Введение
Приветствую вас, заинтересованные читающие разработчики на не важно каких языках, на которых я ориентирую эти статьи и чьи поддержку и мнения я ценю.
Для начала, по устоявшимся традициям, я приведу ссылки на предыдущие статьи:
Часть 1: пишем языковую ВМ
Часть 2: промежуточное представление программ
Для формирования в вашей голове полного понимания того, что в этих статьях мы пишем, вам стоит заранее ознакомиться с предыдущими частями.
Также мне стоит разместить сразу ссылку на статью о проекте, который был написан мной ранее и на основе которого идет весь этот разбор полётов: Клац сюды. С ним пожалуй стоит ознакомиться первым делом.
И немного о проекте:
→ Небольшой сайт проекта
→ GitHub репозиторий
Ну и также скажу сразу, что все написано на Object Pascal, а именно — на FPC.
Итак, начнем.
Принцип работы большинства трансляторов
Первым делом, стоит понимать что я не смог бы ничего путного написать, предварительно не ознакомившись с кучей теоретического материала и рядом статеек. Опишу основное в паре слов.
Задача транслятора первым делом — подготовить код к анализу (например удалить из него комментарии) и разбить код на токены (токен — минимальный значащий для языка набор символов).
Далее нужно путем анализа и преобразований разобрать код в некое промежуточное представление и затем уже собрать готовое к выполнению приложение или… Что там ему в общем нужно собрать.
Да, этой кучей текста я ничего толком то и не сказал, однако — сейчас задача разбита на несколько подзадач.
Пропустим то, как код подготавливается к выполнению, т.к. это слишком скучный для описания процесс. Предположим, что мы имеем уже готовый к анализу набор токенов.
Анализ кода
Вы могли слышать о построении дерева кода и его анализа или ещё более заумные вещи. Как всегда — это не более чем загромождение простого страшными терминами. Под анализом кода я понимаю гораздо более простой набор действий. Задача — пробежаться по списку токенов и разобрать код, каждую его конструкцию.
Как правило, в императивных языках код уже представлен в виде своеобразного дерева из конструкций.
Согласитесь, не приемлемо допустим начинать цикл «A» в теле цикла «B», а заканчивать — вне тела цикла «B». Код представляет собой структуру, состоящую из набора конструкций.
А что есть у каждой конструкции? Правильно — начало и конец (и возможно ещё что-то посередине, но не суть).
Соответственно, разбор кода можно сделать однопроходным, толком без построения дерева.
Для этого нужен цикл, который будет пробегать по коду и большущий switch-case, который будет выполнять основной разбор кода и анализ.
Т.е. пробегаем по токенам, перед нами токен (например пусть будет...) «if» — очень уж сомневаюсь, что такой токен может стоять в коде просто так -> это начало конструкции if..then[..else]..end!
Выполняем разбор всех последующих токенов, соответствующим образом для конструкции условий в нашем языке.
Немного об ошибках в коде
На этапе разбора конструкций и пробега по коду, на обработку ошибок лучше не забивать. Это полезный функционал транслятора. Если в ходе разбора конструкции возникает ошибка, то логично — конструкция построена не должным образом и следует уведомить об этом разработчика.
Теперь о Mash. Как происходит разбор языковых конструкций?
Выше я описал обобщенный концепт устройства транслятора. Теперь настало время поговорить о моих наработках.
По сути транслятор получился очень даже похожим на описанное выше. Но у меня он не разбивает код на кучу токенов для дальнейшего анализа.
Перед началом разбора код приводится в более красивый вид. Удаляются комментарии и все конструкции соединяются в длинные строки, если они описаны в несколько строк.
Таким образом, в каждой отдельно взятой строке находится языковая конструкция либо её часть. Это классно, теперь мы можем разбирать каждую строку в нашем большом switch-case, вместо поиска этих конструкций в наборе токенов. Также плюсом тут выступает то, что строка имеет конец и значит определять ошибки в конструкции с таким подходом проще.
Соответственно разбор отдельных конструкций происходит отдельными методами, которые возвращают промежуточное представление кода конструкций или её частей.
П.с. в предыдущей статье я описал построение транслятора с промежуточного языка в байткод для ВМ. Собственно — этот промежуточный язык и является промежуточным представлением.
Стоит понимать, что конструкции могут состоять из нескольких более простых конструкций. Т.к. у нас разбор каждой конструкции описан отдельными методами, то мы можем без проблем вызывать их друг из друга при разборе каждой конструкции.
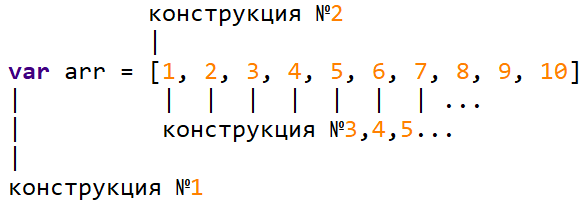
Разминочная пробежка по коду
Для начала транслятору стоит бегло ознакомиться с кодом, пробежавшись по нему и уделив внимание некоторым конструкциям.
На этом этапе можно разобраться с глобальными переменными, uses конструкциями, а также импортами, процедурами & функциями и ООП конструкциями.
Промежуточное представление лучше генерировать в несколько объектов для хранения, чтобы
код для глобальных переменных вставить после инициализации, но перед началом выполнения main().
Код для ООП конструкций можно вставить в конце.
Сложные конструкции
Ок, с простыми конструкциями мы разобрались. Теперь пришло время сложных. Не думаю, что вы успели забыть пример с двумя циклами. Как мы знаем, конструкции обычно идут в виде некого дерева. А это значит, что мы можем разбирать сложные конструкции используя стек.
При чем тут стек? Притом.
Опишем сначала класс, который будем запихивать в стек. При разборе сложных конструкций мы можем генерировать промежуточное представление для начала и конца этого блока, так, например, происходит разбор цикла for, while, until, конструкций if, методов да и вообще всего в языке Mash.
Этому классу нужны поля для хранения промежуточных представлений, мета информации (Для некоторых вариативных конструкций) и, конечно же — для хранения типа блока.
Просто приведу код целиком, потому что его тут не много:
unit u_prep_codeblock; {$mode objfpc}{$H+} interface uses Classes, SysUtils; type TBlockEntryType = (btProc, btFunc, btIf, btFor, btWhile, btUntil, btTry, btClass, btSwitch, btCase); TCodeBlock = class(TObject) public bType: TBlockEntryType; mName, bMeta, bMCode, bEndCode: string; constructor Create(bt: TBlockEntryType; MT, MC, EC: string); end; implementation constructor TCodeBlock.Create(bt: TBlockEntryType; MT, MC, EC: string); begin inherited Create; bType := bt; bMeta := MT; bMCode := MC; bEndCode := EC; end; end.
Ну и стек — простой TList, изобретать велосипед тут просто глупо.
Таким образом, разбор конструкции, допустим того же while цикла выглядит так:
function ParseWhile(s: string; varmgr: TVarManager): string; var WhileNum, ExprCode: string; begin Delete(s, 1, 5); //"while" Delete(s, Length(s), 1); //":" s := Trim(s); //Циклов в коде много, а в промежуточном представлении структуры кода нету... //Нужно точки входа все же отличать как то :) WhileNum := '__gen_while_' + IntToStr(WhileBlCounter); Inc(WhileBlCounter); //Номер очередной конструкции while в коде //Метод проверяет, является ли строка логическим или математическим выражением if IsExpr(s) then ExprCode := PreprocessExpression(s, varmgr) else ExprCode := PushIt(s, varmgr); //Теперь в ExprCode лежит промежуточное представление выражения //Результат после выполнения будет лежать в вершине стека //Проверка условия перед итерацией //(промежуточное представление ставится на место начала конструкции) Result := WhileNum + ':' + sLineBreak + 'pushcp ' + WhileNum + '_end' + sLineBreak + ExprCode + sLineBreak + 'jz' + sLineBreak + 'pop'; //Ну и соответственно генерация кода на завершение конструкции //Последний аргумент - название точки входа на выход из цикла //нужен для генератора break BlockStack.Add(TCodeBlock.Create(btWhile, '', 'pushcp ' + WhileNum + sLineBreak + 'jp' + sLineBreak + WhileNum + '_end:', WhileNum + '_end')); end;
Про математические выражения
Возможно вы могли этого не замечать, но математические/логические выражения — это тоже структурированный код.
Их разбор я реализовывал стековым путем. Сначала все отдельные элементы выражения ложатся в стек, затем в несколько проходов генерируется код промежуточного представления.
В несколько раз — т.к. есть приоритетные математические операции, такие как умножение.
Код тут приводить не вижу смысла, т.к. его много и он скучный.
П.с. /lang/u_prep_expressions.pas — тут он целиком и полностью выставлен на ваше обозрение.
Итоги
Итак, мы реализовали транслятор, который может преобразовать… Например такой вот код:
proc PrintArr(arr): for(i ?= 0; i < len(arr); i++): PrintLn("arr[", i, "] = ", arr[i]) end end proc main(): var arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] PrintArr(arr) InputLn() end
Чего же не хватает нашему языку? Правильно, поддержки ООП. Об этом мы и поговорим в следующей моей статье.
Спасибо, что дочитали до конца, если вы это сделали.
Если вам что-то не понятно, то я жду ваших комментариев. Или вопросов на форуме, да-да… Я его иногда проверяю.
А теперь небольшой опрос (чтобы я смотрел на него и радовался значимости своих статей):
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Была ли эта статья вам интересна?
56.36%Да.31
30.91%Да, но ничего особенного нового я не узнал.17
12.73%Нет.7
Проголосовали 55 пользователей. Воздержались 12 пользователей.

