Я написал программу для очистки отсканированных конспектов с одновременным уменьшением размера файла.
Исходное изображение и результат:

Слева: исходный скан на 300 DPI, 7,2 МБ PNG / 790 КБ JPG. Справа: результат с тем же разрешением, 121 КБ PNG [1]
Примечание: описанный здесь процесс более-менее совпадает с работой приложения Office Lens. Есть другие аналогичные программы. Я не утверждаю, что придумал нечто радикальное новое — это просто моя реализация полезного инструмента.
Если торопитесь, просто посмотрите репозиторий GitHub или перейдите в раздел результатов, где можно поиграться с интерактивными 3D-диаграммами цветовых кластеров.
По некоторым из моих предметов нет учебников. Для таких студентов я люблю устраивать еженедельные «переписывания», когда они делятся своими конспектами с остальными и проверяют, насколько усвоили материал. Конспекты выкладываются на веб-сайте курса в формате PDF.
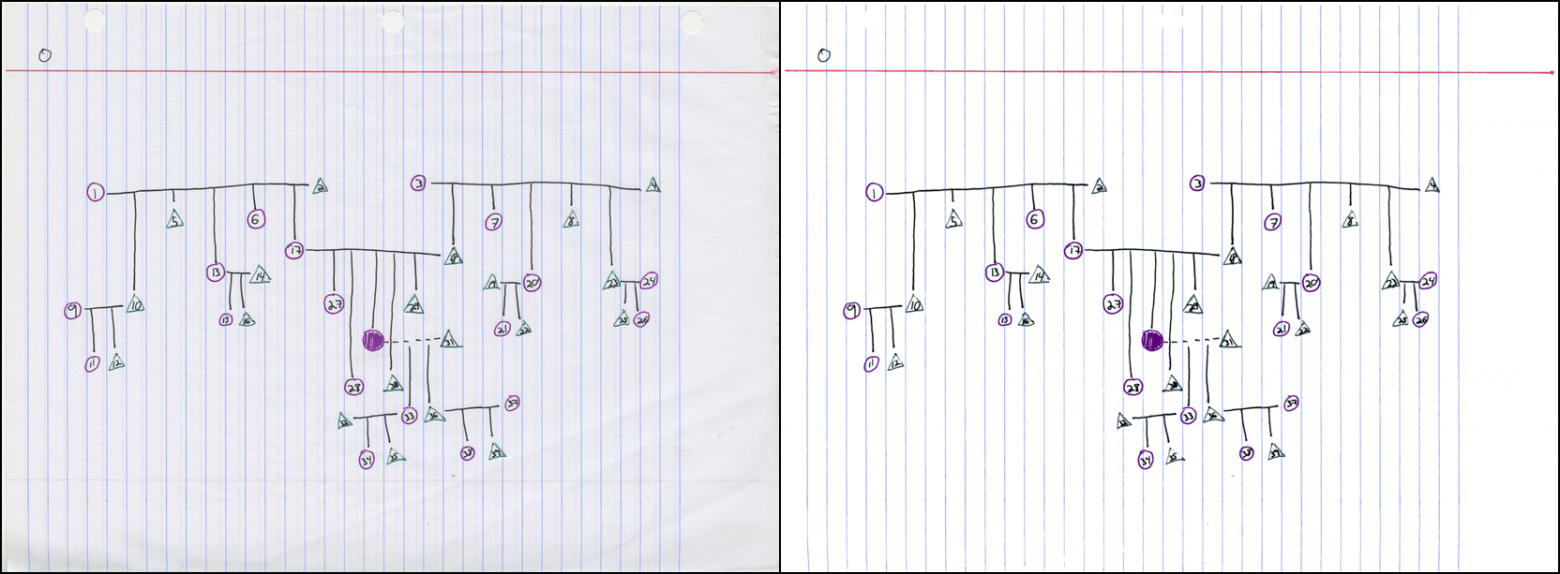
На факультете есть «умный» копир, который сразу сканирует в PDF, но результат такого сканирования… менее чем приятен. Вот некоторые примеры сканирования домашней работы студента:

Как будто случайным образом копир выбирает одно из двух: или бинаризацию знака (символы x), или преобразование в ужасные JPEG-блоки (символы квадратного корня). Очевидно, такой результат можно улучшить.
Начнём со сканирования такой прекрасной страницы студенческого конспекта:

Оригинальный PNG на 300 DPI весит около 7,2 МБ. Изображение в JPG с уровнем сжатия 85 занимает около 790 КБ2. Поскольку PDF — обычно просто контейнер для PNG или JPG, то при конвертации в PDF вы не сожмёте файл ещё сильнее. 800 килобайт на страницу это довольно много, и ради ускорения загрузки я бы хотел бы получить что-то ближе к 100 КБ3.
Хотя этот студент очень аккуратно ведёт конспект, результат сканирования выглядит немного неряшливо (не по его вине). Заметно просвечивается обратная сторона листа, что и отвлекает читателя, и мешает эффективному сжатию JPG или PNG по сравнению с ровным фоном.
Вот что выдаёт программа

Это крошечный файл PNG размером всего 121 КБ. Знаете, что мне нравится больше всего? Кроме уменьшения размера, конспект стал и разборчивее!
Вот шаги для создания компактного и чистого изображения:
Прежде чем углубиться в тему, полезно вспомнить, как цветные изображения хранятся в цифровом виде. Поскольку в глазу человека три типа цветочувствительных клеток, мы можем восстановить любой цвет, изменяя интенсивность красного, зелёного и синего света4. В результате получается система, которая присваивает цветам точки в трёхмерном цветовом пространстве RGB5.
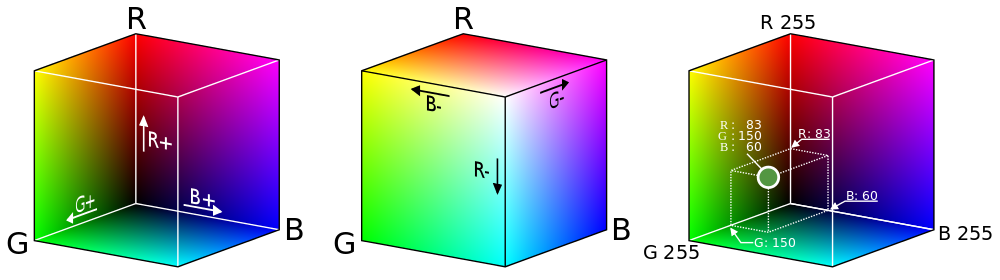
Хотя истинное векторное пространство допускает бесконечное число непрерывно изменяющихся значений интенсивности, для хранения в цифровом виде мы дискретизируем цвета, обычно выделяя по 8 бит каждому из каналов: красному, зелёному и синему. Однако если рассматривать цвета как точки в непрерывном трёхмерном пространстве, то становятся доступны мощные инструменты для анализа, как показано далее в описании процесса.
Поскольку основная часть страницы — чистая, то можно ожидать, что цветом бумаги станет самый часто встречающийся цвет на отсканированном изображении. И если бы сканер всегда представлял каждую точку чистой бумаги как одинаковый триплет RGB, у нас не было бы проблем. К сожалению, это не так. Случайные изменения в цвете возникают из-за пыли и пятен на стекле, цветовых вариаций самой бумаги, шума на сенсоре и т.д. Таким образом, реальный «цвет страницы» может распределяться по тысячам различных значений RGB.
Исходное отсканированное изображение имеет размер 2081×2531, общая площадь 5 267 011 пикселей. Хотя можно рассмотреть все пиксели, но гораздо быстрее взять репрезентативную выборку исходного изображения. Программа

Оно мало похожа на реальный скан — здесь нет текста, но распределение цветов практически идентично. Оба изображения в основном серовато-белые, с горсткой красных, синих и тёмно-серых пикселей. Вот те же 10 000 пикселей, отсортированные по яркости (то есть по сумме интенсивности каналов R, G и B):

Если смотреть издалека, то нижние 80-90% изображения кажутся одним и тем же цветом, но при ближайшем рассмотрении заметно довольно много вариаций. На самом деле на изображении чаще всего встречается цвет со значением RGB (240, 240, 242), и он представлен всего на 226 из 10 000 пикселей — не более 3% от общего количества.
Поскольку мода представляет настолько малый процент выборки, то возникает вопрос, насколько точно она соответствует распределению цветов. Проще определить фоновый цвет страницы, если сначала уменьшить глубину цвета. Вот как выглядит выборка, если снизить глубину с 8 до 4 бит на канал, обнулив четыре наименее значимых бита:

Теперь чаще всего встречается значение RGB (224, 224, 224), которое составляет 3623 (36%) выбранных точек. По сути, уменьшив глубину цвета, мы сгруппировали похожие пиксели в «корзины» большего размера, что облегчило поиск явного пика6.
Здесь определённый компромисс между надёжностью и точностью: небольшие корзины обеспечивают лучшую точность цветов, но большие корзины гораздо более надёжны. В конце концов, для выбора цвета фона я остановился на 6 битах на канал, что показалось оптимальным вариантом между двумя крайностями.
После того, как мы определили цвет фона, нужно выбрать пороговое значение (threshold) для остальных пикселей по степени близости к фону. Естественный способ определить сходство двух цветов — вычислить евклидово расстояние между их координатами в пространстве RGB. Но этот простой метод неправильно сегментирует некоторые цвета:

Вот таблица с цветами и евклидовым расстоянием от фона:
Как видите, тёмно-серый цвет от просвечивающихся чернил, которые нужно классифицировать как фон, на самом деле находится дальше от белого цвета страницы, чем розовый цвет линии, которую мы хотим классифицировать как передний план. Любой порог в евклидовом расстоянии, который сделает розовый цвет передним планом, обязательно включит в себя и просвечивающиеся чернила.
Можно обойти эту проблему, перейдя из пространства RGB в пространство Hue-Saturation-Value (HSV), которое преобразует куб RGB в цилиндр, показанный здесь в разрезе7.

В цилиндре HSV радуга цветов распределена по окружности внешнего верхнего края; значение hue (цветовой тон) соответствует углу на окружности. Центральная ось цилиндра переходит от чёрного внизу до белого вверху с серыми оттенками посредине — вся эта ось имеет нулевую насыщенность или интенсивность цвета, а у ярких оттенков на внешней окружности насыщенность 1,0. Наконец, значение цвета value характеризует общую яркость цвета, от чёрного внизу до ярких оттенков вверху.
Итак, теперь пересмотрим теперь на наши цвета в модели HSV:
Как и следовало ожидать, белый, чёрный и серый значительно различаются по значению цвета, но имеют аналогичные низкие уровни насыщенности — значительно меньше красного или розового. С помощью дополнительной информации в модели HSV можно успешно пометить пиксель как принадлежащий переднему плану, если он соответствует одному из критериев:
Первый критерий забирает чёрные чернила от ручки, а второй — красные чернила и розовую линию. Оба критерия успешно убирают с переднего плана серые пиксели просвечивающихся чернил. Для разных изображений можно использовать разные пороги насыщенности/значения цвета; для дополнительной информации см. раздел с результатами.
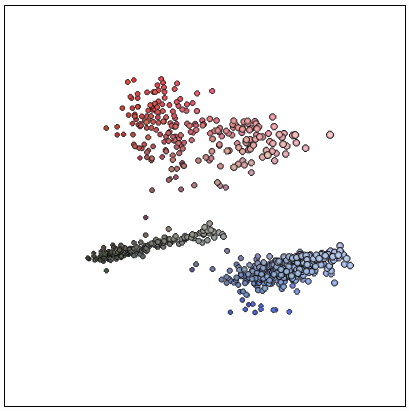
Как только мы изолировали передний план, то получили новый набор цветов, соответствующих отметкам на странице. Давайте визуализируем его — но на этот раз будем рассматривать цвета не как набор пикселей, а как 3D-точки в цветовом пространстве RGB. Результирующая диаграмма выглядит слегка «скученной», с несколькими полосами связанных цветов.
Интерактивная диаграмма по ссылке
Теперь наша цель — преобразовать исходное 24-битное изображение в индексированный цвет, выбрав небольшое количество цветов (в данном случае восемь) для представления всего изображения. Во-первых, это уменьшает размер файла, потому что цвет теперь определяется всего тремя битами (так как 8=2³). Во-вторых, полученное изображение становится более визуально сплочённым, потому что похожим цветным чернильным точкам, вероятно, будет назначен одинаковый цвет в итоговом изображении.
Для этого используем метод на основе данных со «скученной» диаграммы, упомянутой выше. Если выбрать цвета, соответствующие центрам кластеров, то получим набор цветов, точно представляющих исходные данные. С технической точки зрения мы решаем проблему квантования цвета (которая сама по себе является частным случаем векторного квантования) с помощью кластерного анализа.
Для этой работы я выбрал конкретный методологический инструмент — метод k-средних. Его цель — найти набор средних значений или центров, которые минимизируют среднее расстояние от каждой точки до ближайшего центра. Вот что получится, если выбрать семь различных кластеров в нашем наборе данных8.
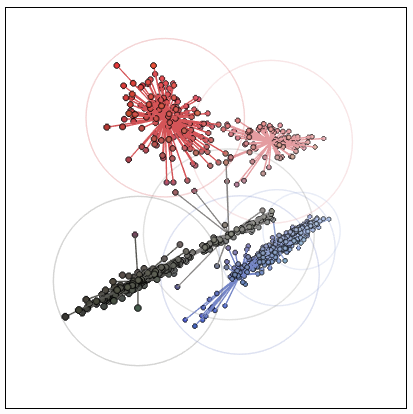
Здесь точки с чёрными контурами соответствуют цветам переднего плана, а цветные линии соединяют их с ближайшим центром в пространстве RGB. Когда изображение преобразуется в индексированный цвет, каждый цвет переднего плана заменяется цветом ближайшего центра. Наконец, большие окружности показывают расстояние от каждого центра до самого дальнего связанного цвета.
Кроме установки пороговых значений цвета и насыщенности, в программе

Отрегулированная палитра более яркая:

Есть опция для принудительной смены фона на белый после изоляции цветов переднего плана. Для дальнейшего уменьшения размеров файла
На выходе программа выдаёт такие PDF-файлы с несколькими изображениями, используя программу конвертации от ImageMagick. В качестве дополнительного бонуса
Вот еще несколько примеров вывода программы. Первый (PDF) отлично смотрится с дефолтными пороговыми значениями:
Визуализация цветовых кластеров:

Для следующего (PDF) понадобилось снизить порог насыщенности до 0,045, потому что серо-голубые линии слишком тусклые:
Цветовые кластеры:
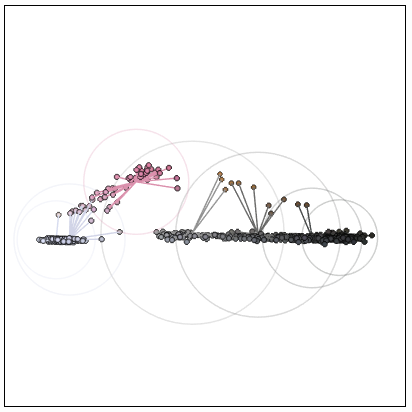
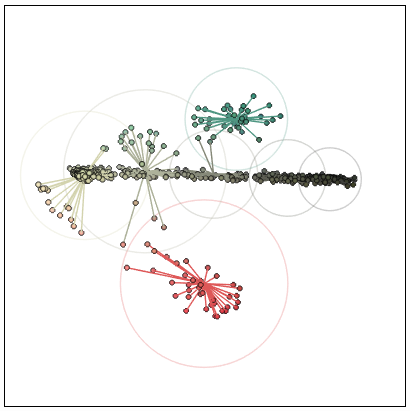
Наконец, пример сканирования миллиметровки (PDF). Для неё я установил пороговое значение 0,05, потому что контраст между фоном и линиями слишком мал:

Цветовые кластеры:
Все вместе четыре PDF-файла занимают около 788 КБ, в среднем около 130 КБ на каждую страницу.
Я рад, что удалось создать полезный инструмент, который можно использовать в подготовке PDF-файлов с конспектами для моих курсов. Кроме того, мне действительно понравилось готовить эту статью, особенно потому что она побудила меня попытаться улучшить важные 2D-визуализации, которые демонстрируются в статье Википедии о квантования цвета, а также наконец-то изучить three.js (очень забавный инструмент, буду использовать его снова).
Если я когда-нибудь вернусь к этому проекту, то хотелось бы поиграть с альтернативными схемами квантования. На этой неделе мне пришла в голову идея использовать спектральную кластеризацию на графе ближайших соседей в наборе цветов — мне показалось, я придумал интересную новую идею, но потом нашёл статью 2012 года, где предлагается именно такой подход. Ну ладно.
Ещё можете попробовать EM-алгоритм для формирования гауссовой модели смеси, которая описывает распределение цветов. Не уверен, что это часто делали в прошлом. Другие интересные идеи: попытка кластеризации в «перцептивно однородном» цветовом пространстве вроде L*a*b*, а также попытка автоматически определять оптимальное количество кластеров для данного изображения.
С другой стороны, нужно разобраться с другими темами для блога, так что я пока оставлю этот проект и предлагаю вам посмотреть репозиторий
1. Образцы конспектов представлены с великодушного разрешения моих студентов Урсулы Монаган и Джона Ларкина. ↑
2. Показанное здесь изображение в реальности уменьшено до 150 DPI, чтобы страница загружалась быстрее. ↑
3. Единственное, что наш копир хорошо делает, так это уменьшает размеры PDF до 50-75 КБ на страницу для документов такого типа. ↑
4. Красный, зелёный, и голубой являются первичными цветами в аддитивной модели. Учитель рисования в начальной школе мог сказать вам, что основные цвета — красный, жёлтый и синий. Это ложь [метод упрощения сложных концепций в системе образования — примеч. пер.]. Однако есть три субтрактивных основных цвета: жёлтый, пурпурный и циан. Аддитивные основные цвета относятся к сочетаниям света (который излучают мониторы), тогда как субтрактивные цвета относятся к сочетаниям пигмента в чернилах и красках. ↑
5. Изображение пользователя Maklaan в Wikimedia Commons. Лицензия: CC BY-SA 3.0 ↑
6. Посмотрите в Википедии диаграмму с распределением чаевых как ещё один пример, почему полезно увеличение размера «корзины». ↑
7. Изображение пользователя SharkD в Wikimedia Commons. Лицензия: CC BY-SA 3.0 ↑
8. Почему k=7, а не 8? Потому что нам нужно восемь цветов в конечном изображении, а мы уже установили цвет фона… ↑
9. Да, я смотрю на тебя, Image Capture из Mac OS… ↑
Исходное изображение и результат:
Слева: исходный скан на 300 DPI, 7,2 МБ PNG / 790 КБ JPG. Справа: результат с тем же разрешением, 121 КБ PNG [1]
Примечание: описанный здесь процесс более-менее совпадает с работой приложения Office Lens. Есть другие аналогичные программы. Я не утверждаю, что придумал нечто радикальное новое — это просто моя реализация полезного инструмента.
Если торопитесь, просто посмотрите репозиторий GitHub или перейдите в раздел результатов, где можно поиграться с интерактивными 3D-диаграммами цветовых кластеров.
Мотивация
По некоторым из моих предметов нет учебников. Для таких студентов я люблю устраивать еженедельные «переписывания», когда они делятся своими конспектами с остальными и проверяют, насколько усвоили материал. Конспекты выкладываются на веб-сайте курса в формате PDF.
На факультете есть «умный» копир, который сразу сканирует в PDF, но результат такого сканирования… менее чем приятен. Вот некоторые примеры сканирования домашней работы студента:
Как будто случайным образом копир выбирает одно из двух: или бинаризацию знака (символы x), или преобразование в ужасные JPEG-блоки (символы квадратного корня). Очевидно, такой результат можно улучшить.
Общее представление
Начнём со сканирования такой прекрасной страницы студенческого конспекта:

Оригинальный PNG на 300 DPI весит около 7,2 МБ. Изображение в JPG с уровнем сжатия 85 занимает около 790 КБ2. Поскольку PDF — обычно просто контейнер для PNG или JPG, то при конвертации в PDF вы не сожмёте файл ещё сильнее. 800 килобайт на страницу это довольно много, и ради ускорения загрузки я бы хотел бы получить что-то ближе к 100 КБ3.
Хотя этот студент очень аккуратно ведёт конспект, результат сканирования выглядит немного неряшливо (не по его вине). Заметно просвечивается обратная сторона листа, что и отвлекает читателя, и мешает эффективному сжатию JPG или PNG по сравнению с ровным фоном.
Вот что выдаёт программа
noteshrink.py:
Это крошечный файл PNG размером всего 121 КБ. Знаете, что мне нравится больше всего? Кроме уменьшения размера, конспект стал и разборчивее!
Основы цвета и процесса обработки
Вот шаги для создания компактного и чистого изображения:
- Определить цвет фона исходного отсканированного изображения.
- Изолировать передний план, установив порог по другим цветам.
- Преобразовать в индексированный PNG, выбрав небольшое количество «репрезентативных цветов» на переднем плане.
Прежде чем углубиться в тему, полезно вспомнить, как цветные изображения хранятся в цифровом виде. Поскольку в глазу человека три типа цветочувствительных клеток, мы можем восстановить любой цвет, изменяя интенсивность красного, зелёного и синего света4. В результате получается система, которая присваивает цветам точки в трёхмерном цветовом пространстве RGB5.

Хотя истинное векторное пространство допускает бесконечное число непрерывно изменяющихся значений интенсивности, для хранения в цифровом виде мы дискретизируем цвета, обычно выделяя по 8 бит каждому из каналов: красному, зелёному и синему. Однако если рассматривать цвета как точки в непрерывном трёхмерном пространстве, то становятся доступны мощные инструменты для анализа, как показано далее в описании процесса.
Определение цвета фона
Поскольку основная часть страницы — чистая, то можно ожидать, что цветом бумаги станет самый часто встречающийся цвет на отсканированном изображении. И если бы сканер всегда представлял каждую точку чистой бумаги как одинаковый триплет RGB, у нас не было бы проблем. К сожалению, это не так. Случайные изменения в цвете возникают из-за пыли и пятен на стекле, цветовых вариаций самой бумаги, шума на сенсоре и т.д. Таким образом, реальный «цвет страницы» может распределяться по тысячам различных значений RGB.
Исходное отсканированное изображение имеет размер 2081×2531, общая площадь 5 267 011 пикселей. Хотя можно рассмотреть все пиксели, но гораздо быстрее взять репрезентативную выборку исходного изображения. Программа
noteshrink.py по умолчанию берёт 5% исходного изображения (более чем достаточно для скана 300 DPI). Но давайте посмотрим на еще меньшее подмножество из 10 000 пикселей, выбранных случайным образом из исходного изображения:Оно мало похожа на реальный скан — здесь нет текста, но распределение цветов практически идентично. Оба изображения в основном серовато-белые, с горсткой красных, синих и тёмно-серых пикселей. Вот те же 10 000 пикселей, отсортированные по яркости (то есть по сумме интенсивности каналов R, G и B):
Если смотреть издалека, то нижние 80-90% изображения кажутся одним и тем же цветом, но при ближайшем рассмотрении заметно довольно много вариаций. На самом деле на изображении чаще всего встречается цвет со значением RGB (240, 240, 242), и он представлен всего на 226 из 10 000 пикселей — не более 3% от общего количества.
Поскольку мода представляет настолько малый процент выборки, то возникает вопрос, насколько точно она соответствует распределению цветов. Проще определить фоновый цвет страницы, если сначала уменьшить глубину цвета. Вот как выглядит выборка, если снизить глубину с 8 до 4 бит на канал, обнулив четыре наименее значимых бита:
Теперь чаще всего встречается значение RGB (224, 224, 224), которое составляет 3623 (36%) выбранных точек. По сути, уменьшив глубину цвета, мы сгруппировали похожие пиксели в «корзины» большего размера, что облегчило поиск явного пика6.
Здесь определённый компромисс между надёжностью и точностью: небольшие корзины обеспечивают лучшую точность цветов, но большие корзины гораздо более надёжны. В конце концов, для выбора цвета фона я остановился на 6 битах на канал, что показалось оптимальным вариантом между двумя крайностями.
Выделение переднего плана
После того, как мы определили цвет фона, нужно выбрать пороговое значение (threshold) для остальных пикселей по степени близости к фону. Естественный способ определить сходство двух цветов — вычислить евклидово расстояние между их координатами в пространстве RGB. Но этот простой метод неправильно сегментирует некоторые цвета:
Вот таблица с цветами и евклидовым расстоянием от фона:
| Цвет | Где найден | R | G | B | Расстояние от фона |
|---|---|---|---|---|---|
| белый | фон | 238 | 238 | 242 | — |
| серый | просвечивается с обратной страницы | 160 | 168 | 166 | 129,4 |
| чёрный | чернило на лицевой странице | 71 | 73 | 71 | 290,4 |
| красный | чернило на лицевой странице | 219 | 83 | 86 | 220,7 |
| розовый | вертикальная линия слева | 243 | 179 | 182 | 84,3 |
Как видите, тёмно-серый цвет от просвечивающихся чернил, которые нужно классифицировать как фон, на самом деле находится дальше от белого цвета страницы, чем розовый цвет линии, которую мы хотим классифицировать как передний план. Любой порог в евклидовом расстоянии, который сделает розовый цвет передним планом, обязательно включит в себя и просвечивающиеся чернила.
Можно обойти эту проблему, перейдя из пространства RGB в пространство Hue-Saturation-Value (HSV), которое преобразует куб RGB в цилиндр, показанный здесь в разрезе7.

В цилиндре HSV радуга цветов распределена по окружности внешнего верхнего края; значение hue (цветовой тон) соответствует углу на окружности. Центральная ось цилиндра переходит от чёрного внизу до белого вверху с серыми оттенками посредине — вся эта ось имеет нулевую насыщенность или интенсивность цвета, а у ярких оттенков на внешней окружности насыщенность 1,0. Наконец, значение цвета value характеризует общую яркость цвета, от чёрного внизу до ярких оттенков вверху.
Итак, теперь пересмотрим теперь на наши цвета в модели HSV:
| Цвет | Значение цвета | Насыщенность | Разница с фоном по значению | Разница с фоном по насыщенности |
|---|---|---|---|---|
| белый | 0,949 | 0,017 | — | — |
| серый | 0,659 | 0,048 | 0,290 | 0,031 |
| чёрный | 0,286 | 0,027 | 0,663 | 0,011 |
| красный | 0,859 | 0,621 | 0,090 | 0,604 |
| розоый | 0,953 | 0,263 | 0,004 | 0,247 |
Как и следовало ожидать, белый, чёрный и серый значительно различаются по значению цвета, но имеют аналогичные низкие уровни насыщенности — значительно меньше красного или розового. С помощью дополнительной информации в модели HSV можно успешно пометить пиксель как принадлежащий переднему плану, если он соответствует одному из критериев:
- значение цвета отличается более чем на 0,3 от фона или
- насыщенность отличается более чем на 0,2 от фона
Первый критерий забирает чёрные чернила от ручки, а второй — красные чернила и розовую линию. Оба критерия успешно убирают с переднего плана серые пиксели просвечивающихся чернил. Для разных изображений можно использовать разные пороги насыщенности/значения цвета; для дополнительной информации см. раздел с результатами.
Выбор набора репрезентативных цветов
Как только мы изолировали передний план, то получили новый набор цветов, соответствующих отметкам на странице. Давайте визуализируем его — но на этот раз будем рассматривать цвета не как набор пикселей, а как 3D-точки в цветовом пространстве RGB. Результирующая диаграмма выглядит слегка «скученной», с несколькими полосами связанных цветов.
Интерактивная диаграмма по ссылке
Теперь наша цель — преобразовать исходное 24-битное изображение в индексированный цвет, выбрав небольшое количество цветов (в данном случае восемь) для представления всего изображения. Во-первых, это уменьшает размер файла, потому что цвет теперь определяется всего тремя битами (так как 8=2³). Во-вторых, полученное изображение становится более визуально сплочённым, потому что похожим цветным чернильным точкам, вероятно, будет назначен одинаковый цвет в итоговом изображении.
Для этого используем метод на основе данных со «скученной» диаграммы, упомянутой выше. Если выбрать цвета, соответствующие центрам кластеров, то получим набор цветов, точно представляющих исходные данные. С технической точки зрения мы решаем проблему квантования цвета (которая сама по себе является частным случаем векторного квантования) с помощью кластерного анализа.
Для этой работы я выбрал конкретный методологический инструмент — метод k-средних. Его цель — найти набор средних значений или центров, которые минимизируют среднее расстояние от каждой точки до ближайшего центра. Вот что получится, если выбрать семь различных кластеров в нашем наборе данных8.
Здесь точки с чёрными контурами соответствуют цветам переднего плана, а цветные линии соединяют их с ближайшим центром в пространстве RGB. Когда изображение преобразуется в индексированный цвет, каждый цвет переднего плана заменяется цветом ближайшего центра. Наконец, большие окружности показывают расстояние от каждого центра до самого дальнего связанного цвета.
Прибамбасы и навороты
Кроме установки пороговых значений цвета и насыщенности, в программе
noteshrink.py есть несколько других примечательных особенностей. По умолчанию она увеличивает яркость и контрастность палитры, изменяя минимальные и максимальные значения интенсивности на 0 и 255, соответственно. Без этого восьмицветная палитра нашего отсканированного образца выглядела бы так:Отрегулированная палитра более яркая:
Есть опция для принудительной смены фона на белый после изоляции цветов переднего плана. Для дальнейшего уменьшения размеров файла
noteshrink.py может автоматически запускать инструменты оптимизации PNG, такие как optipng, pngcrush и pngquant.На выходе программа выдаёт такие PDF-файлы с несколькими изображениями, используя программу конвертации от ImageMagick. В качестве дополнительного бонуса
noteshrink.py автоматически сортирует имена файлов численно в порядке возрастания (а не в алфавитном порядке, как glob в консоли). Это полезно, когда ваша тупая программа сканирования9 выдаёт на выходе названия файлов вроде scan 9.png и scan 10.png, а вы хотите, чтобы страницы в PDF были по порядку.Результаты
Вот еще несколько примеров вывода программы. Первый (PDF) отлично смотрится с дефолтными пороговыми значениями:
Визуализация цветовых кластеров:
Для следующего (PDF) понадобилось снизить порог насыщенности до 0,045, потому что серо-голубые линии слишком тусклые:
Цветовые кластеры:
Наконец, пример сканирования миллиметровки (PDF). Для неё я установил пороговое значение 0,05, потому что контраст между фоном и линиями слишком мал:
Цветовые кластеры:
Все вместе четыре PDF-файла занимают около 788 КБ, в среднем около 130 КБ на каждую страницу.
Выводы и будущая работа
Я рад, что удалось создать полезный инструмент, который можно использовать в подготовке PDF-файлов с конспектами для моих курсов. Кроме того, мне действительно понравилось готовить эту статью, особенно потому что она побудила меня попытаться улучшить важные 2D-визуализации, которые демонстрируются в статье Википедии о квантования цвета, а также наконец-то изучить three.js (очень забавный инструмент, буду использовать его снова).
Если я когда-нибудь вернусь к этому проекту, то хотелось бы поиграть с альтернативными схемами квантования. На этой неделе мне пришла в голову идея использовать спектральную кластеризацию на графе ближайших соседей в наборе цветов — мне показалось, я придумал интересную новую идею, но потом нашёл статью 2012 года, где предлагается именно такой подход. Ну ладно.
Ещё можете попробовать EM-алгоритм для формирования гауссовой модели смеси, которая описывает распределение цветов. Не уверен, что это часто делали в прошлом. Другие интересные идеи: попытка кластеризации в «перцептивно однородном» цветовом пространстве вроде L*a*b*, а также попытка автоматически определять оптимальное количество кластеров для данного изображения.
С другой стороны, нужно разобраться с другими темами для блога, так что я пока оставлю этот проект и предлагаю вам посмотреть репозиторий
noteshrink.py на GitHub.Примечания
1. Образцы конспектов представлены с великодушного разрешения моих студентов Урсулы Монаган и Джона Ларкина. ↑
2. Показанное здесь изображение в реальности уменьшено до 150 DPI, чтобы страница загружалась быстрее. ↑
3. Единственное, что наш копир хорошо делает, так это уменьшает размеры PDF до 50-75 КБ на страницу для документов такого типа. ↑
4. Красный, зелёный, и голубой являются первичными цветами в аддитивной модели. Учитель рисования в начальной школе мог сказать вам, что основные цвета — красный, жёлтый и синий. Это ложь [метод упрощения сложных концепций в системе образования — примеч. пер.]. Однако есть три субтрактивных основных цвета: жёлтый, пурпурный и циан. Аддитивные основные цвета относятся к сочетаниям света (который излучают мониторы), тогда как субтрактивные цвета относятся к сочетаниям пигмента в чернилах и красках. ↑
5. Изображение пользователя Maklaan в Wikimedia Commons. Лицензия: CC BY-SA 3.0 ↑
6. Посмотрите в Википедии диаграмму с распределением чаевых как ещё один пример, почему полезно увеличение размера «корзины». ↑
7. Изображение пользователя SharkD в Wikimedia Commons. Лицензия: CC BY-SA 3.0 ↑
8. Почему k=7, а не 8? Потому что нам нужно восемь цветов в конечном изображении, а мы уже установили цвет фона… ↑
9. Да, я смотрю на тебя, Image Capture из Mac OS… ↑

