они показывали не самые впечатляющие результаты и успешно играли примерно на уровне среднего любителя, и все опирались на метод под названием Monte Carlo Tree Search — MCTS. Идея в чём (с этим важно разобраться).
У тебя есть дерево состояний — ходов. Из данной конкретной ситуации ты идёшь по какой-то из веток этого дерева, пока она не закончится. Когда ветка заканчивается, добавляешь в неё новый узел (ноду), тем самым инкрементально это дерево достраивая. А потом добавленную ноду оцениваешь, чтобы в дальнейшем определять, стоит ходить по данной ветке или не стоит, не раскрывая само дерево.
Чуть детальнее, это работает следующим образом:
Шаг первый, Selection: у нас есть дерево позиций, и мы каждый раз совершаем ход, выбирая наилучший дочерний узел для текущей позиции.
Шаг второй, Expansion: допустим, мы дошли до конца дерева, но это ещё не конец игры. Просто создаём новую дочернюю ноду и идём в неё.
Шаг третий, Simulation: хорошо, появилась новая нода, фактически, игровая ситуация, в которой мы оказались впервые. Теперь надо её оценить, то есть понять, в хорошей мы оказались ситуации или не очень. Как это сделать? В базовой концепции — используя так называемый rollout: просто сыграть партию (или много партий) из текущей позиции и посмотреть, выиграли мы или проиграли. Получившийся результат и считаем оценкой узла.
Шаг четвёртый, Backpropagation: идём вверх по дереву и увеличиваем или уменьшаем веса всех родительских нод в зависимости от того, хороша новая нода или плоха. Пока важно понять общий принцип, мы ещё успеем рассмотреть данный этап в деталях.
В каждой ноде сохраняем два значения: оценку (value) текущей ноды и количество раз, которое мы по ней пробегали. И повторяем цикл из этих четырёх шагов много-много раз.
Как мы выбираем дочернюю ноду на первом шаге?
В самом простом варианте — берём ноду, у которой будет наивысший показатель Upper Confidence Bounds (UCB):
Здесь v — это value нашей ноды, n — сколько раз мы в этой ноде были, N — сколько раз были в родительской ноде, а C — просто некоторый коэффициент.
В не самом простом варианте можно усложнять формулу, чтобы получить более точные результаты, или вообще использовать какую-то другую эвристику, например, нейросеть. Об этом подходе мы тоже ещё поговорим.
Если смотреть чуть шире, перед нами классическая multi-armed bandit problem. Задача — найти такую функцию выбора узла, которая обеспечит оптимальный баланс между использованием лучших из имеющихся вариантов и исследованием новых возможностей.
Почему это работает?
Потому что с MCTS дерево решений растёт асимметрично: более интересные ноды посещаются чаще, менее интересные — реже, а оценить отдельно взятую ноду становится возможным без раскрытия всего дерева.
Это имеет какое-то отношение к AlphaGo?
В общем и целом, AlphaGo опирается на те же самые принципы. Ключевое отличие — когда на втором этапе мы добавляем новую ноду, для того, чтобы определить, насколько она хорошая, вместо rollout'ов используем нейросеть. Как мы это делаем.
(Я совсем в двух словах расскажу про прошлую версию AlphaGo, хотя на самом деле в ней хватает интересных нюансов; кто хочет подробностей — вэлком в видео в начале, там они хорошо объясняются, или в соответствующий пост на хабре, там они хорошо расписаны).
Во-первых, тренируем две сети, каждая из которых получает на вход состояние доски и говорит, какой бы ход в этой ситуации сделал человек. Почему две? Потому что одна — медленная, но работает хорошо (57% верных предсказаний, и каждый дополнительный процент даёт очень солидный бонус к итоговому результату), а вторая обладает намного меньшей точностью, зато быстрая.
Обе эти сети, медленную и быструю, мы тренируем на человеческих ходах — банально идём на сервер го, забираем партии игроков хорошего уровня, парсим и скармливаем для обучения.
Во-вторых, берём две эти натренированные «на людях» сети и начинаем играть ими сами с собой, чтобы их прокачать.
Примерно так.
В-третьих, тренируем value-сеть, которая получает на вход текущее состояние доски, а в ответ отдаёт число от -1 до 1 — вероятность выиграть, оказавшись в этой позиции в какой-то момент партии.
Таким образом, у нас есть одна медленная и точная функция, которая говорит, куда надо ходить (из шага 2), одна быстрая функция, которая делает то же самое, хоть и не так хорошо (опять же из шага 2), и третья функция, которая, глядя на доску, говорит, проиграешь ты или выиграешь, если окажешься в этой ситуации (из шага 3). Всё, теперь мы играем по MCTS и используем первую, чтобы посмотреть, в какие ноды следует соваться из текущей, вторую — чтобы очень быстро просимулировать rollout из текущей позиции, а третью — чтобы напрямую без rollout'а оценить, насколько хороша нода, в которую мы сунулись. Для итоговой value значения, выданные второй и третьей сетями, просто складываются. В результате мы и очень сильно урезаем фактор ветвления, и можем для оценки узла не лезть вниз по дереву (а если лезем, то быстро-быстро).
И это работает прям сильно лучше, чем вариант без нейросетей?
Да, внезапно этого оказывается достаточно.
В октябре 2015 AlphaGo играет с трёхкратным чемпионом Европы Fan Hui и обыгрывает его со счётом 5:0. Событие, с одной стороны, большое, потому что впервые компьютер выигрывает у профессионала в равных условиях, а с другой — не очень, потому что в мире го чемпион Европы — это примерно чемпион водокачки, и тот же Fan Hui обладает всего лишь вторым профессиональным даном (из девяти возможных). Версия AlphaGo, которая играла в этом матче, получила внутреннее название AlphaGo Fan.
А вот в марте 2016 новая версия AlphaGo играет пять партий уже с одним из лучших игроков мира Lee Sedol и выигрывает со счётом 4:1. Забавно, но сразу после игр в медиа к Ли Седолю стали относиться как к первому топ-игроку, проигравшему ИИ, хотя время расставило всё по местам и на сегодня Седоль остаётся (и, вероятно, останется навсегда) последним человеком, обыгравшим компьютер. Но я забегаю вперёд. Эта версия AlphaGo в дальнейшем стала обозначаться AlphaGo Lee.
Хорошая попытка, Ли, но нет.
После этого, в конце 2016 и начале 2017, уже следующая версия AlphaGo (AlphaGo Master) играет 60 матчей в онлайне с игроками из топовых позиций мирового рейтинга и выигрывает с общим счётом 60:0. В мае AlphaGo Master играет с топ-1 мирового рейтинга Ke Jie и обыгрывает его со счётом 3:0. Собственно, всё, противостояние человека и компьютера в го завершено.
Рейтинг ELO. GnuGo, Pachi и CrazyStone — боты, написанные без использования нейросетей.
Но раз они и так всех обыграли, зачем понадобилась ещё одна сеть?
Если коротко — для красоты. У сообщества были три относительно большие претензии к AlphaGo:
1) Для стартового обучения используются игры людей. Получается, что без человеческого интеллекта искусственный интеллект не работает.
2) Много заинженеренных фич. Я опустил этот момент в своём пересказе, но в видео и в посте про AlphaGo Lee ему уделяется достаточно внимания, — обе используемые сети получают на вход значительное количество фич, придуманных людьми. Сами по себе эти фичи никакой новой информации не несут и могут быть вычислены, исходя из положения камней на доске, но вот без них сети не справляются. Например, сеть, которая определяет следующий ход, помимо непосредственно стейта получает следующее:
- сколько ходов назад был поставлен тот или иной камень;
- сколько свободных точек вокруг данного камня;
- сколько своих камней ты пожертвуешь, если сходишь в данную точку;
- легален ли вообще данный ход, то есть позволяется ли он правилами го;
- поучаствует ли камень, поставленный в эту точку, в так называемом “лестничном” построении;
и так далее — в общей сложности 48 слоёв с информацией. А “быстрой” сети, которая предсказывает вероятность победы, и вовсе отдают на вход сто с лишним тысяч заготовленных параметров. Получается, модель учится не играть в го per se, а показывать результаты в некотором заранее очень хорошо подготовленном окружении с большим количеством свойств, о которых ей рассказывает опять же человек.
3) Нужен здоровый кластер, чтобы всё это запустить.
И вот буквально месяц назад Deepmind представили новую версию алгоритма, AlphaGo Zero, в котором все эти проблемы устранены — модель учится с нуля, играя исключительно сама с собой и используя случайные веса нейросети в качестве стартовых; использует только положение камней на доске, чтобы принять решение; и сильно проще по требованиям к железу. Приятным бонусом она обыгрывает AlphaGo Lee в противостоянии из ста партий с общим счётом 100:0.
Так, и что для этого пришлось сделать?
Две большие штуки.
Во-первых, объединить две сети из прошлых версий AlphaGo в одну. Она получает состояние доски с небольшим количеством фич (я расскажу о них чуть позже), прогоняет всё это добро через свои слои, и в конце два её выхода выдают два результата: policy-выход выдаёт массив 19х19, который показывает, насколько вероятен каждый из ходов из данной позиции, а value выдаёт одно число — вероятность выиграть партию, опять же из данной позиции.
Во-вторых, поменять сам RL-алгоритм. Если раньше непосредственно MCTS использовался только во время игры, то теперь он используется сразу при тренировке. Как это работает.
В каждой ноде дерева состояний хранится четыре значения — N (сколько раз мы ходили по этой ноде), V (value этой ноды), Q (усреднённое value всех дочерних нод этой ноды) и P (вероятность, что из всех допустимых на данном ходу нод мы выберем именно эту). Когда сеть играет сама с собой, во время каждого хода она производит следующие симуляции:
- Берёт дерево, корнем которого является текущая нода.
- Идёт в ту дочернюю ноду, где больше Q + U (U — добавка, стимулирующая поиск новых путей; она больше в начале тренировки и меньше — в дальнейшем).
- Таким нехитрым образом доходит до конца дерева — состояния, когда дочерних узлов нет, а игра ещё не закончена.
- Отдаёт это состояние на вход нейросети, в ответ получает v (value текущей ноды) и p (вероятности следующих ходов).
- Записывает v в ноду.
- Создаёт дочерние ноды с P согласно p и нулевыми N, V и Q.
- Обновляет все ноды выше текущей, которые были выбраны во время симуляции, следующим образом: N := N + 1; V := V + v; Q := V / N.
- Повторяет цикл 1-7 1600 раз.
Практика показывает, что такая симуляция выдаёт намного более сильные предсказания, нежели базовая нейросеть.
А дальше ход, который сеть действительно сделает, выбирается одним из двух способов:
— Если это реальная игра, идём туда, где больше N (выяснилось, что такая метрика оказывается самой надёжной);
— Если просто тренировка, выбираем ход из распределения Pi ~ N ^ (1/T), где T — просто некоторая температура для контроля баланса между исследованием и эффективностью.
То, что и policy, и value предсказываются одной общей сетью, даёт возможность крайне эффективно всё это запускать. Мы один раз оказались в какой-то ноде, отдали эту ноду в нашу сеть, получили некоторый результат V, все P запомнили, как изначальные веса на дочерних нодах, и всё, больше для этой ноды сеть не задействуем, сколько бы раз через неё ни ходили, а rollout'ов не запускаем вообще, считая, что предсказанный результат и так достаточно точен. Красота.
Как тренировать сеть, которая должна предсказывать и policy, и value?
Тренируется всё это дело, используя вот такой лосс:
Что это, Бэрримор?
Формула состоит из трёх частей.
В первой части мы говорим, что сеть должна уметь предсказать результат, то есть z (то, с каким результатом закончилась партия) не должно отличаться от v (того value, которое она предсказала).
Во второй части в качестве лейблов для policy используем наши улучшенные вероятности. Это как reward в supervised learning'е — мы хотим как можно точнее предсказать те вероятности, которые получим, пробегаясь по дереву; очень похоже на cross-entropy loss.
Третья часть, c в конце формулы — просто регуляризатор.
Более глобально, у нас есть некоторая «наилучшая» сеть с весами А. Эта сеть A играет сама с собой 25 000 раз (используя MCTS со своими весами для оценки новых нод), и для каждого хода мы сохраняем сам стейт, распределение Pi и то, чем закончилась игра (+1 за победу и -1 за поражение). Дальше готовим батчи из 2048 случайных позиций из последних 500 000 игр, отдаём 1000 таких батчей на тренировку и получаем некоторую новую сеть с весами B, после чего сеть A играет 400 игр с сетью B — при этом обе сети используют MCTS для выбора хода, только при оценке новой ноды A, очевидно, использует свои веса, а B — свои. Если B побеждает более, чем в 55% случаев, она становится лучшей сетью, если нет — чемпион остаётся прежним. Повторять до готовности.
И ты ещё обещал рассказать про фичи, которые подаются на вход.
Ага, было такое. Итак, на вход подаётся поле 19х19, каждый пиксель которого имеет 17 каналов, итого получаем 19х19х17. 17 слоёв нужны для следующего.
Первый говорит, находится ли в данной точке твой камень или нет (1 — стоит, 0 — отсутствует), а дальнейшие семь — находился ли он тут в какой-то из предыдущих семи ходов.
Зачем это нужно
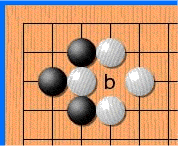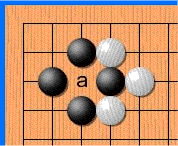
Дело в том, что в го запрещены повторения — в ряде случаев ты не можешь поставить камень туда, где он уже стоял. Как на картинке:
Не знаю, почему, но хабр иногда отказывается проигрывать эту гифку. Если так и произошло и ты не видишь анимации — просто кликни на неё.
Белые делают ход в точку a и забирают камень чёрных. Чёрные делают ход в точку b и забирают камень белых. Без запрета повторений оппоненты могли бы сидеть и играть последовательность a-b до бесконечности. В реальности же белые не могут сразу повторно сходить в позицию a и должны выбрать другой ход (а вот уже после какого-то иного хода сходить в позицию a разрешено). Именно для того, чтобы сеть могла научиться этому правилу, ей и передают историю. Вторая причина — в АМА на реддите разработчики рассказывали, что когда сеть видит, где в последнее время была активность, она лучше учится. По мысли это чем-то похоже на attention.
Не знаю, почему, но хабр иногда отказывается проигрывать эту гифку. Если так и произошло и ты не видишь анимации — просто кликни на неё.
Белые делают ход в точку a и забирают камень чёрных. Чёрные делают ход в точку b и забирают камень белых. Без запрета повторений оппоненты могли бы сидеть и играть последовательность a-b до бесконечности. В реальности же белые не могут сразу повторно сходить в позицию a и должны выбрать другой ход (а вот уже после какого-то иного хода сходить в позицию a разрешено). Именно для того, чтобы сеть могла научиться этому правилу, ей и передают историю. Вторая причина — в АМА на реддите разработчики рассказывали, что когда сеть видит, где в последнее время была активность, она лучше учится. По мысли это чем-то похоже на attention.
Следующие восемь слоёв — то же самое, но для камней оппонента.
Последний, семнадцатый, слой забит единицами, если ты играешь чёрными, и нулями, если играешь белыми. Это нужно, потому что при финальном подсчёте очков белые получают небольшой бонус за то, что ходят вторыми.
Вот и всё, по факту сеть действительно видит только состояние доски, но с информацией о том, камнями какого цвета она играет, и историей на восемь ходов.
А что с архитектурой?
Convolutional layer, потом 40 residual layer'ов, в конце два выхода — value head и policy head. Я не хочу останавливаться на этом подробно, кому важно — посмотрит сам, а всем остальным конкретные слои вряд ли интересны. Если резюмировать, по сравнению с версией Lee сеть стала больше, добавили batch normalization и появились residual connection. Нововведения очень стандартные, очень мейнстримовые, какого-то отдельного rocket science здесь нет.
И всё это чтобы что?
И всё это привело вот к таким результатам.
За три дня AlphaGo Zero учится обыгрывать версию Lee, за 21 — Master, а дальше отправляется в космос. После 40 дней тренировки она обыгрывает версию Lee со счётом 100:0 и версию Master со счётом 89:11. В этом свете интересно отметить, что у Master и Zero идентичный алгоритм тренировки, идентичная архитектура, а все отличия заключаются в фичах, подаваемых на вход, и том, что Zero не тренируется на играх людей. И выигрывает.
То есть всё, компьютер умнее, у человечества шансов нет?
В го — похоже, что да, мы официально в хурме. В общем случае, нет. У го есть несколько особенностей, крайне важных для текущих методов обучения:
- Всегда точно определённая среда, для которой есть идеальный и простой симулятор; никаких случайностей, никаких внешних вмешательств.
- Го — игра с полной информацией. Немножко похоже на предыдущий пункт, но тем не менее — нам известно абсолютно всё, что происходит.
В среде, жёстко ограниченной этими рамками, мы научились строить системы, эффективность которых значительно превышает человеческую. Стоит за рамки немножко выйти, и всё становится сильно сложнее. Поподробнее можно почитать в посте Andrej Karpathy.
А следующий бастион какой?
В играх — Starcraft и DotA. В обоих направлениях ведётся активная работа, но пока без прорывов сравнимого масштаба. Ждём.
Ух! Кажется, немножко понятно. Что ещё можно посмотреть по теме?
Во-первых, посмотри видео в начале этого поста, оно крутое и охватывает многие вопросы, которые я скипнул.
Во-вторых, почитай пост Семёна про AlphaGo Lee.
В-третьих, приходи в канал #data на closedcircles.com, мы там активно всё это обсуждаем.
В-четвёртых, всё, что я сейчас рассказал про AGZ, есть на одной картинке.
И давай финалочку.
Я закончу этот пост последним параграфом оригинального пейпера:
Humankind has accumulated Go knowledge from millions of games played over thousands of years, collectively distilled into patterns, proverbs and books. In the space of a few days, starting tabula rasa, AlphaGo Zero was able to rediscover much of this Go knowledge, as well as novel strategies that provide new insights into the oldest of games.
Просто подумай об этом.
Спасибо всем, у кого хватило терпения доскроллить до этого места. Отдельная благодарность пользователям sim0nsays за контент и комментарии и buriy за помощь в вычитке.


{kind=link}