
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
У математиков есть такая позиция: "не используй в рассуждениях то, что не можешь доказать". Вот с перформансом, мне кажется, должно быть то же самое: не используй в своём коде что-либо, если не знаешь как примерно оно работает под капотом, какие оверхеды несёт и как это в случае чего оптимизировать.
Это не значит что надо сверлить оптимизацию покуда не упрёшься в скорость прохождения электронов по проводам. Но надо всегда понимать что любое удобство даётся не бесплатно. Нет языков программирования, в которых бесплатно создание нового класса, вызов лишней функции, наполнение данными лишней коллекции и лишний её обход — просто нет.
Разумеется, есть ряд оптимизаций, которые сокращают стоимость. Что-то новое в этом направлении пытается сказать Rust, но покуда его не знает каждый встречный — надо помнить что удобство не бесплатно. И надо понимать насколько именно и какое удобство не бесплатно для того чтобы, делать простенькие трейд-оффы, когда это возможно.
Да и вообще мне кажется что плохая производительность — она далеко не всегда из-за того, что где-то есть Один Большой и Толстый Ботлнек. Она вполне себе может складываться из сотен неоптимально написанных мест. Уменьшим же их количество!
Аминь.
Я пишу на python. Да, он красивый, удобный и ни фига не быстрый. Но зачем мне скорость, если я все равно жду, пока удаленный сервер подумает и ответит на кучу запросов?
Меня вполне устраивает, что полный аудит системы осуществляется за 20 минут, если мне это нужно делать раз в неделю. Зато код понятно выглядит и намного проще его поддерживать
Есть некоторая ирония в том, что статья осуждает
Резкие, самодовольные фразы в стиле "этот болван четыре раза пробежался по коллекции, хотя можно было один", и тому подобное.
а Ваш комментарий, который, мне кажется, напоминает фразу "эти болваны, наверно, написали сервер на питоне, хотя можно было взять <высокопроизводительный язык>", получает только положительные оценки.
Допускаю, что я предвзят (сам люблю питон), и Ваш комментарий не осуждает использование питона в серверной разработке.
где кто либо задумывался бы о performance
А что с однопотоком делать?
Интел и Амд наращивают по капли скорость ядра, и каждое дальнейшее ускорение дается со все большим трудом.
Так это и есть основная область Python: I/O-bound задачи. Особенно если учесть такие вещи как GIL.
Можно поинтересоваться. Что вы имели ввиду когда писали "когда после компиляции регистры оказывают в разных частях чипа" ?
Ради справедливости: "технически можно сделать всё" — довольно инфантильная и глупая позиция. Знаю ребят, которые так делали. Их продукт в итоге превратился в нелогичное и неюзабельное говно. Потому что на любую идею говорилось "да мы! да щас как! да мы можем!". А потом выясняется что технически нереализуемые углы, подразумевающие заглядывание в голову пользователя сглаживаются самыми нелицеприятными методами.
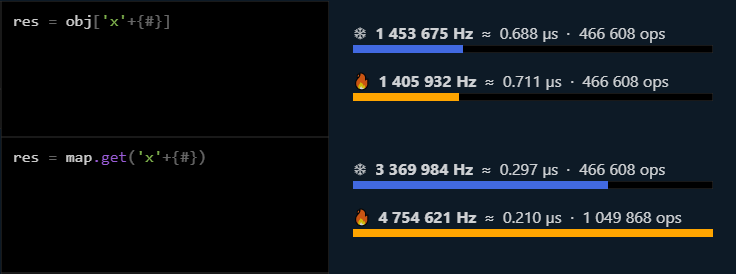
Справедливости ради, наколенные бенчи — абсолютно не показательны. Но в то что у них Map медленнее Objecta отдает по ключу — меня точно не удивит)
А как смотрел? Я вот покопал немного тему бенчмарка, и понял, что тут или хорошо умеешь — или не берись. Результаты на дебаге и на релизе абсолютно разные. Результаты на разных процессорах абсолютно разные. Любое приложение, например WebStrom, работающее во время бенчмарка, способно влиять на результаты этого бенчмарка непредсказуемым образом. При разной температуре процессора результаты могут радикально отличаться. На одних размерах данных будет побеждать один способ, на других — другой. А потом ты опят увеличиваешь размер данных, и результат снова противоположный. Т.е. я говорю не о маленьких погрешностях — результаты могут быть буквально противоположными из-за такой мелочи, как одно запущенное стороннее приложение. И это — верхушка айсберга.
delete.keys, entries у Map возвращает итераторы, в отличие от Object.keys, который возвращает массив, и становится возможным сразу использовать методы перебора массива. С мапом придется или Array.from или for..of.clear.У Map есть одно иногда очень важное преимущество — в нем ключами могут быть другие объекты сами по себе.
Т.е. мы можем использовать внешние объекты как ключи ничего не зная про их структуру и уникальность...
WeakMap — совсем другое дело, нужная и полезная вещь.
А как вы тогда использовали WeakMap?
The keys must be objects and the values can be arbitrary values.
На самом деле, вопрос, и правда меня интересует. Сколько не пишу, не было задачи, где WeakMap был бы решающим
if (myMapInstance.has(something)) ...
if (myObjectAsCollection[something]) ...
(new Map()).constructor.name === 'Map';
({}).constructor.name === 'Object';
const myObj = {};
const nonStringKey = function () {};
const myObjNonStringKeys = [nonStringKey];
const myObjNonStringValues = ['nonStringValue'];
const proxyForObjectNonStringKey = new Proxy(myObjNonStringKeys, {
get (target, nonStringKeyAsString) {
// accessor nonStringKeyAsString может быть только строкой
// поэтому придётся проверять ключи, как строки
// можно попытаться что-нибудь придумать с хешированием
// но это отдельная, ещё более жуткая история
// ничего кроме строк же...
let valueToReturn;
myObjNonStringKeys.filter((key, index) => {
if (
key.toString istanceof Function &&
key.toString() === nonStringKeyAsString
) {
// примерно здесь каррирование реализуем
// но для примера просто вернём значение
valueToReturn = myObjNonStringValues[index];
}
});
return valueToReturn;
}
});
Object.setPrototypeOf(myObj, proxyForObjectNonStringKey);
const s = myObj[nonStringKey];
console.log(s); // 'nonStringValue'
Насколько я понял, основная суть вопроса была через Object получить такое же поведение, как есть у Map.
new Map() instanceof Object //=> true, с ним все тоже самое, что и с обычным объектом.new Map() instanceof Object //=> true — это, надеюсь, понятно теперь, что это просто проверка не совсем правильная? Т.е., так можно проверить, что это нечто имеет в своём составе прототип от Object. Но это не то, что мы бы хотели получить, верно же?const MyConstructor = function () {};
const myInstance = new MyConstructor();
// next line: readonly works
myInstance.constructor.name = 'zzz';
// next 2 lines: MyConstructor
console.log(myInstance.constructor.name);
console.log(MyConstructor.name);
Object.defineProperty(myInstance.constructor, 'name', {
get () {
return 'всё прекрасно меняется';
}
});
// next 2 lines: всё прекрасно меняется
console.log(myInstance.constructor.name);
console.log(MyConstructor.name);

А это сервис какой-то или просто кто-то делал бенч и обернут результаты в красивую картинку?
Сервис, картинки кликабельны.
О, оно даже на $mol работает! Прикольно! Только вот поля ввода как-то неадаптивненько выглядят.
Интересно, как там работает сама проверка: на беке или на фронте?
А вот сайтик hyoo.ru свёрстан и задизайнен очень спорно и "прибит" к левой части экрана(
</фидбек о котором никто не просил>
Есть большая разница между умением оптимизировать и нежеланием экономить на спичках.
Код, который обрабатывает 10К элементов, я буду писать вдумчиво и с оптимизациями. А код, который обрабатывает 10 элементов, я напишу так, как проще и понятнее. И всем того же желаю.
Если есть два алгоритма, один из которых O(N^3) а другой O(M log M), вполне может оказаться, что оптимизировать надо второй — потому что M >> N.
Как вы думаете, авторы Хабра предполагали, что под одной статьёй может скопиться более 2 тысяч комментариев?
А почему бы они это не предполагали, причём с самого начала? На момент запуска Хабра в ЖЖ срачи на тысячу каментов вполне были. Думаете, авторы Хабра не надеялись на растущем рынке сделать что-то сопоставимое?
Предположить такое было бы несложно, я бы предположил :-)
Да на хабре-то как раз я проблем с этим не вижу. Ну, да, на атоме с полгигом памяти и на slow 3g будет не очень, но кого это волнует :-)
Есть некоторые несуществующие бложики, где и на моем core i9 при 2к комментах все тормозит ;)
https://habr.com/post/423889 Попробуйте в Хроме долистать до последнего комментария.
А код, который обрабатывает 10 элементов, я напишу так, как проще и понятнее
А потом придёт кто-то другой, посмотрит "о, готовый метод" и скормит в него 10К элементов
Разумеется, у такого метода будет не generic название, а специфичное для конкретной задачи. А, скорее всего, и сигнатура будет такая, что скормить этому методу можно только объект совершенно конкретного узкоспециализированного класса. Или вообще это будет private method.
3. А может оптимальный но некрасивый код будет лучше читать? Всякие цепочки вида .Where.Select.GroupBy.Select.Where.Distinct.Any через некоторое время становятся совершенно непонятными, а тупой цикл for можно разметить комментариями и крутить в голове.
Забавно, у меня опыт ровно противоположный: комбинаторы итераторов — это единственный способ сохранить читабельность, а вот цикл с увеличением числа строчек быстро превращается в big ball of mud.
Всякие цепочки вида .Where.Select.GroupBy.Select.Where.Distinct.Any через некоторое время становятся совершенно непонятными
а тупой цикл for можно разметить комментариями и крутить в голове
Один цикл тут будет, 3 условия и 4 переменных.
На каждое слово из этой цепочки тебе может пригодиться минимум по циклу. Итого, в твоём примере будет семь циклов.
Каждый раз, когда задача решается по принципу наименьших усилий — она обязательно возвращается потом обратно, спустя годы, но возвращается.
Это, конечно, не так. В 99% случаев ничего и никогда не возвращается.
А все потому что вместо цикла написали LINQ-запрос, следующий программист не стал вникать
Так проблема в LINQ-запросе или в том, что следующий программист не стал вникать?
Если бы там был цикл, а не LINQ-запрос, следующий программист стал бы?
Каждый раз, когда задача решается по принципу наименьших усилий — она обязательно возвращается потом обратно, спустя годы, но возвращается.
Весь код, не рассчитанный на работу в современных условиях, был очевидно написан давно. Вполне естественно к нему возвращаться и поправлять под новые требования. Ты просто правишь в том месте, где начало тормозить, и всё, а не переписываешь механически весь LINQ везде на циклы и т.п.
Ещё бывает, что потенциально медленный код до этого "спустя годы" не доживает — видоизменяется или заменяется другим. Во время написания он был нормальным и с работой справлялся. А про то, что сейчас он был бы медленным, ты даже не узнаешь. Узнаешь только про тот код, который дожил.
Оптимизировать что угодно можно до бесконечности, поэтому нужно иметь для себя какой-то ориентир, чтобы глядя на который можно было сказать, всё, хватит, код уже достаточно быстр, не надо больше тратить время. Часто когда что-то пишешь с нуля, такого ориентира либо нет (ещё нет), либо пока не напишешь значительную часть кода, не можешь сравнивать. Поэтому сначала пишешь быстро, просто и понятно; и уже потом, когда появляется представление о фактической производительности, об узких местах, начинаешь оптимизировать там, где в этом есть смысл.
Как же хорошо, что я пишу на языке, где можно использовать LINQ-подобные цепочки функций и при этом не убивать перформанс
Не бывает в программировании абсолютного «медленно» и абсолютного «быстро». Бывает «достаточно быстро» и «недостаточно быстро», а несколько размытая граница между ними определяется обстоятельствами. LINQ вероятно не стоит пихать внутрь цикла из 10k итераций на кадр / 60 кадров в секунду ― 16 миллисекунд не резиновые. Но если код запускается при нажатии юзером на GUI-кнопку, то вообще плевать, за сколько он отрабатывает, за 1/10 микросекунды или за 10. Лучше будет тот вариант, который проще и понятнее. Если LINQ вдруг проще, то и пусть будет он, отличная же вещь.
Просто альтернативный подход ― это преждевременная пессимизация, когда ты стреляешь себе в ногу прямо сейчас специально и прицельно; вместо того чтобы мимоходом написать пару простых строк, от которых когда-нибудь в будущем тебе может прилететь, а может и не прилететь ― но даже если и прилетит, их не жалко переписать под новые требования.
Вот есть «ленивые вычисления» (привет, LINQ!), а это такое «ленивое программирование». Принцип одинаковый ― незачем делать сейчас то, что сейчас никому не нужно, и хрен знает, потребуется ли в будущем.
Или эти люди прошли собеседования в лучших традициях вопросов про алгоритмы и большего О. А потому и считают, что связанный список самая оптимальная структура данных в то время когда в реальном мире теория и практика иногда сильно расходятся :)
Большинство из тех, кто знает про большое О, почему-то не понимает, что оно имеет смысл, когда N стремится в бесконечность. В реальности же N=100, или даже 100k, от бесконечности сильно отличаются, и часто всё решают константы, а не O().
Особенно, когда вместо O(n^2) пишут O(2^n), которое при любом разумном соотношении констант будет занимать часы при уже n>40.
То же N^2 для N~100k уже невообразимо медленнее O(N log n) — тут никакие константы не помогут.
Поскольку O() тупо не учитывает константы, то O(N), O(N/100k) и O(N*100k) друг другу тождественны. Ну и как тут можно серьёзно рассуждать о производительности?
Потому что константа редко достигает таких экстремальных размеров.
Очень сложно придумать хоть сколько нибудь реальный алгоритм, который выполняет 100N операций. Вся константа зарыта в коде. Чтобы сделать 100kn операций, надо или цикл гнать до 100k, что на самом деле будет каким-то дополнительным параметром M, который тоже надо включать в анализ, или написать 100k строчек кода!
Константы меньше единицы вообще сложно получить, если только не игнорировать 99.99999% процентов данных, что тоже весьма специфический случай.
Очень сложно придумать хоть сколько нибудь реальный алгоритм… Вся константа зарыта в коде.
Вот. Константы в коде. Очень легко представить две реализации одного алгоритма, одна из которых для обработки каждого элемента входных данных совершает по времени в 100k больше бессмысленной работы, чем другая реализация.
O() ― это такая странная безразмерная штука про условные операции абстрактного исполнителя алгоритма в вакууме. Мы же пишем код для конкретного исполнителя, под данные определённого размера и характера; и время работы этого кода в секундах ― единственное, что нас реально волнует.
Знать про O() вообще полезно, но не написав код, только по двум разным O() делать какие-то выводы, это пальцем в небо и «преждевременная пессимизация».
Очень легко представить две реализации одного алгоритма, одна из которых для обработки каждого элемента входных данных совершает по времени в 100k больше бессмысленной работы, чем другая реализация.
А я ничего такого представить не могу. Ну кроме умышленного замедления, где над, собственно, кодом обернут цикл на 10k операций. Вы можете сделать в 10 раз больше работы, если очень постараетесь, будете очень не cache friendly, и не примените ни одной очевидной оптимизации.
O() ― это такая странная безразмерная штука про условные операции абстрактного исполнителя алгоритма в вакууме
На практике, если у вас N>30, то O(N^2) почти всегда медленнее O(N log N), а даже самая быстрая реализация O(N^3) медленнее даже самой дерьмовой реализации O(N^2) алгоритма. Опять же, если умышленно искусственно код не замедлять.
А я ничего такого представить не могу. Ну кроме умышленного замедления, где над, собственно, кодом обернут цикл на 10k операций.
Одна высокоуровневая "операция" без всяких циклов может разлагаться на непредсказуемое количество низкоуровневых. Никто не может сказать чётко, что такое "операция" в O() и чему она соответствует в реальности, и как результат, никто об этом и не говорит.
Можно читать и обрабатывать байты из файла по одному через какой-нибудь высокоуровневый поток, можно буферизировать ввод и двигать указатель по байтам в буфере, а можно читать и обрабатывать не байты, а пачки по 16/32 байта через SSE/AVX. Алгоритмически варианты не отличаются, а разница в скорости на многие порядки и определяется исключительно константами.
На практике, если у вас N>30, то O(N^2) почти всегда медленнее O(N log N), а даже самая быстрая реализация O(N^3) медленнее даже самой дерьмовой реализации O(N^2) алгоритма. Опять же, если умышленно искусственно код не замедлять.
Умышленно никто не замедляет, просто необходимость оптимизировать код, когда такая необходимость существует, регулярно упускается в пользу рассуждений об O(). Типа, N^2 лучше, чем N^3, значит соответствующая реализация должна работать быстрее и можно не напрягаться. А это O() описывает не реализации и не скорость, а исключительно поведение алгоритмов на максимально неудобных входных данных при росте их объёма.
Для двух конкретных реализаций можно построить два графика времени их работы в зависимости от объёма входных данных, сравнивать и делать выводы.
Графики O(n^2) и O(n^3) даже нарисовать невозможно, делать выводы и подавно. Единственный вывод, которых можно сделать, — существует такое неизвестно какое N, больше которого любая возможная реализация алгоритма O(N^2) будет работать быстрее любой возможной реализации O(N^3). Ну, не очень полезное практически знание. N-то у нас обычно задано заранее или мы уже представляем, в каких примерно пределах оно может гулять.
Одна высокоуровневая "операция" без всяких циклов может разлагаться на непредсказуемое количество низкоуровневых.
Приведите пример, когда "высокоуровневая операция" в 100k раз медленнее на практике?
Можно читать и обрабатывать байты из файла по одному через какой-нибудь высокоуровневый поток, можно буферизировать ввод и двигать указатель по байтам в буфере, а можно читать и обрабатывать не байты, а пачки по 16/32 байта через SSE/AVX.
На практике, опять же, операционная система, контроллер диска, страндартная библиотека — все будут какую-то буфиризацию производить. Что бы именно до побайтового чтения с диска допрограммировать, это надо что-то специально делать. Всякая векторизация — ускорение в 32 раза, а не в 100k.
Вы все правильные вещи говорите. Да, из-за константы O(n^2) алгоритм, теоретически, может быть медленее O(n^3). Но, позвольте мне перефразировать свое утверждение, чтобы предмет спора не терялся: Если какая-то задача имеет решения за квадрат и за куб, и n не тревиально маленькое (скажем, n>=30) — то хорошая реализация решения за квадрат будет быстрее хорошей реализации решения за куб. Потому что константы не различаются на много порядков. Исключения настолько редки, что знание ассимптотического анализа, все-таки, полезно.
Закольцованный буфер — ещё ладно; время потрачено, но он хотя бы работает. А на связном списке проще секунду просрать, чем 0.0001 выиграть.
Кто ты и куда дел fillpackart? Где нытьё? Почему в статье написаны простые разумные вещи?
Ну вот зачем так? Есть у меня и другие статьи без нытья, например
https://habr.com/ru/post/506088/
Ну, в идеальном мире. В реальном мире, ну блин, ну не пишут эти требования. А если пишут, то недостаточно детально. А если достаточно детально, то они устаревшие. Я не знаю. Я работал в гигантских и крутых компаниях, где есть ресурсы на такие вещи — но даже там качественно расписанных требований днем с огнем не сыщешь.
У меня есть друг, опытный разраб высокого класса, который на днях выпнул человека с собеса, потому что тот предоставил медленное решение. Задача была — реализовать специфичный LINQ метод. В C# эти методы следует делать ленивыми — через итераторы и yeild — а парень просто зафигачил новый список, и стал пихать в него значения, чем сломал ленивость.
Да, непонимание философии LINQ — это проблема. Но само решение, которое рушит эту философию — не критичное. Вот например майки в доку положили именно такое решение, и не чешутся https://docs.microsoft.com/ru-ru/dotnet/csharp/programming-guide/concepts/linq/how-to-add-custom-methods-for-linq-queries
Ну да. Об этом ещё Макконелл говаривал.
Во имя эффективности — при- чем достигается она далеко не всегда — совершается больше компьютерных грехов, чем по любой другой причине, включая банальную глупость. (Совершенный код, глава 25)
Задача была — реализовать специфичный LINQ метод. В C# эти методы следует делать ленивыми — через итераторы и yeild — а парень просто зафигачил новый список, и стал пихать в него значения, чем сломал ленивость.
public IEnumerable<user> GetBatch(int pageNumber)
{
return users.Skip(pageNumber * 1000).Take(1000);
}'C# enumerate collection batches',— это слишком круто для такого кода.
Всегда нужно смотреть вперёд.Всегда есть обратная сторона медали.
появляется несколько клиентов, у которых размеры локальных баз доходят до десятка гигабайтЕсли бы сразу обдумывали все возможные нюансы, этих клиентов могло бы и не быть. А могли бы и быть.
Я стараюсь писать сразу оптимальный код, тем более с опытом издержки на такую реализацию практически равны нулю. В последнее время часто использую спаны для работы со строками — это тоже все несложно. И я редко использую LINQ, хотя и не против него, если другие участники команды его используют.
Ну и да — на моей практике встречалось, что код конвертера Objective-C -> Swift начинал тормозить из-за неоптимальных коллекций — приходилось менять обычные списки на HashSet или словари. Причем проблема проявлялась только на относительно больших файлах. А в одном месте отказ от yield наоборот помог ускорить производительности.
Я бы вышвырнул из профессии людей, которые пишут нечитабельный и неподдерживаемый код.
Как только напишете эталон читаемости и поддерживаемости — начнём вышвыривать.
Ну я на самом деле тут ответил агрессией на агрессию. По большому счету, речь ни идёт ни о каких эталонах. Вопрос в приоритетах и трейдофах. Т.е. не так важно, читабельный код на самом деле или нет, важно, пытаюсь ли я сделать его читабельным.
Отвечать агрессией на агрессию — тупиковая ветвь диалога.
Ну вот один пытается сделать читабельно, а другой читать это не может — у него кровь из глаз течёт.
Да какой диалог. Меня задели, я насрал в ответ.
А по читаемости — ну да, так и есть. Но мы же это обычно обсуждаем. Вот у меня был кейс, что тимлид буквально хейтил вертикальные вайтспейсы. Не ставил их нигде, ещё и линтер настроил. В итоге нам удалось его переубедить. Потому что мотивация то у него была правильная — писать красивый и читабельный код.
Так и осталось непонятно почему для автора медленный код — более «эстетичный».
Логическая ошибка. Статья про то, что эстетичный код бывает «медленным», и что это не повод убивать эстетику, если скорость работы и так устраивает. Из этого утверждения не следует, что медленный код ― эстетичный.
«Художникам» от мира программирования стоит подумать о смене профессии на действительно творческую, ИМХО. Ради себя и других.
Как это возможно, программировать и одновременно не дружить с логикой?
я посидел с ней некоторое небольшое время и ускорил в 27 раз
Ну так всё ровно в соответствии с поговоркой.
while(--l) работал раньше быстрее всего, но сейчас разницы с forEach нет. Больше меня ничего не спрашивали. )Что люди не делают, как не извиваются, лишь бы на Си не писать...
Как написать на C обобщённую сортировку, в которой компаратор не будет каждый раз вызываться по указателю?
лишь бы на Си не писать...Спасибо, но не надо. Си подарил огромное количество уязвимостей и падающих программ.
Ну а что вы хотели, когда со всех сторон перинка не постелена — выстрелить в ногу гораздо проще...
Тем больше разница отличающая хорошего программиста от обыкновенного.
Понятно, что бизнесу лучше перинки. Пока в жесткие тиски не зажали.
Ну а что вы хотели, когда со всех сторон перинка не постелена — выстрелить в ногу гораздо проще...Уже был cyclone, сейчас rust, однако до сих пор предлагается писать на си, особенно на opennet или на лоре.
Тем больше разница отличающая хорошего программиста от обыкновенного.Нет никакой разницы. Ладно, если бы ошибки были в проектах школьников, а так они практически везде, посмотрите блог psv-studio.
Pvs studio не плюсы ли проверяют?
Си это база, основа, глыба — есть огромное коммьюнити, десятки лет граблей и прочего. Где стрельнет в ногу раст если на нем ssl начнут писать — может увидим. А может и нет...
Pvs studio не плюсы ли проверяют?Там четыре языка С, C++, C# и Java.
Си это база, основа, глыба — есть огромное коммьюнити, десятки лет граблей и прочего.Си, это прекрасная возможность писать код в 2020 году так, словно на дворе семидесятые. И на всё те же грабли можно наступить, за прошедшие десятилетия их никуда не дели. Как тогда, когда
while(*to++ = *from++) ;считалось верхом изящества, можно было запросто затереть кусочек памяти, так и сейчас.Где стрельнет в ногу раст если на нем ssl начнут писатьНасколько я понимаю, в этой библиотеке всё равно будет использоваться ассемблер, для ускорения работы, так что это не показатель. Сравнивать имеет смысл программы на си и на rust. Вот пример, когда переписывание магическим образом заставляет работать %include с тремя уровнями вложенности.
Краткое содержание статьи: «что лучше: табурет, или апельсин? — ответ: у табурета три ноги, а апельсин — круглый».
Термин «преждевременная оптимизация» в обиход ввел Дональд Кнут, одной максимой, которая легко гуглится, и которая, разумеется, разносчиками была полностью вырвана из контекста. Кнут имел в виду совершенно не то, что поняли и продолжают понимать люди, знакомые только с самим лишенным контекста мемом. Я полагал, что прямая ссылка на полный текст появится в заметке, полностью посвященной этой фразе, но если автор не удосужился дать ссылку, то и я не стану.
Вот правильный тезис, который занимает 2 строки — вместо воды на сто абзацев из заметки выше.
Неоптимизированный код писать можно, и нужно, но только в двух случаях:
- если доподлинно известно с гарантией 102%, что объемы обрабатываемых этим кодом данных — постоянны во времени, и никогда не вырастут,
- если четко понятно, как этот код впоследствии, когда объемы вырастут, можно будет изменить малой кровью без необходимости переписывания с нуля.
Во всех остальных случаях эффективность не должна страдать в угоду «высокой читаемости», а сторонников тезиса «код чаще читают, чем пишут» — надо просто увольнять за профнепригодность.

Медленный код — вообще не проблема, если ты знаешь как его ускорить. Главное красиво