
И снова я несколько переоценил объем статьи! Планировал, что это будет заключительная статья, где сделаем компилятор и выполним тестирование. Но объем оказался велик, и я решил разбить статью на две.
В этой статье мы сделаем практически все основные функции компилятора. Он уже оживет, и можно будет писать, компилировать и выполнять достаточно серьезный код. А тестирование сделаем в следующей части. (Кстати, предыдущие части: раз, два, три).
Я впервые пишу на Хабре, возможно, получается не всегда все хорошо. На мой взгляд, статьи 2, 3 получились довольно сухими, много кода, мало описания. В этот раз я постараюсь сделать по другому, сосредоточиться на описании самих идей. Ну а код… код, конечно будет! Кто захочет разобраться досконально, такая возможность будет. В многих случаях я помещу код под спойлер. И, конечно, всегда можно заглянуть в полный исходник на гитхабе.
Компилятор продолжим писать некоторое время на ассемблере, но потом перейдем на форт и продолжим писать компилятор на самом себе. Это будет напоминать барона Мюнхаузена, который вытаскивал сам себя за волосы из болота. Но, для начала, я расскажу в общих чертах, как устроен компилятор на форте. Добро пожаловать под кат!
Как устроен компилятор
Память в форте состоит из непрерывного фрагмента, в котором последовательно расположены словарные статьи. После их окончания следует свободная область памяти. На первый свободный байт указывает переменная h. Еще есть часто используемое слово here, которое кладет на стек адрес первого свободного байта, оно определяется очень просто:
: here h @ ;
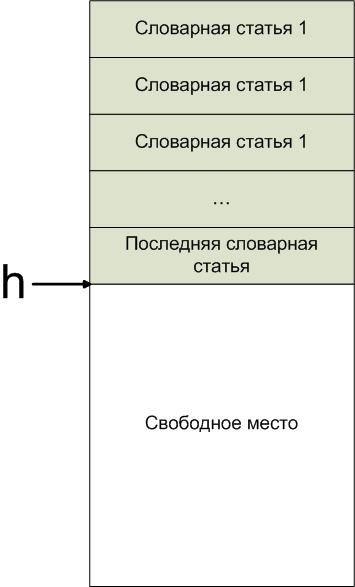
Стоит упомянуть слово allot, которое резервирует указанное количество байт, перемещая указатель h. Слово allot можно определить так:
: allot h +! ;
Фактически, компилятор использует особый режим интерпретатора плюс некоторые специальные слова. Вот так, одним предложением, можно описать весь принцип работы компилятора в форте. В каком режиме работает интерпретатор определяет переменная state. Если она равна нулю, то установлен режим исполнения, иначе — режим компиляции. С режимом исполнения мы уже знакомы, в нем слова из входного буфера просто исполняются друг за другом. А в режиме компиляции они не исполняются, а компилируются в память по указателю h. Соответственно, указатель при этом передвигается вперед.
В классическом форте для компиляции целого значения используется слово ",", для компиляции байта — слово «с,». В нашей системе используются значения разной разрядности (8, 16, 32, 64), поэтому сделаем дополнительно слова «w,» и «i,». Так же сделаем слово «str,», которое будет компилировать строку, принимая со стека два значения — адрес и длину строки.
Специальные слова компилятора используются для формирования управляющих конструкций. Это слова if, then, do, loop, и другие. Эти слова исполняются даже в режиме компиляции. Например, слово if при исполнении компилирует байт-команду условного перехода (?nbranch). Что бы система знала, какие слова нужно исполнять в режиме компиляции, а не компилировать, используется флаг (признак) immediate. Он уже у нас есть в поле флагов словарной статьи. В исходном коде на ассемблере он называется f_immediate. Для установки этого флага служит слово immediate. Оно не имеет параметров, флаг immediate устанавливается у последнего слова в словаре.
А теперь перейдем от теории к практике!
Подготовка
В начале нужно сделать на ассемблере некоторые простые байт-команды, которые нам понадобятся. Вот они: move (копирование области памяти), fill (заполнение области памяти), битовые операции (and, or, xor, invert), команды битового сдвига (rshift, lshift). Сделаем так же rpick (это то же, что pick, только работает со стеком возврата, а не стеком данных).
Эти команды очень просты, вот их код
b_move = 0x66 bcmd_move: pop rcx pop rdi pop rsi repz movsb jmp _next b_fill = 0x67 bcmd_fill: pop rax pop rcx pop rdi repz stosb jmp _next b_rpick = 0x63 bcmd_rpick: pop rcx push [rbp + rcx * 8] jmp _next b_and = 0x58 bcmd_and: pop rax and [rsp], rax jmp _next b_or = 0x59 bcmd_or: pop rax or [rsp], rax jmp _next b_xor = 0x5A bcmd_xor: pop rax xor [rsp], rax jmp _next b_invert = 0x5B bcmd_invert: notq [rsp] jmp _next b_rshift = 0x5C bcmd_rshift: pop rcx or rcx, rcx jz _next 1: shrq [rsp] dec rcx jnz 1b jmp _next b_lshift = 0x5D bcmd_lshift: pop rcx or rcx, rcx jz _next 1: shlq [rsp] dec rcx jnz 1b jmp _next
Еще надо сделать слово word. Это то же, что и blword, но на стеке указывается конкретный разделитель. Код не привожу, его можно найти в исходнике. Я сделал copy/paste слова blworld и заменил команды сравнения.
В завершение сделаем слово syscall. С помощью него можно будет сделать недостающие системные операции, например, работу с файлами. Такое решение не пойдет, если требуется платформонезависимость. Но эта система применяется сейчас для тестов, поэтому, пусть будет пока так. При необходимости, все операции можно переделать на байт-команды, это совсем не сложно. Команда syscall будет принимать со стека 6 параметров для системного вызова и номер вызова. Возвращать она будет один параметр. Назначения параметров и возвращаемое значение определяются номером системного вызова.
b_syscall = 0xFF bcmd_syscall: sub rbp, 8 mov [rbp], r8 pop rax pop r9 pop r8 pop r10 pop rdx pop rsi pop rdi syscall push rax mov r8, [rbp] add rbp, 8 jmp _next
А теперь приступим непосредственно к компилятору.
Компилятор
Создадим переменную h, тут все просто.
Ее инициализацию пропишем в стартовой строке:item h h: .byte b_var0 .quad 0
# forth last_item context @ ! h dup 8 + swap ! quit start: .byte b_call16 .word forth - . - 2 .byte b_call16 .word last_item - . - 2 .byte b_call16 .word context - . - 2 .byte b_get .byte b_set .byte b_call16 .word h - . - 2 .byte b_dup, b_num8, b_add, b_swap, b_set .byte b_quit
Сделаем слово here:
item here .byte b_call8, h - . - 1 .byte b_get .byte b_exit
А так же слова для компиляции значений: "allot" и "c,", "w,", "i,", ",", "str,"
# : allot h +! ; item allot allot: .byte b_call8, h - . - 1, b_setp, b_exit # : , here ! 8 allot ; item "," .byte b_call8, here - . - 1, b_set, b_num8, b_call8, allot - . - 1, b_exit # : i, here i! 4 allot ; item "i," .byte b_call8, here - . - 1, b_set32, b_num4, b_call8, allot - . - 1, b_exit # : w, here w! 2 allot ; item "w," .byte b_call8, here - . - 1, b_set16, b_num2, b_call8, allot - . - 1, b_exit # : c, here c! 1 allot ; item "c," .byte b_call8, here - . - 1, b_set8, b_num1, b_call8, allot - . - 1, b_exit # : str, dup -rot dup c, here swap move 1+ h +!; item "str," c_str: .byte b_dup, b_mrot, b_dup callb c_8 callb here .byte b_swap, b_move callb h .byte b_setp .byte b_exit
А теперь сделаем переменную state и два слова для управления ее значением: "[" и "]". Обычно эти слова используются для того, что бы что-то выполнить в момент компиляции. Поэтому, слово "[" выключает режим компиляции, а слово "]" — включает. Но ничего не мешает их использовать в других случаях, когда необходимо включить или выключить режим компиляции. Слово "[" будет у нас первым словом, имеющим признак immediate. В противном случае оно не сможет выключить режим компиляции, так как будет скомпилировано, а не исполнено.
item state .byte b_var0 .quad 0 item "]" .byte b_num1 callb state .byte b_set, b_exit item "[", f_immediate .byte b_num0 callb state .byte b_set, b_exit
Пришел черед для слова $compile. Оно будет брать со стека адрес словарной статьи и компилировать указанное слово. Для того, что бы скомпилировать слово в обычных реализациях форта, достаточно применить слово "," к адресу исполнения. У нас все намного сложнее. Во первых есть два типа слов — байт-код и машинный код. Первые компилируются байтом, а вторые — байт-командой call. А во вторых — у нас есть целых четыре варианта команды call: call8, call16, call32 и call64. Четыре? Нет! Когда я писал компилятор, я к этим четырем добавил еще 16! :)
Как такое произошло? Придется сделать небольшое отступление.
Совершенствуем команду call
Когда заработал компилятор, я обнаружил, что во многих случаях (но не во всех) хватает команды call8. Это когда вызываемое слово находится в пределах 128 байт. Я задумался — а как сделать, что бы это происходило почти во всех случаях? Как засунуть в байт больше 256 значений?
Первый момент, на который я обратил внимание, это то, что в форте вызов идет всегда в сторону меньших адресов. Это значит, что можно переделать команду call таким образом, что она сможет вызывать только меньшие адреса, но уже на 256 байт, а не на 128. Уже лучше.
Но вот если бы куда-нибудь поместить несколько бит… Оказывается, есть куда! Байта у нас два: один байт — команда, второй — смещение. Но ничто не мешает в несколько младших битах команды разместить старшие биты параметра (смещения). Для байт-машины это выглядит, как будто вместо одной команды call стало несколько. Да, таким образом мы занимаем несколько ячеек таблицы кодов байт-команд одной командой, но иногда это стоит сделать. Команда call — одна из самых используемых команд, поэтому я решил поместить в команду 4 бита смещения. Таким образом, можно делать вызов на расстояние целых 4095 байт! Это значит, что такая короткая команда call будет использоваться почти всегда. Команды эти я разместил с кода 0xA0 и в таблице команд появились следующие строки:
.quad bcmd_call8b0, bcmd_call8b1, bcmd_call8b2, bcmd_call8b3, bcmd_call8b4, bcmd_call8b5, bcmd_call8b6, bcmd_call8b7 # 0xA0 .quad bcmd_call8b8, bcmd_call8b9, bcmd_call8b10, bcmd_call8b11, bcmd_call8b12, bcmd_call8b13, bcmd_call8b14, bcmd_call8b15
Первая из этих байт-команд просто делает вызов в сторону меньших адресов на указанное в параметре смещение (до 255). Остальные добавляют к параметру соответствующее смещение. bcmd_call8b1 добавляет 256, bcmd_call8b2 добавляет 512, и так далее. Первую команду call я сделал отдельно, остальные с помощью макроса.
Первая команда:
b_call8b0 = 0xA0 bcmd_call8b0: movzx rax, byte ptr [r8] sub rbp, 8 inc r8 mov [rbp], r8 sub r8, rax jmp _next
Макрос и создание остальных команд call:
.macro call8b N b_call8b\N = 0xA\N bcmd_call8b\N: movzx rax, byte ptr [r8] sub rbp, 8 inc r8 add rax, \N * 256 mov [rbp], r8 sub r8, rax jmp _next .endm call8b 1 call8b 2 call8b 3 call8b 4 call8b 5 call8b 6 call8b 7 call8b 8 call8b 9 call8b 10 call8b 11 call8b 12 call8b 13 call8b 14 call8b 15
Ну а старую команду call8 я переделал на вызов вперед, так как вызов назад у нас уже делают целых 16 команд. Что бы не было путаницы, я ее переименовал в b_call8f:
b_call8f = 0x0C bcmd_call8f: movzx rax, byte ptr [r8] sub rbp, 8 inc r8 mov [rbp], r8 add r8, rax jmp _next
Кстати, для удобства сделал макрос, который на ассемблере автоматически компилирует соответствующий вызов call назад в пределах 4095. А дальше мне ни разу не потребовалось :)
.macro callb adr .if \adr > . .error "callb do not for forward!" .endif .byte b_call8b0 + (. - \adr + 1) >> 8 .byte (. - \adr + 1) & 255 .endm
А теперь…
Компиляция команды
Итак, у нас получается довольно сложный алгоритм компиляции команды. Если это байт-команда, компилируем просто байт (код байт-команды). А если это слово, уже написанное на байт-коде, надо скомпилировать его вызов командой call, выбрав одну из двадцати. Точнее 19, так вызова вперед у нас нет, и call8f для форта использоваться не будет.
Значит, выбор такой. Если смещение лежит в пределах 0...-4095, выбираем команду bcmd_call8b с кодом 0xA0, помещая четыре старших бита смещения в младшие биты команды. При этом, для байт-машины получиться код одной из команд bcmd_call8b0 — bcmd_call8b15.
Если смещение назад больше или равно 4095, то определяем, в какую размерность помещается смещение, и используем соответствующую команду из call16/32/64. При этом надо учитывать, что смещение для этих команд со знаком. Они могут вызывать и вперед, и назад. Например, call16 может вызывать на расстояние 32767 в обе стороны.
Вот такая реализация получилась в итоге:
$compile
Компилирует слово. В качестве параметра принимает адрес словарной статьи компилируемого слова. Фактически, проверяет флаг f_code, вычисляет адрес кода (cfa) и вызывает compile_b или compile_c (если флаг установлен).
compile_c
Компилирует байт-команду. Самое простое тут слово, на форте описывается так:
: compile_c c@ c, ;
compile_b
Принимает на стеке адрес байт-кода и компилирует его вызов.
test_bv
Принимает со стека смещение (со знаком) и определяет, какую нужно использовать разрядность (1, 2, 4 или 8 байт). Возвращает значение 0, 1, 2 или 3. С помощью этого слова можно определить, какую использовать из команд call16/32/64. Пригодится это слово и при компиляции чисел (выбор из lit8/16/32/64).
Кстати, можно запустить систему и «поиграться» в форт-консоли с любыми этими словами. Например:
$ ./forth ( 0 ): > 222 test_bv ( 2 ): 222 1 > drop drop ( 0 ): > 1000000 test_bv ( 2 ): 1000000 2 > drop drop ( 0 ): > -33 test_bv ( 2 ): -33 0 >
test_bvc
Принимает со стека смещение (со знаком) и определяет, какую использовать команду call. Фактически, проверяет, не лежит ли смещение в пределах 0… -4095, и возвращает в этом случае 0. Если нет попадания в этот интервал, вызывает test_bv.
Вот и все, что нужно для компиляции команды
# : test_bvc dup 0 >= over FFF <= and if 0 exit else ... item test_bvc test_bvc: .byte b_dup, b_neg .byte b_num0 .byte b_gteq .byte b_over, b_neg .byte b_lit16 .word 0xFFF .byte b_lteq .byte b_and .byte b_qnbranch8, 1f - . .byte b_num0 .byte b_exit item test_bv test_bv: .byte b_dup, b_lit8, 0x80, b_gteq, b_over, b_lit8, 0x7f, b_lteq, b_and, b_qnbranch8, 1f - ., b_num0 .byte b_exit 1: .byte b_dup .byte b_lit16 .word 0x8001 .byte b_gteq .byte b_over .byte b_lit16 .word 0x7ffe .byte b_lteq, b_and, b_qnbranch8, 2f - ., b_num1, b_exit 2: .byte b_dup .byte b_lit32 .int 0x80000002 .byte b_gteq .byte b_over .byte b_lit32 .int 0x7ffffffd .byte b_lteq, b_and, b_qnbranch8, 3f - ., b_num2, b_exit 3: .byte b_num3 .byte b_exit # компиляция байт-кода item compile_c compile_c: .byte b_get8 callb c_8 .byte b_exit # компиляция вызова байт-кода item compile_b compile_b: callb here .byte b_num2, b_add .byte b_sub callb test_bvc .byte b_dup .byte b_zeq .byte b_qnbranch8, 1f - . .byte b_drop .byte b_neg .byte b_dup .byte b_lit8, 8 .byte b_rshift .byte b_lit8, b_call8b0 .byte b_or callb c_8 callb c_8 .byte b_exit 1: .byte b_dup, b_num1, b_eq, b_qnbranch8, 2f - ., b_drop, b_lit8, b_call16 callb c_8 .byte b_wm callb c_16 .byte b_exit 2: .byte b_num2, b_eq, b_qnbranch8, 3f - ., b_lit8, b_call32 callb c_8 .byte b_num3, b_sub callb c_32 .byte b_exit 3: .byte b_lit8, b_call64 callb c_8 .byte b_lit8, 7, b_sub callb c_64 .byte b_exit #: $compile dup c@ 0x80 and if cfa compile_c else cfa compile_b then ; item "$compile" _compile: .byte b_dup, b_get8, b_lit8, 0x80, b_and, b_qnbranch8, 1f - ., b_cfa callb compile_c .byte b_exit 1: .byte b_cfa callb compile_b .byte b_exit
А теперь нам нужно сделать компиляцию числа.
Компиляция числа (литерала)
Написал целый подзаголовок, приготовился конкретно описать компиляцию литерала, а оказывается, и описывать особо нечего :)
Половину работы мы уже сделали в слове test_bv. Остается только вызвать test_bv, и, в зависимости от результата, скомпилировать lit8/16/32/64, а затем — соответствующее значение размером 1, 2, 4 или 8 байт.
Сделаем это, определив слово compile_n
# компиляция числа item compile_n compile_n: callb test_bv .byte b_dup .byte b_zeq .byte b_qnbranch8, 1f - . .byte b_drop, b_lit8, b_lit8 callb c_8 callb c_8 .byte b_exit 1: .byte b_dup, b_num1, b_eq, b_qnbranch8, 2f - ., b_drop, b_lit8, b_lit16 callb c_8 callb c_16 .byte b_exit 2: .byte b_num2, b_eq, b_qnbranch8, 3f - ., b_lit8, b_lit32 callb c_8 callb c_32 .byte b_exit 3: .byte b_lit8, b_lit64 callb c_8 callb c_64 .byte b_exit
Модифицируем интерпретатор
Для компиляции команды и литералов все готово. Теперь это надо встроить в интерпретатор. Модификация эта проста. Там, где исполнялась команда, надо добавить проверку state. Если state не нулевое и слово не содержит флаг immediate, вместо исполнения нужно вызвать $compile. И примерно тоже самое сделать там, где получено из входного потока число. Если state равно нулю, просто оставляем число на стеке, а если нет — вызываем compile_n.
Вот такой получился интерпретатор
item interpret interpret: .byte b_blword .byte b_dup .byte b_qnbranch8 .byte 0f - . .byte b_over .byte b_over .byte b_find .byte b_dup .byte b_qnbranch8 .byte 1f - . .byte b_mrot .byte b_drop .byte b_drop callb state .byte b_get .byte b_qnbranch8, irpt_execute - . # если 0, поехали на исполнение .byte b_dup, b_get8, b_lit8, f_immediate, b_and # вытащили immediate из флагов слова .byte b_qbranch8, irpt_execute - . # если флаг установлен - на исполнение # все сложилосьб компилируем! callb _compile .byte b_branch8, 2f - . irpt_execute: .byte b_cfa # сюда попадаем, когда надо исполнять (state = 0 или immediate слова установлен) .byte b_execute .byte b_branch8, 2f - . 1: .byte b_drop .byte b_over, b_over .byte b_numberq # проверка, что число преобразовалось .byte b_qbranch8, 3f - . # если на стеке не 0, значит, преобразовалось и идем на метку 3 .byte b_type # иначе печатаем слово .byte b_strp # потом диагностику .byte 19 # это длинна сообщениЯ ниже .ascii " : word not found!\n" .byte b_quit # и завершаем интерпретацию 3: .byte b_nip, b_nip # удалим значения, сохраненные для печати слова (команды b_over, b_over) # в стеке - преобразованное число callb state # проверим, компиляция или исполнение .byte b_get .byte b_qnbranch8, 2f - . # если исполнение - больше ничего делать не нужно; на проверку - и выход # компиляция числа callb compile_n 2: # проверка стека на выход за границу .byte b_depth # получаем глубину стека .byte b_zlt # сравниваем, что меньше 0 (команда 0<) .byte b_qnbranch8, interpret_ok - . # если условие ложно, то все в порЯдке, делаем переход .byte b_strp # иначе выводим диагностику .byte 14 .ascii "\nstack fault!\n" .byte b_quit # и завершаем интерпретацию interpret_ok: .byte b_branch8 .byte interpret - . 0: .byte b_drop .byte b_exit
Теперь мы в одном шаге от компилятора…
Определение новых слов (слово ":")
Теперь, если мы установим переменную state в ненулевое значение, начнется процесс компиляции. Но полученный результат будет бесполезен, мы его не сможем ни выполнить, ни даже найти в памяти. Что бы было возможно все это сделать, необходимо оформить результат компиляции в виде словарной статьи. Для этого, перед включением режима компиляции, надо сформировать заголовок слова.
В заголовке должны быть флаги, поле связи и имя. Тут у нас знакомая история — поле связи может быть 1, 2, 4, или 8 байт. Сделаем слово compile_1248, которое поможет нам сформировать такое поле связи. Оно будет принимать на стеке два числа — смещение и значение, сформированное командой test_bv.
compile_1248
# компиляция значения в один, два, четыре или восемь байт # на стеке значение и байт, полученный test_dv item compile_1248 compile_1248: .byte b_dup .byte b_zeq .byte b_qnbranch8, 1f - . .byte b_drop callb c_8 .byte b_exit 1: .byte b_dup, b_num1, b_eq, b_qnbranch8, 2f - . .byte b_drop callb c_16 .byte b_exit 2: .byte b_num2, b_eq, b_qnbranch8, 3f - . callb c_32 .byte b_exit 3: callb c_64 .byte b_exit
Теперь сделаем слово $create. Оно нам пригодится еще не раз. Можно будет использовать его всегда, когда потребуется создать заголовок словарной статьи. Оно будет принимать со стека два значения — адрес имени создаваемого слова и его длину. После исполнения этого слова на стеке окажется адрес созданной словарной статьи.
$create
# : $create here current @ @ here - test_bv dup c, compile_1248 -rot str, current @ ! ' var0 here c!; item "$create" create: callb here callb current .byte b_get, b_get callb here .byte b_sub callb test_bv .byte b_dup callb c_8 callb compile_1248 .byte b_mrot callb c_str # обновим указатель на последнее слово словаря callb current .byte b_get, b_set # новое слово будет содержать байт-код var0, но он будет за границей here # с одной стороны, это для безопасности - если выполнить это слово, система не упадет # но можно продолжить формирование слова, и этот байт затрется # или просто сделать 1 allot и получиться слово, содержащее данные .byte b_lit8, b_var0 callb here .byte b_set8 .byte b_exit
Следующее слово будет забирать имя нового слова из входного потока с помощью слова blword и вызывать $create, создавая новое слово с указанным именем.
create_in
item "create_in" create_in: .byte b_blword .byte b_dup .byte b_qbranch8 .byte 1f - . .byte b_strp # выводим диагностику (не получили слово из входного потока) .byte 3f - 2f # это длинна сообщениЯ ниже 2: .ascii "\ncreate_in - name not found!\n" 3: .byte b_quit 1: callb create .byte b_exit
И, наконец, сделаем слово ":". Оно создаст с помощью create_in новое слово и установит режим компиляции, он не установлен. А если установлен — выдает ошибку. Слово ":" будет иметь признак immediate.
слово :
# : : create_in 1 state dup @ if ." : - no execute state!" then ! 110 ; immediate item ":", f_immediate colon: callb create_in .byte b_num1 callb state .byte b_dup .byte b_get .byte b_qnbranch8, 2f - . .byte b_strp # выводим диагностику (не получили слово из входного потока) .byte 4f - 3f # это длинна сообщения ниже 3: .ascii "\n: - no execute state!\n" 4: .byte b_quit 2: .byte b_set .byte b_lit8, 110 .byte b_exit
Если кто то заглянул в код, то увидел, что это слово делает еще кое-что :)
Причем тут 110???
Да, еще это слово кладет в стек число 110, и вот зачем. При компиляции, различные конструкции должны составлять единое целое. Например, после if обязательно должно быть then. А слово, созданное с помощью ":", должно завершиться ";". Для проверки этих условий специальные слова компилятора кладут в стек определенные значения, и проверяют их наличие. Например, слово ":" кладет значение 110, а слово ";" проверяет, что на вершине стека находится именно 110. Если это не так, то это — ошибка. Значит, управляющие конструкции оказались не парными.
Такая проверка осуществляется во всех подобных словах компилятора, поэтому сделаем для этого специальное слово — "?pairs". Оно будет принимать со стека два значения, и выдавать ошибку, если они не равны.
Так же в таких словах часто приходится делать проверку на то, что установлен режим компиляции. Сделаем для этого слово "?state".
?pairs ?state
#: ?pairs = ifnot exit then ." \nerror: no pairs operators" quit then ; item "?pairs" .byte b_eq, b_qbranch8, 1f - . .byte b_strp .byte 3f - 2f 2: .ascii "\nerror: no pairs operators" 3: .byte b_quit 1: .byte b_exit #: ?state state @ 0= if abort" error: no compile state" then ; item "?state" callb state .byte b_get, b_zeq, b_qnbranch8, 1f - . .byte b_strp .byte 3f - 2f 2: .ascii "\nerror: no compile state" 3: .byte b_quit 1: .byte b_exit
Все! Больше мы ничего не будем компилировать в ассемблер вручную :)
Но до конца компилятор еще не написан, поэтому в начале придется использовать несколько не обычные методы…
Приготовимся компилировать создаваемый компилятор создаваемым компилятором
Для начала, можно проверить, как работает слово ":", скомпилировав что-то простое. Сделаем, например такое слово:
: ^2 dup * ;
Это слово возводит в квадрат. Но у нас нет слова ";", как быть? Напишем вместо этого слово exit, и оно скомпилируется. А потом выключим режим компиляции словом "[" и дропнем значение 110:
$ ./forth ( 0 ): > : ^2 dup * exit [ drop ( 0 ): > 4 ^2 ( 1 ): 16 >
Работает!
Продолжим…
Поскольку дальше мы будем писать форт на форте, надо подумать, где будет исходный код форта, и когда компилироваться. Сделаем самый простой вариант. Исходный код форта разместим в исходнике на ассемблере, в виде текстовой строки. А что бы он не занимал лишнего места, разместим его сразу после адреса here, в области свободной памяти. Конечно, нам понадобится эта область для компиляции, но скорость «убегания» интерпретации будет больше, чем потребность в новой памяти. Таким образом, компилируемый код начнет перезаписывать исходник на форте, начиная с начала, но он нам будет уже не нужен, так как мы уже этот участок прочитали и использовали.
fcode: .ascii " 2 2 + . quit"
Но, в начале строки все же стоит поместить десяток пробелов.
Что бы все это заработало, изменим стартовый байт-код таким образом, что бы tib, #tib указывали на эту строку. В конце находится quit для входа в обычную командную строку системы.
Стартовый байт-код стал таким
start: .byte b_call16 .word forth - . - 2 .byte b_call16 .word last_item - . - 2 .byte b_call16 .word context - . - 2 .byte b_get .byte b_set .byte b_call16 .word vhere - . - 2 .byte b_dup .byte b_call16 .word h - . - 2 .byte b_set .byte b_call16 .word definitions - . - 2 .byte b_call16 .word tib - . - 2 .byte b_set .byte b_lit16 .word fcode_end - fcode .byte b_call16 .word ntib - . - 2 .byte b_set .byte b_call16 .word interpret - . - 2 .byte b_quit
Запускаем!
$ ./forth 4 ( 0 ): >
Отлично!
А теперь…
Компилируем компилятор компилятором
Дальше пишем код в строку fcode. Первым делом сделаем, конечно, слово ";".
: ; ?state 110 ?pairs lit8 [ blword exit find cfa c@ c, ] c, 0 state ! exit [ current @ @ dup c@ 96 or swap c! drop
Сделаю некоторые пояснения.
?state 110 ?pairs
Тут проверяем, что установлено действительно состояние компиляции, и на стеке лежит 110. В противном случае, будет прерывание по ошибке.
lit8 [ blword exit find cfa c@ c, ]
Это мы компилируем команду lit с байт-кодом команды exit. Пришлось перейти в режим исполнения, найти слово exit, получить адрес исполнения, и взять оттуда код команды. Все это потребовалось потому что у нас нет пока еще слова compile. Если бы оно было, вместо всего этого достаточно было бы просто написать «compile exit» :)
c, 0 state !
Это будет компилироваться команда exit в момент исполнения слова ";", а потом установиться режим интерпретации. Слово "[" тут использовать нельзя, так как оно имеет признак immediate и выполниться сейчас, а нам надо скомпилировать такие команды в слово ";", что бы они выключили режим компиляции.
exit [
Это уже мы испытывали. Компилируется слово exit и выключается режим компиляции. Все, слово ";" скомпилировано. А что же там еще написано дальше?
current @ @ dup c@ 96 or swap c! drop
Нужно установить флаг immediate для нового слова. Именно это и делает указанная последовательность, кроме слова drop. Слово drop удаляет забытое 110, которое поместило слово ":" при начале создания.
Вот теперь все!
Запускаем и пробуем.
$ ./forth ( 0 ): > : ^3 dup dup * * ; ( 0 ): > 6 ^3 . 216 ( 0 ): >
Есть! Вот и первое слово, которое скомпилировал наш компилятор «по настоящему».
Но у нас еще нет ни условий, ни циклов, ни многого другого… Начнем с небольшого, но очень необходимого для создания компилятора слова: immediate. Оно устанавливает признак immediate у последнего созданного слова:
: immediate current @ @ dup c@ 96 or swap c! ;
Знакомая последовательность :) Недавно ее писали вручную, больше этого не потребуется.
Теперь сделаем некоторые маленькие, но полезные слова:
: hex 16 base ! ; : decimal 10 base ! ; : bl 32 ; : tab 9 ; : lf 10 ;
hex и decimal устанавливают соответствующую систему счисления. Остальные — это константы для получения соответствующих кодов символов.
Еще сделаем слово для копирования строки со счетчиком:
: cmove over c@ 1+ move;
А теперь займемся условиями. Вообще, если бы было слово compile, это выглядело бы так:
: if ?state compile ?nbranch8 here 0 c, 111 ; immediate : then ?state 111 ?pairs dup here swap - swap c! ; immediate
Все эти слова в начале проверяют, что установлен режим компиляции и генерируют ошибку, если это не так.
Слово if компилирует условный переход, резервирует байт для параметра команды условного перехода и кладет на стек адрес этого байта. Затем кладет на стек контрольное значение 111.
Слово then проверяет наличие контрольного значения 111, и затем по адресу на стеке записывает смещение.
И сразу сделаем слово else. Оно в начале компилирует команду безусловного перехода, для обхода ветки else. Точно так же, как у if, смещение перехода еще не известно, оно просто резервируется, и его адрес кладется на стек. Ну а после делается ровно все то же, что и при then: адрес уловного перехода устанавливается на ветку else. Что-то это описать сложнее, чем сам код :) Если кто-то хочет досконально разобраться, лучше разобрать работу вот такого, максимально упрощенного кода:
: if compile ?nbranch8 here 0 c, ; immediate : then dup here swap - swap c! ; immediate
Ну а теперь запрограммируем реальный код. Поскольку у нас нет слова compile, применим тот же трюк, что и при создании слова ";":
: if ?state lit8 [ blword ?nbranch8 find cfa c@ c, ] c, here 0 c, 111 ; immediate : then ?state 111 ?pairs dup here swap - swap c! ; immediate : else ?state 111 ?pairs lit8 [ blword branch8 find cfa c@ c, ] c, here 0 c, swap dup here swap - swap c! 111 ; immediate
Теперь можно попробовать скомпилировать условие. Сделаем, например, слово, которое выводит 1000, если на стеке число 5, и 0 в других случаях:
$ ./forth ( 0 ): > : test 5 = if 1000 . else 0 . then ; ( 0 ): > 22 test 0 ( 0 ): > 3 test 0 ( 0 ): > 5 test 1000 ( 0 ): >
Понятно, что такой результат получился не сразу, были ошибки, была отладка. Но, в конце-концов, условия заработали!
Небольшое отступление про разрядность команд перехода
Стоит отметить, что тут используются переходы с восьмиразрядным смещением, которые может выполняться в пределах 127 байт. Это ограничивает объем кода в ветках условия. Но, к сожалению, мы не можем выбирать разрядность команд автоматически. Потому что компилятор форта однопроходный, используются переходы вперед, и надо сразу резервировать место под команду перехода. Для экспериментов 8 бит нам хватит, это примерно от 40 до 127 команд в ветке условия. А как быть, если бы мы делали систему для продакшен?
Вариантов тут несколько. Самый простой — это использовать переходы 16 бит.
Но я бы сделал по другому. 16 бит на смещение для перехода по условиям — это с огромным избытком. Поэтому, я бы применил тот же трюк, что и с командой call, поместив несколько бит смещения в команду. Думаю, 11 бит на смещение достаточно (по 1023 в обе стороны). Это позволит поместить в ветки условия примерно от 300 до 1000 фортовских команд. Обычно бывает не больше нескольких десятков, в противном случае код будет просто не читаем. Тогда в код команды уходит 3 бита смещения, и команда перехода займет 8 ячеек в таблице кодов. Команд у нас три: по нулю (?nbranch), по не нулю (?branch) и безусловный (branch). Итого — 24 ячейки.
Вариантов тут несколько. Самый простой — это использовать переходы 16 бит.
Но я бы сделал по другому. 16 бит на смещение для перехода по условиям — это с огромным избытком. Поэтому, я бы применил тот же трюк, что и с командой call, поместив несколько бит смещения в команду. Думаю, 11 бит на смещение достаточно (по 1023 в обе стороны). Это позволит поместить в ветки условия примерно от 300 до 1000 фортовских команд. Обычно бывает не больше нескольких десятков, в противном случае код будет просто не читаем. Тогда в код команды уходит 3 бита смещения, и команда перехода займет 8 ячеек в таблице кодов. Команд у нас три: по нулю (?nbranch), по не нулю (?branch) и безусловный (branch). Итого — 24 ячейки.
Условия у нас появились, жизнь становится проще :)
Сделаем слово ." (точка-кавычка). Оно при выполнении выводит указанный текст. Используется таким образом:
." этот текст будет выведен"
Использовать это слово можно только в режиме компиляции. Это станет очевидно после того, как разберем устройство этого слова:
: ." ?state 34 word dup if lit8 [ blword (.") find cfa c@ c, ] c, str, else drop then ; immediate
Это слово исполняется в режиме компиляции. Оно принимает из входного потока строку до кавычки (34 word). Если строку получить не удалось, не делает ничего. Хотя, тут лучше бы вывести диагностику. Но для вывода строки как раз и нужно это слово, которое мы делаем :) При необходимости, потом можно переопределить это слово еще раз, уже с диагностикой.
Если строку получить удалось, компилируется бай-команда (."), а затем полученная строка. Эта байт-команда (точка-кавычка в скобках) при исполнении выводит строку, которая скомпилирована за байтом команды.
Проверим.
$ ./forth ( 0 ): > : test ." этот текст будет выведен" ; ( 0 ): > test этот текст будет выведен ( 0 ): >
И, наконец, сделаем слово compile.
Понятно, что в режиме компиляции это слово должно взять из потока имя следующего слова, найти его в словаре. А дальше будут варианты: это может быть байт-команда, а может быть слово, написанное на байт-коде. Эти слова надо компилировать по разному. Поэтому сделаем два вспомогательных слова: "(compile_b)" и "(compile_c)".
(compile_b) будет компилировать команду call для вызова байт-кода. В качестве параметра будет 64-разрядное слово — адрес вызываемого байт-кода.
(compile_c) будет компилировать байт-команду. Соответственно, параметр этой команды будет один байт — код команды.
Ну а само слово compile будет компилировать либо (compile_b), либо (compile_c) с соответствующими параметрами.
Начнем с (compile_c), как с наиболее простой:
: (compile_c) r> dup c@ swap 1+ >r c, ;
Несмотря на простоту, мы впервые пишем слово на байт-коде, которое само по себе имеет параметры. Поэтому прокомментирую. После входа в (compile_с) на стеке возвратов находится, как это не банально, адрес возврата. Это адрес следующего байта после команды call. Ниже изображена ситуация в момент вызова. A0 — код команды call, XX — это параметр команды call — адрес вызова (смещение) байт-кода слова (compile_c).
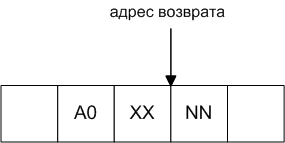
Адрес возврата указывает на байт NN. Обычно там код следующей байт команды. Но у нас слово имеет параметры, поэтому NN — это как раз параметры слова "(compile_c)", а именно, байт-код компилируемой команды. Нужно прочитать этот байт и изменить адрес возврата, передвинув его вперед, на следующую байт-команду. Это делается последовательностью «r> dup c@ swap 1+ >r». Эта последовательность вытаскивает адрес возврата из стека возвратов в обычный стек, извлекает по нему байт, прибавляет к нему же (адресу возврата) единицу, и возвращает обратно в стек возвратов. Оставшаяся команда «c,» компилирует полученный из параметров код байт-команды.
(compile_b) не намного сложнее:
: (compile_b) r> dup @ swap 8 + >r compile_b ;
Здесь все то же самое, только читается 64х разрядный параметр, и для компиляции слова используется слово compile_b, которое мы уже создали для компилятора.
А теперь само слово compile. Как уже разбирали, оно читает имя слова, находит его и сомпилирует одну из двух предыдущих команд. Его я комментировать не буду, все используемые конструкции мы уже применяли и разбирали.
Слово compile
: compile blword over over find dup if dup c@ 128 and if cfa c@ (compile_b) [ blword (compile_c) find cfa , ] c, else cfa (compile_b) [ blword (compile_b) find cfa , ] , then drop drop else drop ." compile: " type ." - not found" then ; immediate
Для проверки созданного слова сделаем, с его помощью, слово ifnot.
: ifnot ?state compile ?branch8 here 0 c, 111 ; immediate
Проверим!
$ ./forth ( 0 ): > : test 5 = ifnot 1000 . else 0 . then ; ( 0 ): > 22 test 1000 ( 0 ): > 3 test 1000 ( 0 ): > 5 test 0 ( 0 ): >
Все в порядке! И пора делать циклы…
В этой статье сделаем циклы с условием. В форте два варианта цикла с условием.
Первый вариант — begin… until. Слово until снимает со стека значение, и, если оно не равно нулю, цикл заканчивается.
Второй вариант — begin… while… repeat. В данном случае проверка происходит при исполнении слова while. Выход из цикла происходит в том случае, если значение на стеке равно нулю.
Циклы на форте сделаны так же, как и условия — на условных и безусловных переходах. Привожу код, комментарии, думаю, не нужны.
: begin ?state here 112 ; immediate : until ?state 112 ?pairs compile ?nbranch8 here - c, ; immediate : while ?state 112 ?pairs compile ?nbranch8 here 0 c, 113 ; immediate : repeat ?state 113 ?pairs swap compile branch8 here - c, dup here swap - swap c! ; immediate
На сегодня с компилятором закончим. Осталось совсем немного. Из ключевых функций, которые еще не реализованы — это только циклы со счетчиком. И еще стоит сделать команду выхода из циклов leave. Это сделаем в следующий раз.
Но мы не испытали команды цикла!
Сделаем это, написав стандартное слово words. Надо же посмотреть, наконец, наш словарь.
Для этого, в начале, сделаем слово link@. Оно будет извлекать из словарной статьи поле связи (смещение на предыдущую статью). Как мы помним, поле связи может иметь разный размер: 1, 2, 4 или 8 байт. Это слово будет принимать в стеке адрес словарной статьи, а возвращать два значения: адрес поля имени и значение поля связи.
: link@ dup c@ 3 and swap 1+ swap dup 0= if drop dup 1+ swap c@ else dup 1 = if drop dup 2 + swap w@ else 2 = if drop dup 4 + swap i@ else drop dup 8 + swap @ then then then ;
А теперь можно сделать и слово words:
: words context @ @ 0 begin + dup link@ swap count type tab emit dup 0= until drop drop ;
Запускаем…
$ ./forth ( 0 ): > words words link@ repeat while until begin ifnot compile (compile_b) (compile_c) ." else then if cmove tab bl decimal hex immediate ; bye ?state ?pairs : str, interpret $compile compile_b compile_n compile_1248 compile_c c, w, i, , allot here h test_bv test_bvc [ ] state .s >in #tib tib . #> #s 60 # hold span holdpoint holdbuf base quit execute cfa find word blword var16 var8 (.") (") count emit expect type lshift rshift invert xor or and >= <= > < = 0> 0< 0= bfind compare syscall fill move rpick r@ r> >r -! +! i! i@ w! w@ c! c@ ! @ depth roll pick over -rot rot swap drop dup abs /mod mod / * - + 1+ 1- exit ?nbranch16 ?nbranch8 ?branch16 ?branch8 branch16 branch8 call8b0 call64 call32 call16 call8f lit64 lit32 lit16 lit8 8 4 3 2 1 0 context definitions current forth ( 0 ): >
Вот оно, наше богатство :)
Хотел сказать все… нет, давайте, все же, сделаем возможность указать в качестве параметра файл с форт-программой для компиляции и исполнения.
Сделаем через syscall команды открытия, закрытия и чтения файла. Определим необходимые для них константы.
: file_open 0 0 0 2 syscall ; : file_close 0 0 0 0 0 3 syscall ; : file_read 0 0 0 0 syscall ; : file_O_RDONLY 0 ; : file_O_WRONLY 1 ; : file_O_RDWR 3 ;
Теперь можно сделать стартовое слово _start:
: _start 0 pick 1 > if 2 pick file_O_RDONLY 0 file_open dup 0< if .\" error: \" . quit then dup here 32 + 32768 file_read dup 0< if .\" error: \" . quit then swap file_close drop #tib ! here 32 + tib ! 0 >in ! interpret then ;
Это слово загрузит из файла и выполнит любую форт-программу. Точнее сказать, интерпретатор исполнит все, что будет в этом файле. А там может быть, например, компиляция новых слов и их исполнение. Имя файла указывается первым параметром при старте. Не буду углубляться в подробности, но параметры запуска в Линуксе передаются через стек. Cлово _start достанет их командами 0 pick (количество параметров) и 2 pick (указатель на первый параметр). Для форт-системы эти значения лежат за границей стека, но командой pick их достать можно. Размер файла ограничим размером 32 Кб, пока нет управления памятью.
Теперь остается написать в строке fcode в конце:
_start quit
Создадим файл test.f и напишем там что-нибудь на форте. Например, алгоритм Евклида для нахождения наибольшего общего делителя:
: NOD begin over over <> while over over > if swap over - swap else over - then repeat drop ; 23101 44425 NOD . bye
Запускаем.
$ ./forth test.f 1777 Bye! $
Ответ верный. Слово скомпилировалось, потом выполнилось. Результат выведен, далее исполнилась команда bye. Если убрать последние две строки, слово NOD будет добавлено в словарь и система перейдет в свою командную строку. Уже можно писать программы :-)
На этом все. Кому интересно, можно скачать исходник или готовый бинарник для Линукса на x86-64 с Гитхаба: https://github.com/hal9000cc/forth64
Исходники поставляются с лицензией

