Художников Эдуарда Мане и Клода Моне путали и при жизни (вот очень интересная статья на Арзамас). Что неудивительно, ведь они оба родоначальники импрессионизма и писали в схожей манере. Слушая на coursera курс по Convolutional neural networks, я решила попробовать сделать модель, определяющую, кем из художников написана картина.
До начала работы я знала только то, что Мане написал “скандальные” “Олимпию” и “Завтрак на траве”. В процессе сбора данных стало понятно, что:
Примеры картин:
Мане

Моне

Код, использованный для этой статьи, доступен на github.
Полный набор данных получился небольшим как для задач обработки изображений: чуть больше 100 изображений у одного класса (Мане) и чуть больше 400 изображений у другого (Моне, хотя это не все его картины). Поэтому я не ожидала высокой точности классификации, которую обычно можно увидеть в таких задачах. Но было интересно, какого уровня можно достичь.
Для начала мы будем использовать простую CNN модель, и не будем обрабатывать данные (кроме рескелинга).
По результатам обучения заметен значительный оверфиттинг:
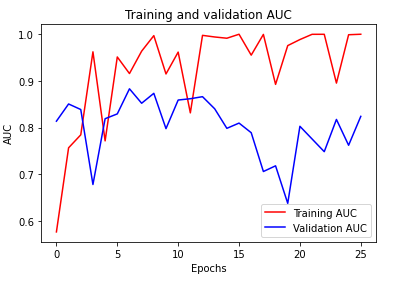
Наилучший результат validation AUC ― 0.883, но при этом AUC на тренинговой выборке ― 0.997.
Чтобы справиться с оверфиттингом, попробуем добавить предобработку данных.
Для предобработки воспользуемся функцией ImageDataGenerator в keras. К рескелингу добавим поворот, сдвиги по вертикали и горизонтали, “вытягивание” и масштабирование изображения, изменения в яркости и цвете, а также отображение по горизонтали.
Модель и все параметры обучения оставим те же. По результатам обучения видно, что значения метрики (AUC) для тренинговой и валидационной выборки довольно близки, то есть предобработка помогла устранить оверфиттинг.

В результате AUC на тестовой выборке составляет 0.919, на валидационной ― 0.909.
Результаты по первым двум моделям:
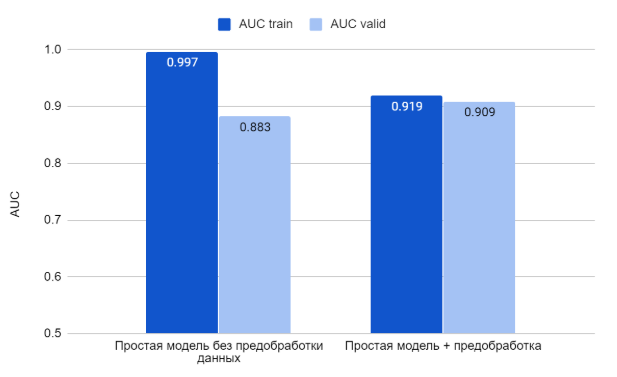
Добавление предобработки устранило оверфиттинг. И хотя AUC получился неплохой, несбалансированность данных мотивировала меня попробовать добавить в модель еще и веса. Я использовала подход к расчету весов из мануала keras:
В результате таких расчетов вес для класса 0 (Мане) 2.50, для класса 1 (Моне) 0.62
Переменная class_weight потом добавляется в model.fit()
Однако, результат обучения не отличается значительно от варианта без весов: AUC на тренинговой выборке равен 0.892, на валидационной ― 0.915.
Результаты по первым трем моделям:
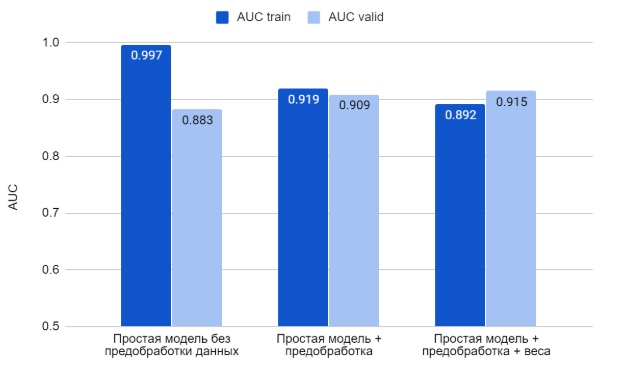
Наш набор данных небольшой как для задач машинного обучения, и тем более deep learning. В таких случаях может помочь подход transfer learning.
Идея в том, чтобы взять готовую к использованию модель, которая была натренирована на большом наборе данных, и соответственно имела возможность выучить больше паттернов в данных. После этого последний слой сети заменяется на тот, который подходит нашей задаче, и модель тренируется на нашем наборе данных.
Я использовала модель Inception V3 (wiki и статья на “Хабр”). Результат получился хороший: AUC на тренинговой выборке 0.971, на валидационной ― 0.970.
Результат по всем моделям:
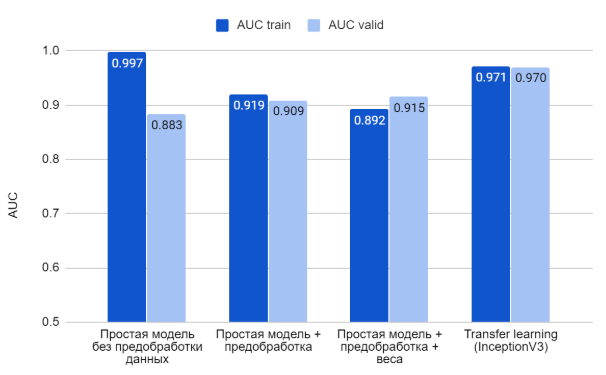
Посмотрим, какой результат получится на тестовой выборке. Сравним две модели ― простую CNN с предобработкой данных и модель, полученную в ходе transfer learning с использованием InceptionV3.
Результаты подтверждают превосходство модели, обученной с помощью transfer learning:

Возьмем предсказания, сделанные transfer learning моделью на тестовой выборке и посмотрим на confusion matrix. Для этого выберем threshold так, чтобы обеспечить значение true positive rate близкое к 0.95 (это произвольно выбранное значение).
Результат такой:
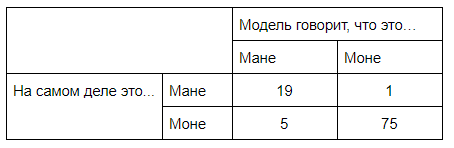
Итого, из картин Мане правильно определено 19 из 20 (true negative rate 0.95), а из картин Моне ― 75 из 80 (true positive rate 0.9375). Показатели TPR и TNR близки, чего нам и хотелось бы добиться, т.к. в этой задаче было важно правильно определять обоих художников.
Теперь посмотрим на картины, которые были классифицированы неверно. Этот прием рекомендует в своей книге Andrew Ng. Цель ― попробовать понять, почему модель ошибается, и можно ли ее доработать так, чтобы устранить ошибку.
Вот картина Мане, которая была классифицирована как Моне:

А вот картины Моне, которые были определены как Мане:

Единственная идея, которая у меня возникла, это то что портреты (2 картины с женщинами + картину с собакой тоже засчитаем как портрет) определяются как картины Мане, т.к. он чаще писал портреты.
Но это неточно :) Хотя Моне действительно писал мало портретов (гораздо меньше, чем пейзажей), на той же тестовой выборке есть портреты его кисти, которые были определены моделью верно:

Учитывая небольшой датасет и схожесть объектов разных классов, я изначально рассчитывала получить AUC в районе 0.8. Однако, даже с помощью простой CNN модели с предобработкой данных удалось получить результат близкий к 0.9, и улучшить его до 0.97 с помощью transfer learning с использованием InceptionV3.
До начала работы я знала только то, что Мане написал “скандальные” “Олимпию” и “Завтрак на траве”. В процессе сбора данных стало понятно, что:
- Стиль написания действительно очень похож
- Мане писал больше портретов, а Моне — пейзажей
- У Моне есть целые серии похожих картин (например, один и тот же пейзаж, написанный в разное время дня)
- Моне написал гораздо больше картин, чем Мане.
Примеры картин:
Мане
Моне
Код, использованный для этой статьи, доступен на github.
Полный набор данных получился небольшим как для задач обработки изображений: чуть больше 100 изображений у одного класса (Мане) и чуть больше 400 изображений у другого (Моне, хотя это не все его картины). Поэтому я не ожидала высокой точности классификации, которую обычно можно увидеть в таких задачах. Но было интересно, какого уровня можно достичь.
Простая модель без дополнительной обработки данных
Для начала мы будем использовать простую CNN модель, и не будем обрабатывать данные (кроме рескелинга).
model_simple_cnn_wo_augm = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(input_size, input_size, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(32, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) train_datagen_wo_augm = ImageDataGenerator(rescale=1.0/255.)
По результатам обучения заметен значительный оверфиттинг:
Наилучший результат validation AUC ― 0.883, но при этом AUC на тренинговой выборке ― 0.997.
Чтобы справиться с оверфиттингом, попробуем добавить предобработку данных.
Простая модель с предобработкой данных
Для предобработки воспользуемся функцией ImageDataGenerator в keras. К рескелингу добавим поворот, сдвиги по вертикали и горизонтали, “вытягивание” и масштабирование изображения, изменения в яркости и цвете, а также отображение по горизонтали.
train_datagen_with_augm = ImageDataGenerator(rescale=1.0/255., rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, brightness_range = [0.5, 1.5], channel_shift_range = 100, horizontal_flip=True, fill_mode='nearest')
Модель и все параметры обучения оставим те же. По результатам обучения видно, что значения метрики (AUC) для тренинговой и валидационной выборки довольно близки, то есть предобработка помогла устранить оверфиттинг.
В результате AUC на тестовой выборке составляет 0.919, на валидационной ― 0.909.
Результаты по первым двум моделям:
Простая модель с предобработкой данных и весами
Добавление предобработки устранило оверфиттинг. И хотя AUC получился неплохой, несбалансированность данных мотивировала меня попробовать добавить в модель еще и веса. Я использовала подход к расчету весов из мануала keras:
weight_for_manet = (1 / manet_test_size)*(manet_test_size + monet_test_size)/2.0 weight_for_monet = (1 / monet_test_size)*(manet_test_size + monet_test_size)/2.0 class_weight = {0: weight_for_manet, 1: weight_for_monet}
В результате таких расчетов вес для класса 0 (Мане) 2.50, для класса 1 (Моне) 0.62
Переменная class_weight потом добавляется в model.fit()
Однако, результат обучения не отличается значительно от варианта без весов: AUC на тренинговой выборке равен 0.892, на валидационной ― 0.915.
Результаты по первым трем моделям:
Transfer learning: использование модели Inception V3
Наш набор данных небольшой как для задач машинного обучения, и тем более deep learning. В таких случаях может помочь подход transfer learning.
Идея в том, чтобы взять готовую к использованию модель, которая была натренирована на большом наборе данных, и соответственно имела возможность выучить больше паттернов в данных. После этого последний слой сети заменяется на тот, который подходит нашей задаче, и модель тренируется на нашем наборе данных.
Я использовала модель Inception V3 (wiki и статья на “Хабр”). Результат получился хороший: AUC на тренинговой выборке 0.971, на валидационной ― 0.970.
Результат по всем моделям:
Оценка модели на тестовой выборке
Посмотрим, какой результат получится на тестовой выборке. Сравним две модели ― простую CNN с предобработкой данных и модель, полученную в ходе transfer learning с использованием InceptionV3.
Результаты подтверждают превосходство модели, обученной с помощью transfer learning:
Confusion matrix & misclassified examples
Возьмем предсказания, сделанные transfer learning моделью на тестовой выборке и посмотрим на confusion matrix. Для этого выберем threshold так, чтобы обеспечить значение true positive rate близкое к 0.95 (это произвольно выбранное значение).
Результат такой:
Итого, из картин Мане правильно определено 19 из 20 (true negative rate 0.95), а из картин Моне ― 75 из 80 (true positive rate 0.9375). Показатели TPR и TNR близки, чего нам и хотелось бы добиться, т.к. в этой задаче было важно правильно определять обоих художников.
Теперь посмотрим на картины, которые были классифицированы неверно. Этот прием рекомендует в своей книге Andrew Ng. Цель ― попробовать понять, почему модель ошибается, и можно ли ее доработать так, чтобы устранить ошибку.
Вот картина Мане, которая была классифицирована как Моне:
А вот картины Моне, которые были определены как Мане:
Единственная идея, которая у меня возникла, это то что портреты (2 картины с женщинами + картину с собакой тоже засчитаем как портрет) определяются как картины Мане, т.к. он чаще писал портреты.
Но это неточно :) Хотя Моне действительно писал мало портретов (гораздо меньше, чем пейзажей), на той же тестовой выборке есть портреты его кисти, которые были определены моделью верно:
Выводы
Учитывая небольшой датасет и схожесть объектов разных классов, я изначально рассчитывала получить AUC в районе 0.8. Однако, даже с помощью простой CNN модели с предобработкой данных удалось получить результат близкий к 0.9, и улучшить его до 0.97 с помощью transfer learning с использованием InceptionV3.

