Привет, Хабр! Я Дмитрий Клепиков из команды Modus.
После прошлой статьи захотелось взять тот же стек — ИИ-агента и пару MCP-серверов — и собрать через него в нашем BI-портале DQ-шаблон. DQ здесь — это Data Quality, то есть проверка качества данных: полнота, корректность, уникальность, согласованность, актуальность и всё то, из чего потом складывается доверие к данным.
Шаблон получился не универсальным в духе «подставь любую таблицу, и всё само поймётся». Скорее универсальным оказался каркас: одни и те же этапы, одна таблица результатов, один набор отчётов, история запусков и каталог правил. А вот сами правила остаются доменными. В адресном реестре это КЛАДР, ФИАС, ГКН, кадастровые номера и нюансы вроде «ё» в названиях улиц. Для контрагентов будут ИНН, КПП и ОГРН, для продаж — совсем другой набор проверок.
В качестве тестового датасета я взял открытый Реестр адресов Москвы. Задача была такая: агент через postgres-mcp смотрит схему, выбирает проверки из каталога правил, запускает SQL, пишет результаты в dq_snapshots, а потом через modusbi-mcp собирает отчёты в портале. Ниже расскажу, как именно он шёл, что получилось на выходе и почему после такого эксперимента агенту всё равно нельзя просто верить на слово.
Это один из экспериментов в нашей ИИ-работе. Внутри Modus BI мы постепенно расширяем свой MCP-сервер и пробуем агентные сценарии под разные задачи: дашборды, DQ, e2e-тесты, код-ревью, документацию, генерацию кода. Часть этого пути буду показывать в статьях.
Что может пойти не так
Соблазнительно рассказать эту историю коротко и красиво: дал агенту таблицу, попросил прогнать проверку качества, через час забрал готовый отчёт в портале. В каком-то смысле это правда. Но если остановиться на этой версии, то получится опасная картинка: будто агент сам понял данные, сам корректно выбрал правила, сам всё посчитал, и теперь результат можно использовать без оговорок.
На практике всё сложнее. Если запустить тот же самый сценарий ещё раз через десять минут на тех же данных, числа могут немного поехать. Не катастрофически, не в разы, но достаточно, чтобы перестать считать такой прогон воспроизводимым. Поэтому начну не с красивых отчётов, а с того, где агент подводит.

Агент забывает
Прошу прогнать все двадцать одну проверку — обычно он прогоняет все. Но иногда забывает одну-две, на ходу досочиняет формулировку, а в редком случае может пропустить целый класс проверок. Это не баг конкретного инструмента, а нормальное свойство языковой модели: она не исполняет план как детерминированный планировщик, а каждый раз заново собирает ход работы.
Лечится это отдельной проверкой после прогона. Нужно сверять каталог правил с таблицей результатов: все ли правила, которые должны были выполниться, действительно отметились в dq_snapshots. Если какое-то правило не отметилось — повторяем именно его. В отчёте с правилами строка «не прогнано» должна гореть красным сразу, иначе пропущенная проверка легко маскируется под хорошее качество данных.
Агент врёт уверенно
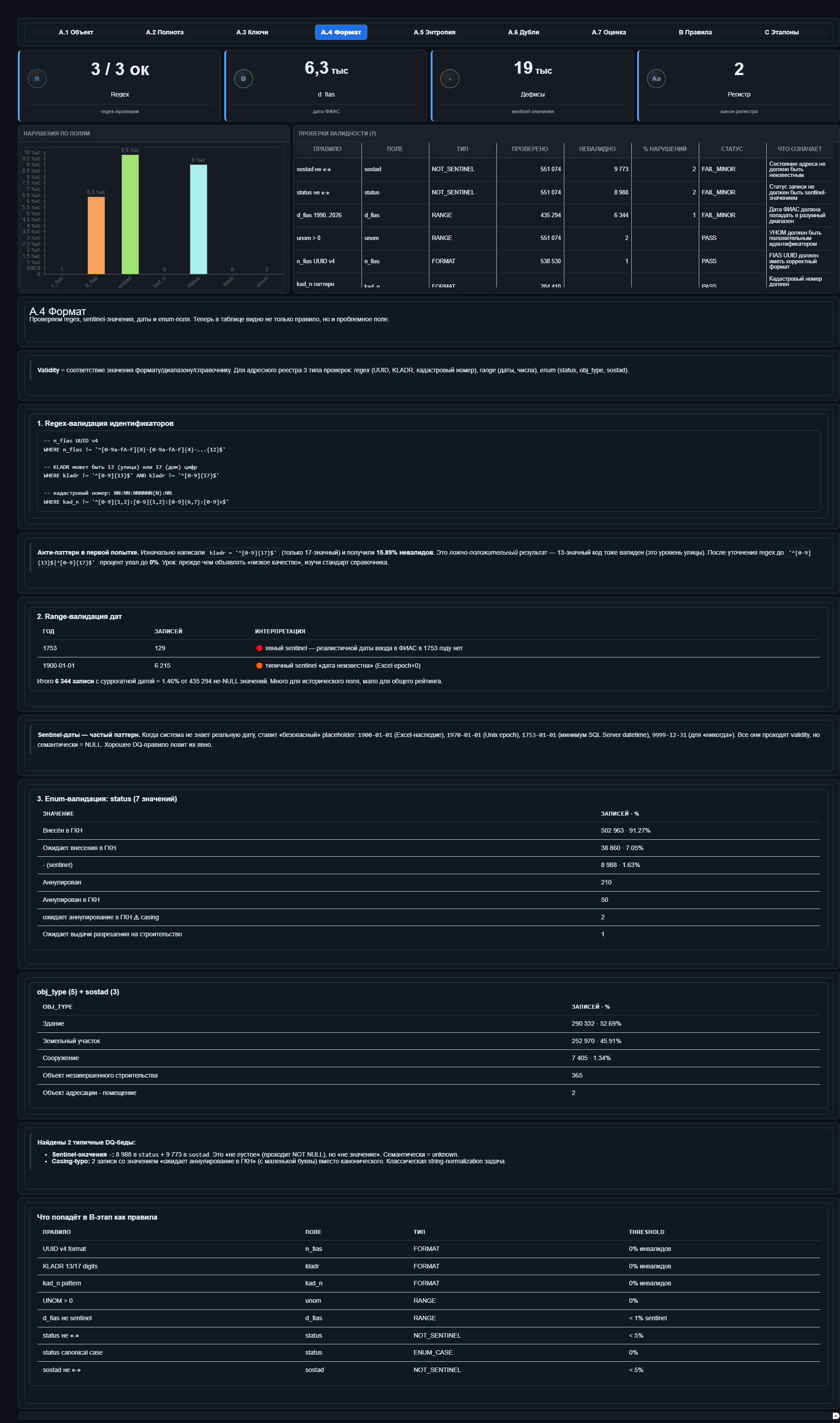
Самый показательный случай был на КЛАДР — классификаторе адресов России. Агент написал для него регулярку: семнадцать цифр. Прогнал проверку, и почти шестнадцать процентов значений оказались «невалидными». На полумиллионе строк это под шестьдесят тысяч записей, то есть уже не мелкая погрешность, а заметная «проблема качества».
Начал смотреть вручную — оказалось, что у КЛАДР в нашем случае два валидных формата: 13 цифр для улицы и 17 для дома. Регулярка с двумя вариантами дала ноль невалидных значений. Проблема здесь даже не ошибке агента, а в том, что он не предупредил, что мог что-то упустить. Он вообще редко предупреждает: скорее даст уверенный ответ, чем скажет «я не знаю нормативный формат, проверьте меня».
Похожее бывает и с SQL. Например, вместо корректного подсчёта через фильтр «count(*) filter (where ...)» агент может написать похожий запрос, который выглядит правдоподобно, но считает уже немного другое.
Поэтому регулярки и SQL для справочников вроде КЛАДР, ИНН, ОГРН я больше не доверяю агенту на лету. Они должны лежать в каталоге со ссылкой на нормативку, а агент должен брать их оттуда.
Агент не повторяется
Это тот самый разброс, с которого я начал. Один и тот же запрос на одних и тех же данных от прогона к прогону может дать чуть разные результаты: где-то агент срезал данные по-другому, где-то сгруппировал иначе, где-то добавил приведение к нижнему регистру, где-то нет. Иногда он по-разному решает, что считать заглушкой, а что нормальным значением.
Лекарство то же самое: SQL должен быть фиксированным и лежать в каталоге. В нём должна быть своя сортировка, явные условия и явный перечень того, что считается заглушкой. На этапе исполнения агент уже не пишет SQL, а только выбирает, какие проверки применить, и запускает готовые запросы. После того как запрос зафиксирован, прогон становится воспроизводимым. Разброс остаётся только в текстовых выводах, которые агент пишет под каждый отчёт, но это уже вопрос стиля, а не чисел.
Агент по-разному читает одну и ту же находку
Есть ещё один неприятный эффект: агент может интерпретировать одинаковые данные по-разному. Допустим, он видит 99 случаев, когда городской номер строения встречается в таблице больше одного раза. В одном прогоне он напишет «99 нарушений уникальности», в другом — «99 случаев, когда один номер покрывает здание и участок под ним, это нормально», в третьем — что-то посередине.
Проблема не в данных. Из них действительно не всегда видно, нарушение это или норма. Это знание про предметную область, а агент его не выводит из таблицы — он каждый раз заново выдумывает интерпретацию. Поэтому интерпретации тоже должны лежать в каталоге рядом с правилом. Для случая с unom формулировка такая: часть дублей может быть легитимной, но это не значит, что все 99 можно автоматически списать. Кандидаты всё равно надо показывать.
На первом круге агент полезен тем, что сам сходил в схему, понял, какие есть колонки, прикинул подходящие проверки, написал первые версии SQL для незнакомых случаев и собрал отчёты в портале. Руками такая работа заняла бы заметно больше времени. Но дальше SQL фиксируется, прогон ставится на расписание, а агент остаётся в основном для новых таблиц с новыми типами полей.
Помогает и второй проход другим агентом, который не повторяет работу, а проверяет её: все ли правила отметились, сходятся ли числа с фиксированным SQL, нет ли пропущенных проверок. Главный вывод для меня здесь простой: агент не заменяет аналитика. Он даёт скелет за час. Дальше человек смотрит, поправляет, дописывает правила в каталог. И в следующий раз шаблон работает не потому, что агент внезапно стал умнее, а потому что каталог накопился.
Что в итоге получилось
На выходе получилось девять связанных отчётов в портале. Между ними есть навигация сверху каждой страницы, чтобы можно было идти от общего описания объекта к конкретным нарушениям, правилам, эталонам и итоговой оценке. В подписях к иллюстрациям – ссылки на скриншоты отчётов.
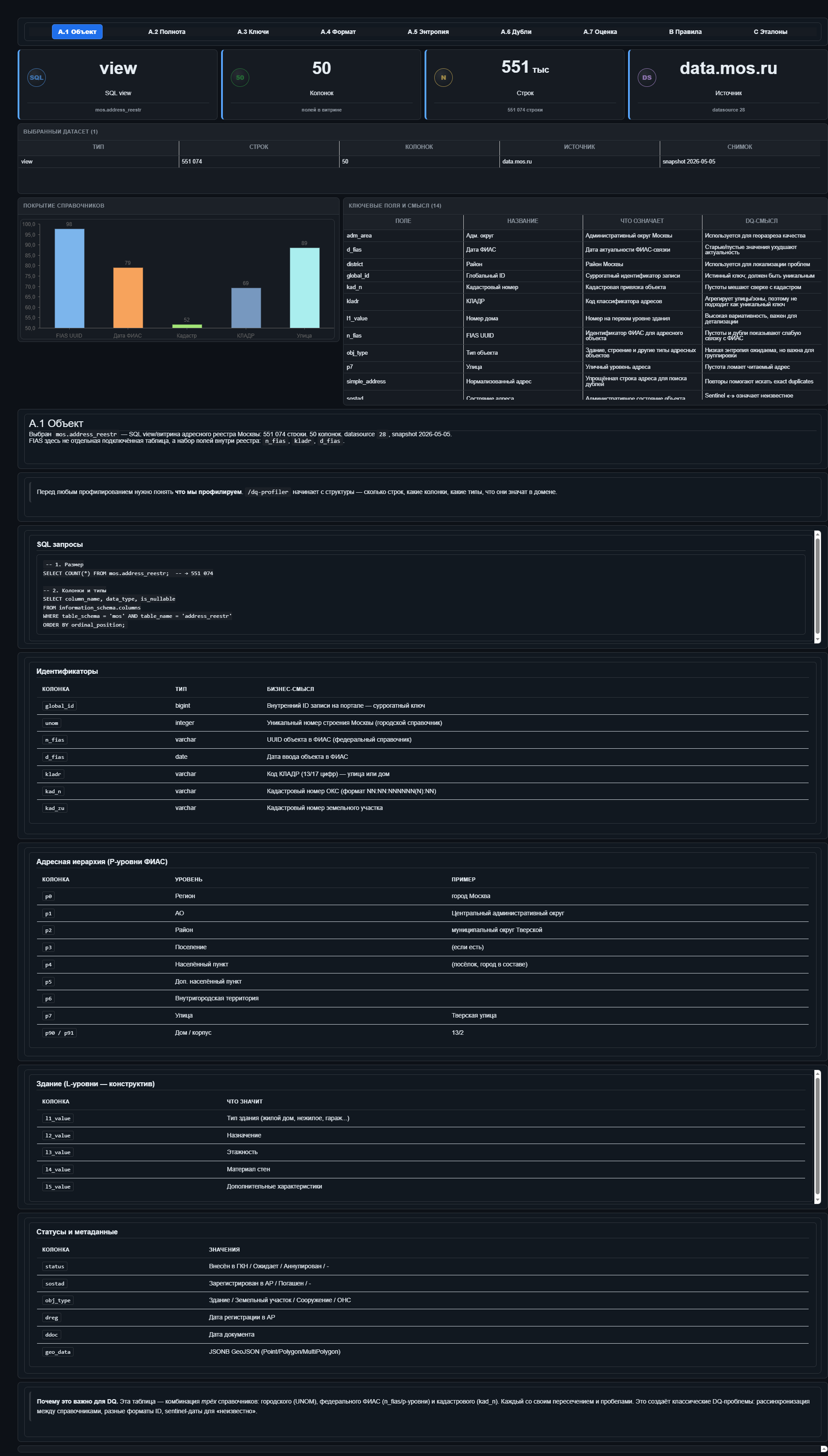
Профиль объекта
На нём четыре крупные карточки: тип объекта, количество строк, количество колонок и источник данных. Рядом текст с разбором колонок по группам: идентификаторы, адресная иерархия, конструктив здания, статусы, метаданные документа и геометрия. Это страница, которая отвечает на вопрос «что мы вообще проверяем». Без такого паспорта таблицы любые проценты качества висят в воздухе: непонятно, какие поля ключевые, какие вторичные, а какие вообще приходят из другого контура.

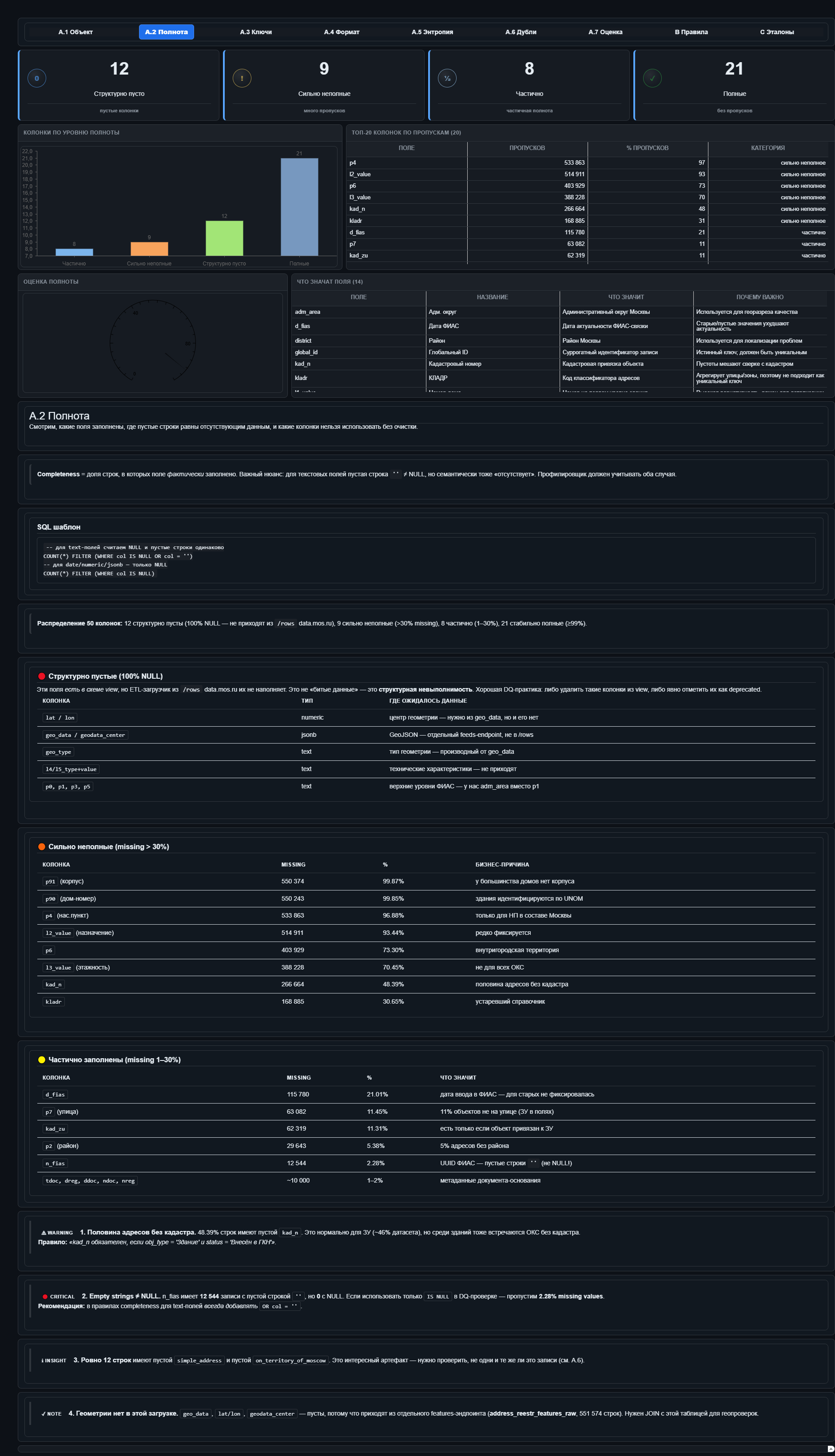
Полнота
Здесь сделан светофор по группам колонок: двенадцать пустых целиком, девять заполнены меньше чем наполовину, восемь заполнены частично, двадцать одна — почти всегда.
Под светофором таблица топ-20 колонок с пропусками, а сбоку текстовое пояснение. Оно важно, потому что двенадцать полностью пустых колонок — это не обязательно битые данные. Часть из них приходит другим потоком, например геометрия. Поэтому итоговая полнота получается 95, а не 60: мы не штрафуем источник за то, что заведомо из него не приходит.
На этом же экране нашлась первая нормальная DQ-находка. Колонка федерального идентификатора (n_fias) по проверке на NULL показывает стопроцентную заполненность, но больше двенадцати тысяч строк заполнены пустой строкой. Формально это не NULL, по сути — пусто. Стандартная проверка на NULL такое пропускает, поэтому в каталоге для текстовых колонок проверка хитрее: значение должно быть не NULL и не пустой строкой. В production я бы ещё добавлял проверку на пробельные значения «btrim(value) = ''», потому что пробелы тоже умеют притворяться данными:
На этом же экране нашлась первая нормальная DQ-находка. Колонка федерального идентификатора (n_fias) по проверке на NULL показывает стопроцентную заполненность, но больше двенадцати тысяч строк заполнены пустой строкой. Формально это не NULL, по сути — пусто. Стандартная проверка на NULL такое пропускает, поэтому в каталоге для текстовых колонок проверка хитрее: значение должно быть не NULL и не пустой строкой. В production я бы ещё добавлял проверку на пробельные значения «btrim(value) = ''», потому что пробелы тоже умеют притворяться данными:

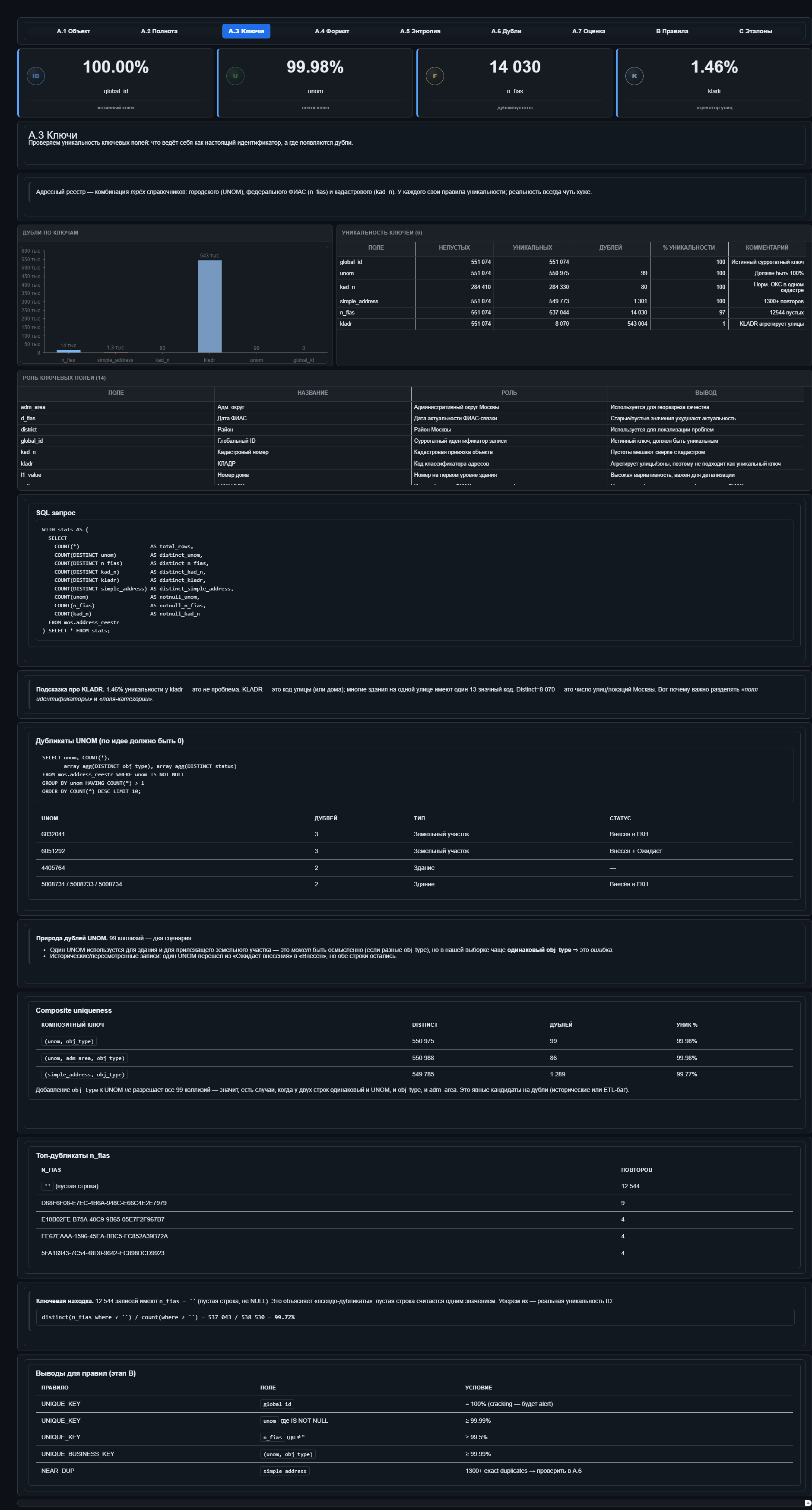
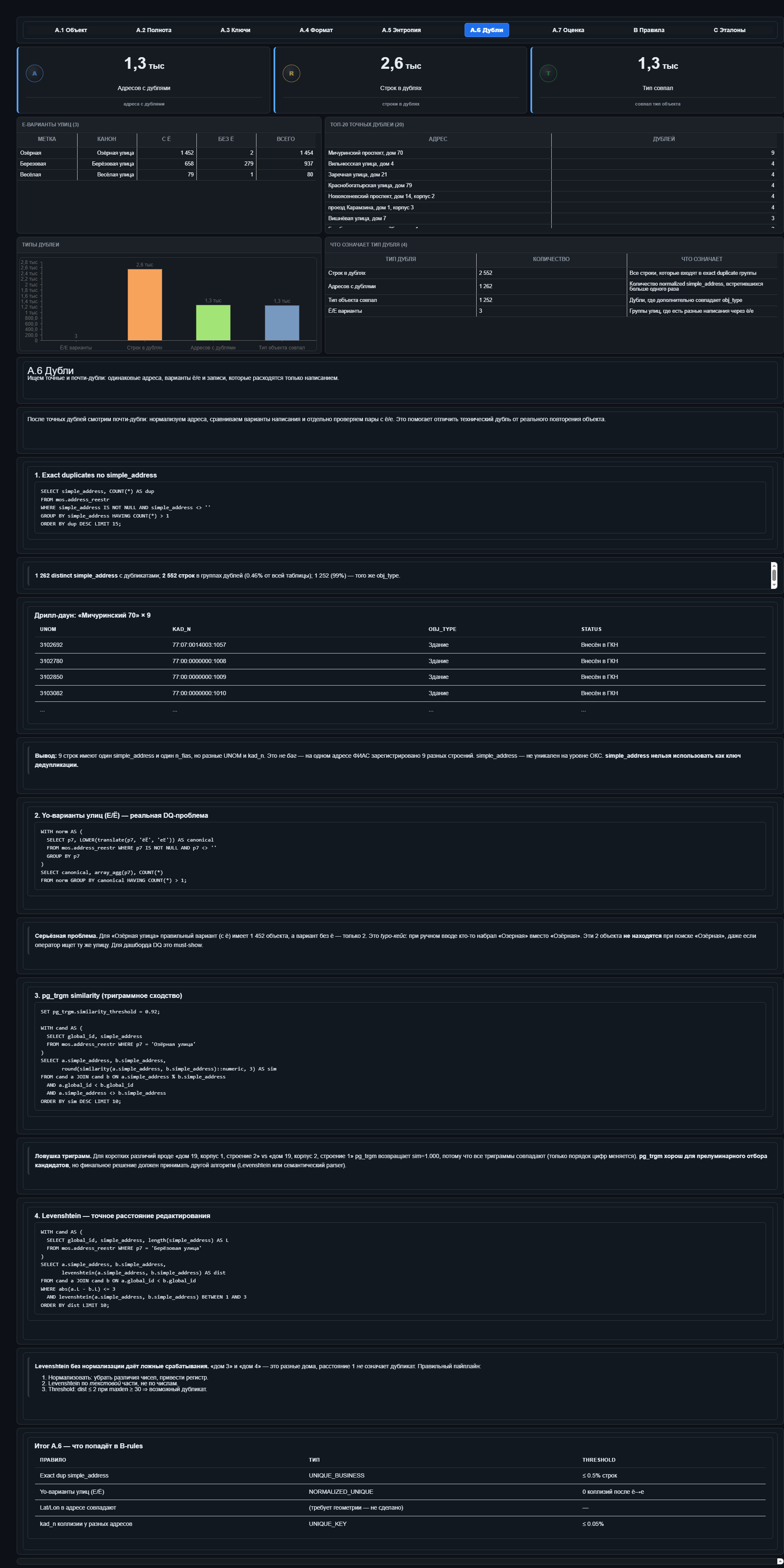
Уникальность
Здесь получилась таблица коллизий:
Суррогатный ключ (global_id) — уникален на сто процентов.
Городской номер строения (unom) — 99 повторов на полумиллион; часть легитимна (один номер может относиться к зданию и участку под ним), но часть всё равно надо смотреть.
Федеральный идентификатор (n_fias) — около четырнадцати тысяч «дублей», но двенадцать с лишним тысяч из них — те самые пустые строки. Поэтому реальная уникальность среди непустых значений заметно выше.
Адресная строка — группы, где один адрес встречается больше одного раза. В адресных данных это ожидаемо: иногда за одним адресом стоят несколько строений, корпусов или связанных объектов. Но именно поэтому отчёт должен не просто кричать «дубликат», а показывать кандидатов для разбора.

Корректность
Это проверки по шаблону и отдельный блок про заглушки.КЛАДР после правильной регулярки на 13 или 17 цифр дал ноль невалидных значений. Кадастровый номер по маске — тоже ноль.
Но заглушки считаются отдельно: дефис вместо статуса, дефис вместо состояния, фейковые даты вроде 1900-го или 1753-го. Это не то же самое, что битый формат. Значение может быть формально валидным и всё равно означать «ничего».

Энтропия
Здесь мы считаем, насколько разнообразны значения в колонке. Логика такая: если по смыслу там должен быть справочник, а разнообразие почти как у уникального поля, значит туда мог натечь свободный текст.
На улицах высокое разнообразие нормально: в Москве действительно тысячи улиц. А вот на колонке со значением типа объекта неожиданно много разных значений. Это не ошибка в строгом смысле, а сигнал «иди посмотри». Такая колонка уходит в раздел про эталоны.

Дубликаты
Дубликаты разделены на точные и почти-точные. Точные — это группы по адресной строке. В топе встречаются адреса, где на одном адресе несколько строений. Это не всегда баг: у каждого строения может быть свой номер.
Почти-точные — интереснее. Нашлись три улицы с разнобоем по «ё»: «Озёрная» и «Озерная», «Берёзовая» и «Березовая», «Весёлая» и «Веселая». Для человека это мелочь, а для поиска, сопоставления и нормализации уже проблема.

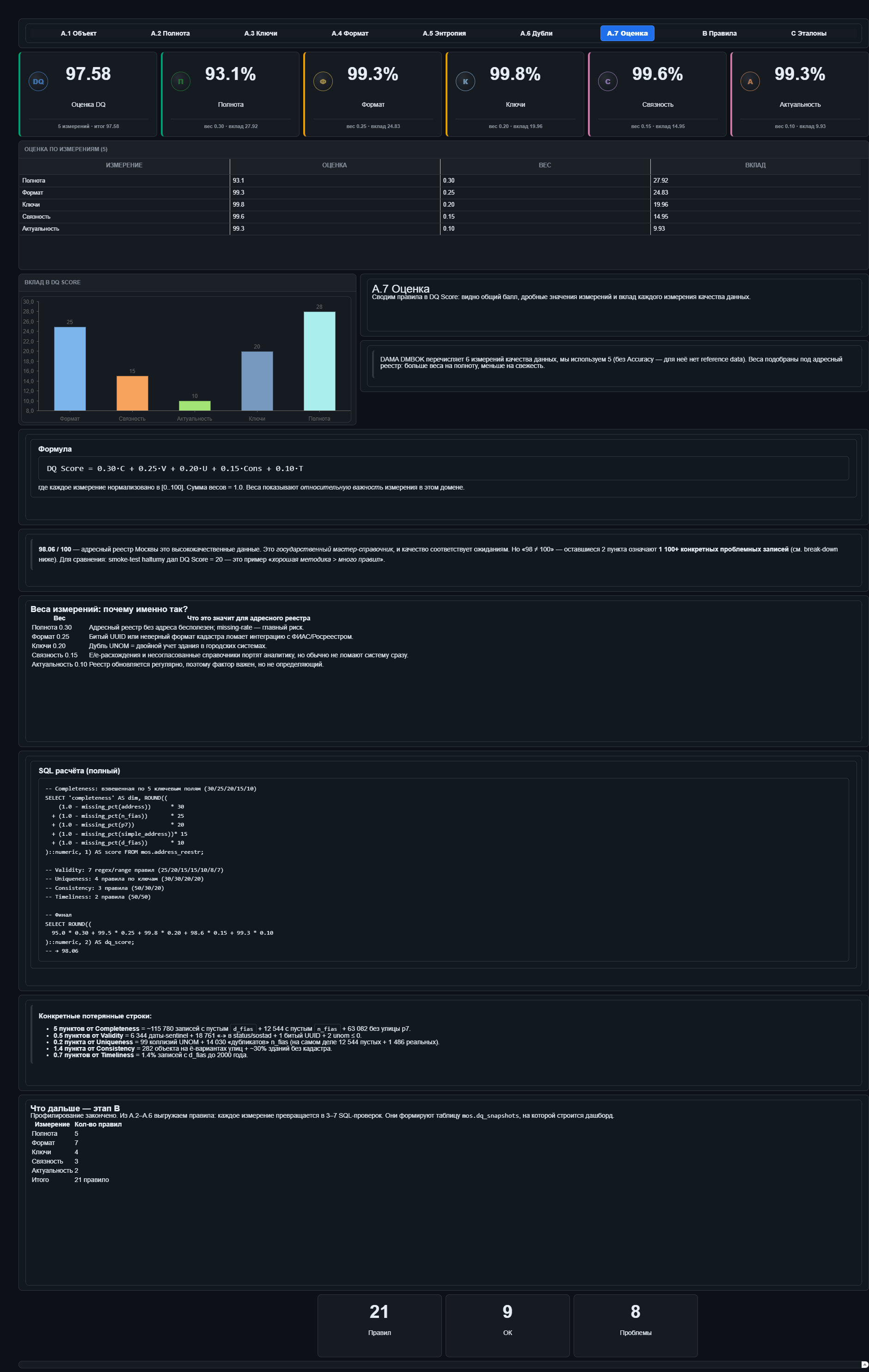
Итоговая оценка
И последний по списку, но первый по тому, на что обычно смотрят, — итоговая оценка. На странице спидометр от нуля до ста, стрелка на 98.06. Ниже разбивка по измерениям:
Изменение | Значение | Вес |
Полнота | 95,0 | 0,30 |
Корректность | 99,5 | 0,25 |
Уникальность | 99,8 | 0,20 |
Согласованность | 98,6 | 0,15 |
Актуальность | 99,3 | 0,10 |
Чтобы оценивать качество данных, мы опираемся на общую логику DAMA/ISO Это не волшебная формула, которая говорит: «данные хорошие на 98%». Это скорее методология: она помогает разложить качество данных на понятные признаки — заполненность, отсутствие дублей, согласованность, корректный формат и т.д. Но важность этих признаков зависит от задачи. Для адресного реестра одни ошибки критичны, другие терпимы. Если у записи нет населённого пункта — это серьёзная проблема. Если сокращение “ул.” записано не так, как хотелось бы, — это неприятно, но не всегда ломает использование данных.
Поэтому веса мы выбираем сами. Чем сильнее конкретный тип ошибки мешает использовать адресный реестр, тем больше вес. Наши коэффициенты 0.30 / 0.25 / 0.20 / 0.15 / 0.10 — это не стандарт DAMA и не истина в последней инстанции, а договорённость внутри проекта.
Главное: итоговый индекс показывает не “истинность” адресов, а соответствие данных нашим правилам проверки.

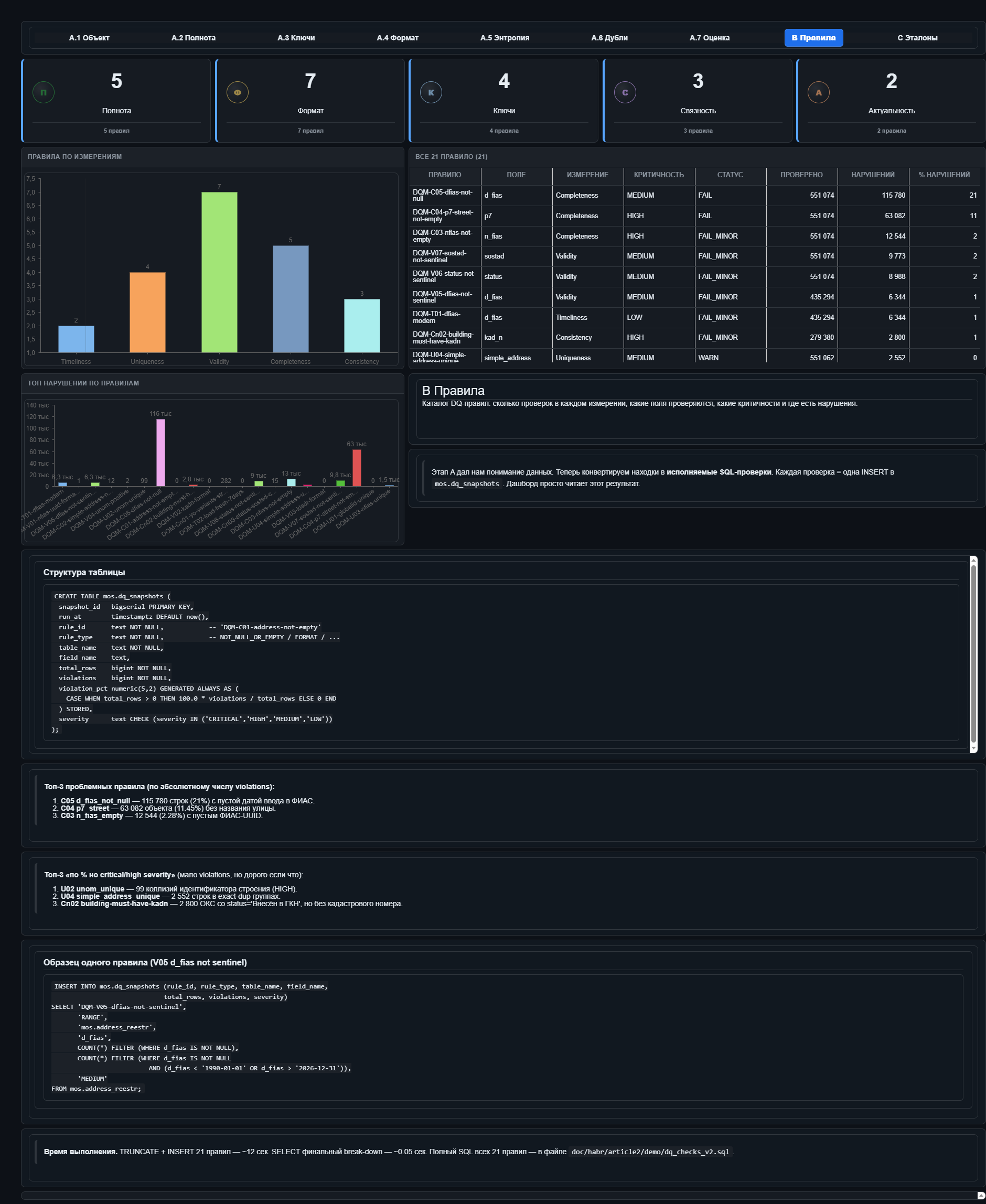
Каталог правил
В нём лежат идентификатор, тип, критичность, статус, количество нарушений и ссылка на SQL. Статус подкрашен, клик ведёт к примерам. Для меня это один из ключевых экранов, потому что именно он отделяет воспроизводимый DQ-процесс от красивого агентного демо. Если правило существует только в истории чата, оно неуправляемо. Если оно лежит в каталоге и связано с SQL, его можно повторить, проверить, обсудить, изменить и поставить на расписание.

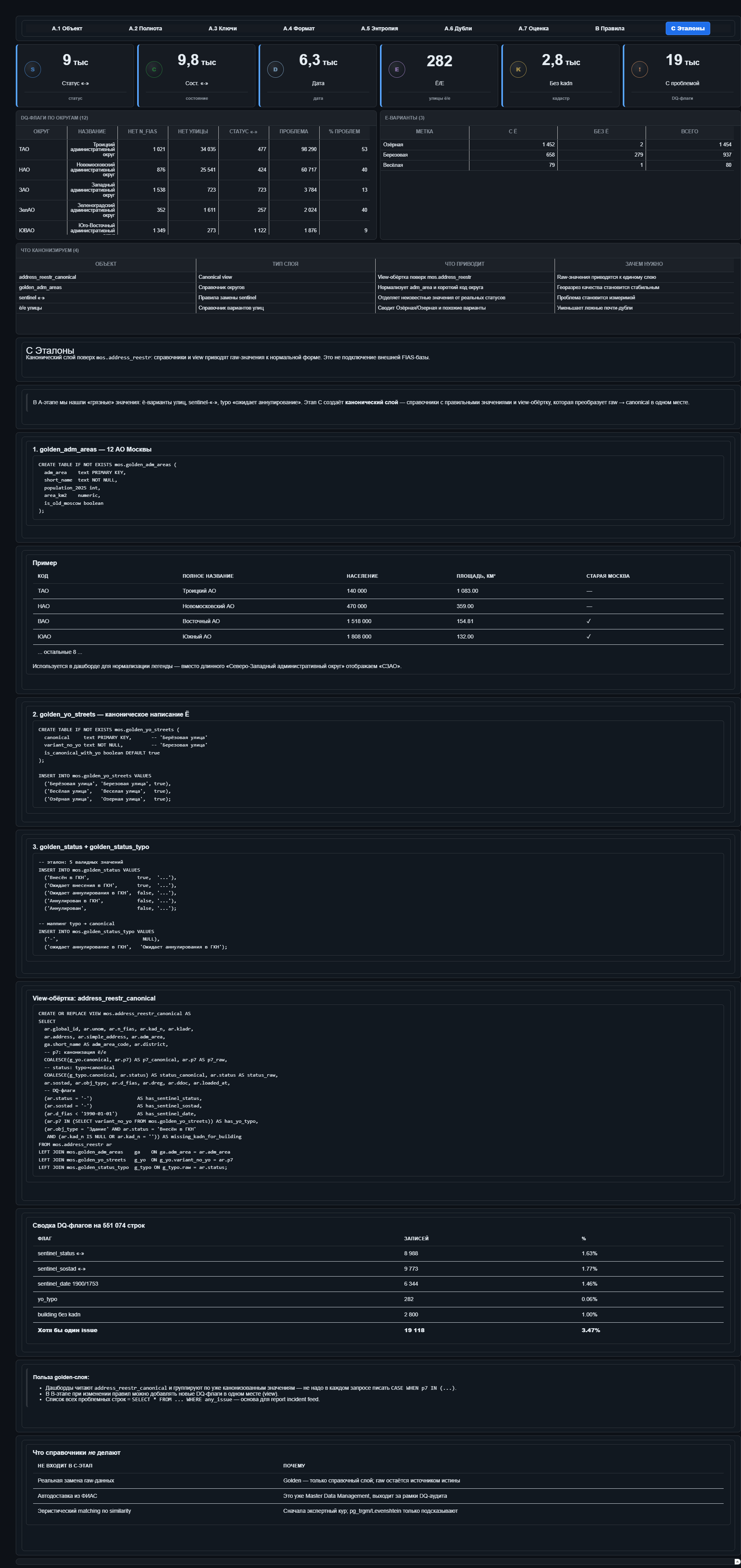
Эталоны
Это двенадцать административных округов Москвы, канонические написания для «ё»-улиц, сопоставление «опечатка → как правильно» для статусов. Поверх этого сделано представление, которое приклеивает эталоны к сырой таблице и дорисовывает флаги: заглушка вместо статуса, опечатка в названии, у здания нет кадастрового номера, хотя должен быть.
Всё вместе складывается в один каркас, который можно переносить на любую таблицу в Postgres: профиль, каталог правил, dq_snapshots, отчёты, история запусков. Но сами правила остаются доменными. КЛАДР, ФИАС, ГКН и «ё»-улицы нужны адресному реестру. Для контрагентов будут ИНН, КПП, ОГРН. Для продаж — свои проверки.

Откуда данные и почему они подходят для демо
Данные — Реестр адресов Москвы с data.mos.ru. Это открытый датасет примерно на полмиллиона строк и пятьдесят колонок. Он скачивается через API постранично, но без гарантии, что таблица не поменяется во время выгрузки. Поэтому для воспроизводимости нужен готовый срез: дата выгрузки, количество строк и колонок, SQL-прогон и выгрузка dq_snapshots. Без этого другие люди смогут повторить подход, но не обязательно получат те же цифры.
Для DQ-демо этот датасет удобен тем, что внутри это по сути три справочника, склеенных в одну таблицу: городской, федеральный ФИАС и кадастровый. Когда несколько источников описывают одни и те же объекты, расхождения появляются почти неизбежно. Отсюда пустые поля, заглушки, разные форматы, неоднозначные дубли и необходимость в доменных правилах.
Это не стерильная таблица, где все проблемы заранее придуманы для демонстрации. Данные достаточно живые, чтобы агенту было за что зацепиться, а человеку — что перепроверить.
Чем собирали
Из инструментов использовались MCP-сервера и четыре скилла.
MCP-серверы:
postgres-mcp — даёт агенту доступ к Postgres (чтение схемы, выполнение SQL);
modusbi-mcp — доступ к нашему BI-порталу (создание дашбордов и отчётов).
Скиллы:
Мастер — ведёт весь процесс.
Каталог правил — что и как проверять.
Историзация — таблица с прогонами, retention, запуск по расписанию.
Сборка отчётов в портале.
Между собой скиллы общаются не напрямую, а через одну таблицу с результатами. Кто-то в неё пишет, кто-то читает. Это и есть контракт: каталог правил, таблица результатов, MCP-серверы. При смене модели или раннера ломаться должно меньше, потому что методика лежит в SQL и таблицах, а не в памяти конкретного чата.
Здесь важна именно эта граница. Агент может помогать, ускорять и собирать обвязку, но воспроизводимая часть процесса должна жить вне агента. Если завтра поменять модель, чат или раннер, правила не должны исчезнуть вместе с контекстом.
Откуда берётся «двадцать одно правило»
Двадцать одно правило не появилось из воздуха. LLM сначала идёт в схему и смотрит, какие есть колонки, какого они типа и могут ли быть NULL. Потом по названиям и данным решает, какие проверки подходят. Если колонка называется как известный справочник — например, ИНН или КЛАДР, — берёт готовую проверку из каталога со ссылкой на нормативку. Если колонка текстовая, проверяет, что она не пустая, с поправкой на пустую строку. Если поле похоже на ключ, проверяет уникальность. Если по виду должно быть справочником, смотрит на заглушки и разнообразие. Для дат проверяет диапазон и свежесть.
Но есть вещи, которые агент сам надёжно не придумает. Это межполевые правила и легитимные исключения вроде «дубль номера тут может быть нормой». Такое знание относится к предметной области, его должен закладывать человек. Агент может предложить гипотезу, но не должен превращать её в истину без проверки.
Почему именно эти колонки в критичных
Критичность правил тоже объясняется предметкой:
Адресная строка и адрес — реестр адресов без адреса бессмысленен.
Федеральный идентификатор — высокий приоритет, на нём держатся связки с другими госсистемами.
Суррогатный ключ — критичный, его дубль значит, что объект учли дважды.
Городской номер — высокий, а не критичный, потому что про легитимные дубли мы знаем.
КЛАДР — потому что у него два валидных формата и на этом легко споткнуться.
Кадастровый номер — потому что есть бизнес-правило: у здания, которое уже внесли в ГКН, он должен быть.
Метки времени — на свежесть.
Граница ответственности агента
Ниже не витрина всех проверок, а граница ответственности. Всё, что в таблице, должно исполняться одинаково при каждом прогоне. Всё, чего в таблице нет, агент может придумать по-разному.
ID | Тип проверки | Критичность | Что проверяет |
DQM-C01 | обязательное непустое значение | критичный | address не пустой |
DQM-C02 | обязательное непустое значение | критичный | simple_address не пустой |
DQM-C03 | обязательное непустое значение | высокий | n_fias не пустой |
DQM-C04 | обязательное непустое значение | высокий | p7 / улица не пустая |
DQM-C05 | обязательное заполнение | средний | d_fias не NULL |
DQM-V01 | проверка по шаблону | высокий | n_fias — UUID-формат |
DQM-V02 | проверка по шаблону | высокий | kad_n — кадастровая маска |
DQM-V03 | проверка по шаблону | средний | kladr — 13 или 17 цифр |
DQM-V04 | диапазон значений | высокий | unom > 0 |
DQM-V05 | диапазон значений | средний | d_fias в 1990–2026 |
DQM-V06 | не служебная заглушка | средний | status не равен - |
DQM-V07 | не служебная заглушка | средний | sostad не равен - |
DQM-U01 | уникальность | критичный | global_id уникален |
DQM-U02 | уникальность | высокий | unom уникален |
DQM-U03 | уникальность | высокий | n_fias уникален среди непустых |
DQM-U04 | дубли | средний | дубли по simple_address |
DQM-Cn01 | нормализация | средний | ё-варианты названий улиц |
DQM-Cn02 | межполевая проверка | высокий | kad_n обязателен при obj_type='Здание' и status='Внесён в ГКН' |
DQM-Cn03 | межполевая проверка | средний | status и sostad не противоречат друг другу |
DQM-T01 | актуальность данных | низкий | d_fias не слишком старый |
DQM-T02 | актуальность данных | низкий | loaded_at свежий |
Всего получилось три критичных правила, восемь высоких, восемь средних и два низких.
Весь SQL-прогон занимает около двенадцати секунд на полумиллионе строк, без специальных индексов. Для публичной версии важно, чтобы этой таблице соответствовал конкретный SQL-файл и конкретная выгрузка dq_snapshots, иначе цифры в статье будет труднее проверить.
Если захочется попробовать
Для повторения нужен минимальный набор в репозитории:
четыре файла скиллов;
SQL-прогон;
срез данных или инструкция по его получению;
HTML-снимки отчётов;
выгрузка dq_snapshots.
DQ-часть можно повторить без Modus BI-портала: профилирование, каталог, историзация работают через Postgres. Сам портал — нет, modusbi-mcp пока внутренний, не публичный продукт; но те же отчёты можно отдать в HTML и увидеть результат так.
Каталог написан на диалекте Postgres: используются COUNT FILTER, регулярки через оператор тильда, generated columns и другие привычные для Postgres вещи. На ClickHouse, Vertica или MS SQL часть SQL придётся переписать. Я этого не проверял.
Про «менее чем за час» тоже важно сказать честно. Это не про создание всей системы с нуля, а про прогон уже готовой цепочки на новой таблице. Сами скиллы и обвязку я писал дольше, баги в MCP тоже ловил отдельно. Инструмент пишется один раз, дальше каждый новый датасет — это час чистого прогона.
Заключение
Главный вывод для меня не в том, что агент «сделал DQ». Была продемонстрирована возможность создания богатых и в меру универсальных отчётов качества данных в достаточно сжатые сроки. Безусловно каждый случай требует детальной ручной работы и проверки. Про это не стоит забывать. Благодаря скиллам мы можем получить «скелет» для дальнейшей работы.
В разрезе развития нашего MCP-сервера мне хотелось показать, насколько легко и просто можно составлять готовые дашборды. В ходе работы, честно признаюсь, был составлен значительный лист TODO: пока наш MCP-сервер не со всеми задачами справляется или справляется без пинка. Но именно поэтому эксперимент оказался полезным — это было испытание продукта на реальной задаче, и часть найденных шероховатостей уже поехала в бэклог.
Если есть вопросы по каталогу правил, скиллам или подводным камням MCP — пишите в комментарии, все разберём.
P.S. Присоединяйтесь к нашему BI-сообществу в Telegram и будьте в курсе последних новостей Modus!


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}