
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Если мы посмотрим на то количество титанических усилий, которое было вдыхано в этот убогий процессор из клавиатур (4004), чтобы получить
современную скорость работы, то увидим, что арму нужны какие-то нереальные подвиги для этого.
А сколько?
Приведите тогда количество x86 команд и количество микроопераций, в которые они транслируются.
режим процессоров ARM, в котором используется сокращенная система команд. Она состоит из 36 команд, взятых из стандартного набора 32-разрядных команд архитектуры ARM и преобразованных до 16-разрядных кодов.
Длина команд Thumb составляет половину длины стандартных 32-разрядных команд, что позволяет существенно сократить необходимые объёмы памяти программ (порядка 30 %) и, кроме того, позволяет использовать более дешёвую 16-разрядную память.
При выполнении эти команды дешифруются процессором в эквивалентные операции ARM, выполняемые за то же количество тактов.
Наиболее распространённая архитектура современных настольных, серверных и мобильных процессоров построена по архитектуре Intel x86 (или х86-64 в случае 64-разрядных процессоров). Формально, все х86-процессоры являлись CISC-процессорами, однако новые процессоры, начиная с Intel Pentium Pro, являются CISC-процессорами с RISC-ядром. Они непосредственно перед исполнением преобразуют CISC-инструкции процессоров x86 в более простой набор внутренних инструкций RISC.
В микропроцессор встраивается аппаратный транслятор, превращающий команды x86 в команды внутреннего RISC-процессора. При этом одна команда x86 может порождать несколько RISC-команд (в случае процессоров типа P6 — до четырёх RISC-команд в большинстве случаев). Исполнение команд происходит на суперскалярном конвейере одновременно по несколько штук.
Это потребовалось для увеличения скорости обработки CISC-команд, так как известно, что любой CISC-процессор уступает RISC-процессорам по количеству выполняемых операций в секунду. В итоге, такой подход и позволил поднять производительность CPU.
набор внутренних инструкций может быть как больше, так и меньше от исходного
add [ebx+edi], eax
В смысле? У x86 есть промежуточный набор команд между macro-ops и micro-ops? Почему вы так решили?
Ну ни откуда это не следует, что множество команд CISC больше множества команд micro-ops.
Пример: в языке c++ есть примерно 60 операторов (аналог CISC). Программа на C++ компилируется в x86 код, в котором примерно (не менее) 120 операторов (аналог micro-ops). Здесь множество «micro-ops» больше, чем множество «CISC».
Ну так эти «RISC ISA» и есть micro-ops, я их называю micro-ops, а не «что-то дальше».
Не следует. Для этого просто нужно вспомнить смысл этой трансляции — скорость работы (а не удобство программирования и простота процессора). Была бы не нужна скорость — оставили бы исполнитель команд как есть. Если добавление избыточной команды в набор micro-ops увеличит скорость, несмотря на то, что она будет избыточной — ее добавят.
Это будет суть оператор (), не более.
См. en.wikipedia.org/wiki/Micro-operation
Только цель этого — повышение производительности процессора. Набор команд micro-ops формируется с целью быстрой работы, а не простоты архитектуры.
Происходит трансляция команд в наборы micro-ops (µops).
OUT не захватывает все пространство «портов», поэтому для доступа к портам вне этого пространства требуется использовать ST.
Ха-ха-ха. «Разумный» — это субъективное понятие.
Простота — это субъективное понятие. Это мое главное возражение.
Могу предположить, что набор micro-ops похож на набор 40-битных инструкций Itanium.
Т.е. там уменьшилось число транзисторов, или что? Где упрощение?
Кому интересны упрощения в базовых блоках (если они есть), есть сложность процессора в целом возрастает?
У CISC вообще-то длина команд не фиксированная, а у Trumb фиксированная по этой причине транслировать Trumb проще.
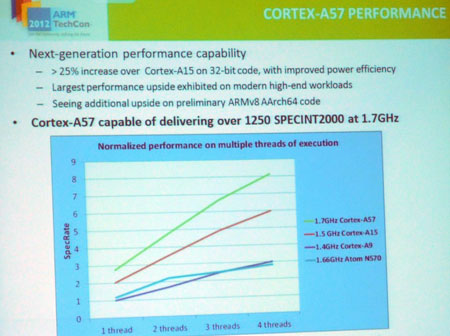
В итоге производительность на ватт x86 проигрывает ARM с треском.Это не так, они примерно на одном уровне плюс-минус.
роизводительность на ватт x86 проигрывает ARM с треском?E5-2630 (мой рабочий процессор) — 10к попугаев
мой ноутбук (i7-2640M) — 8.6k попугаев.
домашний компьютер 4х-летней давности (core quad) — 6k попугаев
Свежий-свежий арм (цифр на сайте не нашёл, верю вашим) — 2.2k.
E5-2630 (мой рабочий процессор) — 10к попугаев
мой ноутбук (i7-2640M) — 8.6k попугаев.
домашний компьютер 4х-летней давности (core quad) — 6k попугаев

а он ограничен 50 мб для казуалок
Whenever I see code that asks what the native byte order is, it's almost certain the code is either wrong or misguided. And if the native byte order really does matter to the execution of the program, it's almost certain to be dealing with some external software that is either wrong or misguided. If your code contains #ifdef BIG_ENDIAN or the equivalent, you need to unlearn about byte order.
unsigned funca(unsigned char *data)
{
return (data[3]<<0) | (data[2]<<8) | (data[1]<<16) | (data[0]<<24);
}
funca(unsigned char*): # @funca(unsigned char*)
movzbl 3(%rdi), %ecx
movzbl 2(%rdi), %eax
shll $8, %eax
orl %ecx, %eax
movzbl 1(%rdi), %ecx
shll $16, %ecx
orl %eax, %ecx
movzbl (%rdi), %eax
shll $24, %eax
orl %ecx, %eax
ret
unsigned funcb(unsigned char *data)
{
unsigned i = *((unsigned*)data);
i = ((i&0xFF)<<24) | (((i>>8)&0xFF)<<16) | (((i>>16)&0xFF)<<8) | (((i>>24)&0xFF)<<0);
return i;
}
funcb(unsigned char*): # @funcb(unsigned char*)
movl (%rdi), %eax
bswapl %eax
ret
А по поводу производительности — вы же знаете, что говорил Кнут о преждевременной оптимизации?
funca(unsigned char*):
ldrb r3, [r0, #1]
ldrb r1, [r0, #2]
ldrb r2, [r0, #3]
lsls r3, r3, #16
ldrb r0, [r0, #0]
orr r3, r3, r1, lsl #8
orrs r3, r3, r2
orr r0, r3, r0, lsl #24
bx lr
funcb(unsigned char*):
ldr r0, [r0, #0]
rev r0, r0
bx lr
И сегодня Apple доказала, что у них не просто маленький отдел из нескольких сотрудников занимается чипостроением
то отличие будет на проценты.

выпуском чужих разработокПочему чужих? Зря, что ли, они P.A. Semi покупали?
Многие лицензиаты делают собственные версии ядер на базе ARM: DEC StrongARM, Freescale i.MX, Intel XScale, NVIDIA Tegra, ST-Ericsson Nomadik, Krait в Qualcomm Snapdragon, Texas Instruments OMAP, Samsung Hummingbird, LG H13, Apple A6 и HiSilicon K3.



Apple первой начала выпускать 64-битный ARM-чип!