Эта статья является пересказом моего доклада на Java-конференции SnowOne 2021 года. LJV — проект, созданный в 2004 году как инструмент для преподавания языка Java студентам. Он позволяет визуализировать внутреннее устройство структур данных. В этом докладе я запускаю LJV на разных структурах (от String до ConcurrentSkipListMap) в разных версиях Java и разбираю, что там внутри, как оно менялось от версии к версии, и как это всё работает.

Откуда взялся LJV и зачем он нужен
Моя основная работа – инженер на коммерческих проектах, но также я работаю в МФТИ, где раз в неделю читаю лекции по Java. Обычно на конференциях я рассказываю про опыт, связанный с коммерческими проектами, но этот доклад сделан исключительно на основе опыта, полученного в процессе преподавания.
Моя основная работа – инженерная, преподаю я как совместитель. Пару лет назад мне пришла идея сделать лекционный курс по Java. Что такое сделать лекционный курс? Это значит, что 14 недель подряд нужно готовить качественный полуторачасовой доклад. Неохота рисовать на доске, хочется переиспользовать из года в год одни и те же слайды. В процессе создания и редактирования слайдов хочется не выходить из своей IDE, то есть создавать слайды как код. Кроме того, мне, как ленивому программисту (а каждый программист ленив) хочется, чтобы некоторые слайды себя сами нарисовали – например, слайд с внутренним устройством какой-нибудь HashMap.
Насчёт того, как делать слайды как код, у меня есть пост на Habr, где рассказано, какие технологии для этого можно применить. Но отдельно следует упомянуть такую вещь, как Graphviz – Graph Visualization Software. Я уверен, что очень многие знают его, но кто-то, возможно, слышит о нём впервые. Если зайти на Википедию, то можно узнать, что это программа очень старая, первый релиз был до 1991 года. Но если зайти в GitLab, то мы увидим, что последний релиз был совсем недавно, и бурная деятельность в проекте продолжается. Это очень продвинутая и активно развивающаяся десятилетиями штука. Она состоит из двух частей. Первая – это язык DOT. Вторая – это софт для визуализации текстов на языке DOT.
Вот пример простого DOT-скрипта:
digraph G{ A->B->C; B->D->A; C->A; }
Мы определили digraph, то есть directed graph, направленный граф, определили ноды, связи между ними, сохранили этот скрипт как текстовый файл. Теперь, если выполнить в консоли команду
dot -Tpng myfile.dot > myfile.png
то мы получим вот такую красивую png-картинку:
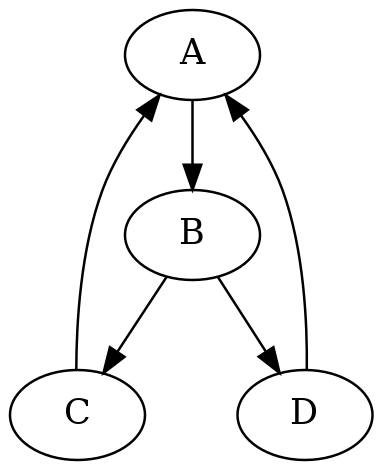
Смысл Graphviz в том, что вы задаете ноды и связи в графе, а он сам красиво их располагает на плоскости и отрисовывает. Конечно, как всегда, дьявол кроется в деталях. DOT – система достаточно продвинутая, на ней можно рисовать интересные вещи, но для того, чтобы достичь желаемых результатов, потребуется некоторое изучение этой технологии. Однако именно на языке DOT я люблю рисовать диаграммы, когда мне надо делать слайды как код.
И вот, начиная создавать курс лекций по Java, я стал гуглить в поисках какого-нибудь механизма, который внутреннее устройство стандартных объектов Java автоматически отрисовывал бы в языке DOT. И я нашел. Я нашел очень старую страницу Computer Science Department Оклендского университета. Человек по имени John Hamer в 2004 году сделал утилиту, которую назвал LJV. Хотя сейчас это трудно себе представить, но в 2004 году ещё не было ни GitHub, ни Maven. Поэтому все, что сделал Джон – по GPL лицензии выложил файл LJV.java на университетской странице.
Я взял этот файл, и, к моему удивлению, эта штука оказалась рабочей. Она работает на любых версиях Java, потому что она очень проста по идее: она использует Reflection API для того, чтобы посмотреть, из чего объект состоит, и довольно прямолинейную трансляцию в DOT для того, чтобы это визуализировать. Я построил какие-то иллюстрации для своих слайдов. Затем осенью 2020 года я предложил своим студентам, Нурасу Ногаеву и Илье Селиванову, в качестве семестрового задания превратить этот проект в современный, то есть выложить на GitHub, обложить тестами, отрефакторить. Вот какой проект получился: https://github.com/atp-mipt/ljv (кстати, приходите, поставьте туда звезду). О том, как им пользоваться, можно прочитать в документации и README.
Цель моего доклада – применить этот инструмент к стандартным классам и стандартной библиотеке Java и посмотреть, какие штуки интересные мы можем там увидеть.
Простой пример использования LJV
Пользоваться LJV довольно просто. Сначала мы создаем объект с типом LJV и при необходимости конфигурируем его дополнительными опциями:
LJV ljv = new LJV() .setQualifyNestedClassNames(true) .setIgnoreNullValuedFields(true) .addFieldAttribute("sourceSpliterator", "constraint=false");
На втором шаге мы создаем тот объект, который хотим визуализировать. Например, мы хотим посмотреть, как устроен объект Stream<Integer>, построенный на иммутабельном списке, с map и filter:
Stream<Integer> o = List.of(1, 2, 3) .stream() .map(x -> x * x) .filter(x -> x % 2 == 0);
Построив этот объект, мы просто передаем его в метод LJV.drawGraph. На выходе у нас получается строка, которая из себя представляет DOT-скрипт:
String dot = ljv.drawGraph(o);
И дальше мы можем с этим делать что угодно. Если программа dot стоит на локальной машине, можно локально сгенерировать и получить png или svg. Но есть замечательный сайт, называемый Graphviz Online, который тот же самый dot-скрипт выполняет у вас в браузере, и может прямо в браузере открыть визуализацию скрипта, если его в формате URLEncoded передать в URL страницы.
//use GraphViz online String encoded = URLEncoder.encode(dot, "UTF8") .replaceAll("\\+", "%20"); Desktop.getDesktop().browse( new URI("https://dreampuf.github.io/GraphvizOnline/#" + encoded));
При запуске этой программы откроется браузер, и мы увидим такую картинку:

Что это за нотация?
Прямоугольники – это объекты. Три выложенных в ряд квадратика в правом нижнем углу – это массив. Т. к. источником данных у нас является иммутабельный список, его объект отображён как экземпляр класса ListN, в основе которого массив из трех элементов – боксированных Integer.
Примитивные поля каждого объекта перечисляются в правой части прямоугольника. Примитивные поля – это либо поля примитивных типов (таких как int, boolean и т. п.), либо такие, которые мы настройкой LJV считаем примитивными, чтобы излишне не усложнять граф объектов.
Поля, являющиеся ссылками на другие объекты (например, previousStage, nextStage) показаны именованной стрелкой.
Так получается граф объектов: есть иммутабельная коллекция ListN, на неё ссылается RandomAccessSpliterator, над ним три Stage нашего Stream, и еще в стороны торчат лямбды для map и для filter – но средствами Reflection API невозможно узнать, что находится внутри лямбд.
Визуализация строк и боксированных примитивов
Теперь мы попробуем применить этот инструмент к самым разным классам и объектам из стандартной библиотеки. Сначала начнем с простого. Какой самый распространенный класс в Java? Конечно, String. Выполним new LJV.drawGraph ("hello"), и посмотрим, что он нарисует.
Результат, который мы увидим, будет зависеть от версии Java, которая у вас стоит.
На сегодняшний день устройство строк менялось в Java три раза. До 6-й версии в начале 7-й у строки было три поля – offset, count и hash. Потом убрали поля offset и count. Потом стали появляться новые поля.
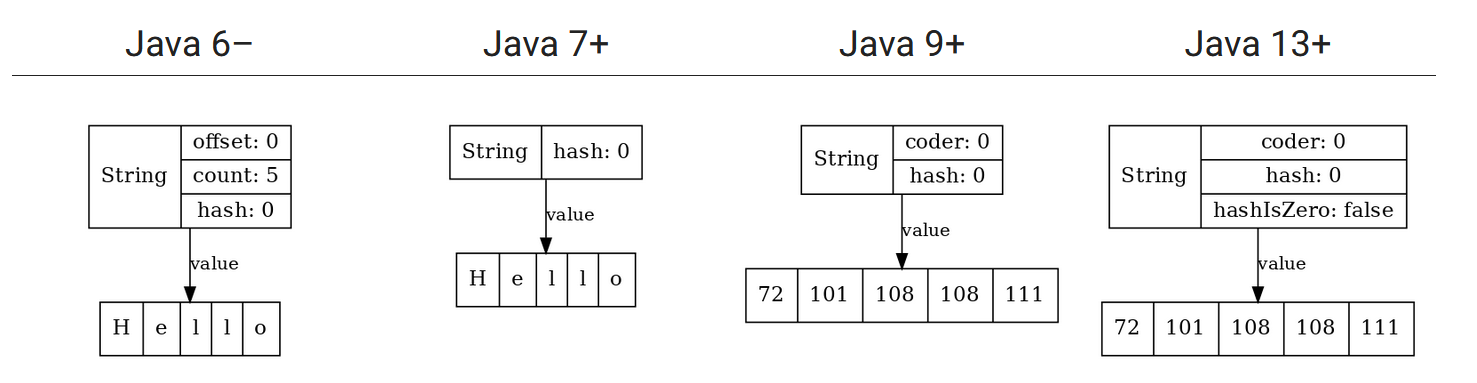
В общем, вся эволюция string немножко напоминает одну известную картинку:

Давайте быстро разберёмся, почему так происходило.
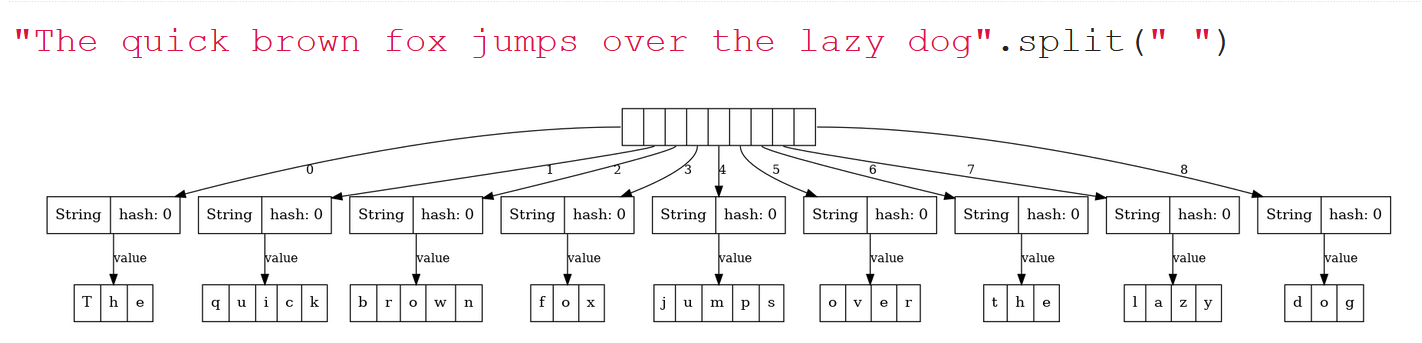
Если в Java 6 мы возьмем длинную строчку и выполним split(...), то картинка, которую мы увидим, будет вот такая:
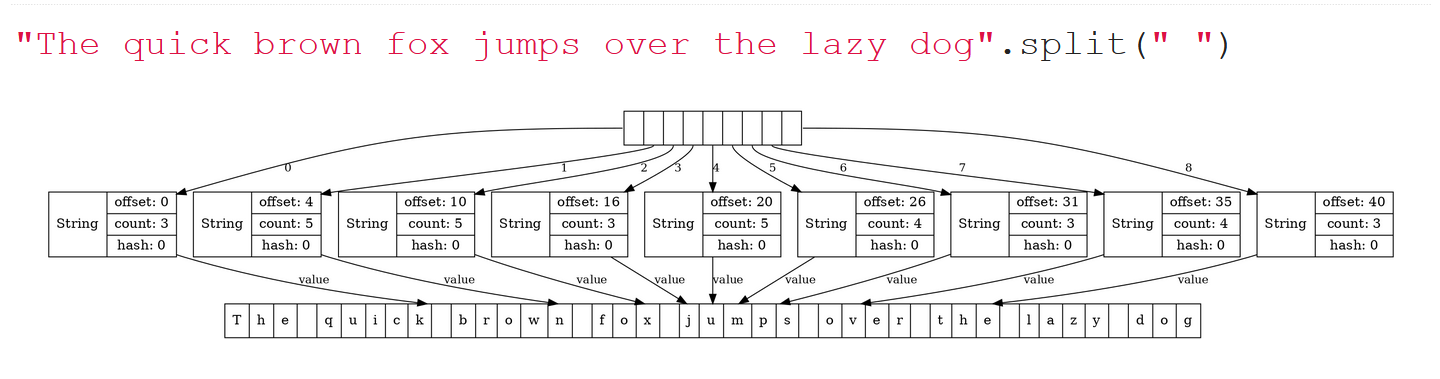
Исходная строка превратилась в массив строк, но при этом каждая строка из этого массива переиспользует один большой длинный буфер, а поля offset и count указывают на разные сегменты этого буфера. Вроде бы замечательная идея, потому что в этой ситуации метод split работает быстро, метод substring работает тоже быстро, мы не тратим время на пересоздание этих буферов.
Однако более часто встречается иная ситуация. Если мы хотим просто выделить из длинной строки первое слово, допустим, «The» при помощи substring, и в Java 6 это визуализируем, то мы увидим такую картинку:
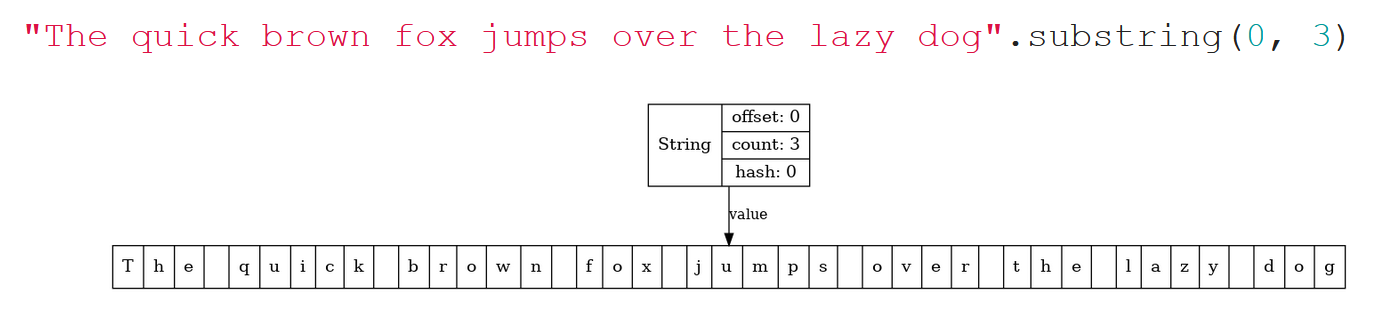
То есть, обратите внимание: эта строчка, если её распечатать в консоли, выведет просто «The». Но в памяти она держит ссылку на длинный буфер. Если весь буфер нам больше не нужен, а нужен только этот сегмент «The», то, если мы специально не постараемся, от остальных символов мы не избавимся никак. Это утечка памяти, и поэтому, начиная с определенного апдейта Java 7, ситуация поменялась: от offset решили избавиться, и все стало гораздо проще. Теперь, если мы на Java 8 сделаем split, то увидим, что каждая строчка порождает свой собственный внутренний буфер (что привело к замедлению работы split), но пример с substring уже выглядит хорошо:
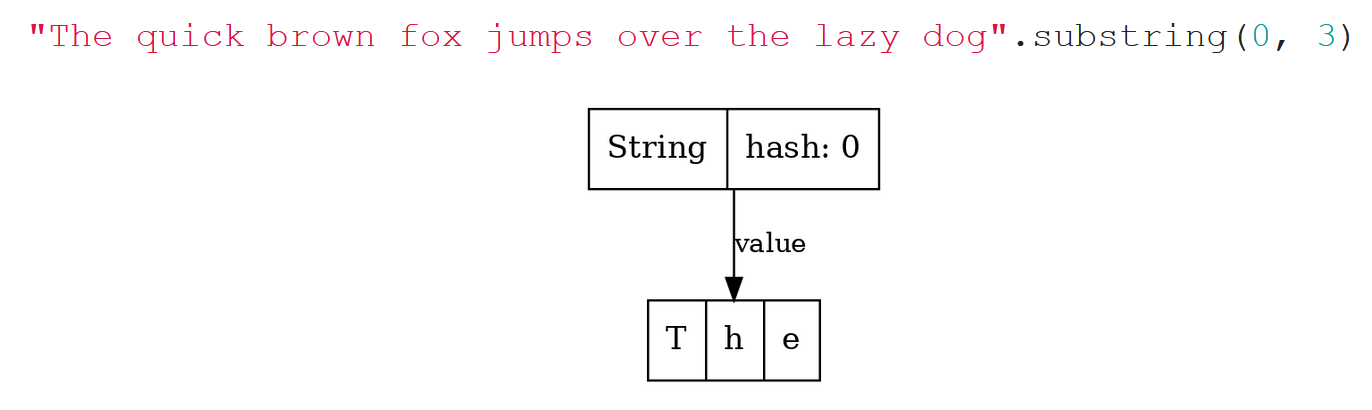
Теперь строка, содержащая три символа, занимает в памяти всего лишь три char, а большой буфер, если он не нужен, можно отправить в garbage collection.
История двигалась дальше, и в Java 9, как мы знаем, появились compacted-строки. До этого момента буфер String был массивом char[]. Char – это 16-битовое значение. Когда выбирали примитивные типы для Java в 90-е годы прошлого столетия, считалось, что, наверное, 65 тысяч значений хватит, чтобы каждый символ Unicode в char уместить.
Потом оказалось, что это не так, и char, строго говоря, это уже не всегда целый символ. А потом, с другой стороны, оказалось, что большое количество строк, с которыми работают программы на Java, состоят из латинского алфавита и каких-то базовых знаков препинания. Короче говоря, они умещаются в байт, и поэтому, используя 2 байта на один char, мы впустую тратим пространство.
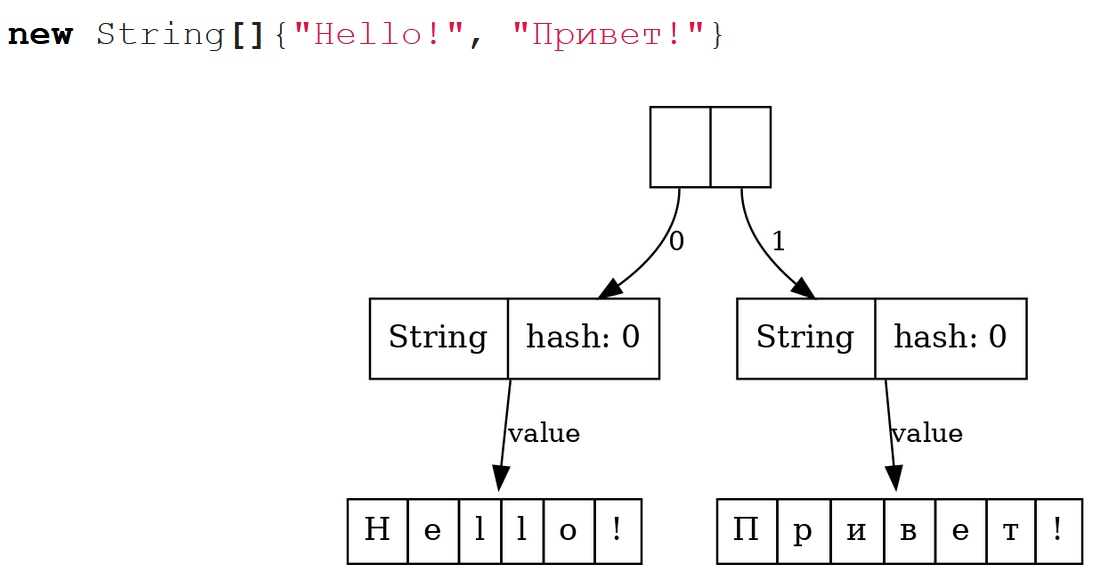
Поэтому, начиная с Java 9, появились compacted строки. Теперь буфер строки – не char[], а byte[], и поэтому в случае со строкой “hello”, содержащей только латинские буквы, значение поля coder = 0, и каждый символ превратился в один байт. Хотя элементов в массиве столько же, но памяти он занимает в два раза меньше, потому что это не char[], а byte[]. В случае со строчкой «привет» мы, по крайней мере, не проиграли в длине буфера, потому что на каждый символ приходится по два байта, и coder = 1.
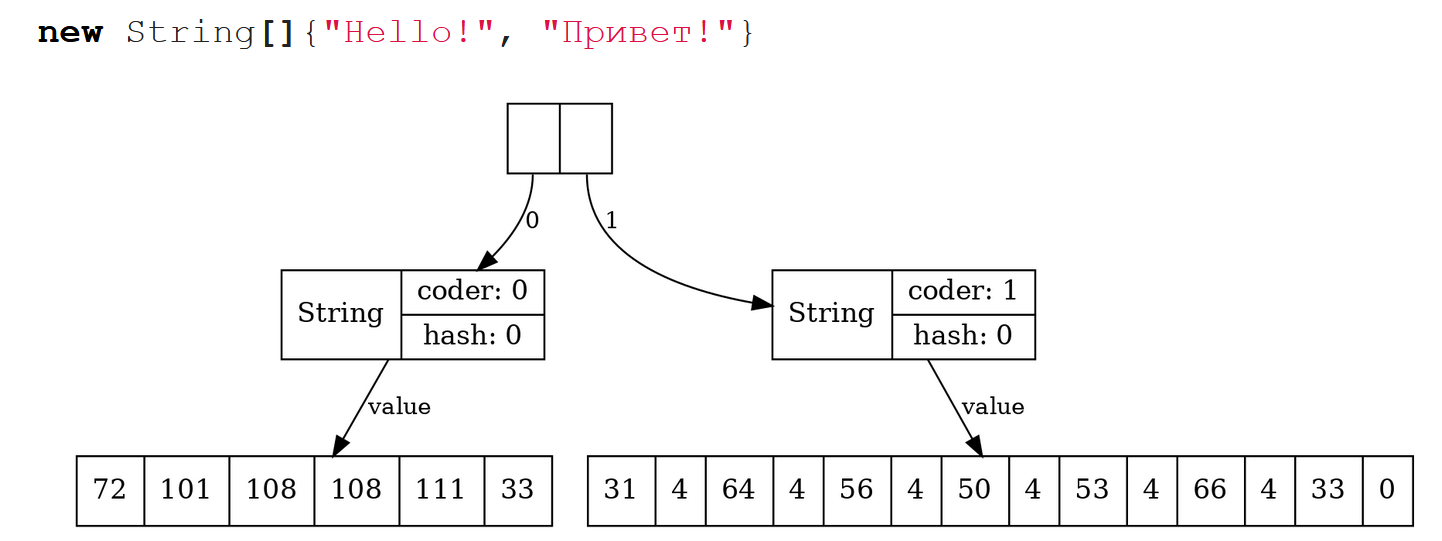
Но это еще не все. Последнее на сегодня усовершенствование класса String произошло в Java 13, и оно было связано вот с чем.
Так получилось, что алгоритм вычисления хэшей для Java строки допускает нулевой хэш для непустой строки. Значение переменной hash призвано запоминать уже вычисленный hash, но если оно равно нулю, то система считает, что мы hash еще не посчитали, и будет его пересчитывать всякий раз. Из-за этого непустые строчки, в которых нулевой hash (к примеру, "f5a5a608"), будут себя аномально плохо вести с точки зрения перформанса внутри хэш-таблиц.
String[] s = new String[]{"f5a5a608", "abc"}; System.out.println(s[0].hashCode()); //0 System.out.println(s[1].hashCode()); //96354
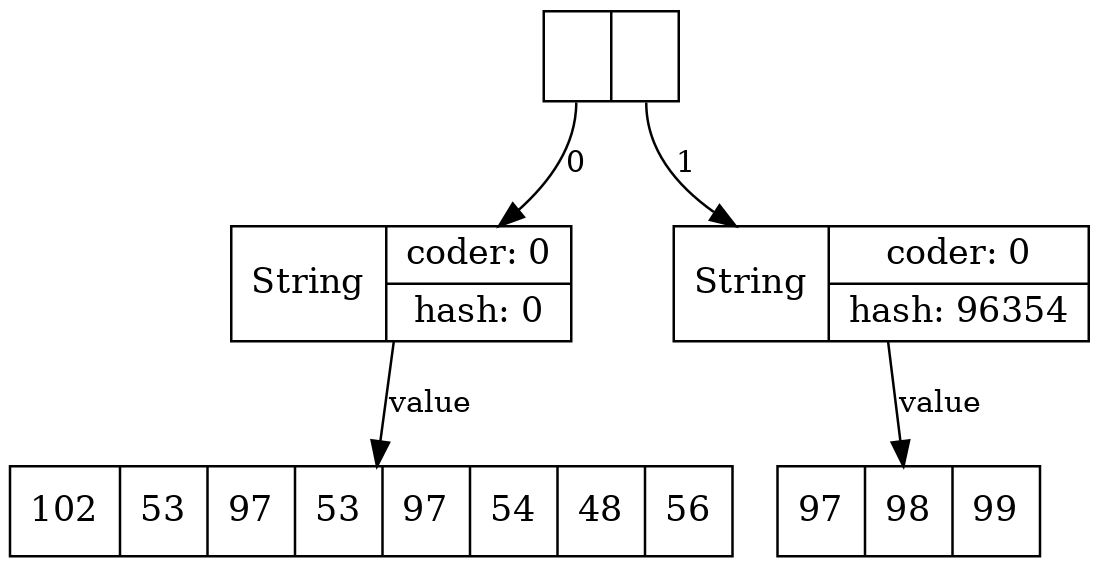
Поэтому, начиная с Java 13, появилось специальное поле hashIsZero, позволяющее различить такие случаи. Теперь, если наша строка действительно имеет нулевой хэш, она будет так же быстро обрабатываться, как и все остальные. Заметим, что на общем объёме памяти, занимаемой строками, это нововведение никак не сказалось, т. к. за счёт выравнивания полей объем памяти, занимаемый объектом String, не изменился:
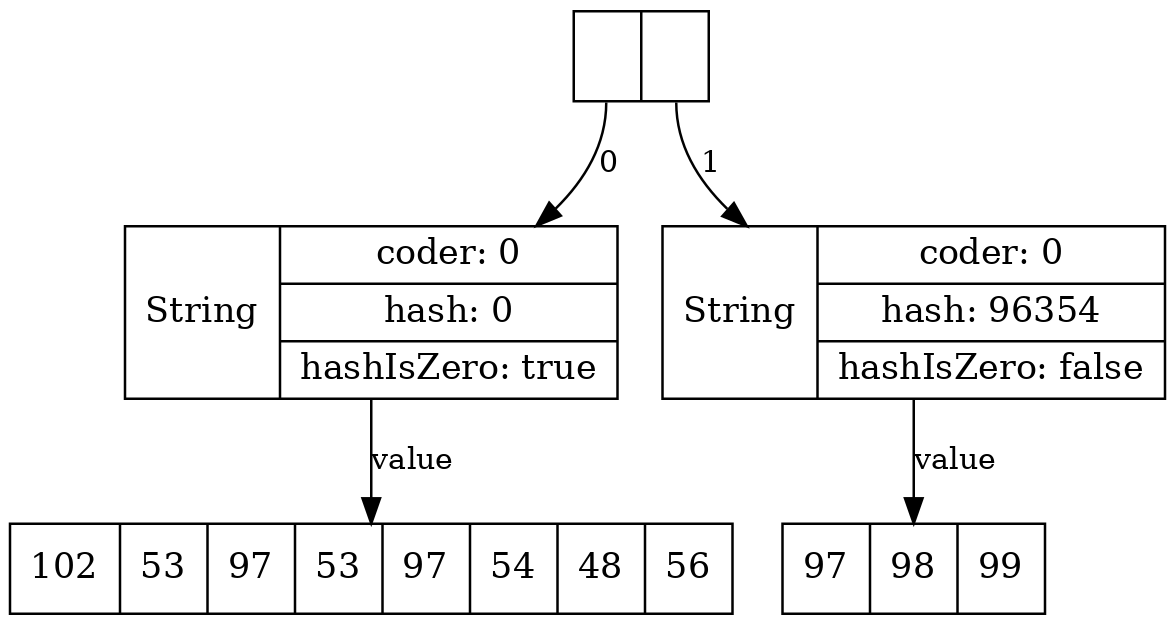
Тут можно поспорить, нужно это было делать или нет: ведь строки с нулевым хэшем должны встречаться очень редко, статистически – одна на 4 миллиарда. Но, по крайней мере, ушла возможность с помощью злонамеренных действий заполнить хэш-таблицу специально строками с нулевым хэшем с целью устроить DoS атаку. Ведь хэш-функция для Java-строк не является криптографической и можно очень легко сгенерировать много строк с заранее заданным хэшем!
Есть еще интересный момент. Хотя начиная с Java 7, система больше не занимается попытками частично переиспользовать длинные буферы, в целом не запрещено и даже имеет смысл переиспользовать буфер строки целиком между двумя равными по equals строками. Посмотрим на следующий пример: в нём есть «hello» и массив строчек, каждый элемент которого сконструирован по-разному, но при этом с точки зрения equals равен исходному «hello»:
String x = "Hello"; new String[]{x, new String(x), new String(x.toCharArray()), x + "", "" + x, x.concat(""), "".concat(x)}
Как это будет выглядеть с точки зрения размещения объектов в памяти?
На Java до версии 15 мы увидим такую картину:
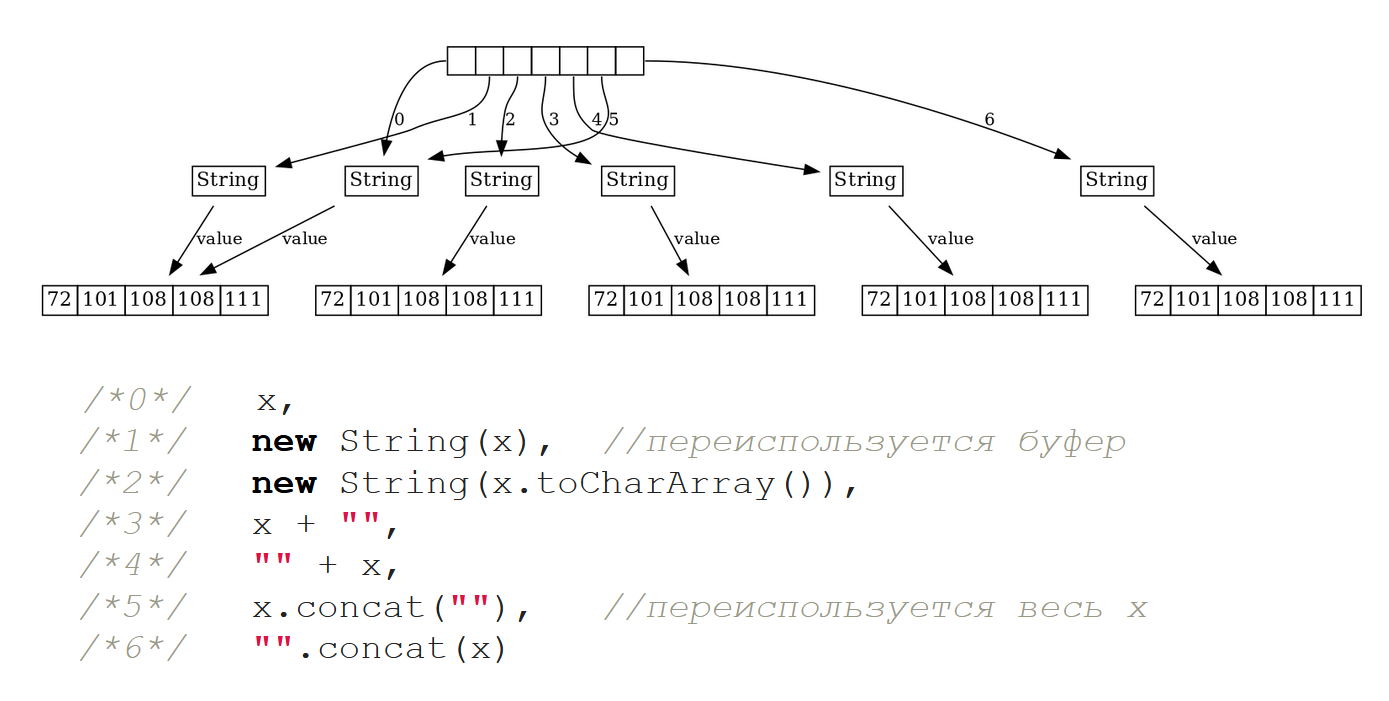
Нулевой элемент массива – сама исходная строчка x.
Понятно, что оператор new должен порождать новый объект. Но если мы передаем какую-то строчку в параметр конструктора String, то Java переиспользует внутренний буфер.
Во втором элементе мы сначала перевели строку в char[], и понятно, что тут связь потерялась с исходным буфером, поэтому ничего удивительного, что второй случай порождает нам новый String с новым буфером.
А вот дальше происходит что-то интересное. Случай конкатенации с пустой строкой – тривиальный, но тем не менее, нам спецификация языка говорит, что конкатенация должна порождать новый объект. Однако заметим, что до 15-й Java при этом зачем-то и буфер пересоздается заново!
У класса String есть еще метод concat(..). В методе concat(..), если посмотреть его исходный код, есть микрооптимизация: если в качестве аргумента приходит пустая строка, то возвращается тот же самый объект, на котором метод concat(..) вызывался. Это – пятый элемент массива.
Выглядит это не очень здорово, но, благодаря усилиям Тагира Валеева, начиная с Java 16 картина сильно исправилась. Как мы видим, теперь во всех этих случаях происходит переиспользование буфера для одинаковой строки, в том числе при конкатенации с пустой строкой. Для элемента с индексом 5 микрооптимизация для concat сохраняется, ну и в случае №2, когда мы теряем всякую связь с исходным буфером – ничего не поделаешь, тут, конечно, будет новый объект и новый его буфер:
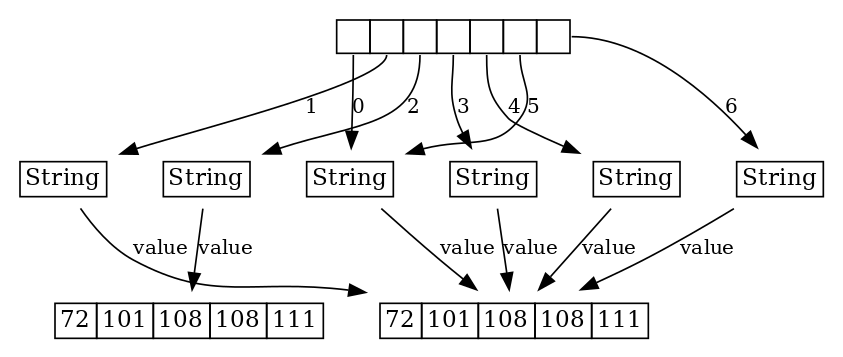
Коротко скажу про интернирование. Наверное, лучше, чтобы много людей не знали про метод intern(). Но так уж вышло, что люди любят разбираться в низкоуровневых API и знают про него. Если мы возьмем все те же самые выражения, вызовем на них метод intern() и запустим LJV, LJV покажет, что все это схлопнулось в один-единственный объект, который был дедуплицирован и положен во внутренний пул строк:

Но если вы не пишете стандартную библиотеку Java, то метод intern() не для вас. Почему? Можете посмотреть соответствующий доклад Алексея Шипилёва на эту тему – прямо сейчас я дам ссылки.
Давайте сделаем промежуточные выводы:
- Переходите на новые версии Java, если это, конечно, возможно. Строки становятся все эффективнее и эффективнее, оптимизации видны невооруженным глазом.
- Помним про дедупликацию строк и при наличии показаний со стороны перформанс-анализа имеет смысл задуматься о ней, чтобы сделать ее, например, на HashSet-е, но только не через метод
intern().
Почему так? Про внутреннее устройство строк и их эволюцию довольно много было докладов. Это и доклады Алексея Шипилева (Катехизис java.lang.String (JPoint 2015, 20.04.2015), The Lord of the Strings: Two Scours (JBreak 2016, 19.03.2016)), доклады Тагира Валеева (Ещё немного маленьких оптимизаций (JPoint 2020, 29.06.2020)), и был доклад Сергея Цыпанова на прошлом JPoint (Ах, эти строки (JPoint 2020, 29.06.2020)), тоже посвященный внутренностям строк и каким-то перформанс-тонкостями, с этим связанными. Там вы можете услышать всю теоретическую часть и все объяснения, почему сделано так, а не иначе.
Коротко хотелось бы посмотреть на родственников строк – boxed primitives. Они тоже иммутабельные, и для них также существует проблема дедупликации. Вопрос “сколько разных объектов создастся при выполнении такого кода?” можно задавать студентам для проверки того, насколько хорошо они уяснили материал, но я думаю, что у опытного Java-разработчика здесь вопросов быть не должно:
new Integer[]{ 42, 42, Integer.valueOf(42), new Integer(42), -4242, -4242 }
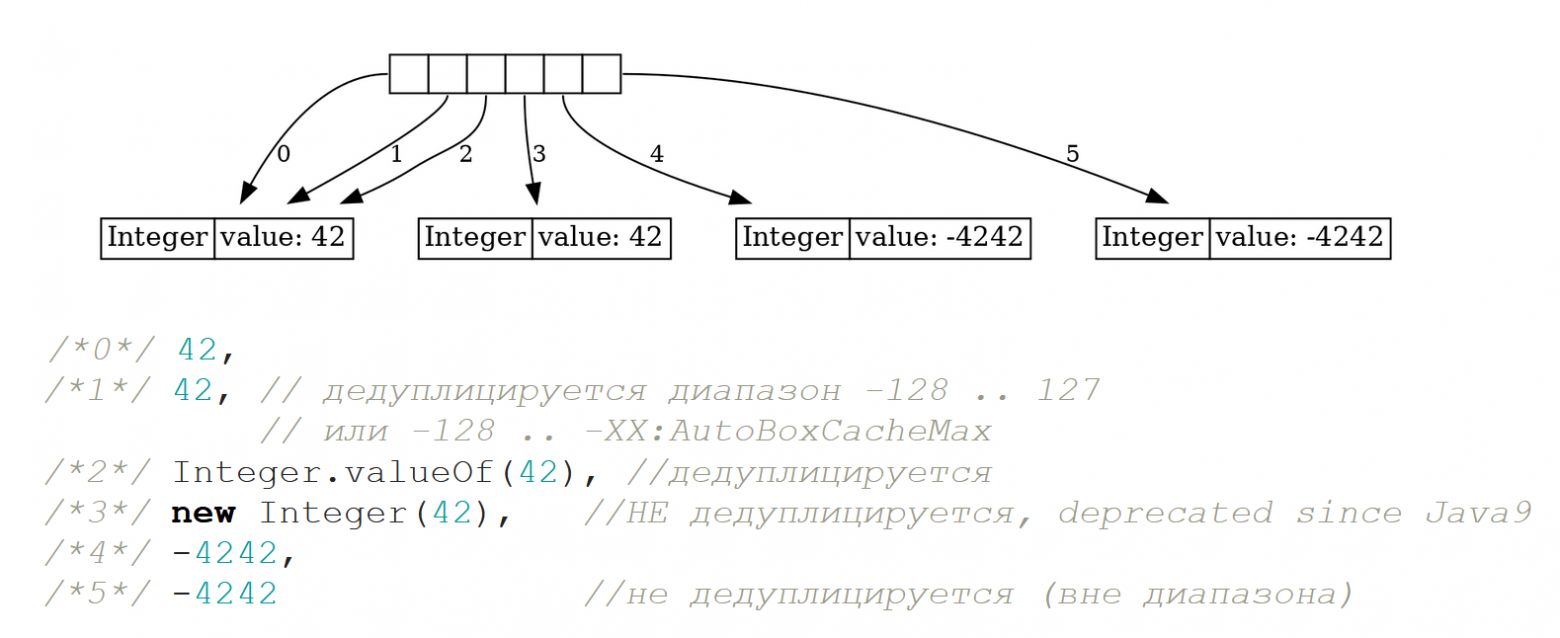
Оператор new, конечно же, всегда порождает новый объект. Особого смысла это не имеет, потому что у нас есть механизм дедупликации, и начиная с Java 9 все конструкторы new Integer(..), new Character(..) и т. п. помечены как @Deprecated. Вместо этого надо использовать – если, конечно, не получается использовать автобоксинг – статический метод valueOf, имеющийся у всех примитивов. Этот метод дедуплицирует объекты в диапазоне от -128 до 127.
Глядя на эту картинку, мы можем сделать следующие выводы:
- О дедупликации boxed primitives следует помнить, в частности, создавая их через метод
valueOf, а не конструкторами. - При наличии показаний со стороны перформанс-анализа можно воспользоваться специальными библиотеками коллекций, которые работают напрямую с примитивами, не боксируя их (например, fastutil).
- Мы все ждем проект Valhalla в той его части, которая связана с generic specialization, когда мы сможем наконец написать
new ArrayList<int>()и забыть про проблемы боксинга. Но, кажется, это произойдет еще не очень скоро.
Списки и очереди
Давайте теперь посмотрим что-то более интересное и сложное – на одномерные, линейные структуры данных, к которым относятся списки и очереди.
LinkedList
На любом курсе по алгоритмам и структурам данных изучается связный список. В Java он реализован в виде класса LinkedList.
Подготовим LJV для того, чтобы он красиво нарисовал LinkedList:
LJV ljv = new LJV().setDirection(Direction.LR) .addFieldAttribute("last", "constraint=false") .addFieldAttribute("prev", "constraint=false") .setTreatAsPrimitive(Integer.class);
Затем возьмём LinkedList, положим туда элементы и получим вот такую картинку:
List<Integer> list = new LinkedList<>(); list.add(1); list.add(2); list.add(3); list.add(4); visualize(ljv, list);

Действительно, это связный список, который теоретически обладает рядом полезных свойств. Например, в ситуации, когда мы не знаем заранее размера списка, мы его легко, со скоростью  можем увеличить, а также мы можем быстро, со скоростью в середину вставлять и из середины вынимать элементы.
можем увеличить, а также мы можем быстро, со скоростью в середину вставлять и из середины вынимать элементы.
Теоретических преимуществ у этой структуры данных много, но на практике в Java всё обстоит не так. Я люблю показывать своим студентам этот твит Джошуа Блоха:

В жизни Java-разработчиков LinkedList не пригождается. Дело в том, что в стандартной библиотеке есть структуры данных, более эффективные, чем LinkedList для любого его применения.
ArrayDeque
Для начала рассмотрим очередь. Кажется, что LinkedList хорош тем, что мы, можем добавлять в него элементы с одной стороны, а с другой стороны – “подъедать”. Но недостатки LinkedList тоже понятны: у него большой overhead по памяти. Ведь каждая из нод связного списка, на самом деле, есть лишний объект, который в себе несёт ссылку еще на какой-то объект. В нашем случае используется Integer, который мы на нашей диаграмме показываем как примитив только чтобы не усложнять диаграмму.
Мы можем столкнуться с фрагментацией памяти: как ноды, так и связанные с ними объекты могут быть “разбросаны” по памяти, и при проходе по LinkedList мы не сможем получить преимущества процессорного кэша. Эта проблема отсутствует в реализациях списка, основанных на массивах, например, ArrayList. Но ArrayList – это совсем тривиальная структура данных, это я даже не буду показывать.
А вот как может быть устроена очередь, основанная на массиве? Чтобы понять, как она работает, мы используем метод highlightChangingArrayElements() в LJV, который нам подсветит желтым меняющееся состояние в массиве.
LJV ljv = new LJV() .setTreatAsPrimitive(Integer.class) .highlightChangingArrayElements(); Deque<Integer> arrayDeque = new ArrayDeque<>(4); arrayDeque.add(1); arrayDeque.add(2); arrayDeque.add(3); visualize(ljv, arrayDeque);
ArrayDeque по своему внутреннему устройству похож на ArrayList, String, и множество других Java-классов, поскольку это всего-навсего лишь массив, которому приделан заголовочный объект. В этом объекте хранятся два индекса-указателя: на “голову” и на “хвост”. Вот мы положили туда три элемента:
//note that this sets initial capacity to 5! Deque<Integer> arrayDeque = new ArrayDeque<>(4); arrayDeque.add(1); arrayDeque.add(2); arrayDeque.add(3); visualize(ljv, arrayDeque);

Вот мы вычитали первые два, и мы видим, что они заменились null-ами с начала, а тройка никуда не переместилась.
arrayDeque.poll(); //returns 1 arrayDeque.poll(); //returns 2
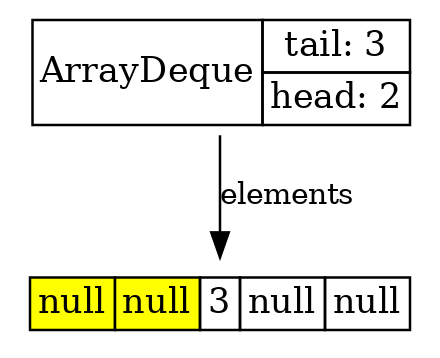
Потом мы добавили еще три элемента, дошли до конца буфера. Но в начале буфера у нас есть свободное пространство, поэтому закольцевались и пишем с начала.
arrayDeque.add(4); arrayDeque.add(5); arrayDeque.add(6); visualize(ljv, arrayDeque);
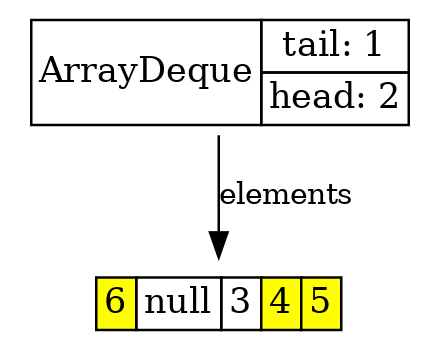
И так далее. То есть получается у нас закольцованный буфер, и если мы примерно с одинаковой скоростью пишем и читаем, и буфер нам не надо изменять в размерах, то ясно, что это будет работать очень эффективно и гораздо эффективней, чем LinkedList.
PriorityQueue
Другой очень интересный класс – это PriorityQueue, т. е. очередь с приоритетами.
Если бы мы спросили себя: “как бы мы реализовали очередь с приоритетами?”, ничего об этом заранее не зная, то кажется, первое, что пришло бы на ум, это связный список. Мы его отсортируем. Потом, когда нам надо будет вынимать, мы будем вынимать всегда из головы за время , а когда надо будет вставлять, мы будем вставлять куда-то в серединку, так, чтобы новое значение всегда ставилось на место сортировки, т. е. вставка имела бы сложность  .
.
Но на самом деле есть решение иное, без применения связного списка.
Давайте возьмём и случайным образом перетасуем массив значений от 0 до 15:
List<Integer> list = IntStream.range(0, 16) .boxed() .collect(Collectors.toList()); Collections.shuffle(list); visualize(new LJV().setTreatAsPrimitive(Integer.class), list.toArray());

Потом положим их в PriorityQueue и визуализируем. Получается картинка, очень похожая на ArrayList или ArrayDeque:
LJV ljv = new LJV().setTreatAsPrimitive(Integer.class) .setIgnoreNullValuedFields(true) .highlightChangingArrayElements(); PriorityQueue<Integer> q = new PriorityQueue<>(16); q.addAll(list); visualize(ljv, q);
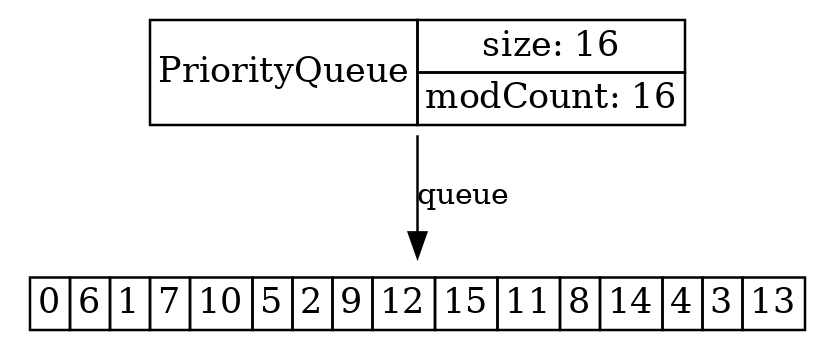
Массив значений выглядит так, словно он не до конца отсортирован. Есть маленькие значения в левой части: 0, 1, 6. Но и в правой части тоже есть маленькие – например, 3, 4.
Как же это работает? Фокус здесь в том, что применяется так называемая структура binary min-heap, в которой предполагается, что каждый элемент удовлетворяет вот такому инварианту:
![$q[n] \leq q[2n+1]$](https://habrastorage.org/getpro/habr/formulas/1ce/3a1/0ab/1ce3a10ab48d4190de5214395168f70e.svg)
![$q[n] \leq q[2n+2]$](https://habrastorage.org/getpro/habr/formulas/ea3/272/f68/ea3272f68f771d7f37be560a6ea6c788.svg)
Нулевой элемент массива меньше следующих за ним двух, то есть 0 меньше 6 и 1. В свою очередь, 6 меньше 7 и 10, 1 меньше 5 и 2 и так далее.
Следствие – в голове у нас всегда минимальный элемент.
Другое следствие – что мы можем вынимать и вставлять в такую структуру данные за время  .
.
q.poll();
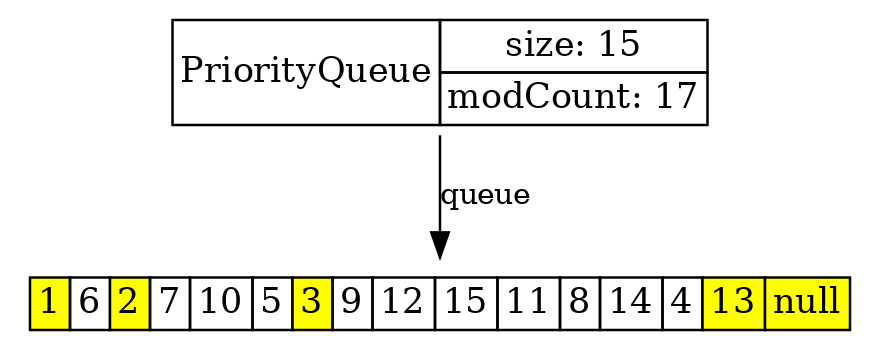
Если мы вынули первый элемент из PriorityQueue, то ясно, что на его место должен встать минимальный из 6 и 1, то есть 1. А на место 1 должен был встать минимальный из тех двух, которые являются его потомками, а потом – тех двух, которые являются потомками вынутого далее элемента.
Понятно, что при этом “дырка”, т. е. блок не подлежащих перемещению элементов, каждый раз удваивается, и мы за логарифмическое время передвинем все элементы, потому что мы логарифмически малую долю элементов двигаем.
Вот мы можем вынуть пару элементов и посмотреть, как это происходит:
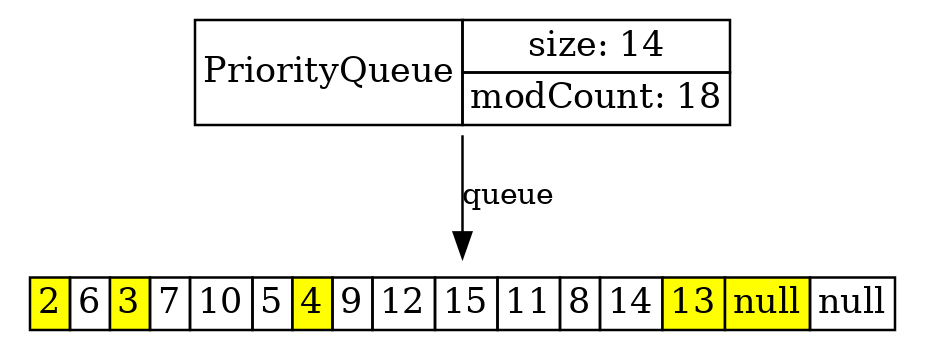

Можем вставить какой-то элемент. И мы видим, что всякий раз перемещается только очень маленькое подмножество элементов, и за счет этого PriorityQueue работает быстро.
q.add(1);

ConcurrentLinkedQueue и ConcurrentLinkedDeque
Все вещи, которые я показывал до сих пор, не потокобезопасны. Если мы хотим использовать их в многопоточной программе, мы должны либо их синхронизировать полностью, либо, если мы хотим что-то более эффективное, если мы не хотим устраивать lock contention, нам нужно использовать lock-free структуры.
И такие структуры в Java есть. Первая называется ConcurrentLinkedQueue, а вторая – ConcurrentLinkedDeque. Если мы эти структуры визуализируем, то мы увидим старые добрые связные списки, односвязный и двусвязный:


То есть в данном случае идея cвязного списка как структуры данных никуда не делась, она здесь работает, позволяя реализовывать lock-free алгоритмы.
Конечно, сложность этих двух классов не в их внутренней структуре, а в алгоритмике, которая, увы, никак не визуализируется при помощи LJV. Но, во всяком случае, мы можем видеть, что идея связного списка никуда не девается.
Итак, промежуточные выводы по этой части.
- Класс
LinkedListне нужен Java-разработчику, сценариев использования для него нет. Зато есть многие другие, более эффективные, чемLinkedList, в каждом конкретном случае. - Не стоит недооценивать массив как основу для построения эффективных структур данных. Кажется, что массив – штука примитивная, но на самом деле можно реализовать очень мощные вещи, просто используя массив как таковой.
- Если нужна потокобезопасность и, вдобавок, неблокирующее поведение, идея связного списка снова начинает работать уже на другом уровне, в структурах данных, более сложных алгоритмически.
Реализации интерфейса Map
HashMap
Следующая часть посвящена мапам. В первую очередь рассмотрим HashMap. Наверное, я не очень ошибусь, если скажу, что троица классов String, ArrayList и HashMap удовлетворяют 95% потребностей Java-разработчика. И конечно, Java-профессионалы знают, как HashMap устроен. Давайте возьмём LJV, подготовим его определенным образом, запустим и посмотрим.
LJV ljv = new LJV() .setIgnoreNullValuedFields(true) .setTreatAsPrimitive(Integer.class) .setTreatAsPrimitive(String.class); Map<String, Integer> map = new HashMap<>(); map.put("one", 1); map.put("two", 2); map.put("three", 3); map.put("four", 4); visualize(ljv, map);
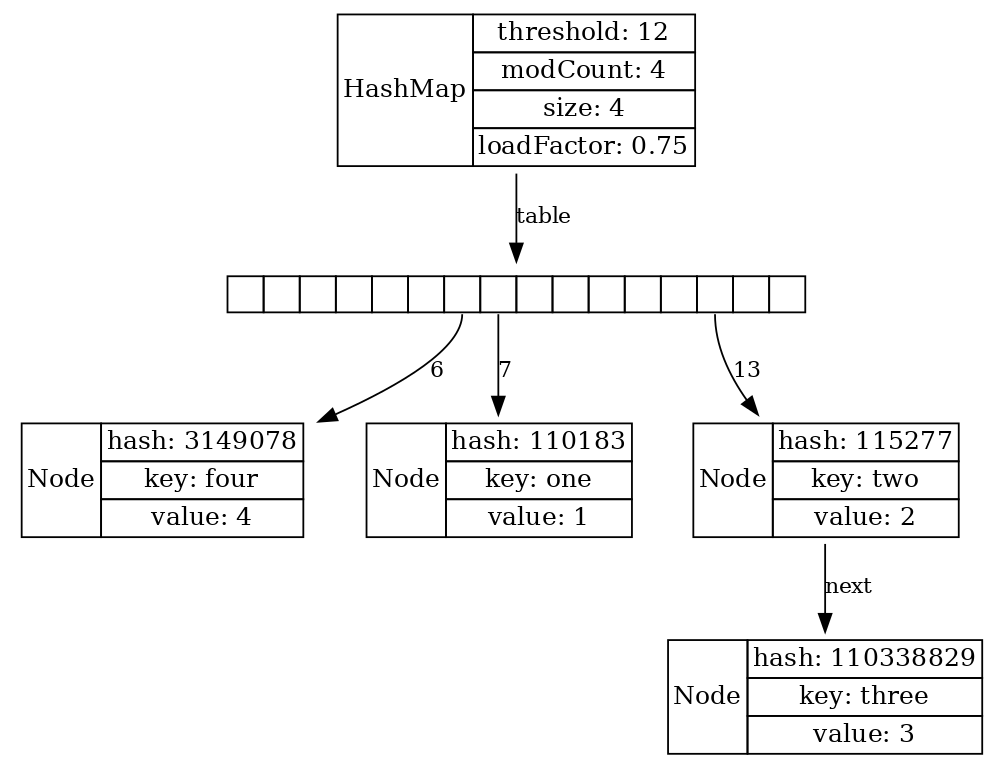
Именно ради этой самой картинки, чтобы показать ее студентам, я в свое время LJV и отыскал.
У нас имеется массив bucket-ов. Мы вычисляем хэш от ключа, определяем, в какую ячейку массива положить новую пару “ключ-значение”. У нас может возникнуть ситуация коллизии, когда разные ноды попадают в один bucket, и ситуацию с коллизией можно теоретически разными способами разруливать.
Конкретно для HashMap разработчики Java выбрали метод chaining. То есть возникает маленький связный список: например, если вышло так, что ключ “three” попал в 13-ю ячейку, где уже лежит ключ “two”, то он “цепляется” к уже существующей записи с помощью связного списка. Во время поиска при разрешении конфликта происходит поиск перебором по списку, но это поиск короткий. Поэтому, вроде бы, всё в порядке и хэш-мапа работает быстро.
Давайте подготовим более серьезно наш LJV и попробуем устроить более длинные коллизии. Как мы знаем, хэш строки не является криптографическим, строки довольно легко подделать под задуманный хэш, поэтому достаточно просто написать класс, генерирующий очень много строчек с одинаковым хэшем.
LJV ljv = new LJV() .setIgnoreNullValuedFields(true) .setTreatAsPrimitive(Integer.class) .setTreatAsPrimitive(String.class) .addIgnoreField("value") .addFieldAttribute("prev", "constraint=false,color=green") .addFieldAttribute("next", "constraint=false,color=green") .addObjectAttributesProvider(Main::redBlackForHM); /*redBlackForHM: red ? "color=red" : "color=black";*/ List<String> collisions = new HashCodeCollision().genCollisionString(7); Map<String, Integer> map = new HashMap<>(); for (int i = 0; i < len; i++) { map.put(collisions.get(i), i); } visualize(ljv, map);
Начнём вставлять коллизии в HashMap и посмотрим на пример, когда имеется 6 коллизий. Мы видим, что вся наша HashMap вырождается в связный список!

Этим свойством HashMap могут воспользоваться злоумышленники – например, если вы храните в HashMap список идентификаторов активных пользовательских сессий, и у вас старая версия Java, то вы очень легко, сгенерировав много идентификаторов так, чтобы у них был один и тот же хеш, превратите вашу HashMap в связный список с линейным поиском и устроите DoS-атаку на сервер.
Обратите внимание, что здесь количество bucket-ов вообще никак не спасает ситуацию. Проблема такой коллизии не в том, что ключи попадают в один и тот же бакет случайно: у них у всех хэш одинаковый, поэтому, сколько бакетов не добавляй, они непременно попадут в один и тот же бакет, и map превращается в связный список.
Такая беда могла произойти вплоть до Java 7, но в Java 8 ситуацию исправили. Поэтому, если мы возьмем свежую версию Java и накидаем туда много коллизий в одну и ту же hash-таблицу, мы увидим вот такую картинку:
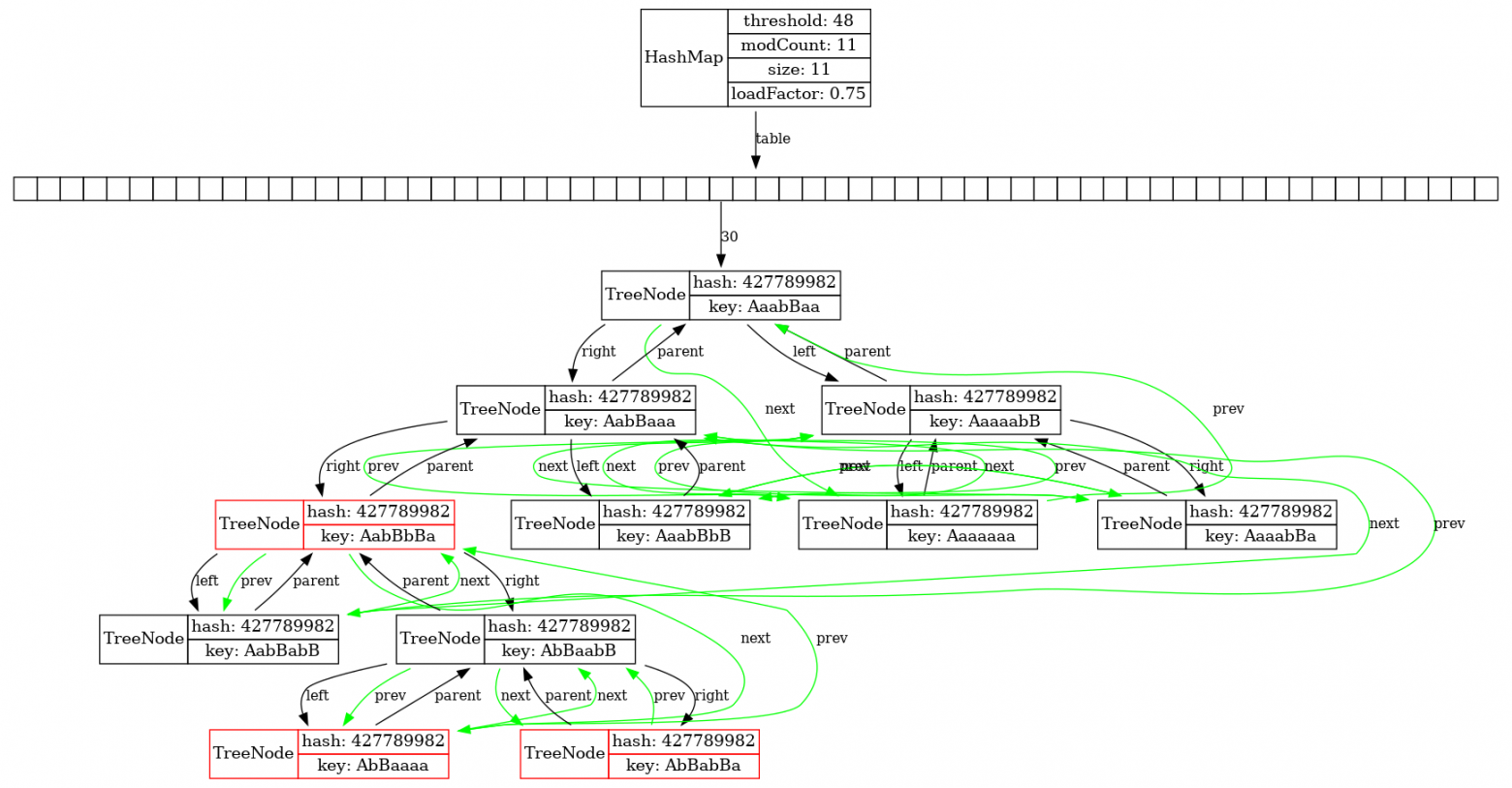
В исходниках hashmap это по-английски называется treeification, на русский я бы это перевёл как “одеревенение”. Как только длина связного списка переходит через определенный порог, у нас происходит превращение связного списка в дерево. Заметим, что некоторые ноды покрашены красным, из чего мы делаем вывод, что это красно-черное дерево, но LJV об этом не просто так догадался: обратите внимание на то, что мы передали ему AttributesProvider в виде ссылки на метод Main::redBlackForHM, который по значению определённого поля объекта выбирает для него DOT-атрибут, в данном случае это color=red.
Заметим ещё, что ноды этого дерева “прошиты” зелёными ссылками вперед и назад, с помощью полей prev и next.
Что же произошло? Если коллизий становится слишком много, чтобы все-таки не делать линейный поиск по связному списку, список превращается в красно-черное дерево поиска. Вообще говоря, для дерева поиска нужно, чтобы ключи были сравнимы не только по “равно”, но и по “больше/меньше”. Таким образом, если для ключей реализован интерфейс Comparable, то он и будет использован для того, чтобы строить это бинарное дерево поиска. Если же Сomparable не присутствует, то Java использует identity hash code объектов для того, чтобы разрулить неоднозначность, чтобы определить, какой из объектов меньше какого.
Мы видим, что здесь очень большой overhead по памяти. Например, много места занимает “лапша” из зелёных ссылок. Она нужна для двух вещей: во-первых, для совместимости с LinkedHashMap, о котором я вкратце расскажу, а во-вторых, за счет этого достигается быстрый обход элементов внутри бакета, потому что мы не пользуемся обходом по дереву (где потребовалось бы рекурсивно возвращаться на родительские элементы), а можем напрямую обходить его по-прежнему вперед по ссылкам next. А ссылки prev нам нужны для того, чтобы удалять элементы из этого дерева, и у нас при этом не нарушался бы связный список (у односвязного списка, понятное дело, трудно с удалением элементов из середины). Впрочем, такая неэффективность допустима, ведь “одеревенение” – не штатный режим работы HashMap.
LinkedHashMap
Давайте посмотрим визуализацию только что упомянутого LinkedHashMap. Это HashMap, все элементы которого прошиты ссылками before и after, то есть это двусвязный список, наложенный поверх HashMap.
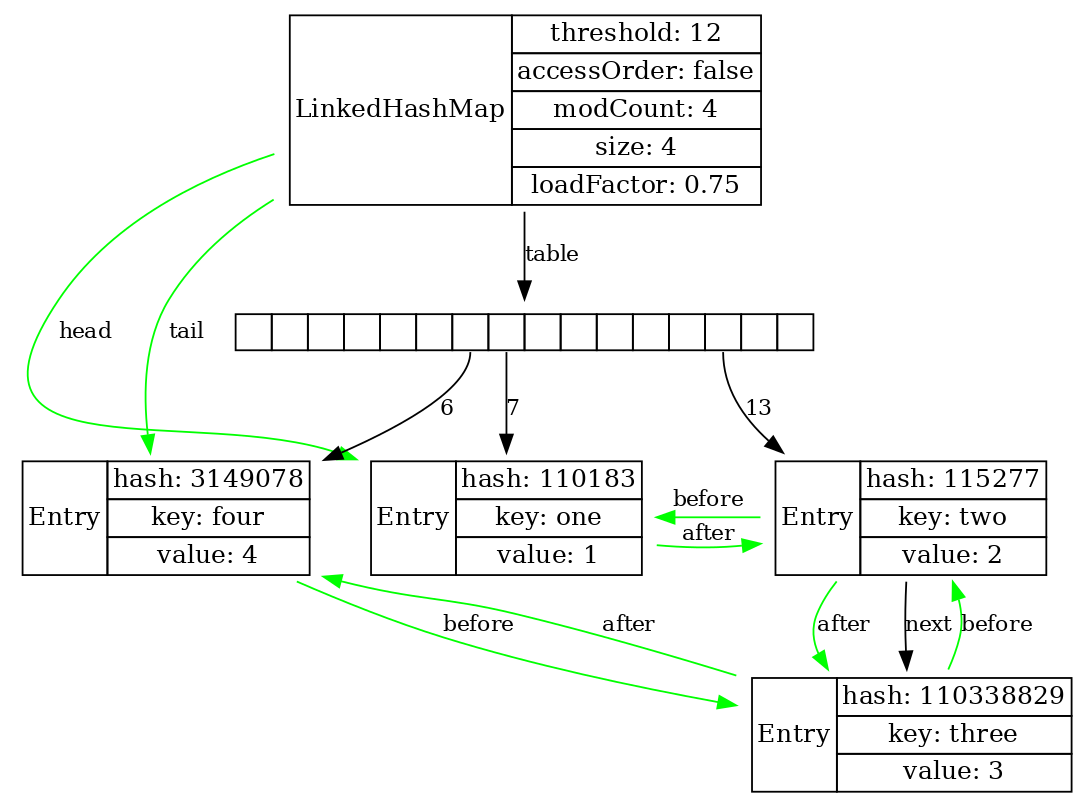
Помимо случаев, когда нам надо сохранить правильный порядок перебора элементов внутри мапы, HashMap может работать как LRU-кэш (т. е. least recently used cache).
Если создать LinkedHashMap с параметром accessOrder=true, то тогда порядок элементов в этом связном списке будет меняться по мере извлечения элементов из мапы.
Map<String, Integer> map = new LinkedHashMap<>(5, 0.8f, /*accessOrder:*/ true); map.put("one", 1); map.put("two", 2); map.put("three", 3); map.put("four", 4);

map.get("two");

Такое поведение даёт возможность, например, удалять из кэша те элементы, которые мы дольше всего не читали. Те элементы, которые были прочитаны недавно, всегда будут в голове списка, их удалять не надо. Получается, что LinkedHashMap – это отличная заготовка для тех, кому нужен LRU кэш.
Мы сейчас рассмотрели старые классы, о которых более-менее все знают. Я думаю, что большинству Java-разработчиков устройство HashMap знакомо, и вообще, “как устроены HashMap и что изменилось после Java 8?” – это один из довольно расхожих вопросов на собеседованиях.
MapN
Недавно в Java появилась еще одна вещь, которую, возможно, ещё знают не все. Пользователи Java 11 заметили удобные конструкции List.of(..) и Map.of(...) для конструирования иммутабельных мап и списков. Но если кто-то думает, что эти, довольно удобные сами по себе, методы генерируют обычный HashMap, то ничего подобного! Конструируется вот такое:
ljv = new LJV().setIgnoreNullValuedFields(true); Map.of(1, 'A', 2, 'B', 3, 'C', 4, 'D'));

Мы видим, что это ещё одна имплементация интерфейса Map, которая называется MapN, и выглядит она довольно интересно. В основе MapN лежит массив Object[], причем, все нечетные поля занимают ключи, а все четные занимают значения. Благодаря этому, у нас меньше перерасход памяти и отсутствует фрагментация.
Самое главное, что для разрешения коллизий у такой мапы используется не chaining-подход, а метод открытой адресации, также известный как linear probing. Если мы положим в наш MapN строчки с одинаковым hash значением, то она будет вести себя следующим образом:
Map.of("aaa", 1, "abB", 2, "bBa", 3)
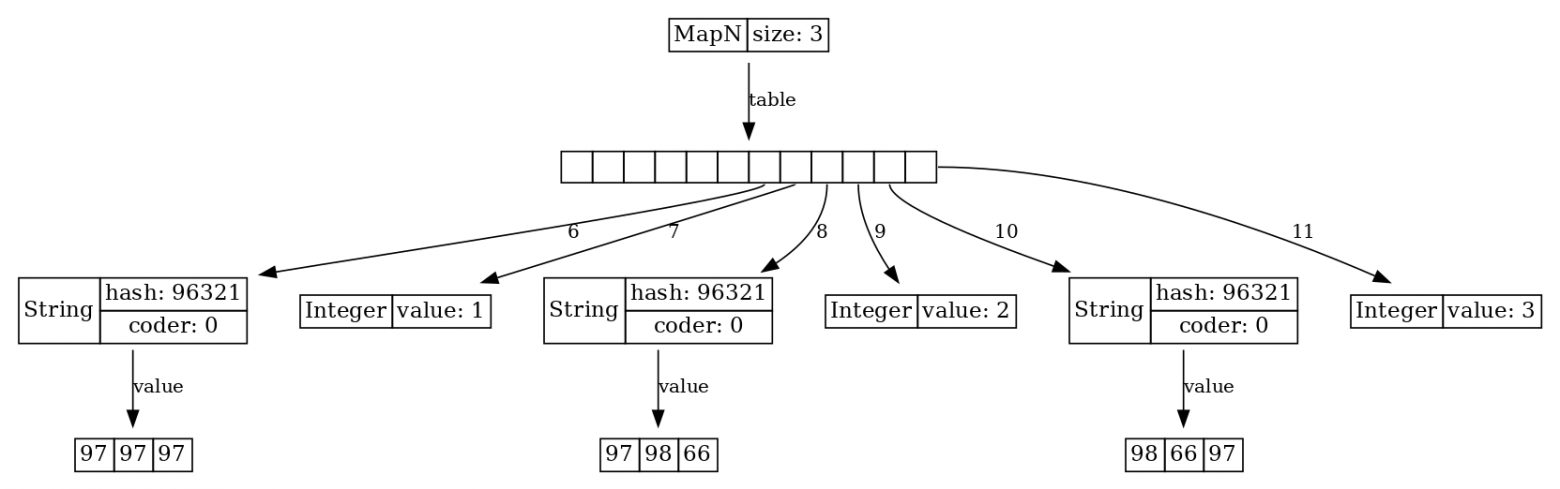
Мы нашли нужное место в массиве, вставили строчку "aaa". Потом вставляем "abB" с тем же хэшем, но место уже занято. Тогда мы идем вправо, пока не найдем свободное место, и вставляем туда. В следующий раз – идем еще дальше вправо, и так далее. Поиск нужного ключа происходит подобным же образом: ищем начиная с позиции, соответствующей хешу ключа, и идём вправо пока не найдём подходящий элемент или не упрёмся в пустой bucket.
У linear probing имеется ряд проблем. Во-первых, размер массива бакетов должен быть достаточно большим, чтобы занятые бакеты не “слепились” в большой блок и поиск не превратился в последовательный перебор. Во-вторых, имеется проблема с удалением. Нельзя просто взять и удалить элемент, потому что мы можем создать “дырку” из пустого элемента в массиве и нарушить поиск в linear probing, поэтому приходится что-то с этим делать. Однако особенность иммутабельной мапы как раз в том, что удалять ничего и не надо! Изменять размер её массива в случае переполнения тоже не надо. С момента выбора достаточного размера массива в самом начале больше меняться ничего не будет. Конечно же, такая мапа с точки зрения производительности работает гораздо лучше, и у нее гораздо меньше overhead по памяти. У нее нет проблемы с фрагментацией памяти, потому что все её данные лежат рядом, не то что у HashMap.
ConcurrentHashMap
Теперь давайте посмотрим на ConcurrentHashMap. Этот класс нам нужен, если нам нужна такая же мапа, как HashMap, но только потокобезопасная. Класс ConcurrentHashMap имеется в стандартной библиотеке давно, и он подвергался некоторым изменениям. Поэтому, если на собеседовании спросят, как устроен ConcurrentHashMap, то уместно уточнить: «В какой версии?» В версиях, предшествовавших Java 8, была другая реализация, и в известной книге «Java Concurrency in practice» подробно объясняется именно старая реализация. По сути дела, ConcurrentHashMap раньше представлял собой разбитую на сегменты HashMap. По умолчанию их вообще 16, но здесь я принудительно задал их количество 8, просто чтобы лучше уместить все на один слайд:
Map<String, Integer> map = new ConcurrentHashMap<String, Integer>( /*initialCapacity:*/16 , /*loadFactor:*/0.75f, /*concurrencyLevel:*/8); map.put("one", 1); map.put("two", 2); map.put("three", 3); map.put("four", 4); map.put("five", 5); visualize(map);
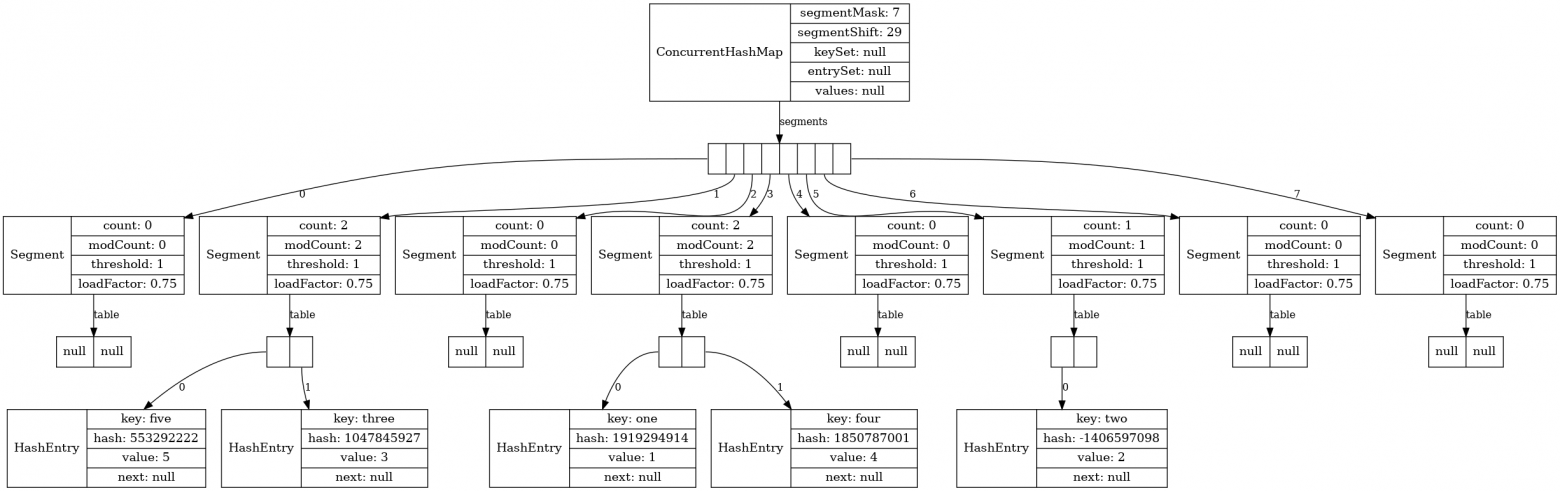
Сначала по хэш-коду ключа определяется то, с каким сегментом мы работаем. Далее этот сегмент мы блокируем, синхронизируемся по нему и работаем с ним, независимо от остальных.
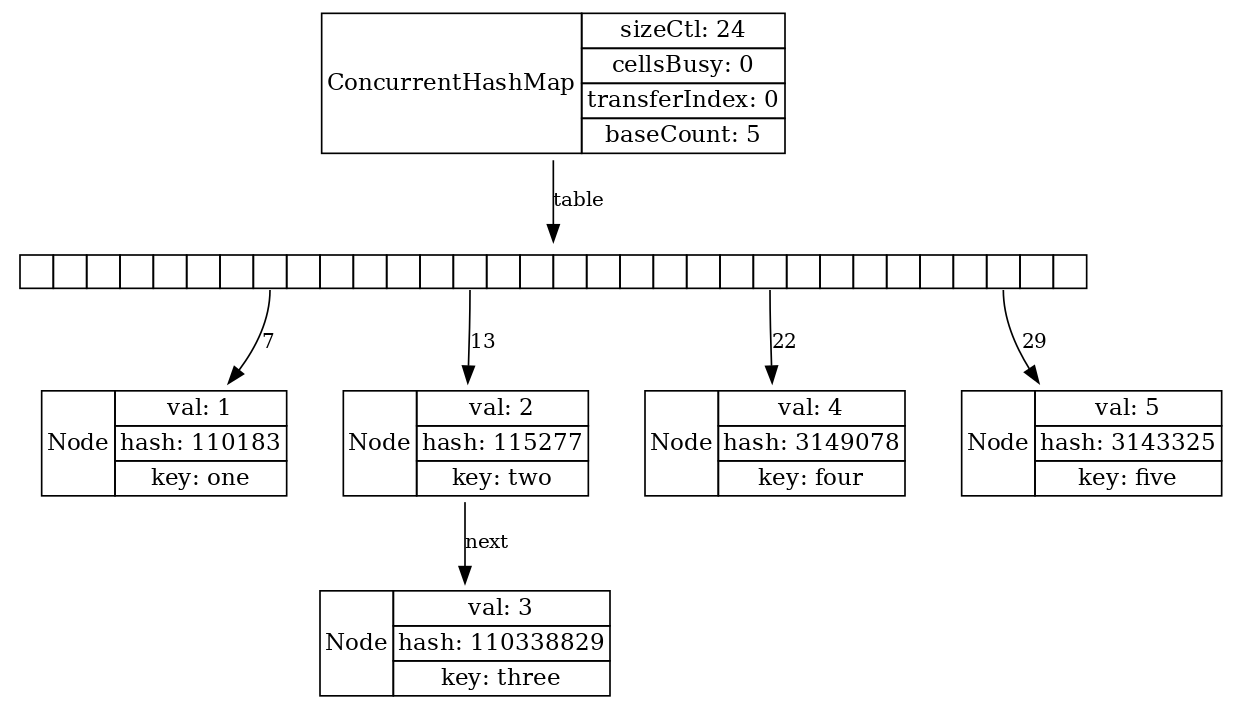
Эта история поменялась в Java 8, поэтому глава книги «Java Concurrency in practice», посвящённая ConcurrentHashMap, уже устарела. Нынешний ConcurrentHashMap с точки зрения визуализации выглядит уже как самый обычный НashMap. Но естественно, у него другой алгоритм работы.
Для заполнения элемента массива бакетов используются CAS-операции, а дальше, в случае коллизии, синхронизация уже происходит по всей цепочке нод, привязанной к конкретному бакету. Легко видеть, что здесь гораздо меньше overhead по памяти, структурно все проще, lock contention встречается реже, стало работать лучше.
Промежуточные выводы.
- В Java 8 произошёл существенный апгрейд
HashMapиConcurrentHashMap. - В Java 9 появились еще и иммутабельные хэшмапы
MapNс открытой адресацией и улучшенным быстродействием. ПоэтомуMap.of(..)– это не просто “синтаксический сахар”, это штука, которая даёт ещё и прирост по производительности. - Не забываем и про
LinkedHashMap, который может нам послужить в качестве LRU кэша.
Реализации интерфейса NavigableMap
TreeMap
Map как интерфейс хорош, когда нам по ключу необходимо быстро получить значение. Но часто бывает так, что в точности ключ не известен, и мы хотим найти в некотором смысле ближайшее к заданному ключу значение. Или же мы знаем диапазон ключей, и мы хотим извлечь все ключи в этом диапазоне.
Для таких задач имеется интерфейс NavigableMap, и стандартная непотокобезопасная имплементация NavigableMap в Java – это TreeMap, которая из себя представляет красно-черное дерево. Если мы подготовим LJV для того, чтобы он распознавал цвета нод, и визуализируем таким образом TreeMap, то мы получим вот такую картинку:
LJV ljv = new LJV() .setTreatAsPrimitive(Integer.class) .setTreatAsPrimitive(String.class) .setIgnoreNullValuedFields(true) .addIgnoreField("color") .addObjectAttributesProvider(Main::redBlack); //color ? black : red Map<String, Integer> map = new TreeMap<>(); map.put("one", 1); map.put("two", 2); map.put("three", 3); map.put("four", 4); map.put("five", 3); map.put("six", 4); visualize(ljv, map);
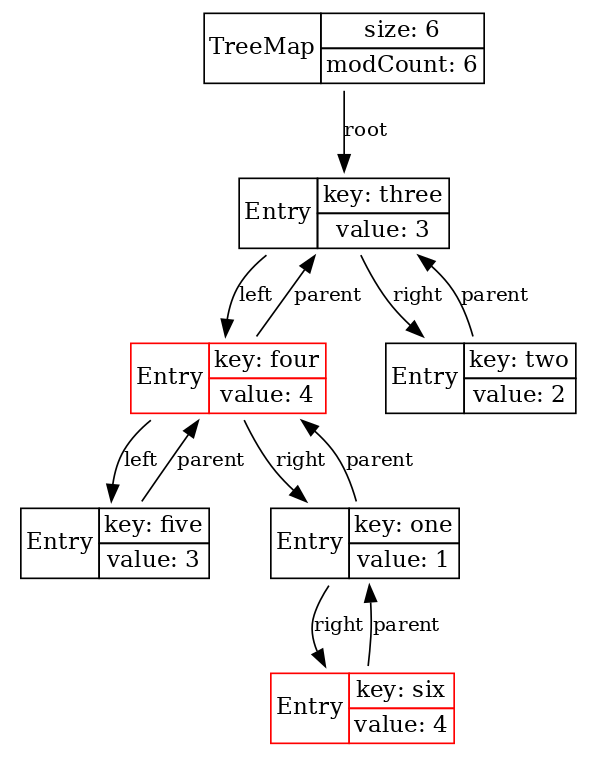
Действительно, это дерево, и действительно какие-то ноды красные, какие-то – черные.
Как это работает? Алгоритм здесь уже достаточно сложный, чтобы объяснить его в деталях, нужна целая отдельная лекция. Сейчас получится только пройтись по основным идеям.
Как мы видим, в основе этой структуры лежит бинарное дерево поиска. Если это дерево хорошо сбалансировано, т. е. все его ветви примерно одинаковой длины, то для поиска нужного элемента необходимо будет, двигаясь от корня, проходить небольшое, , количество “развилок”.
В чём проблема у дерева поиска? Если не предпринимать специальных действий, то вставка элементов в эту структуру может привести к ситуации, когда большинство элементов будут лежать в очень длинных ветвях. Например, если вставлять уже отсортированные данные, то будет всегда выбираться одно и то же плечо дерева, и в итоге вместо дерева у нас получится связный список с линейным временем поиска. (Опять связный список! Сколько раз он уже был упомянут, и это ещё не последний раз!) Значит, вставка и удаление в дереве поиска должны сопровождаться его перестроением, балансировкой.
Идея балансировки красно-чёрного дерева, как в случае с очередью с приоритетами, основана на сохранении инвариантов. Имеются определенные условия, инварианты, которые мы обязаны сохранять на каждом шаге изменения дерева. Вот они:
- Корень дерева — чёрный.
null—«листья» в конце ветвей считаются чёрными.- Оба потомка каждого красного узла — чёрные.
- Любой простой путь от узла-предка до листового узла-потомка содержит одинаковое число чёрных узлов.
Из этих условий (посмотрите внимательно на последние два) следует, что путь от корня до конца потенциально самой длинной ветки – он будет состоять из чередующихся ЧКЧК-узлов – будет не более чем вдвое длиннее пути от корня до конца потенциально самой короткой ветки, состоящей только из чёрных узлов. Таким образом, красно-чёрное дерево будет всегда – пусть не идеально, но достаточно хорошо – сбалансировано. Цена сохранения инварианта – всегда логарифмическое время.
За неимением времени я не буду рассказывать про алгоритмы, выполняющие данные инварианты, просто давайте посмотрим на визуализацию, как это происходит:

ConcurrentSkipListMap
Вопрос: если мы хотим то же самое, тот же интерфейс NavigableMap, но thread-safe?
Как вы помните, у нас имеется эффективно работающий ArrayDeque на основе массива, но когда мы захотели сделать потокобезопасную реализацию Deque, то нам пришлось выбрать другую структуру.
В случае с NavigableMap решение в стандартной библиотеке тоже есть, оно называется ConcurrentSkipListMap. Если исходный код этого класса открыть, то можно увидеть очень много сложного кода и много комментариев. Почитав эти комментарии, я обнаружил в них ссылки на две научные статьи, одну монографию и три докторских диссертации. Это, наверное, один из самых сложных и наукоёмких классов в Java-библиотеке, но мы просто посмотрим на него снаружи, не вникая в алгоритмы того, как он работает.
Для начала вспомним, что такое skip list map в принципе.
Это, как ни удивительно, все тот же связный список, в котором мы решили облегчить себе поиск нужного элемента путём “наслоения” дополнительных связных списков. Все значения в этой структуре данных отсортированы.

Допустим, нам нужен элемент H. Сначала мы перебираем самый верхний, короткий список и понимаем, что нам нужен диапазон от D до I. Спускаемся на уровень ниже по ссылке down, перебираем сегмент следующего списка и сужаем интересующий нас диапазон от F до I. Наконец, спускаемся на самый нижний уровень, и нам остаётся уже совсем чуть-чуть перебрать значений. В сумме, при правильно сбалансированной структуре, поиск будет выполняться за логарифмическое время.
Понятно, что с точки зрения затрат памяти это гораздо менее эффективная структура, чем бинарное дерево. Но для того, чтобы создать lock-free структуру, это как раз то, что нужно. Именно на ней lock-free алгоритмы работают.
Еще одно замечательное ухищрение, которое здесь используется, заключается в следующем. Когда мы добавляем элементы, нам надо в какой-то момент принимать решение о том, что соответствующий сегмент списка сделался слишком длинным и пора вставлять индексы, т. е. элементы в списках верхнего уровня. Фокус в том, что мы можем принимать такое решение на основании датчиков случайных чисел. Не пытаясь подсчитать количество элементов, независимо от других потоков, которые что-то параллельно делают, просто на основании датчика случайных чисел мы можем автономно принимать решение, когда вставлять индекс. Тогда законы статистики будет работать на нас и в целом наша структура получится примерно сбалансированной: хотя “перекосы” и возможны, но просто вероятность их возникновения будет мала.
Поэтому, когда мы визуализируем ConcurrentSkipListMap, у нас каждый раз получаются разные картинки – иногда красивые, иногда не очень. Если вы сами будете использовать LJV для визуализации ConcurrentSkipListMap, вы увидите, что на одних и тех же данных он всякий раз по-разному будет выглядеть.

Какие выводы по этой части можно сделать?
- Продвинутые алгоритмы творят чудеса. Действительно, в области алгоритмов и структур данных уже придумано и реализовано много эффективных решений для очень нетривиальных задач.
- Стандартная библиотека Java к нашим услугам с хорошо реализованными классами
TreeMapиConcurrentSkipListMap. - Под конец нашего доклада мы вступили на почву, где простой визуализации недостаточно. Хотя мы видим, как выглядит
ConcurrentSkipListMapс точки зрения распределения объектов памяти и их связи между ними, мы никак не понимаем той алгоритмической сложности, которая содержится в методахConcurrentSkipListMap.
На этом у меня всё. Заходите на проект https://github.com/atp-mipt/ljv, ставьте звёздочки.
Спасибо Джону Хеймеру, который в свое время этот проект придумал. Я с ним связался, он сейчас не в Новой Зеландии, он профессор в Шотландии, до сих пор преподает Computer Science, и очень был рад, что эта штука до сих пор актуальна и кому-то пригождается.
Спасибо Тагиру Валееву, который ревьюил этот доклад и предложил для него несколько идей.
Экспериментируйте с LJV, присылайте свои идеи насчёт того, что ещё было бы интересно визуализировать.
Весь этот доклад находится на GitHub, презентация как код. И весь код, который здесь показан, присутствует в этом же проекте.
И в заключение – несколько слов от программного комитета конференции SnowOne:
В этом году SnowOne пройдет в офлайне, 25-26 февраля в Новосибирске. Для тех, кто не сможет — есть онлайн-трансляция. Кроме того, будет отдельный студенческий день. Значительная часть программы уже опубликована на сайте, можно поглядеть (и там же купить билет). Приезжайте в Новосибирск или подключайтесь онлайн — и там, и там будет круто!

