Мне оказали честь — пригласили выступить на первой конференции C++ 2015 Russia 27-28 февраля. Я был насколько наглым, что запросил 2 часа на выступление вместо положенного одного и заявил тему, наиболее меня интересующую — конкурентные ассоциативные контейнеры. Это hash set/map и деревья. Организатор sermp пошел навстречу, за что ему большое спасибо.
Как подготовиться ко столь ответственному
Конечно, надо записать свои мысли, глядя на слайды. А если что-то написано, то не худо бы и опубликовать. А если публиковать, — то на хабре.
Итак, по следам C++ 2015 Russia! Авторское изложение, надеюсь, без авторского косноязычия, без купюр и с отступлениями по теме, написанное до наступления события, в нескольких частях.
Мне, как программисту на C++, больше всего из стандартной библиотеки контейнеров приходилось использовать не очереди/стеки/деки/списки, а ассоциативные контейнеры — hash set/map, они же std::unordered_set/map, и деревья, то есть std::set/map. Как мы знаем, стандарт C++11 гарантирует нам thread-safe работу с такими контейнерами, но очень слабую — только read-only, любое изменение — только под внешней блокировкой! На практике такая гарантия — это почти ничто, ибо если у меня вырисовывается read-only map, то скорее всего я сделаю отсортированный массив и буду по нему искать бинарным поиском — опыт показывает, что так и быстрее, и память используется бережно, и кешу процессора приятно.
Можно ли реализовать concurrent map – контейнер без необходимости внешней синхронизации? Давайте изучим этот вопрос.
Для разминки посмотрим на внутреннее строение hash map.
Hash table
Внутренне устройство простейшего hash map со списком коллизий чрезвычайно примитивно: имеется массив
T[N], каждый элемент которого — это список. Входом в таблицу (индексом) является хеш-значение ключа. Все ключи с одним и тем же хешем (по модулю N) попадают в один и тот же список, называемый списком коллизий.
Вообще, всё самое главное здесь скрыто внутри хеш-функции. Hash map будет хорошо работать тогда и только тогда, когда для множества ключей выбрана правильная хеш-функция. «Правильная» — это значит, прежде всего, «хорошо разбрасывающая» ключи по ячейкам таблицы. Но с точки зрения повышения уровня конкуренции нам совершенно не важно, как внутри устроена хеш-функция, так что более мы о ней говорить не будем.
Глядя на картинку, можно сразу догадаться, как обычный hash map сделать конкурентным: вместо того, чтобы блокировать доступ ко всему hash map, можно блокировать на уровне каждой ячейки таблицы
T[N]. Тем самым работа с каждым конкретным списком коллизий T[i] будет сериализована, но работу с разными списками T[i] и T[j] (i != j ) можно вести параллельно. Эта техника описана в работе M.Herlihy and Nir Shavit «The Art of Multiprocessor Programming» и называется авторами striping.
Претензия издателям
Почему эта работа у нас ещё не переведена, хотя в оригинале выдержала уже два издания?!!! Этот фундаментальный труд от весьма известных в мире авторов — аналог монументальной монографии Кнута, но для параллельных алгоритмов, бесценное пособие для студентов и всех, кто хочет разобраться, «как это работает», стартовая площадка для выращивания отечественных кадров.
Нет, будем издавать макулатуру «C++ за 35 минут для чайников»! Чайникам не нужен C++!!! А без таких книг у нас только и будут, что чайники. К читателям хабра этот дисклеймер не относится.
Нет, будем издавать макулатуру «C++ за 35 минут для чайников»! Чайникам не нужен C++!!! А без таких книг у нас только и будут, что чайники. К читателям хабра этот дисклеймер не относится.
Striped map

Итак, в технике striping мы имеем два массива — массив блокировок
Lock[N] и собственно хеш-таблицу T[N]. Изначально размер этих двух массивов совпадает (это важное требование, далее мы увидим, почему). Внутренний алгоритм работы простой: при любой операции (insert/erase/find) мы вычисляем хеш-значение i ключа по модулю N, блокируем мьютекс Lock[i] и идем выполнять операцию в списке T[i]. Но есть одно «но»: хеш-таблицу требуется время от времени расширять. Критерием необходимости расширения является так называемый load factor: отношение числа элементов в hash map к размеру N хеш-таблицы. Если мы расширять таблицу не будем, списки коллизий у нас станут очень большими, и все преимущества hash map превратятся в тыкву: вместо оценки O(1) для сложности операции мы получим O(S/N), где S – число элементов в таблице, что при S >> N и неизменном N эквивалентно O(S), то есть сложности линейного поиска! Это неприемлемо. Для борьбы с этим явлением требуется делать rehashing: увеличивать N, если load factor превысит некоторое пороговое значение, и перестраивать хеш-таблицу под новые хеш-значения std::hash(key) % N'.Алгоритм rehashing для striped map таков:
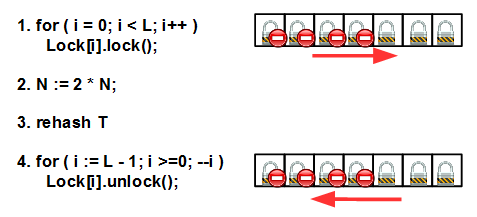
Сначала мы блокируем все мьютексы слева направо; затем увеличиваем N в целое число раз (целое число — это важно, см. далее), перестраиваем хеш-таблицу и, наконец, разблокируем все мьютексы в обратном порядке — справа налево. Не забываем, что основная причина deadlock – несоблюдение порядка блокировки/разблокировки нескольких мьютексов.
Блокировка всех мьютексов здесь важна, чтобы никто не помешал нам сделать rehashing. Rehashing является довольно тяжелой операцией и перераспределяет ключи по ячейкам новой таблицы
T[N'].Заметим, что выше мы говорили об увеличении размера хеш-таблицы, но ничего не сказали об увеличении размера массива блокировок
Lock[N], — это неспроста: дело в том, что размер массива блокировок не изменяется. 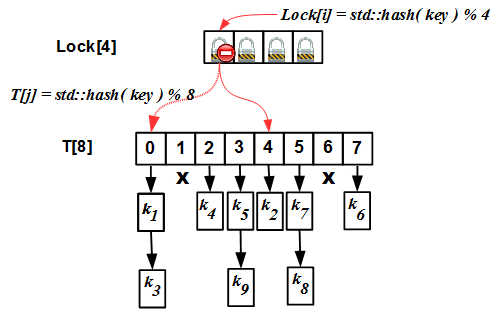
Если размеры массивов
Lock и T различны, то в принципе возможна ситуация, когда разным мьютексам Lock[i] и Lock[j] соответствует одна и та же ячейка T[k], что ломает весь наш стройный алгоритм. Чтобы это было недопустимо, требуется:- Изначально размеры массивов
LockиTсовпадают и равныN - При rehashing'е новый размер
N'массиваTвычисляется какN' = k * N, гдеk– натуральное число (обычно 2).
При выполнении этих условий у нас всегда размер массива
T кратен размеру массива Lock (который не изменяется); исходя из свойств арифметики по модулю, легко доказать, что в этом случае одна и та же ячейка T[k] не может соответствовать разным мьютексам Lock[i] и Lock[j].
Refinable hash map
Авторы «The Art of Multiprocessor Programming» идут дальше, решая задачу rehashing'а для массива
Lock, то есть предлагая алгоритм, позволяющий увеличивать размер Lock[] наравне с увеличением хеш-таблицы. Они называют этот алгоритм refinable hash map. Интересующихся отсылаю к оригиналу.Алгоритм striping легко распространяется на другие структуры данных, например, деревья:

Идея очень проста: каждый элемент массива
Lock[L] мьютексов защищает свое дерево. Входом в Lock[L] является хеш-значение ключа (по модулю L). Блокировав Lock[i], мы получаем доступ к соответствующему дереву, в котором и выполняем требуемое действие.
libcds
В библиотеке libcds есть реализации striped и refinable hash set/map, равно как и адаптеры для всех ассоциативных контейнеров из STL и boost, в том числе интрузивных.
Техника striping неплоха, но у неё есть существенный, с точки зрения цикла статей о lock-free структурах данных, изъян, — она блокируемая. Можно ли придумать lock-free алгоритм для hash map?..
Lock-free ordered list
Взглянем ещё раз на внутреннюю структуру hash map:
Пока оставим за бортом вопросы rehashing'а, будем считать, что мы априори знаем число элементов в хеш-таблице и имеем хорошую хеш-функцию для нашего множества ключей. Тогда для построения lock-free hash map нам нужно немного — lock-free список коллизий. А список коллизий — это не что иное, как упорядоченный (по ключу) односвязный список. Его-то мы и будем пытаться построить, вслед за T.Harris и M.Michael.
Поиск по lock-free списку довольно тривиален: линейный проход по списку, начиная с его головы. Учитывая, что мы используем атомарные операции и одну из схем безопасного удаления (Hazard Pointer, user-space RCU или аналогичную), алгоритм поиска не сильно отличается от обычного поиска по упорядоченному списку (на самом деле, если взглянуть на код, — сильно, но это плата за lock-free).
Вставка нового элемента тоже не представляет проблем:
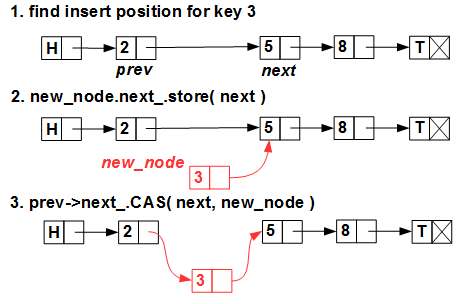
Мы ищем позицию вставки (помним, что список у нас упорядоченный), создаем новый элемент и вставляем его одним-единственным примитивом CAS (compare-and-swap, он же
std::compare_exchange).Удаление тоже довольно тривиально:
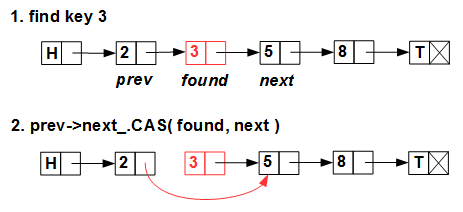
Линейно ищем удаляемый элемент и атомарно, CAS'ом, перекидываем указатель с его предшественника на следующий за ним элемент.
Проблемы начинаются, когда все это делается вместе и параллельно: поток A удаляет элемент с ключом 3, поток B вставляет ключ 4:
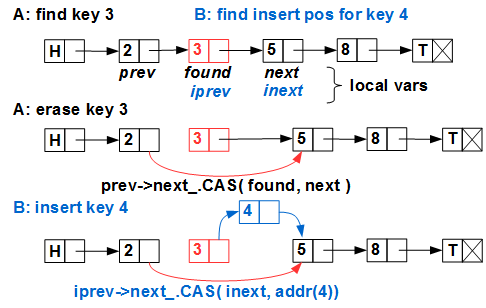
Потоки A и B одновременно выполняют поиск; при этом они запоминают в локальных переменных найденную позицию для удаления (A) и для вставки (B). Затем поток A благополучно удалил 3 из списка, поток B в это время, например, был
iprev и inext в списке — и он выполняет атомарный примитив CAS по вставке элемента — куда? После элемента с ключом 3, который уже исключен из списка! (Hazard Pointer / RCU нам гарантируют, что элемент 3 ещё не удален физически, то есть «обращение к мусору» мы не получим, но 3 уже исключен из списка потоком A). Все выполнилось без ошибок, в результате элемент с ключом 4 потерян и вдобавок мы получили утечку памяти.Элегантное решение этой проблемы нашел T.Harris в 2001 году. Он предложил двухфазное удаление элемента: первая фаза — логическое удаление — помечает элемент как удаленный, не исключая его из списка, вторая фаза — физическое исключение — исключает элемент из списка (а третья фаза — физическое удаление — выполняется схемой безопасного удаления памяти — Hazard Pointer, RCU или подобной). Смысл логического удаления — пометить удаляемый элемент таким образом, чтобы CAS на нем не сработал. Для этого Harris предложил использовать младший бит указателя
next элемента. Действительно, в современных архитектурах (как процессорах, так и ОС) данные выравнены по границе 4 (для 32bit) или 8 (для 64bit) байт, поэтому младшие 2 или 3 бита любого указателя всегда равны нулю и их можно использовать как битовые флаги. Такой трюк получил имя собственное marked pointer и широко применяется в lock-free программировании.С использованием marked pointer параллельные вставка/удаление выглядит так:
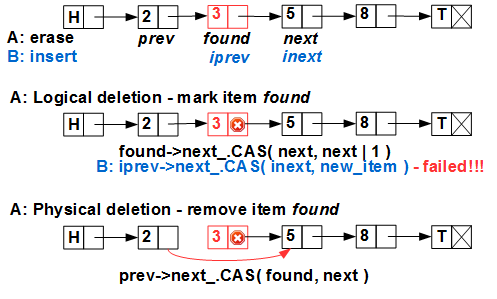
Поток A помечает элемент 3 как логически удаленный — выставляет младший бит указателя
found->next в единицу. Теперь поток B, попытавшись вставить 4 после 3, потерпит неудачу — CAS не сработает, так как мы считаем, что указатель 3.next не помеченный.Цена метода marked pointer – дополнительный вызов CAS при удалении элемента.
Может показаться, что все вышеописанное излишне и гораздо быстрее и проще просто присвоить указателю
next удаляемого элемента значение nullptr – тогда CAS на вставке не сработает. Да, проще, но это две независимые операции: одна — исключение, другая — обнуление next. А раз две операции, то между ними может кто-то вклиниться и вставить новый элемент после уже исключенного. Тем самым мы лишь снижаем вероятность ошибки, но не исключаем её. Гримасы lock-free: все должно быть сделано по возможности атомарно, но в любом случае — не нарушая внутреннюю структуру контейнера.
Исторический экскурс
Интересна эволюция алгоритма Harris'а для lock-free ordered list. Оригинальный алгоритм выделяется тем, что для него в принципе не применима схема Hazard Pointer. Дело в том, что алгоритм Harris'а предполагает физическое удаление цепочки связанных узлов списка, в принципе, бесконечной. Как мы знаем, схема Hazard Pointer требует сначала защитить удаляемые элементы, объявив их как hazard, а уж только затем что-то с ними делать. Но количество hazard pointer'ов ограничено, мы не сможем защитить всю безразмерную цепочку элементов!
M.Michael, разрабатывая Hazard Pointer, выявил эту принципиальную неприменимость своей схемы к изящному алгоритму Harris'а и предложил свою модификацию, которая также использует двухфазное удаление — прием marked pointer, — но удаляет элементы по одному, тем самым сделав допустимым использование Hazard Pointer.
Существует еще одна модификация этого алгоритма, решающая задачу возобновления поиска. Как я неоднократно подчеркивал, все lock-free алгоритмы — это бесконечный цикл «долбежка до тех пор, пока не получится». Описывая выше интересные ситуации я не упомянул, что требуется делать, когда CAS не сработал. На самом деле все просто: если CAS на вставке/удалении не сработал, мы должны снова пытаться выполнить вставку/удаление с самого начала — с поиска позиции — до тех пор, пока мы либо не выполним операцию, либо не поймем, что выполнить её невозможно (для вставки — потому что ключ уже есть в списке, для удаления — потому что ключа нет в списке). Возобновление операции с начала списка — вещь дорогая, если список длинный (а мы далее увидим, что на основе описанного здесь списка можно построить довольно эффективный алгоритм упорядоченного контейнера, поддерживающий миллионы элементов), поэтому приходит мысль: а что если начинать повторный поиск не с начала, а с некоего предыдущего элемента? Но понятие «предыдущий» в вечно меняющемся мире lock-free очень зыбко. Фомичев в своей диссертации предлагает добавить в каждый элемент lock-free списка back-reference на какой-то предыдущий элемент и описывает приемы работы с этими указателями и поддержки их в актуальном состоянии, довольно сложные.
Ну и до кучи — существует оригинальный алгоритм упорядоченного списка, основанный на fine-grained блокировках на уровне каждого элемента — lazy list. Он также реализован в libcds. Несмотря на его lock-based природу, hash map, построенный на нем, не намного уступает разобранному в данной статье lock-free аналогу. В качестве мьютексов он по умолчанию использует spin-lock'и.
M.Michael, разрабатывая Hazard Pointer, выявил эту принципиальную неприменимость своей схемы к изящному алгоритму Harris'а и предложил свою модификацию, которая также использует двухфазное удаление — прием marked pointer, — но удаляет элементы по одному, тем самым сделав допустимым использование Hazard Pointer.
Существует еще одна модификация этого алгоритма, решающая задачу возобновления поиска. Как я неоднократно подчеркивал, все lock-free алгоритмы — это бесконечный цикл «долбежка до тех пор, пока не получится». Описывая выше интересные ситуации я не упомянул, что требуется делать, когда CAS не сработал. На самом деле все просто: если CAS на вставке/удалении не сработал, мы должны снова пытаться выполнить вставку/удаление с самого начала — с поиска позиции — до тех пор, пока мы либо не выполним операцию, либо не поймем, что выполнить её невозможно (для вставки — потому что ключ уже есть в списке, для удаления — потому что ключа нет в списке). Возобновление операции с начала списка — вещь дорогая, если список длинный (а мы далее увидим, что на основе описанного здесь списка можно построить довольно эффективный алгоритм упорядоченного контейнера, поддерживающий миллионы элементов), поэтому приходит мысль: а что если начинать повторный поиск не с начала, а с некоего предыдущего элемента? Но понятие «предыдущий» в вечно меняющемся мире lock-free очень зыбко. Фомичев в своей диссертации предлагает добавить в каждый элемент lock-free списка back-reference на какой-то предыдущий элемент и описывает приемы работы с этими указателями и поддержки их в актуальном состоянии, довольно сложные.
Ну и до кучи — существует оригинальный алгоритм упорядоченного списка, основанный на fine-grained блокировках на уровне каждого элемента — lazy list. Он также реализован в libcds. Несмотря на его lock-based природу, hash map, построенный на нем, не намного уступает разобранному в данной статье lock-free аналогу. В качестве мьютексов он по умолчанию использует spin-lock'и.
Итак, мы разобрали алгоритм lock-free упорядоченного списка, с помощью которого можно реализовать lock-free hash map. Недостаток этого алгоритма – он не предусматривает rehashing'а, то есть нам априори надо знать предполагаемое число элементов S в таком контейнере и оптимальный load factor. Тогда размер N хеш-таблицы
T[N] равен S / load factor. Тем не менее, несмотря на эти ограничения, точнее, благодаря им, такой алгоритм является одним из самых быстрых и масштабируемых, так как нет накладных расходов на rehashing.По результатам моих экспериментов, хорошим значением load factor является 2 – 4, то есть каждый lock-free список коллизий в среднем содержит 2 – 4 элемента. При load factor = 1 (список коллизий состоит из одного элемента в среднем) результаты чуть лучше, но больше накладные расходы по памяти на фактически вырожденные списки коллизий.
В следующей статье мы рассмотрим алгоритм, весьма оригинально поддерживающий rehashing и основанный на lock-free ordered list, описанном здесь.
Lock-free структуры данных

