Как известно настройка и обучение моделей машинного обучения это только одна из частей цикла разработки, не менее важной частью является развертывание модели для её дальнейшего использования. В этой статье я расскажу о том, как модель машинного обучения может быть развернута в виде Docker микросервиса, а также о том, как можно распараллелить работу микросервиса с помощью распределения нагрузки в несколько потоков через Load balancer. В последнее время Docker набрал большую популярность, однако здесь будет описан только один из видов стратегий развертывания моделей, и в каждом конкретном случае выбор лучшего варианта остаётся за разработчиком.
Гитхаб репозиторий с исходным кодом: https://github.com/cdies/ML_microservice
Введение
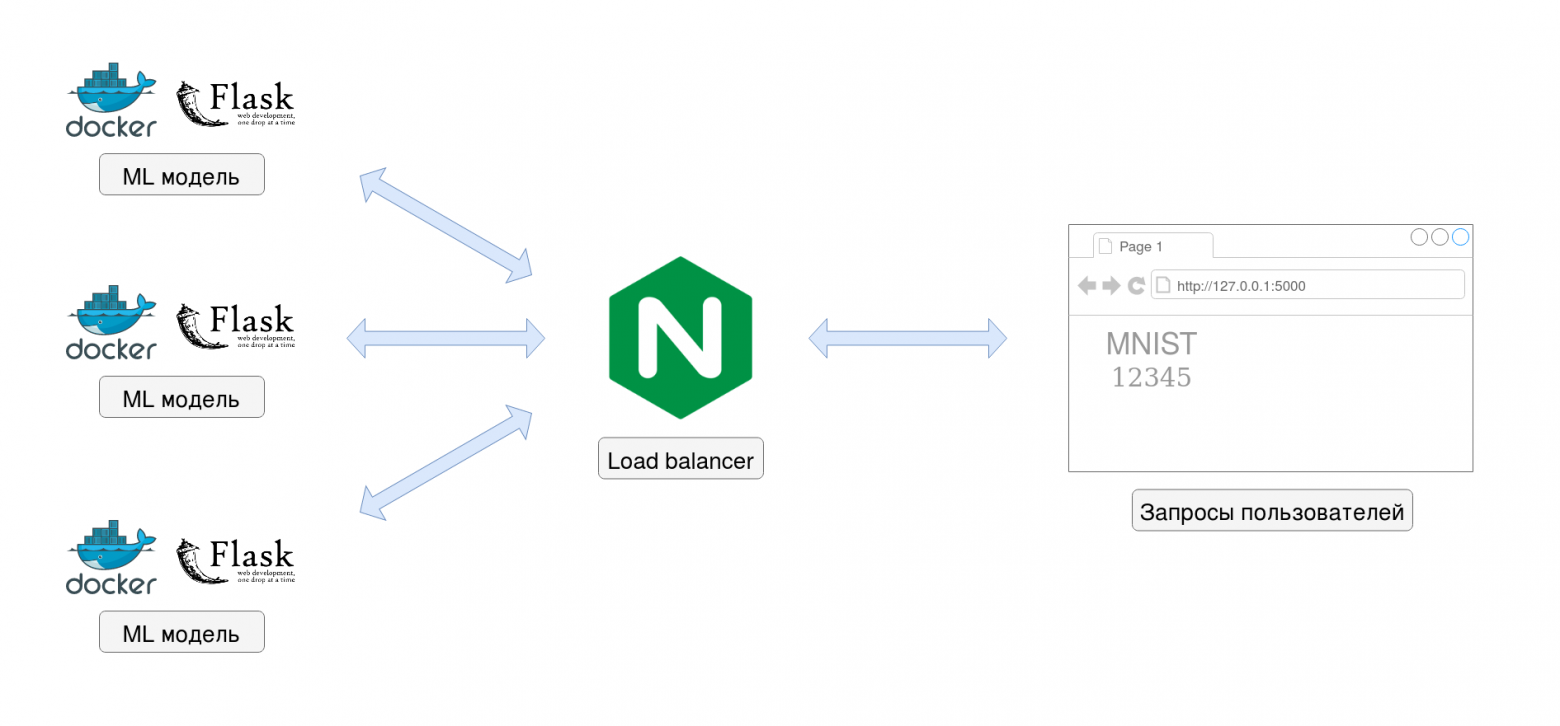
Для этого примера я использовал распространённый набор данных MNIST. Конечная ML модель будет развернута в Docker контейнере, доступ к которой будет организован через HTTP протокол посредствам POST запроса (архитектурный стиль REST API). Полученный таким образом микросервис будет распараллелен через балансировщик на базе Nginx.
Веб фреймворк Flask уже содержит в себе веб-сервер, однако, он используется строго for dev purpose only, т.е. только для разработки, вследствие этого я воспользовался веб-сервером Gunicorn для предоставления нашего REST API.
Описание ML модели
Как уже было отмечено выше, для построения ML модели я использовал, наверное, один из самых известных наборов данных MNIST, тут в принципе показан стандартный пайплайн: загрузка и обработка данных -> обучение модели на нейронной сети Keras -> сохранение модели для повторного использования. Исходный код в файле mnist.py
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout from tensorflow.keras.models import Sequential from tensorflow import keras from tensorflow.keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape((60000,28,28,1)).astype('float32')/255 x_test = x_test.reshape((10000,28,28,1)).astype('float32')/255 y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) model = Sequential() model.add(Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1))) model.add(Conv2D(64, (3,3), activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=128, epochs=12, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test) print(score) # Save model model.save('mnist-microservice/model.h5')
Построение HTTP REST API
Сохранённую ML модель я буду использовать для создания простого REST API микросервиса, для этого воспользуюсь веб-фреймворком Flask. Микросервис будет принимать изображение цифры, приводить его к виду, подходящему для использования в нейронной сети, которую мы сохранили в файле model.h5 и возвращать распознанное значение и его вероятность. Исходный код в файле mnist_recognizer.py
from flask import Flask, jsonify, request from tensorflow import keras import numpy as np from flask_cors import CORS import image app = Flask(__name__) # Cross Origin Resource Sharing (CORS) handling CORS(app, resources={'/image': {"origins": "http://localhost:8080"}}) model = keras.models.load_model('model.h5') @app.route('/image', methods=['POST']) def image_post_request(): x = image.convert(request.json['image']) y = model.predict(x.reshape((1,28,28,1))).reshape((10,)) n = int(np.argmax(y, axis=0)) y = [float(i) for i in y] return jsonify({'result':y, 'digit':n}) if __name__ == "__main__": app.run(host='0.0.0.0', port=5000)
Docker файл микросервиса
В Dockerfile файле микросервиса содержатся все необходимые зависимости, код и сохраненная модель.
FROM python:3.7 RUN python -m pip install flask flask-cors gunicorn numpy tensorflow pillow WORKDIR /app ADD image.py image.py ADD mnist_recognizer.py mnist_recognizer.py ADD model.h5 model.h5 EXPOSE 5000 CMD [ "gunicorn", "--bind", "0.0.0.0:5000", "mnist_recognizer:app" ]
В таком виде микросервис уже можно использовать в однопоточном режиме, для этого нужно выполнить следующие команды в папке mnist-microservice:
docker build -t mnist_microservice_test .
docker run -d -p 5000:5000 mnist_microservice_test
Nginx балансер
Тут сразу стоит уточнить, что, в принципе распараллелить процесс можно было бы с помощью Gunicorn веб-сервера, в частности добавить в Dockerfile в строку запуска Gunicorn веб-сервера --workers n, чтобы было n процессов. Однако я исходил из того, что в Docker контейнере не нужно плодить процессы, кроме необходимых, поэтому решил разделить процессы по контейнерам (одна ML модель — один контейнер), а не сваливать все процессы в один контейнер. (Пишите в комментах, как бы сделали вы)
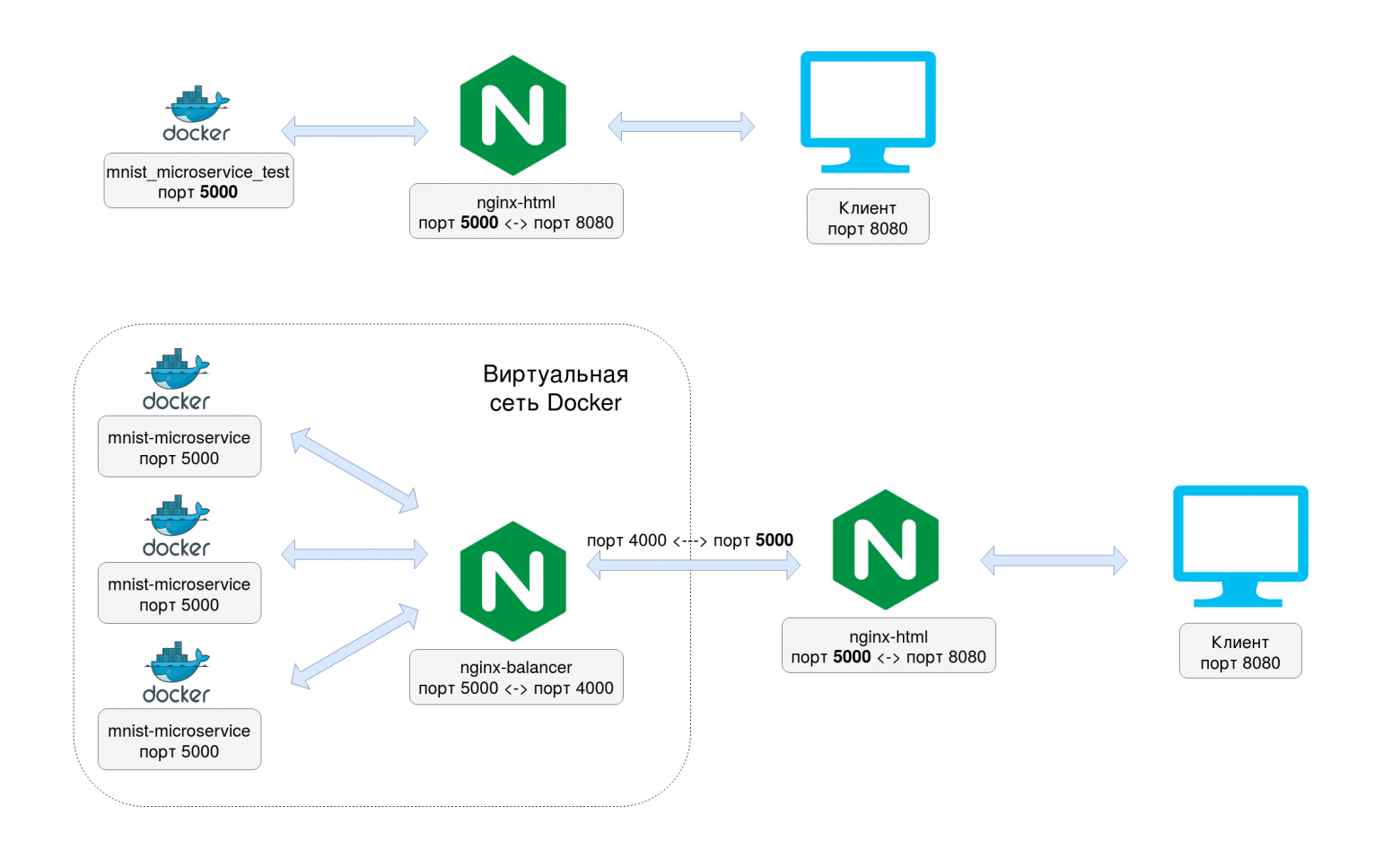
Чтобы балансировщик нагрузки работал, нужно, чтобы Nginx перенаправлял запросы на порт 5000, который слушает наш микросервис. Исходный код в файле nginx.conf
user nginx;events { worker_connections 1000; } http { server { listen 4000; location / { proxy_pass http://mnist-microservice:5000; } } }
В заключительном docker-compose.yml файле я распараллелил созданный ранее микросервис, который назвал здесь mnist-microservice с помощью параметра replicas.
version: '3.7' services: mnist-microservice: build: context: ./mnist-microservice image: mnist-microservice restart: unless-stopped expose: - "5000" deploy: replicas: 3 nginx-balancer: image: nginx container_name: nginx-balancer restart: unless-stopped volumes: - ./nginx-balancer/nginx.conf:/etc/nginx/nginx.conf:ro depends_on: - mnist-microservice ports: - "5000:4000" nginx-html: image: nginx container_name: nginx-html restart: unless-stopped volumes: - ./html:/usr/share/nginx/html:ro depends_on: - nginx-balancer ports: - "8080:80"
Как видно, микросервис также продолжает слушать порт 5000 внутри виртуальной сети докера, в то же самое время nginx-balancer перенаправляет трафик от порта 4000 к порту 5000 также внутри виртуальной сети докера, а уже порт 5000 внешней сети я пробросил на 4000 внутренний порт nginx-balancer. Таким образом, для внешнего веб-сервера nginx-html ничего не поменялось, также не пришлось менять исходный код микросервиса.
Чтобы всё запустить, необходимо выполнить в корневой папке проекта:
docker-compose up --build
Для проверки работы микросервиса можно открыть адрес http://localhost:8080/ в браузере и начать посылать в него цифры нарисованные мышкой, в результате должно получиться что-то вроде этого:

Выводы
В последнее время всё чаще используется микросервисная архитектура. Монолитная и микросервисная архитектуры имеют как свои плюсы, так и минусы. К одному из недостатков монолитной архитектуры можно отнести трудность масштабируемости отдельных компонентов, что напротив, является преимуществом микросервисной архитектуры, ведь появление docker контейнеров позволяет легко и просто масштабировать независимые компоненты и также просто управлять ими.
Полезные ссылки:
https://medium.com/swlh/machine-learning-model-deployment-in-docker-using-flask-d77f6cb551d6
https://medium.com/@vinodkrane/microservices-scaling-and-load-balancing-using-docker-compose-78bf8dc04da9
https://github.com/deadfrominside/keras-flask-app

