
Аннотация
Обработка данных в реальном времени ровно один раз (exactly-once) — задача крайне нетривиальная и требующая серьезного и вдумчивого подхода на всей цепочке вычислений. Некоторые даже считают, что такая задача невыполнима. В реальности хочется иметь подход, обеспечивающий отказоустойчивую обработку вообще без каких-либо задержек и использование различных хранилищ данных, что выдвигает новые еще более жесткие требования, предъявляемые к системе: concurrent exactly-once и гетерогенность персистентного слоя. На сегодняшний день такое требование не поддерживает ни одна из существующих систем.
Предложенный подход последовательно раскроет секретные ингредиенты и необходимые понятия, позволяющие относительно просто реализовать гетерогенную обработку concurrent exactly-once буквально из двух компонент.
Введение
Разработчик распределенных систем проходит несколько стадий:
Стадия 1: Алгоритмы. Здесь происходит изучение основных алгоритмов, структур данных, подходов к программированию типа ООП и т.д. Код исключительно однопоточный. Начальная фаза вхождения в профессию. Тем не менее, достаточно непростая и может длиться годами.
Стадия 2: Многопоточность. Далее возникают вопросы извлечения максимальной эффективности из железа, возникает многопоточность, асинхронность, гонки, дебагинг, strace, бессонные ночи… Многие застревают на этом этапе и даже начинают с какого-то момента ловить ничем не объяснимый кайф. Но лишь единицы доходят до понимания архитектуры виртуальной памяти и моделей памяти, lock-free/wait-free алгоритмах, различных асинхронных моделях. И почти никто и никогда — верификации многопоточного кода.
Стадия 3: Распределенность. Тут такой треш творится, что ни в сказке сказать, ни пером описать.
Казалось бы, чего сложного. Делаем трансформацию: много потоков -> много процессов -> много серверов. Но каждый шаг трансформации привносит качественные изменения, и все они ложатся на систему, раздавливая ее и превращая в прах.
И дело тут в изменении домена обработки ошибок и наличия разделяемой памяти. Если раньше всегда был кусочек памяти, который был доступен в каждом потоке, и при желании, в каждом процессе, то теперь такого кусочка нет и быть не может. Каждый сам за себя, независимый и гордый.
Если раньше сбой в потоке хоронил поток и процесс заодно, и это было хорошо, т.к. не приводило к частичным отказам, то теперь частичные отказы становятся нормой и каждый раз перед каждым действием ты думаешь: “а что, если?”. Это настолько напрягает и отвлекает от написания, собственно, самих действий, что код из-за этого растет не в разы, а на порядки. Все превращается в лапшу обработки ошибок, состояний, переключений и сохранения контекста, восстановления из-за сбоев одного компонента, другого компонента, недоступности части сервисов и т.п. и т.д. Накрутив на все это добро мониторинг можно великолепно проводить ночи напролет за любимым ноутбуком.
То ли дело в многопоточности: взял мьютекс и пошел кромсать общую память в удовольствие. Красота!
В результате мы имеем, что ключевые и проверенные в боях паттерны забрали, а новые, на замену им, отчего-то не завезли, и получилось как в анекдоте про то, как фея взмахнула палочкой, и у танка отвалилась башня.
Тем не менее, в распределенных системах есть набор проверенных практик и доказанные алгоритмы. Однако, каждый уважающий себя программист считает своим долгом отринуть известные достижения и навелосипедить свое, родное добро, невзирая на накопленный опыт, немалое количество научных статей и академических исследований. Ведь если ты можешь в алгоритмы и многопоточность, как можно попасть впросак с распределенностью? Двух мнений тут быть не может!
В результате системы глючат, данные расходятся и портятся, сервисы периодически становятся недоступны на запись, а то и вовсе недоступны, потому что внезапно нода упала, сеть заглючила, Java скушала много памяти и GC затупил, и много еще других причин, позволяющие оттягивать свой конец перед начальством.
Однако, даже с известными и проверенными подходами жизнь не становится проще, т.к. распределенные надежные примитивы являются тяжеловесными с серьезными требованиями, предъявляемые к логике исполняемого кода. Поэтому углы срезаются везде, где только можно. И, как это часто бывает, с отрезанными наспех углами появляется простота и относительная масштабируемость, но улетучивается надежность, доступность и консистентность распределенной системы.
В идеале хотелось бы вообще не думать о том, что система у нас распределенная и многопоточная, т.е. работать на 1-й стадии (алгоритмы), не задумываясь о 2-й (многопоточность+асинхронность) и 3-й (распределенность). Такой способ изоляции абстракций существенно повысил бы простоту, надежность и скорость написания кода. К сожалению, на текущий момент это возможно лишь в мечтах.
Тем не менее, отдельные абстракции позволяют добиться относительной изоляции. Один из характерных примеров — это использование сопрограмм, где вместо асинхронного кода мы получаем синхронный, т.е. переходим от 2-й стадии к 1-й, что и позволяет существенно упростить написание и сопровождение кода.
В статье последовательно раскрывается использование lock-free алгоритмов для построения надежной консистентной распределенной масштабируемой real-time системы, т.е. как lock-free достижения 2-й стадии помогают в реализации 3-й, сводя задачу к однопоточным алгоритмам 1-й стадии.
Постановка задачи
Данная задача лишь иллюстрирует некоторые важные подходы и представлена в качестве примера для введения в контекст проблематики. Ее легко обобщить на более сложные случаи, что и будет сделано в дальнейшем.
Задача: обработка потоковых данных в реальном времени.
Имеется два потока чисел. Обработчик читает данные этих входных потоков и отбирает последние числа за определенный промежуток. Эти числа усредняются в этом временном промежутке, т.е. в скользящем окне данных за некоторое заданное время. Полученное среднее значение необходимо записать в выходную очередь для последующей обработки. Помимо этого если количество чисел в окне превышает некоторое пороговое, то увеличить на единицу счетчик во внешней транзакционной базе данных.
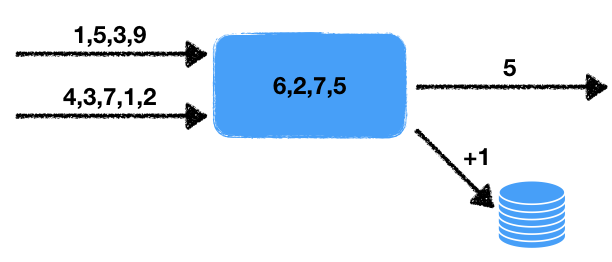
Отметим некоторые особенности данной задачи.
- Недетерминированность. Источников недетерминированного поведения два: это считывание из двух потоков, а также временное окно. Понятно, что считывание можно проводить разными способами, и от того, в какой последовательности будут извлекаться данные, и будет зависеть конечный результат. Временное окно также изменяет результат от запуска к запуску, т.к. от скорости работы будет зависеть количество данных в окне.
- Состояние обработчика. Присутствует состояние обработчика в виде набора чисел в окне, от которого зависит текущий и последующие результаты работы. Т.е. мы имеем stateful обработчик.
- Взаимодействие с внешним хранилищем. Необходимо обновлять значение счетчика во внешней базе данных. Принципиальный момент заключается в том, что тип внешнего хранилища отличается от хранилища состояния обработчика и потоков.
Все это, как будет показано ниже, серьезно влияет на используемые инструменты и на возможные способы реализации.
Осталось добавить к задаче маленький штришок, который сразу переводит задачу из области запредельной сложности в область невозможную: необходима гарантия concurrent exactly-once.
Exactly-Once
Exactly-once часто трактуется слишком широко, что выхолащивает сам термин, и он перестает отвечать изначальным требованиям задачи. Если мы говорим про систему, которая работает локально на одном компьютере — то тут все просто: бери больше, кидай дальше. Но в данном случае речь идет про распределенную систему, в которой:
- Число обработчиков может быть большим: каждый обработчик работает со своим куском данных. При этом результаты могут складываться в различные места, например, внешняя база данных, возможно даже пошардированная.
- Каждый обработчик может внезапно прекратить свою обработку. Отказоустойчивая система подразумевает продолжение работы даже в случае отказа отдельных частей системы.
Таким образом, надо быть готовым к тому, что обработчик может упасть, и другой обработчик должен подхватить уже проделанную работу и продолжить обработку.
Тут сразу возникает вопрос: а что будет означать exactly-once в случае работы недетерминированного обработчика? Ведь каждый раз при перезапуске мы будем получать, вообще говоря, разные результирующие состояния. Ответ тут простой: при exactly-once существует такое исполнение системы, при котором каждое входное значение обрабатывалось ровно один раз, давая соответствующий выходной результат. При этом это исполнение не обязательно должно быть физически на одной и той же ноде. Но результат должен быть таким, как если бы все обрабатывалось на некоторой одной логической ноде без падений.
Concurrent Exactly-Once
Для усугубления требований введем новое понятие: concurrent exactly-once. Принципиальное отличие от простого exactly-once состоит в отсутствие пауз при обработке, как если бы все обрабатывалось на одной ноде без падений и без пауз. В нашей задаче мы будем требовать именно concurrent exactly-once, для простоты изложения, чтобы не рассматривать сравнение с существующими системами, которых на сегодняшний день нет.
О последствиях наличия такого требования будет сказано ниже.
Транзакционность
Чтобы читатель еще глубже проникся возникшей сложностью, давайте рассмотрим различные нехорошие сценарии, которые необходимо учитывать при разработке подобной системы. Также попытаемся использовать общий подход, который позволит решить приведенную выше задачу с учетом наших требований.
Первое, что приходит на ум — это необходимость записывать состояние обработчика и входных и выходных потоков. Состояние выходных потоков описывается простой очередью чисел, а состояние входных потоков — позицией в них. По сути, поток представляет собой бесконечную очередь, и позиция в очереди однозначно задает местоположение.

Возникает следующая наивная реализация обработчика с использованием некоего хранилища данных. На данном этапе конкретные свойства хранилища нам не будут важны. Будем использовать язык Псеко для иллюстрации идеи (Псеко := псевдо код):
handle(input_queues, output_queues, state): # восстанавливаем позиции потоков input_indexes = storage.get_input_indexes() # в цикле обрабатываем входящие потоки while true: # загружаем данные из очередей начиная с предыдущей позиции items, new_input_indexes = input_queues.get_from(input_indexes) # добавляем в очередь state.queue.push(items) # и обновляем окно согласно duration state.queue.trim_time_window(duration) avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary # (A) добавляем среднее в выходную очередь output_queues[0].push(avg) if need_update_counter: # (B) увеличиваем счетчик во внешней базе db.increment_counter() # (C) сохраняем состояние в хранилище storage.save_state(state) # (D) сохраняем значения индексов storage.save_queue_indexes(new_input_indexes) # (E) обновляем текущие индексы input_indexes = new_input_indexes
Здесь приведен простой однопоточный алгоритм, который вычитывает из входных потоков данные и записывает нужные значения согласно описанной выше задаче.
Давайте посмотрим, что будет происходить в случае падения ноды в произвольные моменты времени, а также после возобновления работы. Понятно, что в случае падения в точках (A) и (E) все будет отлично: либо данные никуда еще не успели записаться и мы просто восстановим состояние и продолжим на другой ноде, либо все необходимые данные уже записались и просто продолжим выполнение следующего шага.
Однако в случае падения во всех других точках нас ждут неожиданные неприятности. Если произойдет падение в точке (B), то при повторном запуске обработчика мы восстановим состояния и запишем повторно среднее значение на примерно том же интервале чисел. В случае падения в точке (C) помимо дубликата среднего возникнет дубликат в инкременте значения. А в случае падения в (D) мы получим неконсистентное состояние обработчика: состояние соответствует новому моменту времени, а зачитывать значения из входных потоков мы будет старые.

При этом при перестановке операций записи принципиально ничего не поменяется: неконсистентность и дубликаты так и будут оставаться. Таким образом, мы приходим к выводу о том, что все действия по изменению состояния обработчика в хранилище, выходной очереди и базы данных должны выполняться транзакционно, т.е. все одновременно и атомарно.
Соответственно, необходимо разработать механизм, чтобы различные хранилища могли транзакционно изменять свое состояние, причем не внутри каждого независимо, а транзакционно между всеми хранилищами одновременно. Конечно, можно поместить наше хранилище внутрь внешней базы данных, однако в задаче предполагалось, что движок базы данных и движок фреймворка обработки потоковых данных разведены и работают независимо друг от друга. Здесь я хочу рассматривать наиболее тяжелый случай, т.к. простые случаи рассматривать неинтересно.
Конкурентная отзывчивость
Рассмотрим конкурентное выполнение ровно один раз более подробно. В случае отказоустойчивой системы мы требуем продолжение работы с некоторой точки. Понятно, что эта точка будет некоторым моментом в прошлом, т.к. для сохранения производительности невозможно сохранять в хранилище все моменты изменения состояния в настоящем и будущем: сохраняется либо последний результат операций, либо группа значений для увеличения пропускной способности. Такое поведение сразу приводит нас к тому, что после восстановления состояния обработчика будет происходить некоторая задержка результатов, она будет расти с увеличением размера группы значений и размера состояния.
Помимо этой задержки в системе присутствуют также задержки, связанные с загрузкой состояния на другую ноду. Дополнительно к этому, детектирование проблемной ноды также занимает какое-то время, причем зачастую немалое. Связано это, прежде всего, с тем, что если мы поставим малое время детектирования, то возможны частые ложные срабатывания, что будет приводить к разного рода неприятным спецэффектам.
Кроме того, с ростом количества параллельных обработчиков внезапно оказывается, что не все они одинаково хорошо работают даже в условиях отсутствия отказов. Иногда случаются затупы, которые также приводят к задержкам в обработке. Причина таких затупов может быть разнообразная:
- Программная: паузы GC, фрагментация памяти, паузы в аллокаторе, прерывание ядра и планирование задач, проблемы с драйверами устройств, вызывающие замедление работы.
- Аппаратная: высокая загруженность диска или сети, CPU throttling из-за проблем охлаждения, перегрузки и т.д., замедление работы диска из-за технических проблем.
И это далеко не исчерпывающий список проблем, которые могут приводить к замедлению обработчиков.
Соответственно, замедление работы — это данность, с которой приходится жить. Иногда это не является серьезной проблемой, а иногда крайне важно сохранять высокую скорость обработки несмотря на сбои или замедления.
Сразу возникает идея дублирования систем: запустим для одного и того же потока данных не один, а сразу два обработчика, или даже три. Проблема тут в том, что в этом случае легко могут возникать дубликаты и неконсистентное поведение системы. Обычно фреймворки не рассчитаны на такое поведение и предполагают, что количество обработчиков в каждый момент времени не превышает одного. Системы, допускающие описанное дублирование исполнения, называются concurrent exactly-once.
Такая архитектура позволяет решать сразу несколько проблем:
- Отказоустойчивое поведение: если одна из нод падает, то другая просто продолжает работу как будто ничего не произошло. Здесь нет необходимости в дополнительной координации действий, т.к. второй обработчик выполняется безотносительно состояния первого.
- Удаление затупов: кто первый предоставил результат, тот и молодец. Другому лишь останется подцепить новое состояние и продолжить с этого момента.
Такой подход, в частности, позволяет завершить сложный тяжелый долгий расчет за более предсказуемое время, т.к. вероятность того, что оба будут тупить и падать существенно меньше.
Вероятностная оценка
Попытаемся оценить преимущества дублирования исполнения. Предположим, что с обработчиком в среднем каждый день что-то происходит: либо затупил GC, либо нода лежит, либо контейнеры встали раком. Предположим также, что мы подготавливаем пачки данных за 10 секунд.
Тогда вероятность того, что что-то произойдет за время создания пачки равна 10 / (24 · 3600) ≃ 1e-4.
Если запустить параллельно два обработчика, то вероятность того, что обоим поплохеет ≃ 1e-8. А значит это событие наступит через 23 года! Да системы столько не живут, а значит этого не произойдет никогда!
При этом если время подготовки пачки будет еще меньше и/или затупы будут происходить еще реже, то эта цифра будет лишь увеличиваться.
Таким образом приходим к выводу, что рассматриваемый подход существенно повышает надежность всей нашей системы. Осталось лишь решить маленький такой вопросик: а где прочитать про то, как сделать concurrent exactly-once систему. А ответ простой: здесь и надо читать.
Полутранзакции
Для дальнейшего изложения нам понадобится понятие полутранзакция. Проще всего его объяснить на примере.
Рассмотрим перевод средств с одного банковского счета на другой. Традиционный подход с использованием транзакций на языке Псеко можно описать следующим образом:
transfer(from, to, amount): tx = db.begin_transaction() amount_from = tx.get(from) if amount_from < amount: return error.insufficient_funds tx.set(from, amount_from - amount) tx.set(to, tx.get(to) + amount) tx.commit() return ok
Однако что делать, если такие транзакции нам недоступны? Применяя блокировки, это можно сделать следующим образом:
transfer(from, to, amount): # автоматически отпускает блокировку при выходе из области видимости lock_from = db.lock(from) lock_to = db.lock(to) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) db.set(to, db.get(to) + amount) return ok
Такой подход может приводить к дедлокам, т.к. блокировки могут браться в разной последовательности параллельно. Чтобы исправить такое поведение, достаточно ввести функцию, которая одновременно берет несколько блокировок в детерминированной последовательности (например, сортирует по ключам), что полностью избавляет от возможных дедлоков.
Тем не менее, реализацию можно несколько упростить:
transfer(from, to, amount): lock_from = db.lock(from) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) lock_from.release() # такая блокировка необходима, # т.к. db.set(db.get...) паттерн не является атомарным lock_to = db.lock(to) db.set(to, db.get(to) + amount) return ok
Такой подход также делает конечное состояние консистентным, сохраняя инварианты по типу предотвращения излишнего расхода средств. Главное отличие от предыдущего подхода в том, что в такой реализации у нас есть некоторый промежуток времени, в котором счета находятся в неконсистентном состоянии. А именно, такая операция подразумевает, что суммарное состояние средств на счетах не изменяется. В данном случае между lock_from.release() и db.lock(to) существует временной зазор, в течении которого база данных может выдавать неконсистентное значение: итоговая сумма может отличаться от корректной в меньшую сторону.
По сути, мы разбили одну транзакцию по переводу денег на две полутранзакции:
- Первая полутранзакция делает проверку и снимает со счета необходимую сумму.
- Вторая полутранзакция записывает снятую сумму на другой счет.
Понятно, что раздробление транзакции на более мелкие, вообще говоря, нарушает транзакционное поведение. И приведенный выше пример — не исключение. Однако, если все полутранзакции в цепочки полностью исполнились, то результат будет консистентным с сохранением всех инвариантов. Именно это и является важным свойством цепочки полутранзакций.
Временно теряя некоторую консистентность, мы, тем не менее, приобретаем другое полезное свойство: независимость операций, и, как следствие, лучшую масштабируемость. Независимость проявляется в том, что полутранзакция каждый раз работает лишь с одной строкой, читая, проверяя и изменяя ее данные, не общаясь при этом к другим данным. Таким образом можно пошардировать базу данных, транзакции которой работают лишь с одним шардом. Более того, такой подход можно использовать в случае наличия гетерогенных хранилищ, т.е. полутранзакции могут начинаться на одном типе хранилища, а заканчиваться на другом. Именно такие полезные свойства и будут использованы в дальнейшем.
Возникает закономерный вопрос: а как реализовать полутранзации в распределенных системах и не огрести? Для решения этого вопроса необходимо рассмотреть lock-free подход.
Lock-free
Как известно, lock-free подходы порой улучшают производительность многопоточных систем, особенно в случае конкурентного доступа к ресурсу. Тем не менее, совершенно неочевидно, что такой подход можно использовать в распределенных системах. Давайте копнем вглубь и рассмотрим, что же такое lock-free и почему это свойство будет полезно при решении нашей задачи.
Некоторые разработчики иногда не совсем четко представляют себе, что же такое lock-free. Обывательский взгляд подсказывает, что это что-то, связанное с атомарными процессорными инструкциями. Тут важно понимать при этом, что lock-free означает использование “атомиков”, обратное же неверно, т.е. не всякие “атомики” дают lock-free поведение.
Важное свойство lock-free алгоритма заключается в том, что хотя бы один поток делает прогресс в системе. Но почему-то многие это свойство выдают за определение (именно такое тупорылое определение и можно найти, например, в википедии). Тут необходимо добавить один важный нюанс: прогресс совершается даже в случае затупов одного или нескольких потоков. Это очень критический момент, который часто упускается из виду, имеющий серьезные последствия для распределенной системы.
Почему отсутствие условия прогресса хотя бы одного потока сводит на нет понятие lock-free алгоритма? Дело в том, что в этом случае обычный spinlock также будет являться lock-free. Действительно, тот, кто взял блокировку, тот и будет совершать прогресс. Есть поток с прогрессом => lock-free?
Очевидно, что lock-free обозначает без блокировок, в то время как spinlock своим названием говорит о том, что это есть самая настоящая блокировка. Именно поэтому важно добавить условие о прогрессе даже в случае затупов. Ведь эти задержки могут длиться неограниченно долгое время, т.к. определение ничего не говорит о верхней временной границе. А раз так, то такие задержки будут эквивалентны в каком-то смысле выключениям потоков. При этом lock-free алгоритмы будут производить прогресс и в этом случае.
Но кто сказал, что lock-free подходы применимы исключительно для многопоточных систем? Заменив потоки в одном процессе на одной ноде на процессы на разных нодах, а общую память потоков на общее распределенное хранилище, мы получим lock-free распределенный алгоритм.
Падение ноды в такой системе эквивалентно задержке выполнения потока на какое-то время, т.к. для восстановление работы необходимо это самое время. При этом lock-free подход позволяет продолжать работу другим участникам распределенной системы. Более того, специальные lock-free алгоритмы можно запускать параллельно друг с другом, детектируя конкурентное изменение и вырезая дубликаты.
Exactly-once подход подразумевает наличие консистентного распределенного хранилища. Такие хранилища как правило представляют собой огромную персистентную key-value таблицу. Возможные операции: set, get, del. Однако, для lock-free подхода необходима более сложная операция: CAS или compare-and-swap. Рассмотрим более детально эту операцию, возможности ее использования, а также то, какие результаты это дает.
CAS
CAS или compare-and-swap — основной и важный примитив синхронизации для lock-free и wait-free алгоритмов. Суть его можно проиллюстрировать следующим Псеко:
CAS(var, expected, new): # все, что внутри atomic, выполняется атомарно atomic: if var.get() != expected: return false var.set(new) return true
Иногда для оптимизации возвращают не true или false, а предыдущее значение, т.к. очень часто такие операции производят в цикле, а чтобы получить expected значение, необходимо его для начала прочитать:
CAS_optimized(var, expected, new): # все, что внутри atomic, выполняется атомарно atomic: current = var.get() if current == expected: var.set(new) return current # тогда CAS выражается через CAS_optimized CAS(var, expected, new): return var.CAS_optimized(expected, new) == expected
Такой подход может сэкономить одно чтение. В рамках нашего рассмотрения мы будем использовать простую форму CAS, т.к. при желании такую оптимизацию можно проделать самостоятельно.
В случае распределенных систем каждое изменение версионируется. Т.е. сначала мы читаем значение из хранилища, получая текущую версию данных. А затем пытаемся записать, ожидая, что версия данных не изменилась. При этом версия инкрементируется каждый раз при обновлении данных:
CAS_versioned(var, expected_version, new): atomic: if var.get_version() != expected_version: return false var.set(new, expected_version + 1) return true
Такой подход позволяет более точно контролировать обновление значений, избегая проблемы ABA. В частности, версионирование поддерживают Etcd и Zookeeper.
Отметим важное свойство, которое дает использование CAS_versioned операций. Дело в том, что такую операцию можно повторять без ущерба вышестоящей логики. В многопоточном программировании данное свойство не имеет особой ценности, т.к. там если операция завершилась неудачно, то мы точно знаем, что она не применилась. В случае же распределенных систем данный инвариант нарушается, т.к. запрос может дойти до получателя, а успешный ответ уже нет. Поэтому важно иметь возможность перепосылать запросы без боязни нарушения инвариантов высокоуровневой логики.
Именно такое свойство и предоставляет операция CAS_versioned. По факту, можно бесконечно повторять эту операцию до тех пор, пока не вернется реальный ответ от получателя. Что, в свою очередь, выкидывает целый класс ошибок, связанный с сетевым взаимодействием.
Пример
Давайте рассмотрим, как на основе CAS_versioned и полутранзакций выполнить перевод с одного аккаунта на другой, которые принадлежат, например, разным экземплярам Etcd. Здесь я предполагаю, что функция CAS_versioned уже реализована соответствующим образом на основе предоставляемого API.
withdraw(from, amount): # CAS-цикл while true: # получение версии и данных version_from, amount_from = from.get_versioned() if amount_from < amount: return error.insufficient_funds if from.CAS_versioned(version_from, amount_from - amount): break return ok deposit(to, amount): # CAS-цикл while true: version_to, amount_to = to.get_versioned() if to.CAS_versioned(version_to, amount_to + amount): break return ok transfer(from, to, amount): # первая полутранзакция if withdraw(from, amount) is ok: # если первая полутранзакция произошла успешно, # то выполняем последующую deposit(to, amount)
Здесь мы разбили нашу операцию на полутранзакции, и каждую полутранзакцию выполняем через операцию CAS_versioned. Такой подход позволяет независимо работать с каждым аккаунтом, допуская использовать разнородные хранилища, никак не связанные друг с другом. Единственная проблема, которая нас тут поджидает — это потеря денег в случае падения текущего процесса в промежутке между полутранзакциями.
Очередь
Для того, чтобы идти дальше, необходимо реализовать очередь событий. Идея в том, что для общения обработчиков друг с другом необходимо иметь упорядоченную очередь сообщений, в которой данные не теряются и не дублируются. Соответственно, все взаимодействие в цепочке обработчиков будет построено на этом примитиве. Также это полезный инструмент для анализа и аудита входящих и исходящих потоков данных. Помимо этого мутации состояний обработчиков также можно производить через очередь.
Очередь будет состоять из пары операций:
- Добавление сообщения в конец очереди.
- Получение сообщения из очереди по заданному индексу.
В данном контексте я не рассматриваю удаление сообщений из очереди по нескольким причинам:
- Из одной и той же очереди могут читать несколько обработчиков. Синхронизация удаления будет представлять из себя нетривиальную задачу, хотя не невозможную.
- Полезно сохранять очередь на относительно длительный интервал (день или неделю) для возможности дебагинга и аудита. Полезность такого свойства сложно переоценить.
- Удалять старые элементы можно либо по расписанию, либо выставив TTL на элементы очереди. Важно при этом следить, чтобы обработчики успевали обработать данные до того, как придет метла и все подчистит. Если время обработки порядка секунд, а TTL порядка дней, то ничего такого не должно произойти.
Для хранения элементов и эффективной реализации добавления нам понадобятся:
- Значение с текущим индексом. Этот индекс указывает на конец очереди для добавления элементов.
- Элементы очереди, начиная с нулевого индекса.
Как бы lock-free очередь
Для вставки элемента в очередь нам необходимо обновить два ключа: текущий индекс и вставляемый элемент по текущему индексу. Сразу возникает идея сделать это в следующей последовательности:
- Сначала атомарно через CAS увеличиваем текущий индекс на единицу.
- Затем по возвращаемому значению записываем вставляемый элемент.
Однако у этого подхода, как это ни странно, есть целых два фатальных недостатка.
- Такая реализация не является lock-free. Казалось бы, если мы параллельно вставляем несколько элементов, то хотя бы одна вставка в таком случае завершается успешно. Lock-free? Нет! Дело в том, что у нас 2 операции: вставка и чтение. И хотя вставка сама по себе и является lock-free, однако вставка и чтение — нет! В этом легко убедиться, если предположить, что сразу после атомарного обновления индекса возникла пауза, размером с вечность. Тогда мы никогда не сможем зачитать этот и последующий элементы и будем заблокированы навсегда. Это будет представлять серьезную проблему для доступности нашей очереди, т.к. в случае отказа обработчика в этом месте мы получаем залипание других обработчиков, зачитывающих значение с этой позиции.
- Проблемы при взаимодействии нескольких очередей. При падении обработчика после обновления индекса мы не знаем, по какому индексу нам необходимо будет записать значение в случае продолжения работы после восстановления состояния. Этот индекс потеряется навсегда.
Таким образом, крайне важно сохранять lock-free относительно всех операций для сохранения высокой доступности работы обработчиков.
Lock-free реализация добавления
Соответственно, рассуждая логично, остается только другой вариант реализации: в обратном порядке, т.е. сначала добавляем элемент в конец очереди, а потом обновляем индекс:
push(queue, value): # получение текущего индекса из очереди index = queue.get_current_index() while true: # получение переменной, указывающей на ячейку # для добавления элемента var = queue.at(index) # версия = 0 соответствует новому значению, т.е. такая проверка # означает, что ячейка должна быть пустой в момент записи if var.CAS_versioned(0, value): # запись произведена успешно, теперь обновляем индекс queue.update_index(index + 1) break # здесь хитрый момент, см. описание ниже index = max(queue.get_current_index(), index + 1) update_index(queue, index): while true: # получение текущего версионированного значения cur_index, version = queue.get_current_index_versioned() # текущий индекс может внезапно оказаться больше, # чем записываемый, см. описание ниже if cur_index >= index: # кто-то проактивно обновил на более свежий, # а значит работа сделана и можно отдыхать break if queue.current_index_var().CAS_versioned(version, index): # удалось обновить индекс на более свежий, работа закончена break # кто-то обновил значение. # возможно, что индекс все еще недостаточно свежий, попробуем еще
Стоит подробнее остановиться на хитром моменте. Дело в том, что после успешного выполнения первой полутранзакции обработчик может упасть или затупить (падение или отказ в работе — это, вообще говоря, частный случай затупа на вечность). При этом мы хотим сохранить свойство lock-free для нашей системы. Что при этом произойдет?
А произойдет то, что следующий push будет крутиться в цикле бесконечно, ведь текущий индекс теперь некому обновить! Следовательно, это теперь наша задача по обновлению индекса и мы должны проактивно это сделать, самостоятельно подсматривая за следующим элементом очереди.
После записи значения теперь необходимо обновить текущий индекс. Однако тут тоже поджидает нас подводная грабелька: мы не можем просто так взять и перезаписать значение. Дело в том, что если мы затупили по какой-то причине между полутранзакциями, то кто-то другой за это время мог успеть добавить элемент в очередь и обновить текущее значение индекса. А значит, простое обновление индекса не будет работать, т.к. мы просто перетрем более новое значение. Помимо этого нам необходимо обновить именно на самое свежее значение. Какое самое свежее значение будет в этом случае? Оно будет соответствовать самому большому значению индекса, т.к. индекс соответствует позиции в очереди, и чем выше позиция, тем более свежие данные мы записали в очередь.
Стоит отметить, что мы записывали индекс только ради того, чтобы иметь возможность быстро найти конец очереди для дальнейшего добавления. Т.е. этого всего лишь оптимизация. Без индекса эта очередь также будет прекрасно работать, просто гораздо более медленнее, замедляясь линейно с ростом очереди. Поэтому отставание значения индекса не теряет консистентной записи в нее, а лишь улучшает временные характеристики добавления записи.
Более того, некоторые хранилища предоставляют способ итерироваться по записям. Организовав определенным образом набор ключей для доступа к элементам очереди можно обнаруживать последний элемент сразу, не перебирая предыдущие. Это требует расширения требований, предъявляемых к хранилищу, а потому не будет рассмотрено. Здесь мы лишь ограничимся наиболее общим подходом, который будет работать везде.
Взаимодействие очередей
Для того, чтобы двигаться, рассмотрим модельную задачу, элементы которой нам пригодятся в дальнейшем.
Задача. Перекинуть значения из одной очереди в другую.
Это самая простая задача, которая может возникнуть при обработке данных:
- Отсутствует состояние, т.е. обработчик stateless.
- Нет трансформаций, прочитанное значение и записываемое — одинаковое.
Думаю, что не стоит объяснять, что мы хотим отказоустойчивое решение с гарантией concurrent exactly-once.
Без этого требования обработка выглядела бы следующим образом:
handle(input, output): index = 0 while true: value = input.get(index) output.push(value) index += 1
Добавим немного отказоустойчивости. Для этого необходимо загружать и сохранять состояние обработчика:
handle(input, output, state): # получение состояния index = state.get() while true: value = input.get(index) output.push(value) index += 1 # сохранение индекса state.set(index)
Такая реализация не является exactly-once. Причина в том, что если падает обработчик сразу после добавления элемента в выходную очередь, но перед сохранением позиции, то мы получаем дубликат.
Чтобы добиться гарантии exactly-once, необходимо транзакционно и сохранять позицию, и записывать в очередь. Т.к., вообще говоря, очереди и состояния могут принадлежать разным хранилищам, между которыми могут не быть распределенных транзакций, то единственный вариант, который можно использовать — это разбить такую транзакцию на полутранзакции:
# возвращает наименьший индекс для вставки значения get_next_index(queue): index = queue.get_index() # пытаемся найти пустую ячейку while queue.has(index): # обновляем индекс аналогично queue.push index = max(index + 1, queue.get_index()) return index # пытается записать значение по заданному индексу. # возвращает true в случае успеха push_at(queue, value, index): var = queue.at(index) if var.CAS_versioned(0, value): # обновляем индекс queue.update_index(index + 1) return true return false handle(input, output, state): # получение состояния # в самом начале {PREPARING, 0} fsm_state = state.get() while true: switch fsm_state: case {PREPARING, input_index}: # подготовка к записи: сначала сохраняем индекс, # по которому в дальнейшем будем производить запись output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) if output.push_at(value, output_index): # удалось записать, переходим к следующему элементу input_index += 1 # если ячейка была занята, то push_at вернет false, # и нужно заново повторить для текущего индекса fsm_state = {PREPARING, input_index} state.set(fsm_state)
Почему может быть занята ячейка при вызове push_at? Ведь мы на предыдущем шаге проверяли, что ячейка свободна. Дело в том, что в выходную очередь, вообще говоря, могут писать разные обработчики. А раз так, то к моменту перехода нашего автомата на состояние записи эта ячейка уже может быть занята. В этом случае мы просто заново повторяем процесс с тем же самым индексом. Такой конфликт может возникнуть только в случае успешной работы какого-либо другого обработчика, а значит мы получаем lock-free обработчик.
По сути, мы разбили запись на две полутранзакции:
- Подготовка к записи: запоминаем будущий индекс для избежания появления дубликатов.
- Собственно, сама запись: по сохраненному индексу записываем нужное значение.
Осталось самое малое: добавить свойство concurrent к exactly-once.
В чем проблема с кодом выше? Их тут две:
- В момент записи в очередь может оказаться, что другой обработчик уже записал ровно такое же число, а потому
push_atвернет в этом случае false. И мы вернемся на предыдущий шаг для повторной записи этого же значения. - Состояние может обновляться из двух разных обработчиков, они будут перезатирать данные друг друга. Это, в свою очередь, может приводить к весьма разнообразным состояниям гонки.
Почему важно поддерживать именно concurrent exactly-once в этом случае? Дело в том, что распределенной системе невозможно гарантировать, что в каждый момент времени количество эквивалентных обработчиков будет не более одного. Связано это с тем, что невозможно гарантированно задетектировать остановку обработчика в случае нарушения сетевой связности. Поэтому при любом разбиении транзакции на составные части необходимо предполагать конкурентную обработку.
Следующий код демонстрирует финальное решение задачи с учетом вышеизложенных проблем:
# либо записывает в пустую ячейку, либо проверяет, что значение уже записано # т.е. если в первый раз функция вернула true, # то последующие вызовы также вернут true. # это же свойство справедливо и для false push_at_idempotent(queue, value, index): return queue.push_at(value, index) or queue.get(index) == value handle(input, output, state): version, fsm_state = state.get_versioned() while true: switch fsm_state: case {PREPARING, input_index}: # подготовка к записи, сначала сохраняем индекс, # по которому в дальнейшем будем производить запись output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) # используем идемпотентную функцию, # таким образом весь шаг становится идемпотентным if output.push_at_idempotent(value, output_index): input_index += 1 fsm_state = {PREPARING, input_index} # пытаемся атомарно изменить состояние if state.CAS_versioned(version, fsm_state): version += 1 else: # было конкурентное обновление, необходимо восстановить состояние version, fsm_state = state.get_versioned()
Диаграмма переходов:
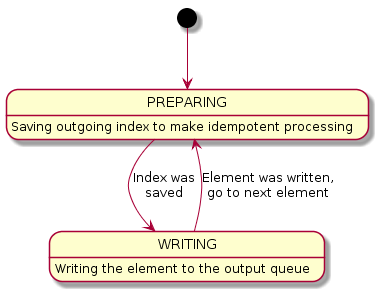
Основная идея заключается в том, чтобы сделать каждое действие идемпотентным. Это необходимо как для конкурентности, так и для правильного продолжения исполнения после падения и восстановления состояния.
При этом такому алгоритму не страшны никакие внешние и внутренние факторы типа kernel panic, внезапное падение приложения, таймауты сети и т.д. Всегда можно перезапустить с самого начала и продолжить как ни в чем не бывало. Грубое прекращение работы не потеряет данные и не приведет к дубликатам и нарушению работы. Можно также делать обновления приложения без остановки: запускаем новую версию совместно со старой, а затем тушим старую. Конечно же, при этом версии должны быть совместимы между собой.
Таким образом, такой обработчик дает абсолютную устойчивость по отношению к сбоям, замедлениям и конкурентному выполнению.
Решение начальной задачи
Теперь можно приступить к решению нашей первоначальной задачи: реализации обработчика с состоянием.
Для этого решим немного более общую задачу: есть обработчик, который из набора выходных значений, полученных из входных очередей, выдает измененное состояние с выходными значениями, которые будут положены в выходные очереди:
# входные параметры: # - input_queues - входные очереди # - output_queues - выходные очереди # - state - текущее состояние обработчика # - handler - наш обработчик с сигнатурой: state, inputs -> state, outputs handle(input_queues, output_queues, state, handler): # получаем текущее состояние автомата и его версию version, fsm_state = state.get_versioned() while true: switch fsm_state: # input_indexes содержат список текущих индексов входных очередей case {HANDLING, user_state, input_indexes}: # зачитываем значения из каждой входной очереди inputs = [queue.get(index) for queue, index in zip(input_queues, input_indexes)] # вычисляем следующие индексы, увеличивая текущие значения next_indexes = next(inputs, input_indexes) # вызываем пользовательский обработчик # для получения выходных значений user_state, outputs = handler(user_state, inputs) # переходим к подготовке к записи результатов, # начиная с нулевой позиции fsm_state = {PREPARING, user_state, next_indexes, outputs, 0} case {PREPARING, user_state, input_indexes, outputs, output_pos}: # получаем индекс, по которому хотим записать значения # на следующем шаге output_index = output_queues[output_pos].get_next_index() # и переходим к записи fsm_state = { WRITING, user_state, input_indexes, outputs, output_pos, output_index } case { WRITING, user_state, input_indexes, outputs, output_pos, output_index }: value = outputs[output_pos] # пытаемся записать значение в выходную очередь if output_queues[output_pos].push_at_idempotent( value, output_index ): # если получилось, то переходим к следующему значению output_pos += 1 # а если не получилось, то просто переходим к шагу PREPARING. # в случае увеличения позиции # необходимо проверить окончание значений fsm_state = if output_pos == len(outputs): # все значения записаны, # переходим снова к обработке входных потоков {HANDLING, user_state, input_indexes} else: # переходим сюда в случае необходимости записи # следующего выходного значения, # либо в случае повторения подготовки для текущей позиции {PREPARING, user_state, input_indexes, outputs, output_pos} if state.CAS_versioned(version, fsm_state): version += 1 else: # было конкурентное обновление, необходимо восстановить состояние version, fsm_state = state.get_versioned()
Диаграмма переходов состояний выглядит так:
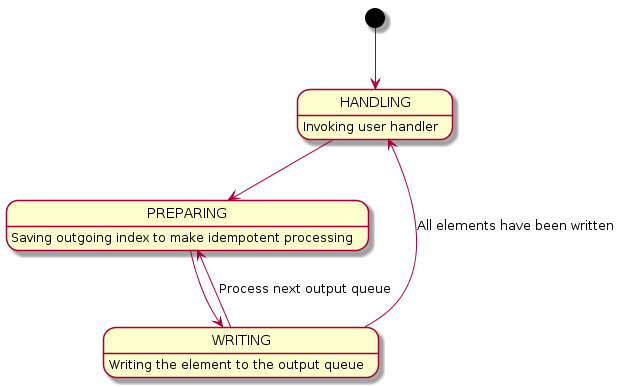
Здесь у нас появляется новое состояние: HANDLING. Это состояние необходимо для фиксации выполнения нашего обработчика, т.к., вообще говоря, он может содержать недетерминированные действия. Тем более, что это как раз наш случай. Помимо этого можно видеть, что фазы PREPARING и WRITING повторяются несколько раз, пока все значения не будут записаны в выходные очереди. Как только все значения записаны, то сразу переходим к фазе HANDLING.
Стоит отметить, что здесь я не обрабатывал ситуации, связанные с отсутствием значений во входных очередях, а также при возврате обработчиком пустых значений для выходных очередей. Это сделано намеренно, чтобы не загромождать код такими проверками для большей наглядности результирующего кода. Я думаю, что читатель сможет справиться самостоятельно с такими ситуациями и обработать их корректно.
Также стоит отметить еще один нюанс. Запись в базу данных будет происходить через выходную очередь. Это позволяет написать обобщенный код и разделить непосредственно обработку и запись во внешнюю базу данных.
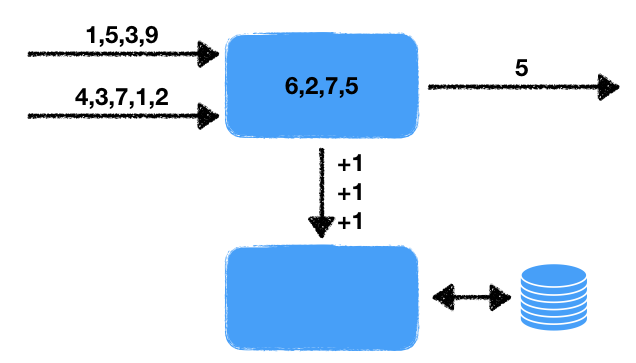
Теперь напишем обработчик:
my_handler(state, inputs): # добавляем значения из входных потоков state.queue.push(inputs) # обновляем окно согласно duration state.queue.trim_time_window(duration) # вычисляем среднее avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary return state, [ avg, if need_update_counter: true else: # none означает отсутствие необходимости добавления элемента none ]
Как видим, сам обработчик просто делает свою работу, при этом вся сложность по манипуляции с очередями и реализации concurrent exactly-once гарантии инкапсулирована внутри функции handle.
Теперь осталось лишь добавить взаимодействие с базой данных:
handle_db(input_queue, db): while true: # в самом начале создаем транзакцию tx = db.begin_transaction() # внутри транзакции считываем текущий индекс. # текущий индекс находится внутри базы данных, # что позволяет транзакционно обновлять состояние index = tx.get_current_index() # записываем увеличенный индекс tx.write_current_index(index + 1) # получаем значение из входной очереди value = intput_queue.get(index) if value: # и увеличиваем счетчик tx.increment_counter() tx.commit() # либо транзакция успешна, и счетчик обновлен совместно с индексом, # либо транзакция неуспешна и мы просто повторим заново это действие
Здесь никаких сюрпризов нет. Т.к. все состояние обновляется внутри одной неразрывной транзакции, то этот обработчик можно запускать параллельно с самим собой, а, значит, он предоставляет гарантию concurrent exactly-once. Такая реализация сразу намекает о полезности транзакций.
За бортом
Приведенный алгоритм — это лишь первый шажок на пути к эффективной и транзакционной обработке данных. Ниже я приведу список возможных оптимизаций и улучшений, которые полезно принять в некоторых случаях, с минимальными комментариями и соображениями.
Оптимизации для конкретного хранилища
Консистентные хранилища обычно поддерживают больше функций, типа транзакционного поведения на наборе ключей, группировка атомарных действий и сканирование по диапазону. Я рассмотрел лишь самый общий случай хранилища с самым простым примитивом, и показал, что даже в этом случае можно построить транзакционную масштабируемую систему.
Асинхронная публикация
После обработки входных потоков следует стадия публикации результатов в выходные очереди. Такая публикация выполняется последовательно, каждая последующая запись ожидает предыдущую. Т.к. сами данные уже записаны и готовы для записи, то возникает идея распараллелить их публикацию. На этом пути можно с невообразимой легкостью отстрелить себе обе ноги и обе руки. Поэтому я оставляю это в качестве домашнего задания.
Группировка значений
Очевидная оптимизация для увеличения пропускной способности очередей — это группировка сообщений. Действительно, в очереди можно запихивать не сами значения, а ссылки на группы значений. Сами значения подготавливать постепенно, с возможностью записи их где-то в сторонке, на отдельных шардах, хранилищах или даже файликах. При этом указатель на элемент очереди станет композитным, т.к. он, помимо индекса в очереди, будет также содержать и позицию в группе значений.
Двойное шардирование
Для параллелизации обработки часто применяют шардирование очередей. Тем не менее, если присутствует большое количество обработчиков, то все они начинают писать в одни и те же очереди. Для избежания холостого хода при публикации значений можно еще раз пошардировать очередь, но уже для записи, а не для чтения.
Фундаментальность подхода
Обсудим основание применение такого подхода. Понятно, что нельзя всякую транзакцию разбить на совокупность атомарных операций. Причина тривиальна: если бы это можно было бы сделать для любой ситуации, то так всегда бы и поступали. Поэтому важно очертить класс задач, который возможно решить с помощью данного подхода.
Если внимательно присмотреться к тем действиям, которые мы совершаем, то можно увидеть ряд характерных черт:
- Транзакции разбиваются на полутранзакции, которые выполняются последовательно. Суммарный эффект всех полутранзакций в точности равен эффекту всей транзакции.
- Изоляция не является важным требованием. Клиент может наблюдать промежуточные действия транзакции, как если бы действия транзакции были видны всем.
- Первая и только первая полутранзакция может проверить валидность последующих действий. Если валидация не прошла, то мы просто не начинаем последующие действия. Однако если мы начали выполнение транзакции, применив первую полутранзакцию, то дальше мы не имеем права обрывать исполнение. Т.е. последующие действия лишь закрепляют действие и могут продвигать исполнение вперед. Связано это с простым фактом: любая мутация видна клиенту.
Последнее свойство можно немного ослабить, однако, во-первых, такое далеко не всегда возможно, а во-вторых, это может сильно усложнить код.
Давайте посмотрим на наших примерах, почему разделение на полутранзакции возможно. Еще раз взглянем на Псеко:
transfer(from, to, amount): # первая полутранзакция if withdraw(from, amount) is ok: # если первая полутранзакция произошла успешно, # то выполняем последующую deposit(to, amount)
Здесь withdraw может не пройти наши проверки, в то время, как deposit никогда этого не сделает: кто же откажется от лишних денег? Однако если функция deposit по какой-то причине может вернуть неуспех (например, аккаунт оказался заблокирован, либо стоит лимит сверху на количество средств), то тогда возникают проблемы. Казалось бы, их можно решить тем, что перекинуть средства обратно, но кто сказал, что в этот момент исходный аккаунт не заблокировали? Может легко получиться результат, когда транзакция подвиснет, и средства необходимо будет перенаправлять куда-то еще, но уже в ручном режиме.
Обработка данных в реальном времени, на мой взгляд, является эталонным примером, когда такой подход идеально работает. Действительно, в самом начале мы проверяем, есть ли данные, которые необходимо обработать. Если их нет, то мы ничего не начинаем. Если данные есть, то мы запускаем обработчик и фиксируем результат, а затем результат последовательно записываем в очереди. Т.к. очереди у нас неограниченно размера, то запись в них всегда заканчивается успехом, а значит транзакционное поведение рано или поздно завершится. При этом можно видеть промежуточное состояние, но это ни у кого не вызовет недовольства: ведь зафиксировать неконсистентность между шардами, где отсутствуют полноценные транзакции — это оксюморон.
Двухфазность без блокировок
Раз уж речь зашла про транзакционность, то нехило было бы обдать двухфазный коммит.
Обычно он состоит из двух фаз: сначала блокируем записи и проверяем возможность выполнения коммита, и далее, если предыдущая фаза прошла благополучно, то накатываем изменения, попутно разблокируя записи. В этом смысле, транзакции на основе двухфазного коммита могут реализовывать оптимистично-пессимистичную схему блокировок:
- Оптимизм. С точки зрения клиента во время выполнения транзакции мы не блокируем записи, а лишь записываем, например, их версии или временные метки, для последующей валидации при коммите.
- Пессимизм. Во время коммита распределенной транзакции начинаем блокировать записи.
Некоторые дополнительные детали можно почитать, например, здесь.
Конечно, это несколько волюнтаристское прочтение понятий оптимистичности и пессимистичности, т.к. их можно лишь применять к самой транзакции, но не к отдельным ее частям, типа коммита. Однако фазу коммита можно рассматривать как отдельную транзакцию, возвращая эти понятия к своим исконным значениям.
Пессимистичная схема применения коммита как бы намекает на простой факт: данное действие не является lock-free от слова совсем, что может существенно снижать скорость обработки при случайных затупах и падений. И тем более тут речь не может идти о конкурентном применении транзакции, т.к. они будут лишь мешать друг другу, чем помогать.
В случае полутранзакций на основе CAS операций можно также увидеть ряд характерных черт. Вспомним, как происходит транзакционная запись в очередь:
# здесь приведены лишь фрагменты кода, который нас интересует handle(input, output, state): # ... while true: switch fsm_state: case {HANDLING, ...}: # обработка и фиксация записываемых данных fsm_state = {PREPARING, ...} case {PREPARING, input_index}: # подготовка к записи... output_index = ...get_next_index() fsm_state = {WRITING, output_index, ...} case {WRITING, output_index, ...}: # записываем данные, используя output_index
По сути, у нас здесь происходит следующее. После обработки данных мы хотим закоммитить результат в выходные очереди. Процесс коммита происходит в две стадии:
- PREPARING. На этой фазе получаем индекс, по которому на следующей фазе будем писать результат.
- WRITING. Запись результата по нужному индексу. Если по этому индексу уже была запись, то транзакция повторяется сначала с фазы PREPARING.
Это очень похоже на то, что происходит во время двухфазного коммита. Действительно, во время первой фазы мы подготавливаем необходимые данные для записи, а во время второй — производим непосредственно саму запись. Однако здесь есть принципиальные отличия:
- Получение индекса в первой фазе не блокирует выходную очередь. Более того, эта фаза является неинтрузивной, т.к. вообще не меняет состояние очереди, все действия происходят во второй фазе.
- В классическом двухфазном коммите после успешной первой фазы происходит безусловное применение второй, т.е. вторая фаза не имеет права завершиться неудачей. Однако в нашем случае вторая фаза может быть неуспешной, и действие необходимо повторить снова.
Таким образом, в lock-free варианте двухфазного коммита первое действие не блокирует состояние, а значит позволяет выполнять транзакционное действие полностью оптимистично, повышая доступность данных для изменения.
Требования к консистентности
Обсудим требования, предъявляемые к уровню консистентности хранилища. Интересный момент заключается в том, что любые чтения могут возвращать Stale Read, при этом консистентность алгоритма не будет нарушена. Самое главное — это правильная запись данных через операцию CAS: между чтением значения и записью во время ее выполнения не должно быть промежуточных изменений. Это приводит нас к следующим возможным хранилищам:
- Distributed single register — хранилища на основе атомарного изменения регистра (например, etcd и Zookeeper):
- Linearizability
- Sequential consistency
- Transactional — хранилища с транзакционным поведением (например, MySQL, PostgreSQL и т.п.):
- Serializability
- Snapshot Isolation
- Repeatable Read
- Read Committed
- Distributed Transactional — NewSQL хранилища:
- Strict Consistency
- Любые из вышеперечисленных
Однако возникает вопрос: на что влияет консистентное чтение и что будет происходить при чтении устаревших данных? Это будет влиять, прежде всего, на производительность алгоритма. Если мы читаем старые данные при изменении состоянии обработчика, то это может означать, что при записи посредством CAS нам может ожидать облом и все наработанные данные к этой фазе придется выкинуть и начать сначала. Поэтому имеет смысл рассматривать более строгие консистентные уровни, например, не ниже Read My Writes.
Заключение
Транзакционное поведение при обработке данных позволяет добиться exactly-once гарантий. Однако такое решение хуже масштабируется, т.к. транзакционная обработка, как правило, основана на двухфазном коммите, который блокирует соответствующие записи. Добавление требования конкурентного исполнения для избежания пауз, а также требования гетерогенности задают следующую, доселе недостижимую, планку, т.к. при высокой конкуренции распределенные транзакции приводят к конфликтам, катастрофически уменьшая пропускную способность обработки.
Разделение транзакций на полутранзакции и использование lock-free подхода позволяют значительно улучшить масштабируемость и гетерогенность.
Отметим важные преимущества подхода:
- Гетерогенность: единая абстракция для разных типов хранилищ.
- Атомарность: каждое действие является атомарным изменением персистентного состояния.
- Корректность: подход реализует самую строгую гарантию обработки реального времени: exactly-once.
- Concurrent: возможно конкурентное исполнение для избежания задержек исполнения.
- Real-time: обработка данных в реальном времени.
- Lock-free: на любом этапе данные не блокируются, всегда происходит прогресс в системе.
- Deadlock free: система никогда не придет в состояние, из которого не сможет делать прогресса.
- Race condition free: система не содержит состояния гонок.
- Hot-hot: отсутствуют временные задержки на восстановление системы от сбоев.
- Hard stop: можно жестко останавливать систему в любом месте.
- No failover: алгоритм загружает текущее состояние и сразу после этого совершает прогресс в системе без необходимости восстановления корректности предыдущего состояния.
- No downtime: обновления происходят без даунтайма.
- Абсолютная устойчивость: устойчивость к сбоям, замедлениям и конкурентному выполнению.
- Масштабируемость: шардирование очередей и соответствующих обработчиков позволяет горизонтально масштабировать систему.
- Гибкость: позволяет гибко настраивать цепочку вычислений и соответствующие параметры системы.
- Фундаментальность: подход на основе полутранзакций решает широкий класс задач.
Стоит отметить, что существует еще более фундаментальный и производительный подход. Но это уже другая история.

Новые термины
Бесполезно пытаться искать информацию о следующих терминах:
- Concurrent exactly-once.
- Semi-transactions или полутранзакции.
- Lock-free two-phase commit, оптимистичная двухфазность или двухфазный коммит без блокировок.
Задачи для самоистязания
- Реализовать асинхронную запись в очереди.
- Реализовать lock-free перевод средств на основе полутранзакций и очередей.
- Найти ошибку в обработчике.
Литература
[1] Википедия: Проблема ABA.
[2] Blog: You Cannot Have Exactly-Once Delivery
[3] Хабр: Достижимость нижней границы времени исполнения коммита распределенных отказоустойчивых транзакций.
[4] Хабр: Асинхронность 3: Субъекторная модель.
[5] Википедия: Неблокирующая синхронизация.

