Данная статья в некотором роды выжимка того, что Вы могли бы узнать просмотрев разные видео ролики господина Шипилева, Елизарова, Смирнова. Собственно мы даже собрали для Вас плейлист если Вы захотите пойти «the hard way». В статье я лишь попробую Вам передать некоторые основные мысли/идеи, которые при желании Вы сможете намного более глубоко изучить в первоисточниках.
Итак, давайте теперь перейдем к собственно сабжу. Еще лет пять назад можно было не сильно «парясь» выдавать на-гора однопоточные программы, которые с трудом запускались на топовом железе и знать, что через год-два этот кусочек “программки” (простите за аллегорию) начнет работать нормально. Сегодня подобный «бесплатный обед» закончился.
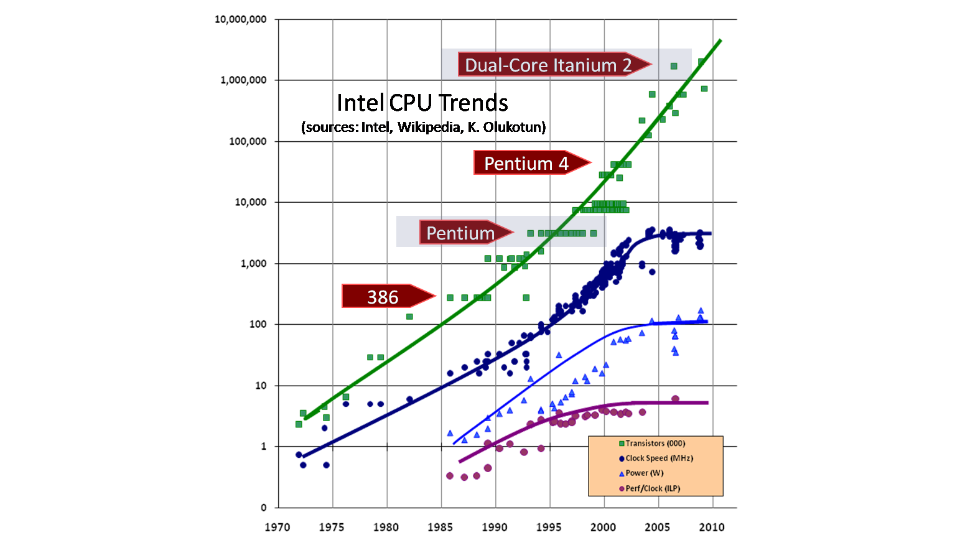
На картинке четко видно, что количество транзисторов все еще растет, но с точки зрения частот мы практически достигли потолка. «Кривизну» рук разработчиков уже трудно компенсировать тем, что через год железо станет работать в два раза быстрее. Хотя не все так печально, процессоры пока еще растут, только с точки зрения количество ядер. Как следствие, для того чтобы «программка», написанная криворуким орком, смогла хоть как-то нормально работать на новом железе, нужно чтобы она нормально работала в многопроцессорной среде. А производительность была напрямую связана с количеством ядер на железе. Вот собственно от том, а что же такое «нормально работала многопроцессорной среде» мы и поговорим далее.
Ответа может быть два. Первый, если Вы пишите под конкретное железо, под Intel Xeon, или не дай Бог Itanium или Эльбрус, Ваш код будет совершенно разный и заточен под конкретное железо. Такой код будет выжимать все из железки, но будет очень слабо масштабируем. Это подходит, когда пишите 3D игры под конкретную железку и нужно выжать все из сегодняшнего железа, PS4 например, и не ждать мифического завтра. А что делать обычным программистам, которые штопают “Хайль Мир” под абстрактные платформы в вакууме и не сильно понимают разницу между VLIW архитектурой ЦПУ и RISC? Им же тоже нужно как-то программировать многопоточные программы, чтобы они и на сегодняшнем железе работали продуктивно, а на завтрашнем (новом железе) чтобы работали еще быстрее. И этот кусок программы, который смог бы работать и на швейной машинке «Зингер», всё же после “умелой” имплементации мог бы быть запущен на кластере.
Ни так как быть программистам? Любую проблему можно решить как? Правильно, путем добавлением нового уровня абстракции. Само собой эта ситуация не исключение. На помощь программистам приходит абстрактная машина (АМ), под которую на самом деле и пишет код большая часть программистов. АМ это по факту трейдофф между желаниями инженеров меньше знать и использовать максимально упрощенно-высокоуровневые концепции (привет FP), в которых живут пони и какают радугами и конкретной реальной железной реализацией. Она (АМ) говорит, что отныне, Вы программисты не пишите под конкретное железо, Вы пишите под абстрактную машину (Вы все пишите под абстрактную машину!) у которой есть абстрактная память и эта память работает по описанной memory model. А уже компилятор, JIT, интерпретатор или Бог знает кто еще будет отвечать за то, чтобы замапить код/байткод/etc, созданный для абстрактной машины, на конкретную имплементацию. То есть, пишите Вы, например, на С++ код, замечу, под абстрактную машину (я упомянул С++ потому что в его спеке, как минимум С++11, очень стройно и четко описана memory model), а уже у компилятора задача будет перевести это в рабочий машинный код под конкретное железо, ну например на Inantium (с архитектурой VLIW) или на CISC процессоры. Понятное дело, что разные части Вашей программы будут при этом показывать разную производительность на разных платформах.
Само собой, если Вы хотите выжать максимум производительности из Вашего кода, то так или иначе, Вам придется выкинуть ко всем чертям все эти уровни абстракции и переписать все на том, что максимально близко к железу в данный момент времени. Конечно же это работает если проблемы именно на уровне близком к железу, ибо если у Вас медленный алгоритм то добавлять в него усложнения переписывая это на низком уровне вряд ли спасет положение. Но речь как раз и не о тех задачах где такой “бэр метал” необходим. Речь все же об “абстрактных программистах”. Возвращаясь к абстракции, вопрос, почему в абстрактной машине мы выделяем именно ММ и почему это вдруг стало актуально именно в последние годы? Описать абстрактную машину получалось давно и работы на эти темы велись, но мало кому были нужны. Дело в том, что ранее при преобладании однопоточной среды все программы, так или иначе, были детерминированы. Как говорил Шипилёв, для прагматического программиста ММ должна дать ответ на всего один вопрос: если я сейчас прочту в потоке переменную А, то результат какой из последних записей (если запись была не одна) я смогу увидеть?
В детерминированной однопоточной программе все это достаточно просто определить даже не зная ММ языка на котором пишешь. Программа может быть полностью поломана для многоядерной архитектуры, но кому это важно, если на дворе суровые девяностые, а машины с более чем одним процессором это суперкомпьютеры? Более того, когда появлялись первые возможности распараллелить программу P4HT, то они давали свои либы и свое видение параллельности и соответственно первопроходцы, как правило, писали код не под 2-3 абстрактных потока, а под P4HT, что само собой было не масштабируемо.
Давайте “ближе к телу”. Если мы собираемся давать ответы на вопросы о том, что же мы сможем прочесть из памяти, то посмотрим на наивную ММ, как ее себе представляют многие из нас.

Эта система не учитывает того, насколько медленно распространяется свет! Именно медленно, несмотря на то, что нас всегда учили, что свет достаточно быстр, есть пару условий. Он не так уж и быстр, а если мы говорим не об идеальных условиях в вакууме то…
Если у Вас есть 3 ГГц процессор, то свет за его один такт проходит 10 см, в проводниках и того меньше. Как результат, процессоры физически не способны сделав изменения с переменной донести информацию об этих изменениях до остальных процессоров. На практике же мы можем получить следующие варианты (это без прошлых вариантов, но они тоже в силе). Самый, обычно сбивающий с толку, вариант это 0х0.

Это вообще супер забавно так как мы, по сути, наблюдаем в некоторой изощренной форме эффект искажения времени на больших скоростях. Само собой странные результаты появляются из-за того как ядра процессоров синхронизируют данные между собой. Но насколько это круто осознавать что у нас, программистов есть свои процессы которые в некотором роде напоминают релятивистскую физику =) У нас есть два ЦПУ, они как бы находятся независимо друг от друга и внутри их происходит физический обмен данными и из-за разных ограничений они видят друг друга по разному, то что один видит как настоящее (переменная «a» равна нулю, второй ЦПУ видит как прошлое, так как для него эта переменная равна уже -1). Само собой, рассинхронизация вызвана не столь скоростями, подобные проблемы появились из-за усложнения процессоров. И в самом деле, если Мы будем думать с этой стороны нам все эти парадоксы очень легко визуализировать на слегка модифицированном примере.

Если посмотреть на то, как поток 2 видит поток 1, то он может увидеть что угодно. Во вселенной потока 2, поток 1 может, например, сделать только write a, т.е. write b может вообще не наступить. Может увидеть только write b, write a может вообще не наступить. Может увидеть write a write b, но при этом их последовательность может совершенно другой, не такой как внутри потока 1.

Как не трудно догадаться, результаты будут совершенно непредсказуемые.

В ранних версиях Java было довольно много того, что называлось “багами”. На самом деле, толпы наивных леммингов совершенно не понимая ограничений ММ писали код, который на практике уходил в вечные циклы. Хотя на самом деле Java просто применяла ряд оптимизаций, так как наивно думала, что разработчик знает, что он пишет.
Написали прекрасную программку, протестили на х86_64, после запускаете на 32х битном ARM (или PowerPC) и получаете ситуации с сюрпризами. А все потому, что писал наш Вася Пупкин под конкретное железо на котором он и тестировал, хотя на самом деле, не понимая он писал под Абстрактную Машину, спецификация которой дает другие гарантии (более слабые), чем конкретная машинка под которую он писал свой код. Само собой, осознание того, что он пишет под абстрактную машину, спеку которой надо знать, после таких поломок придет, но придет очень поздно, когда Ваш код вдруг перестанет работать у клиента на машине.
Как нам ММ поможет собственно разобраться с вот этой создавшейся кашей и беспределом? Одно из фундаментальнейших понятий в ММ это понятие HappensBefore, введенное Лампортом еще в далеком 1978 году. По простому он говорит, да у нас каша, беспредел и рукоблудие, но давайте из всего этого разброда и шатания выделим несколько операций, которые между собой будут упорядочены. Это означает, что у нас будут две операции между потоками при которых мы точно можем сказать, что одна операция будет строго упорядочена со второй операцией во втором потоке. Для наглядности этой операции можно вернуться к нашему бутафорскому примеру.

И наконец, для того чтобы более наглядно понять, как часто подобные примеры таки происходят и на каких платформах, увидеть наглядно ровно ту ситуацию, о которой я говорил, когда Вы работаете на своей локальной машинке и все работает, просто потому что вы пишете не для абстрактной машины, а для конкретного железа, рекомендую посмотреть доклад Глеба Смирнова: “Многопоточность под капотом”. Хотя перед этим взгляните на общетеоретический доклад Романа Елизарова и само собой Шипилева. Все эти доклады мы аккуратно собрали для Вас в плей-лист, чтобы Вы могли просто весь его просмотреть. Мы для Вас даже отсортировали доклады.
Итак, давайте теперь перейдем к собственно сабжу. Еще лет пять назад можно было не сильно «парясь» выдавать на-гора однопоточные программы, которые с трудом запускались на топовом железе и знать, что через год-два этот кусочек “программки” (простите за аллегорию) начнет работать нормально. Сегодня подобный «бесплатный обед» закончился.
На картинке четко видно, что количество транзисторов все еще растет, но с точки зрения частот мы практически достигли потолка. «Кривизну» рук разработчиков уже трудно компенсировать тем, что через год железо станет работать в два раза быстрее. Хотя не все так печально, процессоры пока еще растут, только с точки зрения количество ядер. Как следствие, для того чтобы «программка», написанная криворуким орком, смогла хоть как-то нормально работать на новом железе, нужно чтобы она нормально работала в многопроцессорной среде. А производительность была напрямую связана с количеством ядер на железе. Вот собственно от том, а что же такое «нормально работала многопроцессорной среде» мы и поговорим далее.
Ответа может быть два. Первый, если Вы пишите под конкретное железо, под Intel Xeon, или не дай Бог Itanium или Эльбрус, Ваш код будет совершенно разный и заточен под конкретное железо. Такой код будет выжимать все из железки, но будет очень слабо масштабируем. Это подходит, когда пишите 3D игры под конкретную железку и нужно выжать все из сегодняшнего железа, PS4 например, и не ждать мифического завтра. А что делать обычным программистам, которые штопают “Хайль Мир” под абстрактные платформы в вакууме и не сильно понимают разницу между VLIW архитектурой ЦПУ и RISC? Им же тоже нужно как-то программировать многопоточные программы, чтобы они и на сегодняшнем железе работали продуктивно, а на завтрашнем (новом железе) чтобы работали еще быстрее. И этот кусок программы, который смог бы работать и на швейной машинке «Зингер», всё же после “умелой” имплементации мог бы быть запущен на кластере.
Ни так как быть программистам? Любую проблему можно решить как? Правильно, путем добавлением нового уровня абстракции. Само собой эта ситуация не исключение. На помощь программистам приходит абстрактная машина (АМ), под которую на самом деле и пишет код большая часть программистов. АМ это по факту трейдофф между желаниями инженеров меньше знать и использовать максимально упрощенно-высокоуровневые концепции (привет FP), в которых живут пони и какают радугами и конкретной реальной железной реализацией. Она (АМ) говорит, что отныне, Вы программисты не пишите под конкретное железо, Вы пишите под абстрактную машину (Вы все пишите под абстрактную машину!) у которой есть абстрактная память и эта память работает по описанной memory model. А уже компилятор, JIT, интерпретатор или Бог знает кто еще будет отвечать за то, чтобы замапить код/байткод/etc, созданный для абстрактной машины, на конкретную имплементацию. То есть, пишите Вы, например, на С++ код, замечу, под абстрактную машину (я упомянул С++ потому что в его спеке, как минимум С++11, очень стройно и четко описана memory model), а уже у компилятора задача будет перевести это в рабочий машинный код под конкретное железо, ну например на Inantium (с архитектурой VLIW) или на CISC процессоры. Понятное дело, что разные части Вашей программы будут при этом показывать разную производительность на разных платформах.
Само собой, если Вы хотите выжать максимум производительности из Вашего кода, то так или иначе, Вам придется выкинуть ко всем чертям все эти уровни абстракции и переписать все на том, что максимально близко к железу в данный момент времени. Конечно же это работает если проблемы именно на уровне близком к железу, ибо если у Вас медленный алгоритм то добавлять в него усложнения переписывая это на низком уровне вряд ли спасет положение. Но речь как раз и не о тех задачах где такой “бэр метал” необходим. Речь все же об “абстрактных программистах”. Возвращаясь к абстракции, вопрос, почему в абстрактной машине мы выделяем именно ММ и почему это вдруг стало актуально именно в последние годы? Описать абстрактную машину получалось давно и работы на эти темы велись, но мало кому были нужны. Дело в том, что ранее при преобладании однопоточной среды все программы, так или иначе, были детерминированы. Как говорил Шипилёв, для прагматического программиста ММ должна дать ответ на всего один вопрос: если я сейчас прочту в потоке переменную А, то результат какой из последних записей (если запись была не одна) я смогу увидеть?
В детерминированной однопоточной программе все это достаточно просто определить даже не зная ММ языка на котором пишешь. Программа может быть полностью поломана для многоядерной архитектуры, но кому это важно, если на дворе суровые девяностые, а машины с более чем одним процессором это суперкомпьютеры? Более того, когда появлялись первые возможности распараллелить программу P4HT, то они давали свои либы и свое видение параллельности и соответственно первопроходцы, как правило, писали код не под 2-3 абстрактных потока, а под P4HT, что само собой было не масштабируемо.
Давайте “ближе к телу”. Если мы собираемся давать ответы на вопросы о том, что же мы сможем прочесть из памяти, то посмотрим на наивную ММ, как ее себе представляют многие из нас.
Эта система не учитывает того, насколько медленно распространяется свет! Именно медленно, несмотря на то, что нас всегда учили, что свет достаточно быстр, есть пару условий. Он не так уж и быстр, а если мы говорим не об идеальных условиях в вакууме то…
За один такт 3ГГЦ процессора, свет в вакууме проходит 10см!
Роман Елизаров
Если у Вас есть 3 ГГц процессор, то свет за его один такт проходит 10 см, в проводниках и того меньше. Как результат, процессоры физически не способны сделав изменения с переменной донести информацию об этих изменениях до остальных процессоров. На практике же мы можем получить следующие варианты (это без прошлых вариантов, но они тоже в силе). Самый, обычно сбивающий с толку, вариант это 0х0.
Это вообще супер забавно так как мы, по сути, наблюдаем в некоторой изощренной форме эффект искажения времени на больших скоростях. Само собой странные результаты появляются из-за того как ядра процессоров синхронизируют данные между собой. Но насколько это круто осознавать что у нас, программистов есть свои процессы которые в некотором роде напоминают релятивистскую физику =) У нас есть два ЦПУ, они как бы находятся независимо друг от друга и внутри их происходит физический обмен данными и из-за разных ограничений они видят друг друга по разному, то что один видит как настоящее (переменная «a» равна нулю, второй ЦПУ видит как прошлое, так как для него эта переменная равна уже -1). Само собой, рассинхронизация вызвана не столь скоростями, подобные проблемы появились из-за усложнения процессоров. И в самом деле, если Мы будем думать с этой стороны нам все эти парадоксы очень легко визуализировать на слегка модифицированном примере.
Если посмотреть на то, как поток 2 видит поток 1, то он может увидеть что угодно. Во вселенной потока 2, поток 1 может, например, сделать только write a, т.е. write b может вообще не наступить. Может увидеть только write b, write a может вообще не наступить. Может увидеть write a write b, но при этом их последовательность может совершенно другой, не такой как внутри потока 1.
Как не трудно догадаться, результаты будут совершенно непредсказуемые.
В ранних версиях Java было довольно много того, что называлось “багами”. На самом деле, толпы наивных леммингов совершенно не понимая ограничений ММ писали код, который на практике уходил в вечные циклы. Хотя на самом деле Java просто применяла ряд оптимизаций, так как наивно думала, что разработчик знает, что он пишет.
Написали прекрасную программку, протестили на х86_64, после запускаете на 32х битном ARM (или PowerPC) и получаете ситуации с сюрпризами. А все потому, что писал наш Вася Пупкин под конкретное железо на котором он и тестировал, хотя на самом деле, не понимая он писал под Абстрактную Машину, спецификация которой дает другие гарантии (более слабые), чем конкретная машинка под которую он писал свой код. Само собой, осознание того, что он пишет под абстрактную машину, спеку которой надо знать, после таких поломок придет, но придет очень поздно, когда Ваш код вдруг перестанет работать у клиента на машине.
Как нам ММ поможет собственно разобраться с вот этой создавшейся кашей и беспределом? Одно из фундаментальнейших понятий в ММ это понятие HappensBefore, введенное Лампортом еще в далеком 1978 году. По простому он говорит, да у нас каша, беспредел и рукоблудие, но давайте из всего этого разброда и шатания выделим несколько операций, которые между собой будут упорядочены. Это означает, что у нас будут две операции между потоками при которых мы точно можем сказать, что одна операция будет строго упорядочена со второй операцией во втором потоке. Для наглядности этой операции можно вернуться к нашему бутафорскому примеру.
И наконец, для того чтобы более наглядно понять, как часто подобные примеры таки происходят и на каких платформах, увидеть наглядно ровно ту ситуацию, о которой я говорил, когда Вы работаете на своей локальной машинке и все работает, просто потому что вы пишете не для абстрактной машины, а для конкретного железа, рекомендую посмотреть доклад Глеба Смирнова: “Многопоточность под капотом”. Хотя перед этим взгляните на общетеоретический доклад Романа Елизарова и само собой Шипилева. Все эти доклады мы аккуратно собрали для Вас в плей-лист, чтобы Вы могли просто весь его просмотреть. Мы для Вас даже отсортировали доклады.

