
Однажды на работе возник вопрос — насколько вероятно, что в случайно сгенерированном идентификаторе (отдаваемом пользователю, к примеру) вдруг обнаружится плохое слово. Приблизительная оценка была дана достаточно быстро, а вот точное решение — уже не так тривиально.
Я решил всерьёз выяснить, чему равна эта вероятность в зависимости от длины случайной строки? Можно ли получить явную математическую формулу для ответа? Что, если взять другое слово? Что, если взять другой алфавит?
Обо всём по порядку.
1. Метод Монте-Карло
Что может быть легче? Генерируем миллионы — миллиарды! — случайных строк и проверяем, содержат ли они искомое слово.
Метод очень прост в реализации. Программа, перебирающая случайные строки в течение 30 секунд, для параметров из заголовка выдала ответ примерно  . Позже мы увидим, насколько он близок к точному значению.
. Позже мы увидим, насколько он близок к точному значению.
Тут есть проблема, которая должна быть очевидна: метод Монте-Карло по времени вычисления является самым затратным из описанных в статье и сходится очень медленно. Это особенно хорошо видно, когда нужно получить точность порядка 8-9 знаков после запятой.
Зачем такая точность, спрашиваете? Чтобы была!
На задачи обозначенного размера даже 30 миллисекунд процессорного времени тратить не хочется, не то что просто секунд. Решение, пусть и универсальное, совершенно не годится.
2. Приблизительное решение
Второй вариант, который приходит на ум: быстро подобрать простую формулу и надеяться на то, что она даст хорошую аппроксимацию.
Вопрос: какой может быть позиция подстроки fuck внутри строки из 20-ти символов? Ответ: от 0 до 16, т.е. 17 различных вариантов. Для каждой такой позиции i, существует  различных слов, в которых fuck — на i-й позиции (т.е. все возможные комбинации оставшихся 16-ти букв в строке).
различных слов, в которых fuck — на i-й позиции (т.е. все возможные комбинации оставшихся 16-ти букв в строке).
Приняв к сведению, что некоторые слова мы посчитаем несколько раз (те, в которых fuck содержится более одного раза), можно сказать, что слов, содержащих fuck, будет точно меньше, чем  , а вероятность, соответственно, не превысит
, а вероятность, соответственно, не превысит  (в знаменателе — количество всех возможных слов длины 20).
(в знаменателе — количество всех возможных слов длины 20).
Это значение равно  , или приблизительно
, или приблизительно  .
.
3. Поиск точной формулы
3.1. Рекуррентное соотношение
Все последующие рассуждения будут касаться формул или процедур для получения точного ответа. Очевидно, что подходов может быть множество. Предлагаю начать с простейшей более-менее общей формулировки. Есть английский алфавит из 26 букв, найти количество слов длины  , содержащих в себе последовательность букв fuck хотя бы один раз.
, содержащих в себе последовательность букв fuck хотя бы один раз.
Обозначим такое количество за  . Начинается последовательность безобидно:
. Начинается последовательность безобидно:

Строки короче 4-х символов точно не содержат нужное подслово, а среди строк из 4-х символов есть только один подходящий кандидат — сама строка fuck. Достаточно быстро значения становятся менее упорядоченными:

Тут всё ещё видна некая закономерность, но она очень быстро сломается, гарантирую.
Попробуем рассмотреть, как же значение с большими зависит от значений с меньшими . Допустим, что  . Предлагаю пересчитывать строки следующим способом:
. Предлагаю пересчитывать строки следующим способом:
- Если префикс длины
 уже содержит искомое слово, то выбор последней буквы ни на что не влияет, т.е. мы бесплатно получаем
уже содержит искомое слово, то выбор последней буквы ни на что не влияет, т.е. мы бесплатно получаем  строк.
строк. - Если строка оканчивается на fuck, то первые
 букв значения не имеют. Итого добавляется ещё
букв значения не имеют. Итого добавляется ещё  строк.
строк. - Других вариантов быть не может: слово fuck встречается либо в конце, либо не в конце, но есть проблема — часть строк посчитаны дважды. В частности, те, которые оканчиваются на fuck и содержат его более, чем один раз (afuckafuck).
Нетрудно понять, что это единственный вид исключений. И все такие строки обязательно содержат fuck среди первых символов, это значение мы и должны отнять как дважды посчитанное.
Итого, объединив все рассуждения, приходим к рекуррентному соотношению:

Стоит заметить, что с таким же удобством можно было бы рассматривать величины  , которые являлись бы не количеством, а вероятностью, или, точнее, пропорцией количества искомых строк с количеством всех возможных строк длины . В новых терминах формула примет следующий вид. На мой взгляд, стало намного лучше:
, которые являлись бы не количеством, а вероятностью, или, точнее, пропорцией количества искомых строк с количеством всех возможных строк длины . В новых терминах формула примет следующий вид. На мой взгляд, стало намного лучше:

Код для подобного соотношения будет тривиальным. Ответ для слов длины 20 равен  . Видно, что реальное значение отличается от ответа, полученного методом Монте-Карло, уже на 7-м знаке после запятой (), а если отбросить нули, то и вовсе в третьей значащей цифре.
. Видно, что реальное значение отличается от ответа, полученного методом Монте-Карло, уже на 7-м знаке после запятой (), а если отбросить нули, то и вовсе в третьей значащей цифре.
Простая аппроксимация () показала себя значительно лучше, дав ошибку лишь в 9-м знаке после запятой (пятой значащей цифре).
Рекуррентная формула — это хорошо, но явная формула — лучше, хочется и её найти.
Помимо этого, сложность процедуры вычисления рекуррентного соотношения является  , что не является оптимальной трудоёмкостью для данной задачи. Её обязательно нужно понизить.
, что не является оптимальной трудоёмкостью для данной задачи. Её обязательно нужно понизить.
3.2. Явная формула
На самом деле, задача очень даже типовая. Хорошо известно, как получить явную формулу для подобного класса задач, пусть и совсем не очевидно, почему надо поступать именно так. Но этот вопрос мы опустим, лучше найдём формулу.
В первую очередь забываем о начальном условии  на какое то время.
на какое то время.
Напомню исходную рекуррентную формулу, слегка её обобщив, чтобы она была сейчас перед глазами. За  я обозначил значение
я обозначил значение  , чтобы не делать последующие выражения ещё более громоздкими.
, чтобы не делать последующие выражения ещё более громоздкими.

Для начала нужно найти частное решение, почти как в дифференциальных уравнениях. К счастью, оно лежит на поверхности:  . Действительно, подставив
. Действительно, подставив  в уравнение получим, что обе части тождественно равны.
в уравнение получим, что обе части тождественно равны.
Зная частное решение, само уравнение можно немного упростить. Положим  и попробуем искать ответ относительно
и попробуем искать ответ относительно  :
:

Перенеся всё в одну сторону, получим:

Далее делается знаменитый финт ушами и предполагается, что есть возможность найти решение в виде  для некоего значения
для некоего значения  . Думаю многим читателям данный финт может быть знаком из вывода общей формулы для членов Фибоначчи, но работает он для любой линейной рекуррентной последовательности. Подставим:
. Думаю многим читателям данный финт может быть знаком из вывода общей формулы для членов Фибоначчи, но работает он для любой линейной рекуррентной последовательности. Подставим:

Сократив это выражение на  , получим уравнение четвёртой степени:
, получим уравнение четвёртой степени:

Это уравнение называется "характеристический многочлен", и у него есть 4 различных корня:
Очень надеюсь, что я правильно скопировал ответ:
![$\mu_1 = \frac{1}{4} -\frac{1}{2} \sqrt{\frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} + \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}} + \frac{1}{4}}\\ -\frac{1}{2} \sqrt{\Bigg(- \frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} - \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}}\\ - \frac{1}{4\sqrt{\frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} + \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}} + \frac{1}{4}}} + \frac{1}{2} \Bigg)}$](https://habrastorage.org/getpro/habr/formulas/d1f/b33/6c8/d1fb336c8ba46b4db525c25475acf124.svg)
![$\mu_2 = \frac{1}{4} -\frac{1}{2} \sqrt{\frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} + \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}} + \frac{1}{4}}\\ +\frac{1}{2} \sqrt{\Bigg(- \frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} - \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}}\\ - \frac{1}{4\sqrt{\frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} + \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}} + \frac{1}{4}}} + \frac{1}{2} \Bigg)}$](https://habrastorage.org/getpro/habr/formulas/501/380/857/5013808570e96f6f97d93fb7add694ef.svg)
![$\mu_3 = \frac{1}{4} +\frac{1}{2} \sqrt{\frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} + \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}} + \frac{1}{4}}\\ -\frac{1}{2} \sqrt{\Bigg(- \frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} - \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}}\\ + \frac{1}{4\sqrt{\frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} + \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}} + \frac{1}{4}}} + \frac{1}{2} \Bigg)}$](https://habrastorage.org/getpro/habr/formulas/02c/1d3/cc5/02c1d3cc5cd46a6213f5fb1a5c6f5cd1.svg)
![$\mu_4 = \frac{1}{4} +\frac{1}{2} \sqrt{\frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} + \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}} + \frac{1}{4}}\\ +\frac{1}{2} \sqrt{\Bigg(- \frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} - \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}}\\ + \frac{1}{4\sqrt{\frac {4\sqrt[3]{\frac{2}{3}}k} {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} + \frac {\sqrt[3]{\sqrt{3} \sqrt{27k^2-256k^3} + 9k}} {\sqrt[3]{2} \ 3^{2/3}} + \frac{1}{4}}} + \frac{1}{2} \Bigg)}$](https://habrastorage.org/getpro/habr/formulas/ada/c0f/9d1/adac0f9d180bb49dabcc4263eed8282b.svg)
Несложно убедиться, что если  и
и  — решения, то и
— решения, то и  — тоже решение, где
— тоже решение, где  и
и  — произвольные константы. Т.е. решение в общем виде выглядит так:
— произвольные константы. Т.е. решение в общем виде выглядит так:

Значения , ,  и
и  следует искать из начальных условий:
следует искать из начальных условий:

Решаем данную систему и подставляем результат в ответ, всё просто! Для этого воспользуемся методом Крамера, который выражает решения системы линейных уравнений через определители некоторых матриц. Выглядеть матрицы будут следующим образом:



В данных терминах решения будут найдены в виде  ,
,  ,
,  и
и  .
.
Можно заметить, что каждый из определителей является определителем Вандермонда, для которого есть замечательная формула вычисления:





Поделив определители друг на друга, получим симпатичный ответ:

Т.е. 
4. Поиск эффективной процедуры вычисления
4.1. Регулярный язык
Данный конкретный случай со словом длиной 4 решён в явном виде. Но, помимо математической красоты, практической ценности он не имеет. При словах длиной больше, чем 4, степень характеристического многочлена будет увеличиваться. Так как уравнения степени выше четвёртой не имеют формулы для их решения, то с нахождением соответствующих значений могут возникнуть серьёзные проблемы (хотя Wolfram|Alpha и способен выдать решения соответствующего уравнения 5-й степени через обобщённые гипергеометрические функции, я понятия не имею, что это такое). Конечно, можно попробовать решать их численно, но это как-то слишком сложно для такой простой задачи.
К слову, пусть и не всегда можно явно вычислить корни характеристического многочлена, все рассуждения можно почти дословно повторить для всех  , соответствующих "простым" искомым словам длины
, соответствующих "простым" искомым словам длины  . Что я имею ввиду под "простыми" словами, будет объяснено ближе к концу статьи, не всё сразу.
. Что я имею ввиду под "простыми" словами, будет объяснено ближе к концу статьи, не всё сразу.
Не думаю, что можно выжать ещё какие-то интересные факты из решения с помощью рекуррентной формулы, так что будем использовать другой подход. К математике вернёмся попозже.
Поговорим о регулярных языках. Строки, содержащие подстроку fuck, описываются регулярным выражением ^.*fuck.*$ (пользуясь синтаксисом для языка Java). Эквивалентный способ описания регулярных языков, на практике менее привычный — это конечные автоматы. В частности, детерминированные конечные автоматы (ДКА). Они сложнее в построении, но проще в обработке. ДКА для описания языка, все слова которого содержат подслово fuck, выглядит следующим образом:
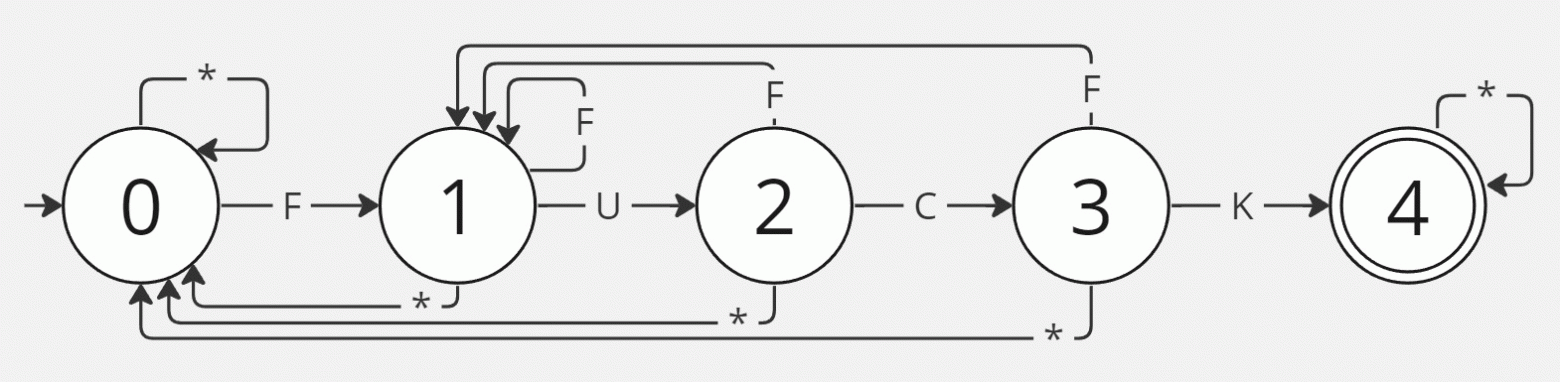
Переходы, помеченные звёздочкой, фактически означают "ветку else" — все оставшиеся символы, которые не встречаются в явно помеченных переходах.
Состояние  — начальное,
— начальное,  — завершающее, все остальные — промежуточные. Видно, что данный конечный автомат не только детерминированный, но и полный, т.е. для каждого состояния и каждого символа алфавита определена функция перехода (существует выходящее ребро графа с соответствующей меткой). Это важно и понадобится в будущем.
— завершающее, все остальные — промежуточные. Видно, что данный конечный автомат не только детерминированный, но и полный, т.е. для каждого состояния и каждого символа алфавита определена функция перехода (существует выходящее ребро графа с соответствующей меткой). Это важно и понадобится в будущем.
Наделим состояния автомата осязаемым смыслом, начиная с последнего.
- — на текущий момент уже найдено подслово fuck и все оставшиеся символы просто пропускаются с помощью перехода из завершающего состояния в него же.
 — на текущий момент прочитан префикс, заканчивающийся на fuc. Есть два возможных варианта — либо дальше идёт k и можно переходить в завершающее состояние, либо там другой символ и поиск нужно "начинать сначала", т.е. идти либо в
— на текущий момент прочитан префикс, заканчивающийся на fuc. Есть два возможных варианта — либо дальше идёт k и можно переходить в завершающее состояние, либо там другой символ и поиск нужно "начинать сначала", т.е. идти либо в  если увидели f, либо идти вообще в начальное состояние .
если увидели f, либо идти вообще в начальное состояние . — на текущий момент прочитан префикс, заканчивающийся на fu. Есть два возможных варианты — либо дальше идёт символ c, удлиняющий текущий найденный префикс слова fuck, либо какой-то другой символ, не позволяющий увеличить прочитанный префикс и заставляющий нас идти либо в , либо в .
— на текущий момент прочитан префикс, заканчивающийся на fu. Есть два возможных варианты — либо дальше идёт символ c, удлиняющий текущий найденный префикс слова fuck, либо какой-то другой символ, не позволяющий увеличить прочитанный префикс и заставляющий нас идти либо в , либо в .- ...
Не хочется ещё несколько раз повторять ту же самую идею. Важно вот что — состояние  означает, что в момент нахождения в нём мы уже вычитали префикс, совпадающий с префиксом длины строки fuck.
означает, что в момент нахождения в нём мы уже вычитали префикс, совпадающий с префиксом длины строки fuck.
Далее я предлагаю отождествлять префиксы искомого слова с названиями состояний соответствующего конечного автомата. Перерисую его с учётом новых названий:

Как по конечному автомату понять, сколько слов длины он сможет распознать? В общем случае этот вопрос может показаться сложным, но точно не для полных ДКА. Ведь для них поиск количества слов сводится к поиску в графе количества путей фиксированной длины из одной вершины к другой (из начального состояния в конечное).
4.2. Исследование конечного автомата
Обозначим за  количество различных путей длины из состояния
количество различных путей длины из состояния  в состояние
в состояние  и исследуем свойства получившихся величин.
и исследуем свойства получившихся величин.
Воспользуемся математической индукцией.  — это просто число рёбер графа, ведущих из состояния в состояние , и вычисляется напрямую из описания конечного автомата.
— это просто число рёбер графа, ведущих из состояния в состояние , и вычисляется напрямую из описания конечного автомата.
Далее, допустим, что мы умеем вычислять все для какого-то  . Найдём
. Найдём  .
.
Любой путь длины  неизбежно разбивается на начало пути длиной и последним переходом длиной . Причём "предпоследним" состоянием может быть совершенно любая вершина графа, обозначим её
неизбежно разбивается на начало пути длиной и последним переходом длиной . Причём "предпоследним" состоянием может быть совершенно любая вершина графа, обозначим её  .
.
Для каждой такой вершины число слов, проходящих сквозь неё на предпоследнем шаге, будет равно  . То есть произведение количества путей длины n на количество последующих путей длины 1 (количество соответствующих рёбер).
. То есть произведение количества путей длины n на количество последующих путей длины 1 (количество соответствующих рёбер).
Взяв в расчёт все вершины , приходим к формуле  . Более того, проведя абсолютно те же самые рассуждения, можно получить формулу
. Более того, проведя абсолютно те же самые рассуждения, можно получить формулу  . Не то, что бы это было необходимо, скорее, помогает заметить закономерность.
. Не то, что бы это было необходимо, скорее, помогает заметить закономерность.
Ничего не напоминает? Это один в один формулы для умножения матриц! Построим матрицу  в соответствии со значениями :
в соответствии со значениями :

Если использовать текущие обозначения, получим следующее общее выражение:

Симпатично вышло. Тем самым становится видно, что вычисление количества путей длины сводится к возведению матрицы в степень . Напомню, что данная формула применима к любому регулярному языку, если известен полный ДКА, который его описывает.
Матрицу  будем называть матрицей смежности. Для конкретного описанного ранее графа она выглядит следующим образом:
будем называть матрицей смежности. Для конкретного описанного ранее графа она выглядит следующим образом:

Здесь видна явная закономерность в распределении единиц. Эта закономерность сохранится для более длинных "простых" слов:

Что же касается вычисления количества слов — оно равно количеству путей из единственного начального в единственное конечное состояние, т.е.  . Если же возвращаться к изначальным обозначениям, то
. Если же возвращаться к изначальным обозначениям, то  для соответствующей матрицы .
для соответствующей матрицы .
Т.к. вероятности мы выражали через  , то новая формула для них будет выглядеть так:
, то новая формула для них будет выглядеть так:

Понимаю, что очень много различных обозначений, но я просто не могу остановиться! Матрицу  можно обозначить
можно обозначить  . Она содержит не число путей из одного состояния в другое, а "вероятность перехода". Фактически она описывает однородную Цепь Маркова, соответствующую случайному блужданию по состояниям нашего графа с равномерной вероятностью выбора следующего ребра. Про цепи Маркова можно было вспомнить раньше, но да ладно.
. Она содержит не число путей из одного состояния в другое, а "вероятность перехода". Фактически она описывает однородную Цепь Маркова, соответствующую случайному блужданию по состояниям нашего графа с равномерной вероятностью выбора следующего ребра. Про цепи Маркова можно было вспомнить раньше, но да ладно.
4.3. Про возведения в степень
Теперь хотелось бы быстренько оценить трудоёмкость вычисления с помощью матриц. Для вычисления с помощью рекуррентного соотношения временная сложность была бы  .
.
Что же для матриц? Наивное итеративное возведение в степень дало бы  , а это хуже предыдущего результата. К счастью, возведение в степень за линейное время никто не осуществляет, ведь есть следующее правило:
, а это хуже предыдущего результата. К счастью, возведение в степень за линейное время никто не осуществляет, ведь есть следующее правило:

Подобный трюк позволяет понизить количество умножений до  , тем самым давая общую трудоёмкость в
, тем самым давая общую трудоёмкость в  — очень даже годится для практических вычислений.
— очень даже годится для практических вычислений.
Можно ещё кое-что сказать о возведении матриц в какие-нибудь степени. Согласно теореме Жордана, матрицу можно представить в виде  , где
, где  — какая-то обратимая матрица, а
— какая-то обратимая матрица, а  — Жорданова матрица, т.е. матрица, состоящая из Жордановых клеток. В частности, для случая простых слов типа fuck — это диагональная матрица, содержащая на диагонали собственные числа матрицы .
— Жорданова матрица, т.е. матрица, состоящая из Жордановых клеток. В частности, для случая простых слов типа fuck — это диагональная матрица, содержащая на диагонали собственные числа матрицы .

Для доказательства этого факта достаточно показать, что у матрицы нет повторяющихся собственных чисел. Можете попробовать сделать это самостоятельно (характеристический многочлен будет дан через несколько абзацев).
Жорданова форма облегчает возведение матриц в степени, в частности,

Возведение в степень диагональной матрицы — задача тривиальная:

К чему я всё это? Взглянем на характеристический многочлен матрицы  :
:

Должно выглядеть знакомо. И ведь действительно —  из явной формулы являются корнями данного уравнения, вдобавок к этому есть дополнительный корень
из явной формулы являются корнями данного уравнения, вдобавок к этому есть дополнительный корень  .
.
Если же попробовать символьно перемножить матрицы ,  и
и  , то можно получить то же самое выражение, что и раньше:
, то можно получить то же самое выражение, что и раньше:

Чтобы упросить дальнейшие формулы, уменьшив в них число делений, лучше рассмотрим характеристический многочлен матрицы , имеющей  строк/столбцов и соответствующей "простому" слову длины
строк/столбцов и соответствующей "простому" слову длины  .
.

Воспользуемся формулой разложения определителя по последнему столбцу, получим следующее:

У матрицы во втором слагаемом последняя строка полностью заполнена нулями, а, значит, и определитель этой матрицы равен нулю. То есть, про второе слагаемое можно забыть. Помним, что матрица в первом слагаемом теперь имеет строк и столбцов.
Снова произведём разложение определителя, на этот раз по первой строке. Получим
![$\chi(L_m) = (26-\lambda)\left[(25-\lambda)\begin{vmatrix} 1-\lambda & 1 & \dots & 0 & 0 \\ 1 & -\lambda & \dots & 0 & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ 1 & 0 & \dots & -\lambda & 1 \\ 1 & 0 & \dots & 0 & -\lambda \end{vmatrix} - 1\begin{vmatrix} 24 & 1 & \dots & 0 & 0 \\ 24 & -\lambda & \dots & 0 & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ 24 & 0 & \dots & -\lambda & 1 \\ 24 & 0 & \dots & 0 & -\lambda \end{vmatrix} \right]$](https://habrastorage.org/getpro/habr/formulas/99c/14c/0a4/99c14c0a46f8b83f0803ff992054969b.svg)
Теперь матрицы в обоих слагаемых имеют  строк и столбцов. Важно за этим следить.
строк и столбцов. Важно за этим следить.
Заметим, что во второй матрице можно вынести 24 из первого столбца. Первую же матрицу снова разложим по первой строке:
![$\chi(L_m) = (26-\lambda)\left[(25-\lambda)\left( (1-\lambda)\begin{vmatrix} -\lambda & 1 & \dots & 0 & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & \dots & -\lambda & 1 \\ 0 & 0 & \dots & 0 & -\lambda \end{vmatrix} - 1\begin{vmatrix} 1 & 1 & \dots & 0 & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ 1 & 0 & \dots & -\lambda & 1 \\ 1 & 0 & \dots & 0 & -\lambda \end{vmatrix} \right) - 24\begin{vmatrix} 1 & 1 & \dots & 0 & 0 \\ 1 & -\lambda & \dots & 0 & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ 1 & 0 & \dots & -\lambda & 1 \\ 1 & 0 & \dots & 0 & -\lambda \end{vmatrix} \right]$](https://habrastorage.org/getpro/habr/formulas/d0f/1c2/30f/d0f1c230f313996c7ed7b1656eaa5619.svg)
Мы получили выражение, в котором содержатся только матрицы очень простой структуры. Обозначим их  и
и  и перепишем выражение в новых терминах. Нижний индекс для и — число строк в матрицах:
и перепишем выражение в новых терминах. Нижний индекс для и — число строк в матрицах:
![$\chi(L_m) = (26-\lambda)\left[(25-\lambda)\left( (1-\lambda)\det(A_{m-2}) - \det(B_{m-2}) \right) - 24\det(B_{m-1}) \right]$](https://habrastorage.org/getpro/habr/formulas/3c9/f52/ac5/3c9f52ac5659cae630154f18f9516cb5.svg)
Здесь я не буду расписывать всё настолько подробно. Матрица — верхне-треугольная, её определитель равен  .
.
С матрицей немного сложнее. Думаю, к этому моменту разложение определителя не должно вызывать проблем, поэтому сделаем его в уме (по первой строке):

Воспользовавшись математической индукцией (а потом формулой суммы геометрической прогрессии), несложно будет доказать, что

Подставив результаты в исходную формулу и упростив выражение несколько раз, получим
![$\chi(L_m) = (26-\lambda)\left[(25-\lambda)\left( (1-\lambda)(-\lambda)^{m-2} - (-1)^{m-1}\frac{\lambda^{m-2} - 1}{\lambda - 1} \right) - 24(-1)^m\frac{\lambda^{m-1} - 1}{\lambda - 1} \right] \\ = (26-\lambda)\left[ (25-\lambda)(1-\lambda)(-\lambda)^{m-2} + (-1)^m(25-\lambda)\frac{\lambda^{m-2} - 1}{\lambda - 1} - 24(-1)^m(\lambda^{m-2} + \frac{\lambda^{m-2} - 1}{\lambda - 1}) \right] \\ = (26-\lambda)\left[ (25-\lambda)(1-\lambda)(-\lambda)^{m-2} - 24(-\lambda)^{m-2} + (-1)^m(25-\lambda - 24)\frac{\lambda^{m-2} - 1}{\lambda - 1}) \right] \\ = (-1)^m (26-\lambda)\left[ (25-\lambda)(1-\lambda)\lambda^{m-2} - 24\lambda^{m-2} - (\lambda^{m-2} - 1) \right] \\ = (-1)^m (26-\lambda)\left[ 25\lambda^{m-2} - 26\lambda^{m-1} + \lambda^m - 24\lambda^{m-2} - \lambda^{m-2} + 1 \right] \\ = (-1)^m (26-\lambda)\left[ \lambda^m - 26\lambda^{m-1} + 1 \right]$](https://habrastorage.org/getpro/habr/formulas/76e/058/8b8/76e0588b8c64b929d3899d67a53788e2.svg)
То есть
![$\chi(L_m) = (-1)^m (26-\lambda)\left[ \lambda^m - 26\lambda^{m-1} + 1 \right]$](https://habrastorage.org/getpro/habr/formulas/3fb/033/631/3fb033631651eefd754cac603da81fe2.svg)
Дальше всё понятно, нужно просто сделать замену переменной в получившейся формуле.
5. Общий случай
На протяжении статьи я употреблял фразу "простое слово", не давая ей точного определения. Постараюсь это исправить. Рассмотрим пример, пусть есть алфавит из трёх символов — {a, b, c}. Посчитаем все слова длиной 3, которые содержат подслово ab: aab, aba, abb, abc, bab и cab. Всего 6 слов из 27-ми.
Если же искать слово aa, то вариантов останется всего пять: aaa, aab, aac, baa и caa. То есть вероятность заметно понизилась.
На самом деле для слова aa предпосылки, на которых мы строили изначальную рекуррентную формулу, ломаются, и использовать эту формулу попросту нельзя.
А именно, ломается подсчёт количества слов, которые "заканчиваются на aa и содержат его более, чем один раз". В этом месте при выводе формулы мы неявно допустили, что у искомого слова нет суффикса, совпадающего с её префиксом. Для fuck свойство выполнено, а для aa — нет.
На примере строк похожей длины, предлагаю рассмотреть слово abab, у него как раз есть префикс ab, совпадающий с суффиксом:
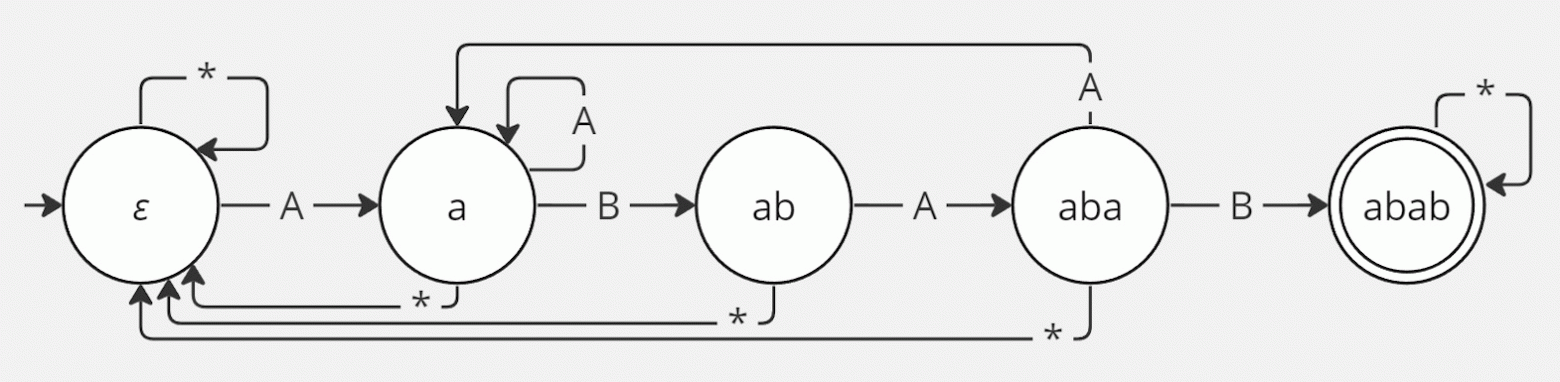
Матрица смежности для него, соответственно, тоже будет отличной. Имеющиеся ранее закономерности нарушены, да и характеристический многочлен другой (считать не буду, просто поверьте):

Казалось бы, совсем чуть-чуть отличается одна строка, а какой эффект. Получается, что эти матрицы отличаются достаточно сильно, чтобы ответы в итоге получались разные.
С другой стороны, есть слова, для которых рассуждения о рекуррентном соотношении всё ещё справедливы, но конечный автомат для которых тоже сильно отличается от исходного. Например, слово aaab:
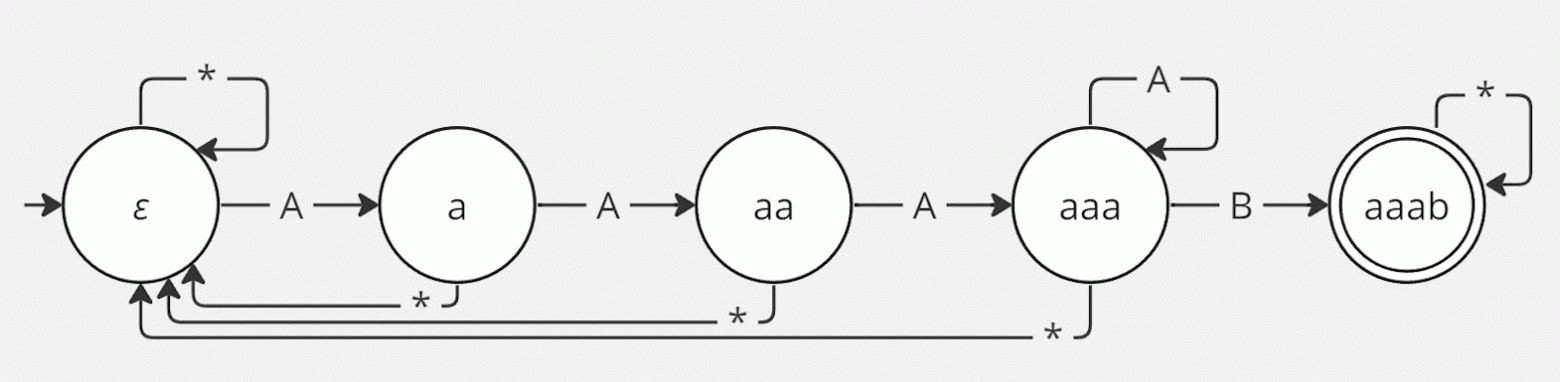

Эта матрица отличается от обеих матриц, приведённых до неё, но всё равно приводит к ответу, совпадающему с таковым для слова fuck! Более того, совпадает не только ответ, но и характеристический многочлен. Матрицы  и
и  имеют одну и ту же Жорданову форму, и вот это уже совсем неочевидно по их внешнему виду.
имеют одну и ту же Жорданову форму, и вот это уже совсем неочевидно по их внешнему виду.
Далее, помимо длины общего префикса/суффикса, на конечный ответ могут влиять и другие факторы. Например, есть ли у префикса/суффикса свой собственный, более короткий префикс/суффикс, и т.д.
Для получения истиной, общей процедуры получения ответа, проще всего построить для слова соответствующий конечный автомат, а по автомату — матрицу, и возводить её в нужную степень. Обобщение рекуррентного соотношения слишком сложно сделать.
Тут я уже не буду никого утомлять точным способом построения ДКА, что-то очень похожее есть, например, в алгоритме Ахо — Корасик. Тот же алгоритм поможет определить вероятность того, что в вашей строке есть нехорошее слово из заранее подготовленного словаря.
Заключение
Кажется, я не ответил на вопрос "Что, если взять другой алфавит?". Замените 26 на другое число, вот и всё.
Что в итоге. Интересную задачу посмотрели, математику младших курсов вспомнили, выводов особо не сделали. Моей целью было немного развлечь читателя и, может быть, показать что-то новое — надеюсь, было интересно. Думаю, наибольшую пользу из статьи смогут извлечь как раз-таки студенты. Код не привожу, да и стали бы вы его читать?
Спасибо за внимание!

