Недавно на Kaggle закончилось соревнование iMaterialist Challenge (Furniture), задачей в котором было классифицировать изображения на 128 видов мебели и предметов быта (так называемая fine-grained classification, где классы очень близки друг к другу).
В этой статье я опишу подход, который принес нам с m0rtido третье место, но прежде, чем переходить к сути, предлагаю воспользоваться для решения этой задачи естественной нейросетью в голове и разделить стулья на фото ниже на три класса.

Вы угадали? Я — тоже нет.
Но стоп, обо всём по порядку.
В соревновании нам был дан набор данных, в котором были представлены 128 классов обычных объектов быта, таких как стулья, телевизоры, сковородки и подушки в виде аниме-персонажей.
Тренировочная часть датасета состояла из ~190 тысяч изображений (точное число назвать сложно, потому что участникам был предоставлен только набор URL для скачивания, часть из которых, разумеется, не работала), причем распределение классов было далеко от равномерного (см. кликабельное изображение ниже).

Тестовый датасет был представлен 12800 картинками, причем был идеально сбалансирован: на каждый класс приходилось по 100 изображений. Также был выдан валидационный датасет, который тоже имел сбалансированное распределение классов и был ровно вдвое меньше тестового.
Метрикой оценивания задачи был .
.
В первую очередь мы скачали данные и просмотрели небольшую часть глазами. Вместо многих картинок скачалось изображение размером 1х1 или плейсхолдер с ошибкой. Такие изображения мы сразу удалили скриптом.
Было очевидно, что с имеющимся количеством изображений и ограничениями по времени обучать на этом датасете нейронные сети с нуля — не очень здравая мысль. Вместо этого мы использовали подход transfer learning, идея которого заключается в следующем: веса сети, обученной на одной задаче, можно использовать для совершенно другого набора данных и получить приличное качество, а то и вовсе прирост к точности по сравнению с обучением с нуля.
За счет чего это работает? Скрытые слои в глубоких нейронных сетях выступают в качестве feature extractor'ов, извлекая признаки, которые потом используются верхними слоями непосредственно для классификации.
Этим мы и воспользовались, дообучив ряд глубоких CNN, предварительно обученных на ImageNet. Для этих целей мы использовали Keras и его зоопарк моделей, где для загрузки готовой архитектуры было достаточно примерно такого кода:
После этого мы извлекали из сети так называемые bottleneck-признаки (фичи на выходе с последнего сверточного слоя) и обучали поверх них softmax с дропаутом.
Затем, обученные веса «верхушки» мы соединяли со сверточной частью сети и обучали уже всю сеть сразу.
При подобной тонкой настройке сетей мы успели попробовать следующие хаки:
Сети, обученные таким образом, составили 90% нашего финального ансамбля.
Дисклеймер: никогда не повторяйте приём, описанный далее, в реальной жизни.
Итак, как мы определились в предыдущем разделе, bottleneck-фичи из сетей, обученных на ImageNet, могут быть использованы для классификации на других задачах. m0rtido решил пойти дальше, и предложил следующую стратегию:
Получившийся в результате чудовищный стекинг давал огромную прибавку по точности к общему ансамблю.
После всего вышеописанного мы имели около двух десятков затюненных сверточных сетей, а также два перцептрона поверх bottleneck-признаков. Стоял вопрос: как из этого всего получить единое предсказание?
По-хорошему, в лучших традициях Kaggle мы должны были сделать стекинг поверх всего этого, но для того, чтобы сделать OOF stacking, у нас не было ни времени, ни GPU, а обучение модели верхнего уровня на валидационном холдауте приводило к очень большому оверфиту. Поэтому мы решили реализовать довольно простой алгоритм жадного создания ансамбля:
В качестве метрики был выбран . Эта формула была подобрана эмпирически таким образом, чтобы
. Эта формула была подобрана эмпирически таким образом, чтобы  и
и  получались примерно одних масштабов. Такая интегральная метрика хорошо коррелировала с как на валидации, так и на публичном лидерборде.
получались примерно одних масштабов. Такая интегральная метрика хорошо коррелировала с как на валидации, так и на публичном лидерборде.
Кроме того, тот факт, что на каждой итерации мы добавляли или удаляли одну модель (т.е. веса моделей всегда оставались целыми числами), играл роль своеобразной регуляризации, не позволяя ансамблю оверфититься под валидационный набор данных.
В итоге в ансамбль вошли следующие модели:
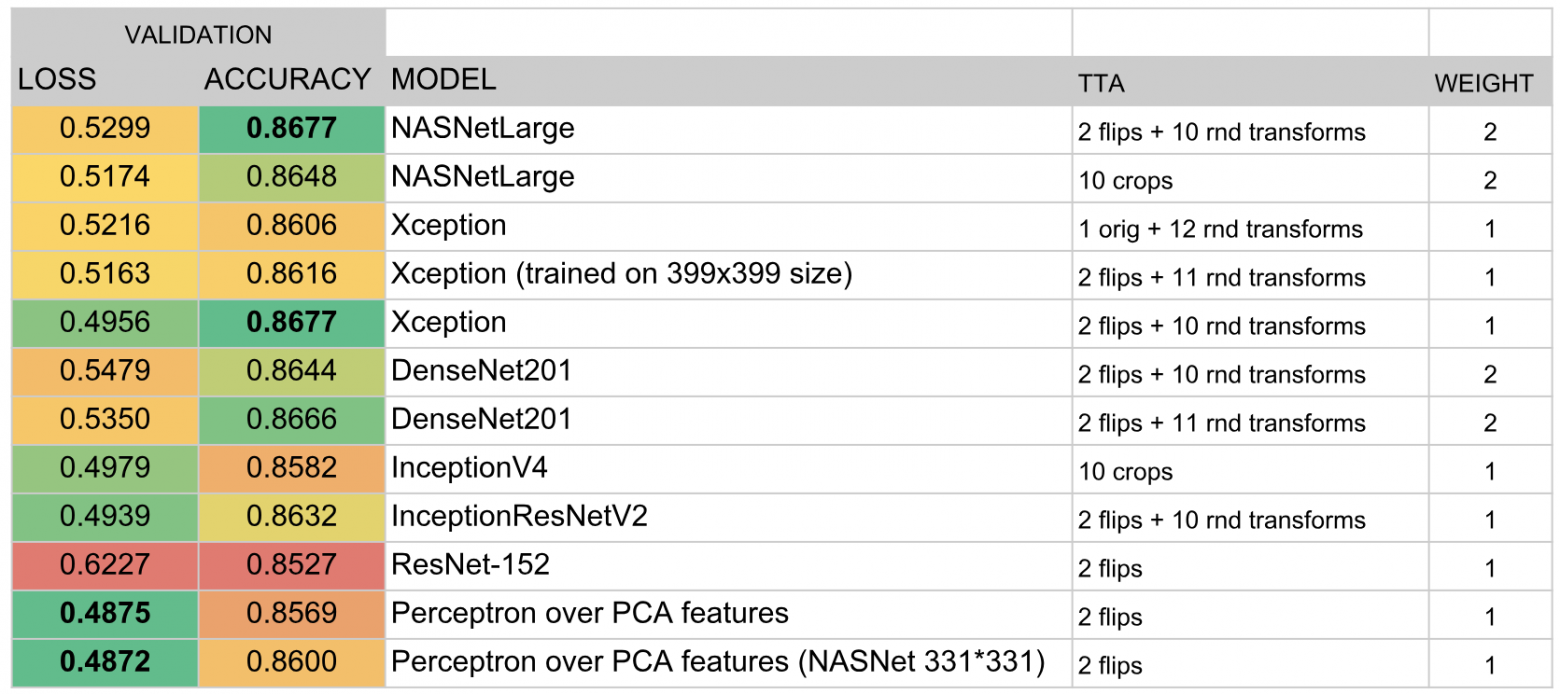
По итогам конкурса мы заняли третье место. Залогом успеха стали, как мне кажется, удачный выбор алгоритма ансамблирования и огромное количество времени, которое m0rtido и я вложили в обучение большого количества моделей.

В этой статье я опишу подход, который принес нам с m0rtido третье место, но прежде, чем переходить к сути, предлагаю воспользоваться для решения этой задачи естественной нейросетью в голове и разделить стулья на фото ниже на три класса.
Настоящие классы
Вы угадали? Я — тоже нет.
Но стоп, обо всём по порядку.
Постановка задачи
В соревновании нам был дан набор данных, в котором были представлены 128 классов обычных объектов быта, таких как стулья, телевизоры, сковородки и подушки в виде аниме-персонажей.
Тренировочная часть датасета состояла из ~190 тысяч изображений (точное число назвать сложно, потому что участникам был предоставлен только набор URL для скачивания, часть из которых, разумеется, не работала), причем распределение классов было далеко от равномерного (см. кликабельное изображение ниже).

Тестовый датасет был представлен 12800 картинками, причем был идеально сбалансирован: на каждый класс приходилось по 100 изображений. Также был выдан валидационный датасет, который тоже имел сбалансированное распределение классов и был ровно вдвое меньше тестового.
Метрикой оценивания задачи был
.Как мы решали?
В первую очередь мы скачали данные и просмотрели небольшую часть глазами. Вместо многих картинок скачалось изображение размером 1х1 или плейсхолдер с ошибкой. Такие изображения мы сразу удалили скриптом.
Transfer learning
Было очевидно, что с имеющимся количеством изображений и ограничениями по времени обучать на этом датасете нейронные сети с нуля — не очень здравая мысль. Вместо этого мы использовали подход transfer learning, идея которого заключается в следующем: веса сети, обученной на одной задаче, можно использовать для совершенно другого набора данных и получить приличное качество, а то и вовсе прирост к точности по сравнению с обучением с нуля.
За счет чего это работает? Скрытые слои в глубоких нейронных сетях выступают в качестве feature extractor'ов, извлекая признаки, которые потом используются верхними слоями непосредственно для классификации.
Этим мы и воспользовались, дообучив ряд глубоких CNN, предварительно обученных на ImageNet. Для этих целей мы использовали Keras и его зоопарк моделей, где для загрузки готовой архитектуры было достаточно примерно такого кода:
base_model = densenet.DenseNet201(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg')
После этого мы извлекали из сети так называемые bottleneck-признаки (фичи на выходе с последнего сверточного слоя) и обучали поверх них softmax с дропаутом.
Затем, обученные веса «верхушки» мы соединяли со сверточной частью сети и обучали уже всю сеть сразу.
Посмотреть код.
for layer in base_model.layers: layer.trainable = True top_model = Sequential() top_model.add(Dropout(0.5, name='top_dropout', input_shape=base_model.output_shape[1:])) top_model.add(Dense(128, activation='softmax', name='top_softmax')) top_model.load_weights('top-weights-densenet.hdf5', by_name=True) model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) initial_lrate = 0.0005 model.compile(optimizer=Adam(lr=initial_lrate), loss='categorical_crossentropy', metrics=['accuracy'])
При подобной тонкой настройке сетей мы успели попробовать следующие хаки:
- Аугментация данных. Для борьбы с оверфитингом мы использовали очень жёсткую аугментацию: горизонтальное отражение, зум, сдвиги, повороты, наклоны, добавление цветового шума, сдвиги цветовых каналов, обучение на пяти кропах (углы и центр изображения). Также мы хотели попробовать FancyPCA, но не смогли из-за недостатка вычислительных ресурсов.
- TTA. Для предсказания классов на валидации и тесте мы применяли аугментацию, чуть менее агрессивную, чем при обучении, и усредняли результаты предсказаний для увеличения точности.
- Циклический Learning rate. Циклическое повышение и понижение темпа обучения помогало моделям не застревать в локальных минимумах.
- Обучение модели на подмножестве классов. Как можно понять из картинки над катом, в датасете содержались очень близкие друг к другу классы. Настолько близкие, что на определенных кластерах объектов (например, на стульях и креслах, которые были представлены аж 8 классами) наши модели ошибались куда сильнее, чем на других типах объектов. Мы попробовали обучить отдельную CNN распознавать только стулья, надеясь, что такая сеть научится различать сорта стульев лучше, чем general-purpose сеть, однако этот подход не дал прироста в точности.
Почему? Частично ответ на этот вопрос представлен на картинке перед катом — классы были настолько похожими, что даже при исходной разметке данных люди, проставлявшие метки классов, не могли их различить, поэтому хорошей точности выжать из этих данных всё равно бы не удалось. - Spatial Transformer Network. Несмотря на то, что мы обучили одну из сетей с ней и получили довольно неплохую точность, в финальный сабмит она, к сожалению, не вошла.
- Взвешенная функция потерь. Чтобы компенсировать несбалансированное распределение классов, мы использовали weighted loss. Это помогало как при обучении softmax-«верхушек», так и при дальнейшем дообучении целой сети. Веса вычислялись с помощью функции из scikit-learn и потом передавались в метод fit у модели:
train_labels = utils.to_categorical(train_generator.classes) y_integers = np.argmax(train_labels, axis=1) class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
Сети, обученные таким образом, составили 90% нашего финального ансамбля.
Стекинг bottleneck-признаков
Дисклеймер: никогда не повторяйте приём, описанный далее, в реальной жизни.
Итак, как мы определились в предыдущем разделе, bottleneck-фичи из сетей, обученных на ImageNet, могут быть использованы для классификации на других задачах. m0rtido решил пойти дальше, и предложил следующую стратегию:
- Возьмём все доступные нам предобученные архитектуры (в частности, были взяты NasNet Large, InceptionV4, Vgg19, Vgg16, InceptionV3, InceptionResnetV2, Resnet-50, Resnet-101, Resnet-152, Xception, Densenet-169, Densenet-121, Densenet-201) и извлечем из них bottleneck-признаки. Посчитаем также признаки для отраженных вариантов картинок (такая себе минималистичная аугментация).
- Уменьшим размерность признаков каждой из моделей в три раза с помощью РСА, чтобы они нормально помещались в доступные нам 16 Gb RAM.
- Конкатенируем эти признаки в один большой feature vector.
- Обучим поверх всего этого один многослойный персептрон и сгенерируем предсказания. Также обучим с разбиением на фолды и усредним все эти предсказания.
Получившийся в результате чудовищный стекинг давал огромную прибавку по точности к общему ансамблю.
Ансамбль моделей
После всего вышеописанного мы имели около двух десятков затюненных сверточных сетей, а также два перцептрона поверх bottleneck-признаков. Стоял вопрос: как из этого всего получить единое предсказание?
По-хорошему, в лучших традициях Kaggle мы должны были сделать стекинг поверх всего этого, но для того, чтобы сделать OOF stacking, у нас не было ни времени, ни GPU, а обучение модели верхнего уровня на валидационном холдауте приводило к очень большому оверфиту. Поэтому мы решили реализовать довольно простой алгоритм жадного создания ансамбля:
- Инициализируем пустой ансамбль.
- Пытаемся добавить каждую модель по очереди и считаем score. Выбираем модель, которая повышает метрику больше всего и добавляем её к ансамблю. Результаты предсказания моделей в ансамбле просто усредняются.
- Если ни одна из моделей не улучшает показателей, проходимся по ансамблю и пытаемся удалять из него модели. Если получается удалить какую-то модель так, что score улучшается, делаем это и возвращаемся на шаг 2.
В качестве метрики был выбран
. Эта формула была подобрана эмпирически таким образом, чтобы и получались примерно одних масштабов. Такая интегральная метрика хорошо коррелировала с как на валидации, так и на публичном лидерборде.Кроме того, тот факт, что на каждой итерации мы добавляли или удаляли одну модель (т.е. веса моделей всегда оставались целыми числами), играл роль своеобразной регуляризации, не позволяя ансамблю оверфититься под валидационный набор данных.
В итоге в ансамбль вошли следующие модели:
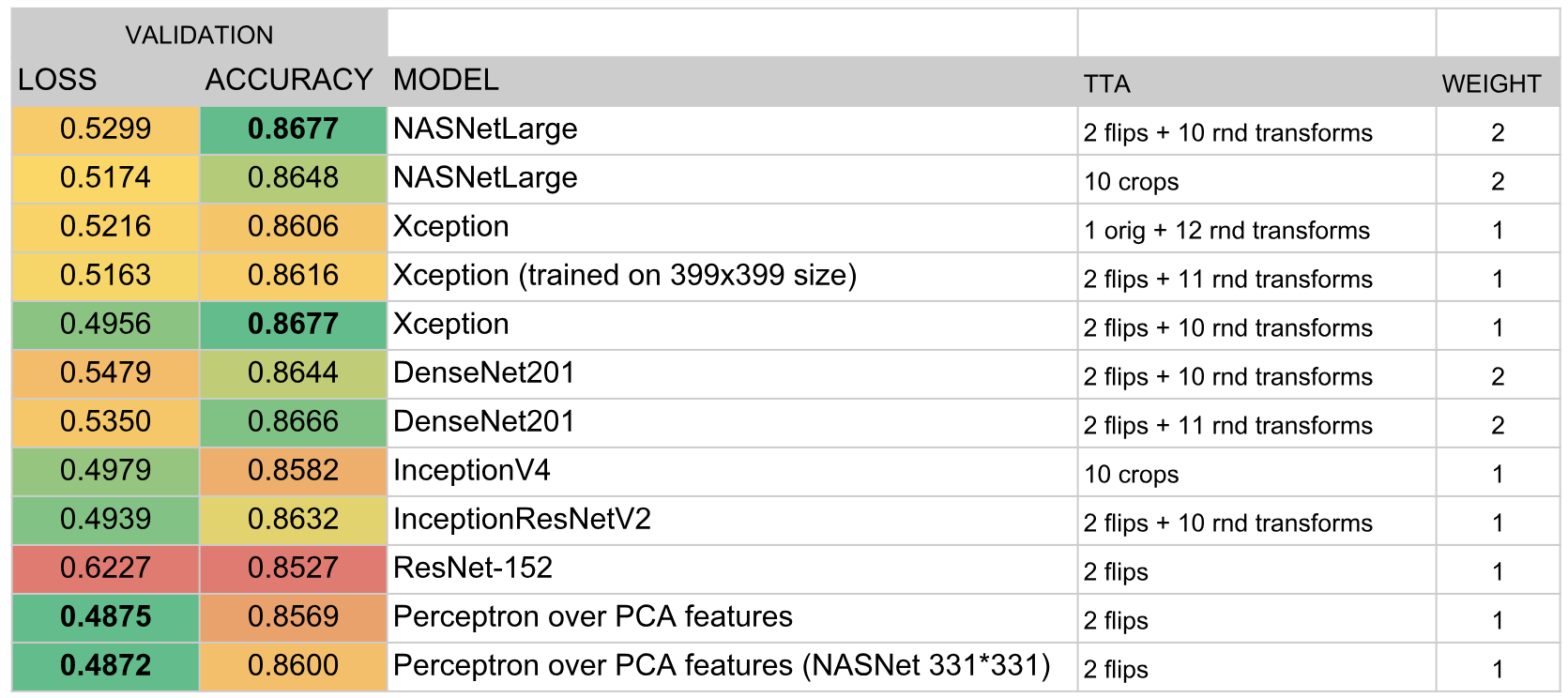
Результаты
По итогам конкурса мы заняли третье место. Залогом успеха стали, как мне кажется, удачный выбор алгоритма ансамблирования и огромное количество времени, которое m0rtido и я вложили в обучение большого количества моделей.

