В последнее время в научных публикациях всё чаще упоминается алгоритм достижения консенсуса в распределенных системах под названием Paxos. Среди таких публикаций ряд работ сотрудников Google (Chubby, Megastore, Spanner) ранее уже частично освещенных на хабре, архитектуры систем WANdisco, Ceph и пр. В то же время, сам алгоритм Paxos считается сложным для понимания, хоть и основывается он на элементарных принципах.
В этой статье я постараюсь исправить эту ситуацию и рассказать об этом алгоритме понятным языком, как когда-то это попытался сделать автор алгоритма Лесли Лэмпорт.
Для начала нужно понять проблему, которую решает данный алгоритм. Для этого представим себе распределенную систему обработки информации, представляющую собой кластер x86 серверов. Если для одного сервера вероятность отказа мала и зачастую при внедрении простых систем ей можно пренебречь, то для кластера серверов вероятность отказа одного из серверов становится в разы больше: MTBF для одного из N серверов в N раз меньше чем MTBF для одного сервера. Добавим к этому ненадежность сети в виде отказа сетевого оборудования и потери пакетов, отказы жестких дисков, сбои серверного ПО на уровне ОС и приложений. Если верить Google, то для кластера из 1800 машин они говорят о 1000 отказах серверов в течении первого года эксплуатации кластера, то есть 3 отказа в день – и это не считая отказов жестких дисков, проблем с сетью и питанием и т.д. В итоге, если не закладывать отказоустойчивость в ПО распределенной системы, мы получим систему, в которой каждая из указанных выше проблем приводит к отказу системы.
Поэтому задача достижения консенсуса – задача получения согласованного значения группой участников в ситуации, когда возможны отказы отдельных участников, предоставление ими некорректной информации, искажения переданных значений средой передачи данных. В целом сценарии нештатного функционирования компонент распределенных систем можно разделить на два класса:
Ошибки второго класса намного более сложны в обнаружении и исправлении. В целом, Лесли Лэмпортом было доказано, что для исправления Византийской проблемы в N узлах распределенная система должна состоять как минимум из 3N+1 узлов и должна реализовывать специальный алгоритм консенсуса. Отказоустойчивость на этом уровне требуется по большей части в системах, критичность функционирования которых крайне высока (например, в задачах космической промышленности).
В кластерных вычислениях под отказоустойчивостью обычно понимают устойчивость системы к полным отказам компонент. Для достижения консенсуса в таких системах и применяется алгоритм Paxos. Алгоритм был предложен Лесли Лэмпортом в 90х годах прошлого века и назван в честь греческого острова Паксос с вымышленной системой организации работы парламента. Для достижения консенсуса данному алгоритму необходимо, чтобы в системе из 2N+1 узлов функционировали как минимум N+1 узла, эти N+1 узлы называются «кворум»
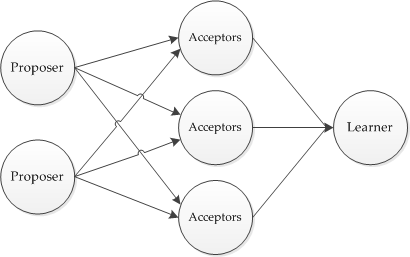
Суть алгоритма во взаимодействии агентов со следующими ролями:
Базовый алгоритм Paxos состоит из следующих этапов:
1а. Prepare («предложение»). На этой фазе proposer генерирует «предложение» с порядковым номером N и отправляет его всем acceptor. Для каждого из последующих «предложений» номер N должен быть больше выбранного ранее
1b. Promise («обещание»). Каждый acceptor получает «предложение» с порядковым номером N и значением V. Если номер «предложения» больше чем все принятые ранее данным acceptor, он обязан ответить на это сообщение «обещанием» не принимать более «предложений» с порядковым номером меньше N. Если данный acceptor уже принимал какое-либо «предложение», он должен вернуть номер Ni этого «предложения» и принятое значение Vi, в противном случае он возвращает пустое значение
2a. Accept! («принять»). Если proposer получил «обещания» от кворума acceptor, он считает запрос готовым к дальнейшей обработке. В случае, если с «обещаниями» от acceptor пришли также значения Ni и Vi, proposer выбирает V равное значению Vi «обещания» с максимальным Ni. Затем proposer отправляет запрос «принять» всем acceptor, который содержит значения N и V
2b. Accepted («принято»). Когда acceptor получает сообщение «принять» со значениями N и V, он принимает его только в том случае, если ранее он не «обещ��л» принимать предложения с номерами строго больше N. В противном случае он принимает значение и отвечает сообщением «принято» всем learner
Задача learner проста – получить сообщение «принято» со значением V и запомнить его
Пример функционирования алгоритма:
Что же происходит, если какой-то из компонент распределенной системы отказывает?
Отказ Acceptor:
Отказ Learner:
Отказ Proposer:
В случае отказа proposer система должна выбрать нового proposer, обычно это производится путем голосования по истечении тайм-аута ожидания возвращения старого proposer. В случае, если после выбора нового proposer старый возвращается к жизни, между лидерами может возникнуть конфликт, который может привести к зацикливанию системы:
В качестве примера реализации приведу немного модифицированный python код одного из репозиториев github:
Литература:
В этой статье я постараюсь исправить эту ситуацию и рассказать об этом алгоритме понятным языком, как когда-то это попытался сделать автор алгоритма Лесли Лэмпорт.
Для начала нужно понять проблему, которую решает данный алгоритм. Для этого представим себе распределенную систему обработки информации, представляющую собой кластер x86 серверов. Если для одного сервера вероятность отказа мала и зачастую при внедрении простых систем ей можно пренебречь, то для кластера серверов вероятность отказа одного из серверов становится в разы больше: MTBF для одного из N серверов в N раз меньше чем MTBF для одного сервера. Добавим к этому ненадежность сети в виде отказа сетевого оборудования и потери пакетов, отказы жестких дисков, сбои серверного ПО на уровне ОС и приложений. Если верить Google, то для кластера из 1800 машин они говорят о 1000 отказах серверов в течении первого года эксплуатации кластера, то есть 3 отказа в день – и это не считая отказов жестких дисков, проблем с сетью и питанием и т.д. В итоге, если не закладывать отказоустойчивость в ПО распределенной системы, мы получим систему, в которой каждая из указанных выше проблем приводит к отказу системы.
Поэтому задача достижения консенсуса – задача получения согласованного значения группой участников в ситуации, когда возможны отказы отдельных участников, предоставление ими некорректной информации, искажения переданных значений средой передачи данных. В целом сценарии нештатного функционирования компонент распределенных систем можно разделить на два класса:
- Полный отказ компонента. Характеризуется этот класс проблем тем, что такой отказ приводит к недоступности одного из компонент распределенной системы (или сегментации сети, в случае отказа коммутатора). К этому классу проблем относятся: отказ сервера, отказ системы хранения данных, отказ коммутатора, отказ операционной системы, отказ приложения;
- Византийская ошибка. Характеризуется тем, что узел системы продолжает функционировать, но при этом может возвращать некорректную информацию. Допустим, при использовании оперативной памяти без ECC может привести к считыванию некорректных данных из памяти, ошибки сетевого оборудования могут приводить к повреждению пакетов и т.п.
Ошибки второго класса намного более сложны в обнаружении и исправлении. В целом, Лесли Лэмпортом было доказано, что для исправления Византийской проблемы в N узлах распределенная система должна состоять как минимум из 3N+1 узлов и должна реализовывать специальный алгоритм консенсуса. Отказоустойчивость на этом уровне требуется по большей части в системах, критичность функционирования которых крайне высока (например, в задачах космической промышленности).
В кластерных вычислениях под отказоустойчивостью обычно понимают устойчивость системы к полным отказам компонент. Для достижения консенсуса в таких системах и применяется алгоритм Paxos. Алгоритм был предложен Лесли Лэмпортом в 90х годах прошлого века и назван в честь греческого острова Паксос с вымышленной системой организации работы парламента. Для достижения консенсуса данному алгоритму необходимо, чтобы в системе из 2N+1 узлов функционировали как минимум N+1 узла, эти N+1 узлы называются «кворум»
Суть алгоритма во взаимодействии агентов со следующими ролями:
- Client – клиент распределенной системы, который может отправить запрос и получить на него ответ
- Proposer – компонент распределенной системы, отвечающий за организацию процесса голосования
- Acceptor – ком��онент распределенной системы, имеющий право голоса за принятие или отклонение конкретного предложения от Proposer
- Learner – компонент системы, который запоминает принятое решение
Базовый алгоритм Paxos состоит из следующих этапов:
1а. Prepare («предложение»). На этой фазе proposer генерирует «предложение» с порядковым номером N и отправляет его всем acceptor. Для каждого из последующих «предложений» номер N должен быть больше выбранного ранее
1b. Promise («обещание»). Каждый acceptor получает «предложение» с порядковым номером N и значением V. Если номер «предложения» больше чем все принятые ранее данным acceptor, он обязан ответить на это сообщение «обещанием» не принимать более «предложений» с порядковым номером меньше N. Если данный acceptor уже принимал какое-либо «предложение», он должен вернуть номер Ni этого «предложения» и принятое значение Vi, в противном случае он возвращает пустое значение
2a. Accept! («принять»). Если proposer получил «обещания» от кворума acceptor, он считает запрос готовым к дальнейшей обработке. В случае, если с «обещаниями» от acceptor пришли также значения Ni и Vi, proposer выбирает V равное значению Vi «обещания» с максимальным Ni. Затем proposer отправляет запрос «принять» всем acceptor, который содержит значения N и V
2b. Accepted («принято»). Когда acceptor получает сообщение «принять» со значениями N и V, он принимает его только в том случае, если ранее он не «обещ��л» принимать предложения с номерами строго больше N. В противном случае он принимает значение и отвечает сообщением «принято» всем learner
Задача learner проста – получить сообщение «принято» со значением V и запомнить его
Пример функционирования алгоритма:
Client Proposer Acceptor Learner | | | | | | | X-------->| | | | | | Request | X--------->|->|->| | | Prepare(1) | |<---------X--X--X | | Promise(1,{Va,Vb,Vc}) | X--------->|->|->| | | Accept!(1,Vn=last(Va,Vb,Vc)) | |<---------X--X--X------>|->| Accepted(1,Vn) |<---------------------------------X--X Response | | | | | | |
Что же происходит, если какой-то из компонент распределенной системы отказывает?
Отказ Acceptor:
Так как в системе 3 узла ассеptor, допускается отказ одного из них, так как кворум в данном случае равен двумClient Proposer Acceptor Learner | | | | | | | X-------->| | | | | | Request | X--------->|->|->| | | Prepare(1) | | | | ! | | !! FAIL !! | |<---------X--X | | Promise(1,{null,null, null}) | X--------->|->| | | Accept!(1,V) | |<---------X--X--------->|->| Accepted(1,V) |<---------------------------------X--X Response | | | | | |
Отказ Learner:
Client Proposer Acceptor Learner | | | | | | | X-------->| | | | | | Request | X--------->|->|->| | | Prepare(1) | |<---------X--X--X | | Promise(1,{null,null,null}) | X--------->|->|->| | | Accept!(1,V) | |<---------X--X--X------>|->| Accepted(1,V) | | | | | | ! !! FAIL !! |<---------------------------------X Response | | | | | |
Отказ Proposer:
Client Proposer Acceptor Learner | | | | | | | X----->| | | | | | Request | X------------>|->|->| | | Prepare(1) | |<------------X--X--X | | Promise(1,{null, null, null}) | | | | | | | | | | | | | | !! Leader fails during broadcast !! | X------------>| | | | | Accept!(1,Va) | ! | | | | | | | | | | | | !! NEW LEADER !! | X--------->|->|->| | | Prepare(2) | |<---------X--X--X | | Promise(2,{null, null, null}) | X--------->|->|->| | | Accept!(2,V) | |<---------X--X--X------>|->| Accepted(2,V) |<---------------------------------X--X Response | | | | | | |
В случае отказа proposer система должна выбрать нового proposer, обычно это производится путем голосования по истечении тайм-аута ожидания возвращения старого proposer. В случае, если после выбора нового proposer старый возвращается к жизни, между лидерами может возникнуть конфликт, который может привести к зацикливанию системы:
Для предотвращения этого в практической реализации алгоритма каждый proposer имеет порядковый номер и при выборе нового proposer этот номер увеличивается на единицу. Никто из acceptor не принимает сообщения от старого proposer.Client Leader Acceptor Learner | | | | | | | X----->| | | | | | Request | X------------>|->|->| | | Prepare(1) | |<------------X--X--X | | Promise(1,{null,null,null}) | ! | | | | | !! LEADER FAILS | | | | | | | !! NEW LEADER (knows last number was 1) | X--------->|->|->| | | Prepare(2) | |<---------X--X--X | | Promise(2,{null,null,null}) | | | | | | | | !! OLD LEADER recovers | | | | | | | | !! OLD LEADER tries 2, denied | X------------>|->|->| | | Prepare(2) | |<------------X--X--X | | Nack(2) | | | | | | | | !! OLD LEADER tries 3 | X------------>|->|->| | | Prepare(3) | |<------------X--X--X | | Promise(3,{null,null,null}) | | | | | | | | !! NEW LEADER proposes, denied | | X--------->|->|->| | | Accept!(2,Va) | | |<---------X--X--X | | Nack(3) | | | | | | | | !! NEW LEADER tries 4 | | X--------->|->|->| | | Prepare(4) | | |<---------X--X--X | | Promise(4,{null,null,null}) | | | | | | | | !! OLD LEADER proposes, denied | X------------>|->|->| | | Accept!(3,Vb) | |<------------X--X--X | | Nack(4) | | | | | | | | ... and so on ...
В качестве примера реализации приведу немного модифицированный python код одного из репозиториев github:
class Proposer (object): # 1a. Генерируется уникальное значение proposal_id (в описании алгоритма фигурирует как "N") # и отправляется "предложение" всем acceptor def prepare(self): self.promises_rcvd = 0 self.proposal_id = self.next_proposal_number self.next_proposal_number += 1 self.messenger.send_prepare(self.proposal_id) # 2a. Получаем "обещание". Если предложение было не наше - ингорируем. Если с "обещанием" # вернулось также принятое acceptor значение - принимаем его как значение нашего предложения. # Если количество принятых "обещаний" равно кворуму, отправляем сообщение "принять" def recv_promise(self, proposal_id, prev_accepted_id, prev_accepted_value): if proposal_id != self.proposal_id: return if prev_accepted_id > self.last_accepted_id: self.last_accepted_id = prev_accepted_id if prev_accepted_value is not None: self.proposed_value = prev_accepted_value self.promises_rcvd += 1 if self.promises_rcvd == self.quorum_size: if self.proposed_value is not None: self.messenger.send_accept(self.proposal_id, self.proposed_value) class Acceptor (object): # 1b. Acceptor получает "предложение" от proposer. В случае, если предложение с таким номером уже приходило, # отправляем тот же самый ответ. Если ранее приходило только предложения с меньшим номером, отправляем # номер последнего принятого предложения и принятое значение (если таковое есть) как "обещание" def recv_prepare(self, proposal_id): if proposal_id == self.promised_id: self.messenger.send_promise(proposal_id, self.accepted_id, self.accepted_value) elif proposal_id > self.promised_id: self.promised_id = proposal_id self.messenger.send_promise(proposal_id, self.accepted_id, self.accepted_value) # 2b. Получаем сообщение "принять". Если мы не обещали не принимать значения с таким номером, то # запоминаем идентификатор и значение этого сообщения и отвечаем "принято" def recv_accept_request(self, from_uid, proposal_id, value): if proposal_id >= self.promised_id: self.promised_id = proposal_id self.accepted_id = proposal_id self.accepted_value = value self.messenger.send_accepted(proposal_id, self.accepted_value) class Learner (object): # 3. Learner получает сообщение "принято", запоминает это значение и возвращает управление клиенту def recv_accepted(self, from_uid, proposal_id, accepted_value): self.final_value = accepted_value self.messenger.on_resolution( proposal_id, accepted_value )
Литература:

